
Memcached支持兩種不同方式的客戶端路由算法,即:求余數Hash算法和一致性Hash算法。下面分別進行介紹。
一、 求余數的路由算法
求余數Hash算法的客戶端路由是對插入數據的鍵進行求余數,根據余數來決定存儲到哪個Memcached實例。
| 視頻講解如下 |
|---|
| 【趙渝強老師】Memcached基于求余數的路由算法 |
例如:Memcached服務器端有三臺MemCached實例。那么客戶端進行路由時會根據鍵值對3進行求余數的操作。下面的示例中的鍵分別為:7、6、5.
7%3=1,那么數據值路由到第2臺Memcached實例。
6%3=0,那么數據值路由到第1臺Memcached實例。
5%3=2,那么數據值路由到第3臺Memcached實例。
提示:求余數Hash算法的客戶端路由的優點在于,能夠使數據均勻地分布在每個Memcached實例上。但是它也存在很大的缺點,就是當進行擴容縮容操作時,或者某個Memcached實例出現宕機的情況。該算法會出現嚴重的數據丟失。
下面通過一個簡單的示例來說明求余數Hash算法的數據是如何丟失的。
擴容前有3個Memcached實例:7%3=1,6%3=0,5%3=2,......
擴容后有4個Memcached實例:7%4=3,6%4=2,5%4=1,......
當有3個Memcached實例時,7號鍵存儲在第2臺Memcached實例上,而擴容后變成了存儲在4臺Memcached實例上,其他的鍵以此類推。這就導致了存取的目標位置不一樣,從而造成數據的丟失。

二、 一致性Hash算法
為了解決求余數Hash算法的數據丟失問題,Memcached又提出了一致性Hash算法的客戶端路由。通過使用該算法能夠將丟失的數據減小到最小,但不能完全解決宕機造成的數據丟失的問題。
| 視頻講解如下 |
|---|
| 【趙渝強老師】Memcached基于一致性Hash的路由算法 |
下圖展示了一致性Hash算法基本原理。
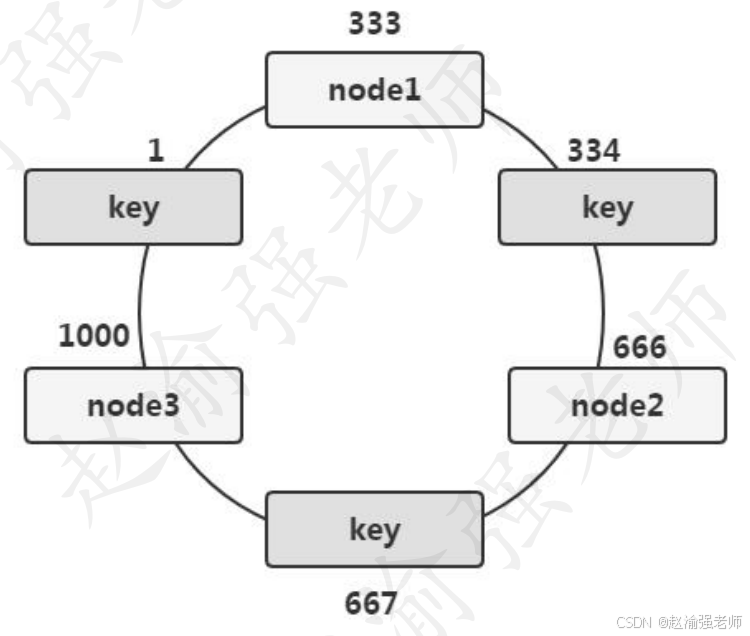
在初始的狀態下有三個Memcached服務器實例,分別是:node1、node2和node3。其中:node1將保存鍵從1333之間的數據值;node2將保存鍵從333666之間的數據值;node3將保存鍵從667~1000之間的數據值。
| 一致性Hash路由算法的擴容和縮容視頻講解如下 |
|---|
| 【趙渝強老師】Memcached一致性Hash路由算法的擴容和縮容 |
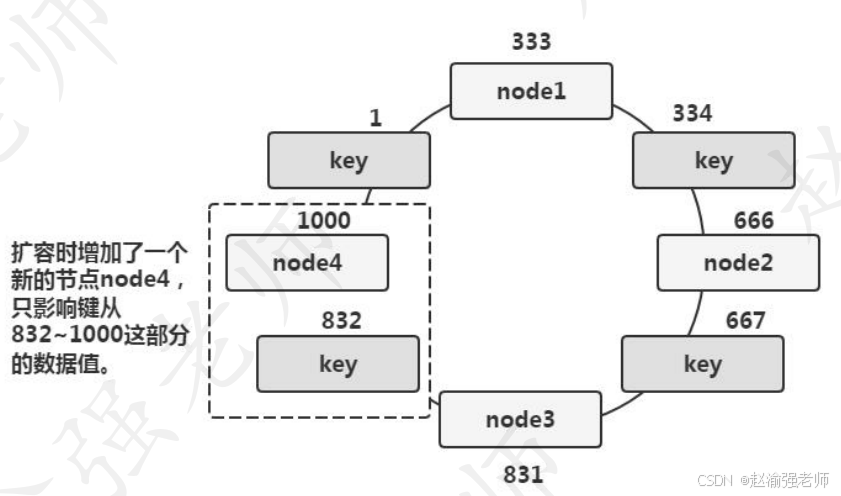
下圖進一步說明當Memcached集群發生擴容時數據存儲位置的變化。
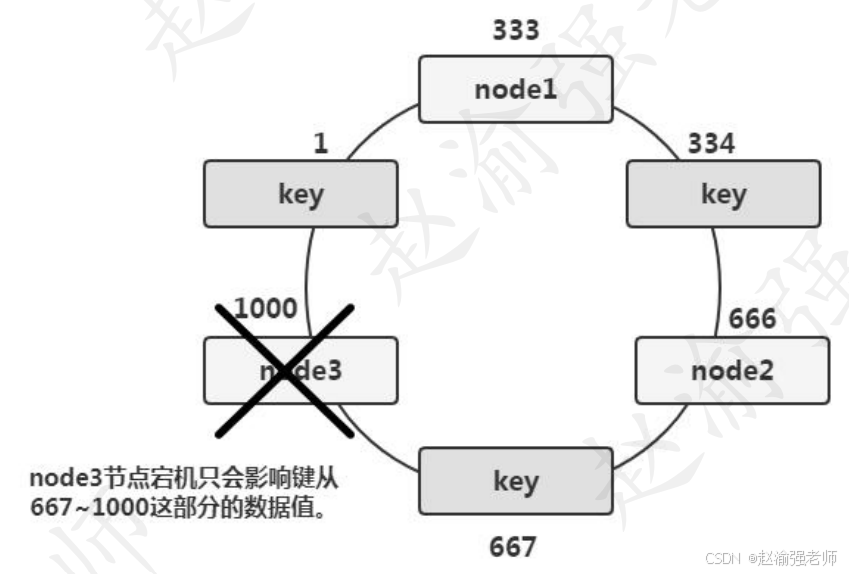
當Memcached集群發生故障出現宕機時,一致性Hash算法能夠將丟失的數據減小到最小。如下圖所示。當node3節點出現故障而宕機時,只會影響鍵從667~1000這部分的數據值。而存儲在node1和node2上的數據將不會有任何的變化。換句話說,node3的宕機只影響了三分之一的數據。
: 線性代數(矩陣運算、特征值分解等))
)







)



1.二分查找)
:基礎設備篇——人類精密制造的“巔峰對決”)




![[ linux-系統 ] 命令行參數 | 環境變量](http://pic.xiahunao.cn/[ linux-系統 ] 命令行參數 | 環境變量)