TL;DR
- 2024 年 Physical Intelligence 發布的 VLA 模型 π0,基于 transformer + 流匹配(flow matching)架構,當前開源領域最強的 VLA 模型之一。
Paper name
π0: A Vision-Language-Action Flow Model for General Robot Control
Paper Reading Note
Paper URL:
- https://www.physicalintelligence.company/download/pi0.pdf
Project URL:
- https://www.physicalintelligence.company/blog/pi0
Introduction
背景
“一個人應該能換尿布、策劃入侵、屠宰豬只、駕駛船只、設計建筑、寫十四行詩、核對賬目、砌墻、接骨、安慰垂死之人、服從命令、發號施令、協作、獨立行動、解方程、分析新問題、鏟糞、編程、做出美味飯菜、高效作戰、英勇赴死。專業化,是昆蟲的事。”
——羅伯特·海因萊因,《愛的時光足夠長》
- 在多樣性這一維度上,人類智能遠遠超越了機器智能:也就是在不同物理環境中解決多樣任務的能力,能根據環境限制、語言指令以及突發擾動作出智能反應
- 然而,構建這樣的通用機器人策略(即“機器人基礎模型”)仍面臨多項重大挑戰:
- 規模要求高:要實現預訓練帶來的全部優勢,研究必須在大規模下進行
- 模型架構合適:需開發能有效利用多源數據、同時能表達復雜交互行為的架構
- 訓練策略關鍵:如在自然語言與視覺模型中,許多進展都依賴于預訓練和后訓練階段的數據精細策劃
本文方案
- 提出一個原型模型及其學習框架,稱為 π?(Pi-zero),展示如何應對上述三大瓶頸
- 規模
- 首先使用預訓練視覺語言模型(VLM)訓練視覺-語言-動作(VLA)模型,引入互聯網上規模級的經驗
- 跨具身訓練(cross-embodiment training),將來自單臂、雙臂、移動操作器等多種機器人平臺的數據整合在一個模型中
- 模型架構
- 基于流匹配(flow matching,一種擴散模型變體)的動作分塊(action chunking)架構,可支持高達 50 Hz 的控制頻率
- 訓練策略
- 預訓練/后訓練兩階段結構。先在多樣大數據上預訓練,再用高質量數據微調,從而達到所需的精細控制能力。
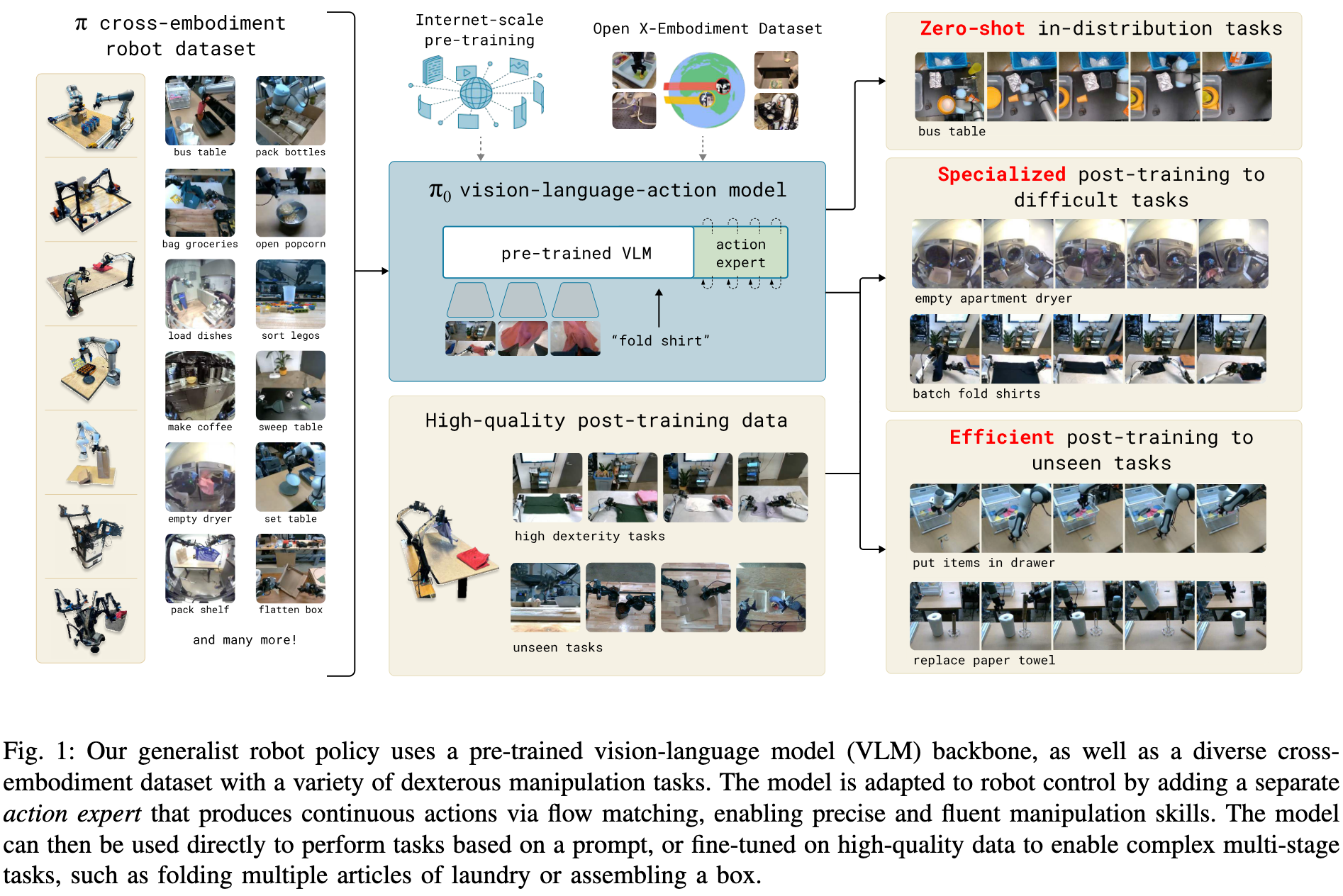
- 預訓練/后訓練兩階段結構。先在多樣大數據上預訓練,再用高質量數據微調,從而達到所需的精細控制能力。
- 規模
通過超過一萬小時的機器人數據進行預訓練,并在多個精細任務中進行微調,包括疊衣服(圖2)、清理餐桌、放置餐具、裝蛋、組裝紙盒和打包購物物品。

Methods
網絡架構
- π0 模型如圖 3 所示,主要由語言模型的 Transformer 主干構成。
- 根據標準的后融合視覺語言模型(VLM)方案,圖像編碼器將機器人的圖像觀測嵌入到與語言標記相同的嵌入空間中。
- 進一步在此主干基礎上增加了特定于機器人任務的輸入與輸出——即本體感知狀態和機器人動作。π0 使用條件流匹配(Conditional Flow Matching)來建模動作的連續分布。流匹配使模型具有高精度和多模態建模能力,特別適合高頻率的精細操作任務。
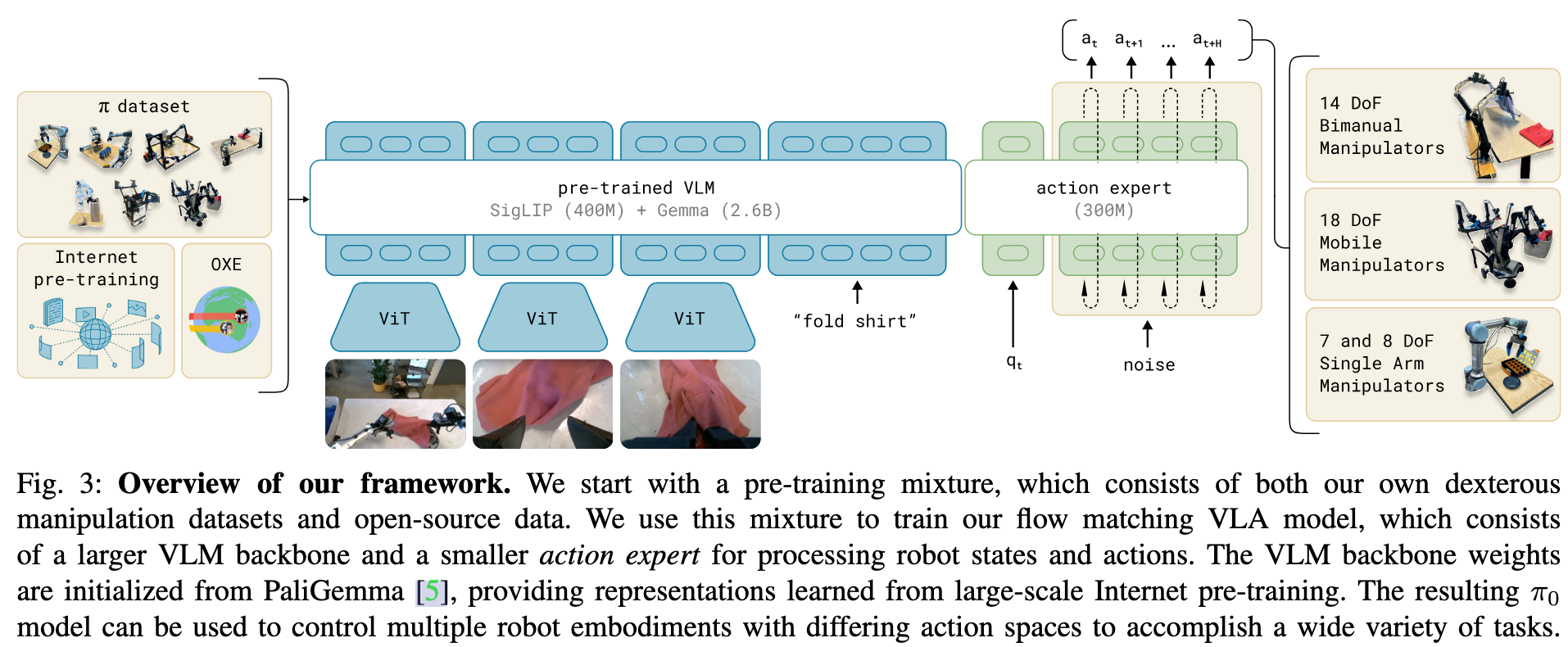
架構靈感來源于 Transfusion,該方法通過多個目標訓練一個單一的 Transformer,利用流匹配損失監督連續輸出的標記,使用交叉熵損失監督離散輸出的標記。在此基礎上,我們發現對機器人特定的動作與狀態標記使用獨立的一套權重會提升性能。這種設計類似于專家混合模型(Mixture of Experts)的兩專家結構:第一專家處理圖像和文本輸入,第二專家處理與機器人相關的輸入與輸出。我們將第二組權重稱為“動作專家”。
訓練目標
形式上,我們要建模的數據分布為 p ( A t ∣ o t ) p(A_t | o_t) p(At?∣ot?),其中 A t = [ a t , a t + 1 , . . . , a t + H ? 1 ] A_t = [a_t, a_{t+1}, ..., a_{t+H-1}] At?=[at?,at+1?,...,at+H?1?] 是未來動作的一個動作塊(在我們的任務中,H = 50),而 o t o_t ot? 是觀測。觀測包括多張RGB圖像、一個語言指令和機器人的本體感知狀態,即
o t = [ I t 1 , . . . , I t n , ? t , q t ] o_t = [I^1_t, ..., I^n_t, \ell_t, q_t] ot?=[It1?,...,Itn?,?t?,qt?]
其中 I t i I^i_t Iti? 是第 i i i 張圖像(每個機器人有 2 或 3 張圖像), ? t \ell_t ?t? 是語言標記序列, q t q_t qt? 是關節角度向量。圖像 I t i I^i_t Iti? 和狀態 q t q_t qt? 經過對應的編碼器,并通過線性投影映射到與語言標記相同的嵌入空間中。
對于動作塊 A t A_t At? 中的每個動作 a t ′ a'_t at′?,我們都有一個對應的動作標記,通過“動作專家”進行處理。訓練期間,這些動作標記通過條件流匹配損失進行監督:
L τ ( θ ) = E p ( A t ∣ o t ) , q ( A t τ ∣ A t ) ∥ v θ ( A t τ , o t ) ? u ( A t τ ∣ A t ) ∥ 2 L_\tau (\theta) = \mathbb{E}_{p(A_t | o_t), q(A^\tau_t | A_t)} \left\| v_\theta (A^\tau_t, o_t) - u(A^\tau_t | A_t) \right\|^2 Lτ?(θ)=Ep(At?∣ot?),q(Atτ?∣At?)?∥vθ?(Atτ?,ot?)?u(Atτ?∣At?)∥2
其中下標表示機器人時間步,上標表示流匹配時間步, τ ∈ [ 0 , 1 ] \tau \in [0, 1] τ∈[0,1]。
近期在高分辨率圖像和視頻合成中的研究表明,當與簡單的線性高斯路徑(或最優傳輸路徑)聯合使用時,流匹配可獲得優異的經驗性能。此概率路徑形式為:
q ( A t τ ∣ A t ) = N ( τ A t , ( 1 ? τ ) I ) q(A^\tau_t | A_t) = \mathcal{N}(\tau A_t, (1 - \tau)I) q(Atτ?∣At?)=N(τAt?,(1?τ)I)
實際中,網絡通過以下方式訓練:采樣隨機噪聲 ε ~ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, I) ε~N(0,I),計算“加噪動作”
A t τ = τ A t + ( 1 ? τ ) ε A^\tau_t = \tau A_t + (1 - \tau) \varepsilon Atτ?=τAt?+(1?τ)ε
并訓練網絡輸出 v θ ( A t τ , o t ) v_\theta (A^\tau_t, o_t) vθ?(Atτ?,ot?) 來匹配去噪向量場
u ( A t τ ∣ A t ) = ε ? A t u(A^\tau_t | A_t) = \varepsilon - A_t u(Atτ?∣At?)=ε?At?
“動作專家”采用全雙向注意力掩碼,確保所有動作標記之間可以相互注意。在訓練中,我們從一個偏向低值(即更嘈雜時間步)的 Beta 分布中采樣 τ \tau τ。
推理
在推理階段,我們通過將學習到的向量場從 τ = 0 \tau=0 τ=0 積分到 τ = 1 \tau=1 τ=1 來生成動作,起始為隨機噪聲 A t 0 ~ N ( 0 , I ) A^0_t \sim \mathcal{N}(0, I) At0?~N(0,I)。我們使用前向歐拉積分規則:
A t τ + δ = A t τ + δ v θ ( A t τ , o t ) A^{\tau + \delta}_t = A^\tau_t + \delta v_\theta(A^\tau_t, o_t) Atτ+δ?=Atτ?+δvθ?(Atτ?,ot?)
其中 δ \delta δ 是積分步長,我們實驗中使用10個積分步(即 δ = 0.1 \delta = 0.1 δ=0.1)。值得注意的是,推理過程可高效實現——可緩存前綴 o t o_t ot? 的注意力鍵和值,僅需在每個積分步重新計算與動作標記相關的后綴部分。
模型細節
雖然理論上該模型可從頭訓練或從任意 VLM 主干微調,實踐中我們使用 PaliGemma 作為基礎模型。PaliGemma 是一個開源的 30 億參數的 VLM,在規模與性能之間實現了良好平衡。我們為“動作專家”額外添加了 3 億參數(從頭初始化),使總參數量達到 33 億。
非VLM對照模型。 除了主模型外,我們還訓練了一個未使用 VLM 初始化的類似對照模型,用于消融實驗。我們稱之為 π0-small,其參數量為 4.7 億,未采用VLM初始化,并針對非 VLM 初始化情境在結構上做了一些小改動,幫助更好地在我們的數據上進行訓練。該模型用于評估使用 VLM 初始化帶來的收益。
數據收集與訓練方案
-
預訓練的目標是讓模型接觸到多樣化的任務,從而習得通用的物理能力;而后訓練的目標則是讓模型能夠熟練地完成具體的下游任務。預訓練與后訓練階段所需的數據具有不同特點:
- 預訓練數據集應覆蓋盡可能多的任務,并且在每個任務內包含多種行為方式;
- 后訓練數據集則應著重于高質量、流暢、連貫的策略表現,能夠有效支持目標任務的執行。
-
圖4中展示了預訓練數據混合概況。
- 開源數據占預訓練數據的 9.1%,包括 OXE、Bridge v2 和 DROID
- 我們自建的數據集占據 9.03 億時間步
- 其中 1.06 億步來自單臂機器人,
- 7.97 億步來自雙臂機器人。
- 總共包含 68 個任務,任務設計復雜。例如,“bussing”(收拾桌面)任務涉及將多種餐具、杯子和餐盤放入清理桶,同時將不同種類的垃圾丟入垃圾桶。

- 訓練配置
- 動作向量 a t a_t at? 和機器人配置向量 q t q_t qt?? 的維度固定為數據集中最大機器人維度(18 維),以容納兩個 6 自由度機械臂、兩個夾爪、一個移動底座和一個升降軀干。
- 對低維度的機器人,我們進行零填充;
- 若圖像數量少于3張,也對缺失圖像位進行遮罩。
后訓練(任務特化)
后訓練階段使用規模較小、與具體任務相關的數據集對模型進行微調,以便其專精于下游應用。不同任務對數據需求不同,從最簡單任務僅需約 5小時數據,到復雜任務可能需要 100小時或以上。
語言與高層策略
對于如“清理桌面”這類需要語義推理和策略規劃的復雜任務,我們引入高層策略(high-level policy)對任務進行分解(如將“清理桌面”分解為“撿起餐巾紙”“扔進垃圾桶”等子任務)。由于模型本身支持語言輸入,我們可以使用高層VLM模型進行語義推理,其方法類似于 SayCan 等LLM/VLM規劃系統。
機器人系統
- 精細操作數據集包含 7 種機器人配置,涵蓋 68 個任務

| 機器人類型 | 配置描述 |
|---|---|
| UR5e | 單臂,7自由度,帶夾爪。配有一個腕部攝像頭和一個肩部攝像頭(共2張圖像)。配置與動作空間維度為7。 |
| Bimanual UR5e | 兩個UR5e機械臂,三張圖像,配置與動作空間為14維。 |
| Franka | 單臂,8維配置與動作空間,配有2張圖像。 |
| Bimanual Trossen | 2個6自由度的Trossen ViperX機械臂,ALOHA架構,配有兩個腕部攝像頭和一個底部攝像頭,14維配置與動作空間。 |
| Bimanual ARX & AgileX | 2個6自由度機械臂(ARX或AgileX),三張圖像,14維空間。因運動學相似歸為同一類。 |
| Mobile Trossen & ARX | Mobile ALOHA平臺,2個6自由度機械臂(ARX或Trossen ViperX),配移動底座(增加2維動作),總共14維配置 + 16維動作。3張圖像。 |
| Mobile Fibocom | 2個6自由度ARX機械臂,帶全向移動底座,底座增加3個自由度(2平移 + 1旋轉),總共14維配置 + 17維動作。 |
數據集比例中看起來是 Bimanual ARX 占了大頭
Experiments
基礎模型測試(開箱即用)
- 與以下模型對比:
- OpenVLA:7B參數,訓練于OXE。
- Octo:93M參數,基于擴散模型生成動作。
- π0-small:未進行VLM初始化的小模型。
- π0 parity:使用與baseline相同訓練步數的π0版本(160k步)。
- OpenVLA-UR5e:僅在UR5e任務上精調過的版本。

- 圖7顯示,即使是 parity 版本的 π0 也顯著優于所有 baseline,完整訓練的 π0 則有壓倒性優勢。OpenVLA 因不支持動作塊(action chunk)而效果不佳;Octo 表現稍好但表示能力有限

跟隨語言指令
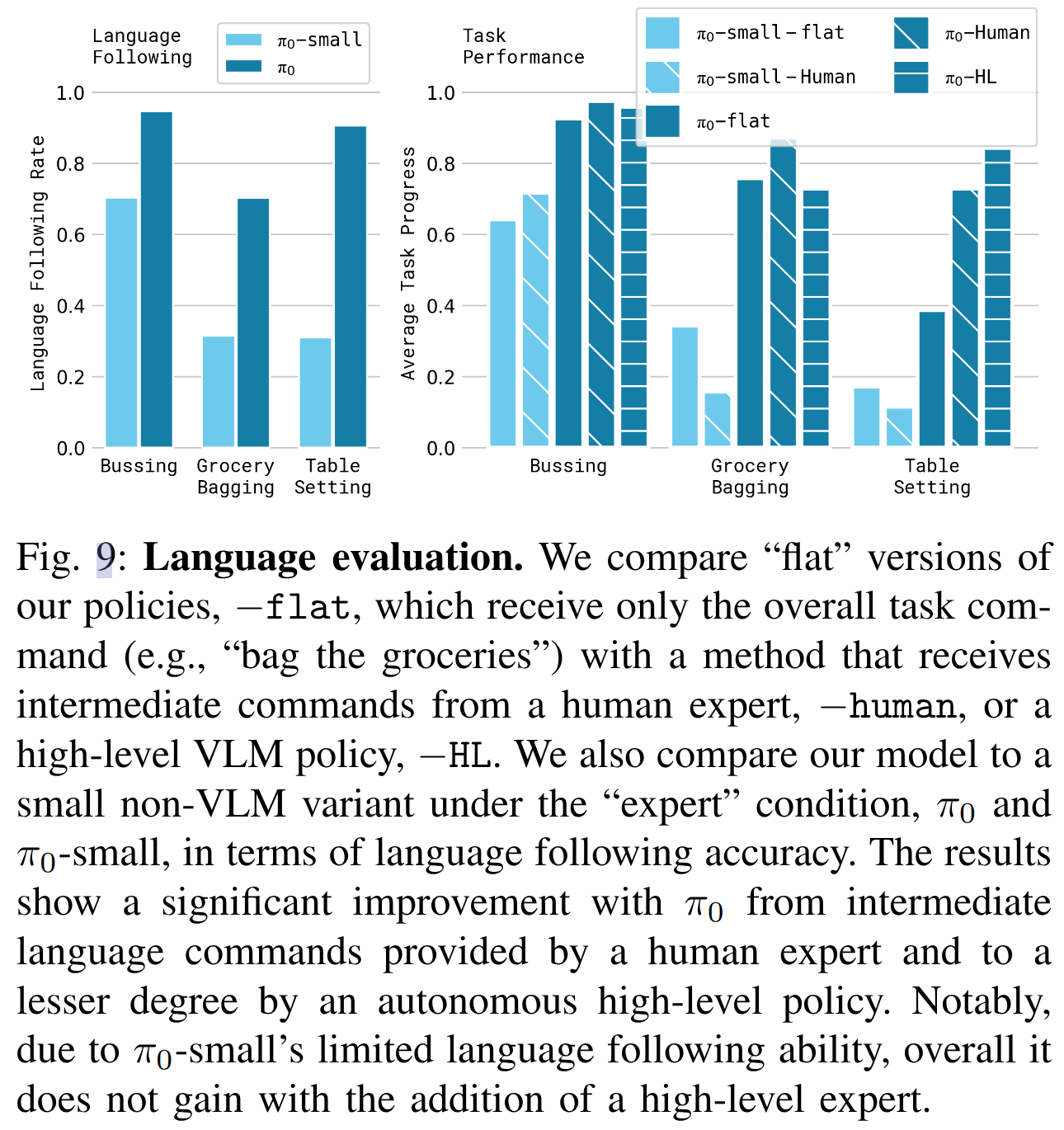
評估 π0 與 π0-small 在語言指令下的跟隨能力,任務包括:
- 清理桌面
- 擺放餐具
- 雜貨打包

我們設置三種提示條件:
- flat:只給出整體任務指令
- human:中間步驟由人工專家提供(如“拿起餐巾紙并扔進垃圾桶”)
- HL:由高層 VLM 策略生成中間語言指令
結果如圖9所示:π0 明顯優于 π0-small,特別是在 human 和 HL 條件下。說明 VLM 預訓練顯著增強了語言理解與自主任務執行能力。
學習全新精細操作任務
| 任務名稱 | 描述 | 難度 |
|---|---|---|
| 疊碗(UR5e) | 疊放不同尺寸碗 | 易 |
| 疊毛巾 | 與疊T恤相似 | 易 |
| 放保鮮盒進微波爐 | 包含新對象“微波爐” | 中 |
| 更換紙巾卷 | 無預訓練相似經驗 | 難 |
| 抽屜收納(Franka) | 打開/關閉抽屜并整理物品 | 難 |
比較以下方法:
- π0(預訓練+精調)
- π0 從頭訓練
- OpenVLA
- Octo
- ACT 與 Diffusion Policy(專為小數據精細操作任務設計)
結果如圖11:π0 在所有任務上整體表現最佳,尤其在預訓練任務相似的場景中效果顯著。對于如“保鮮盒微波爐”這類任務,π0在僅1小時訓練下即可大幅優于其他方法。
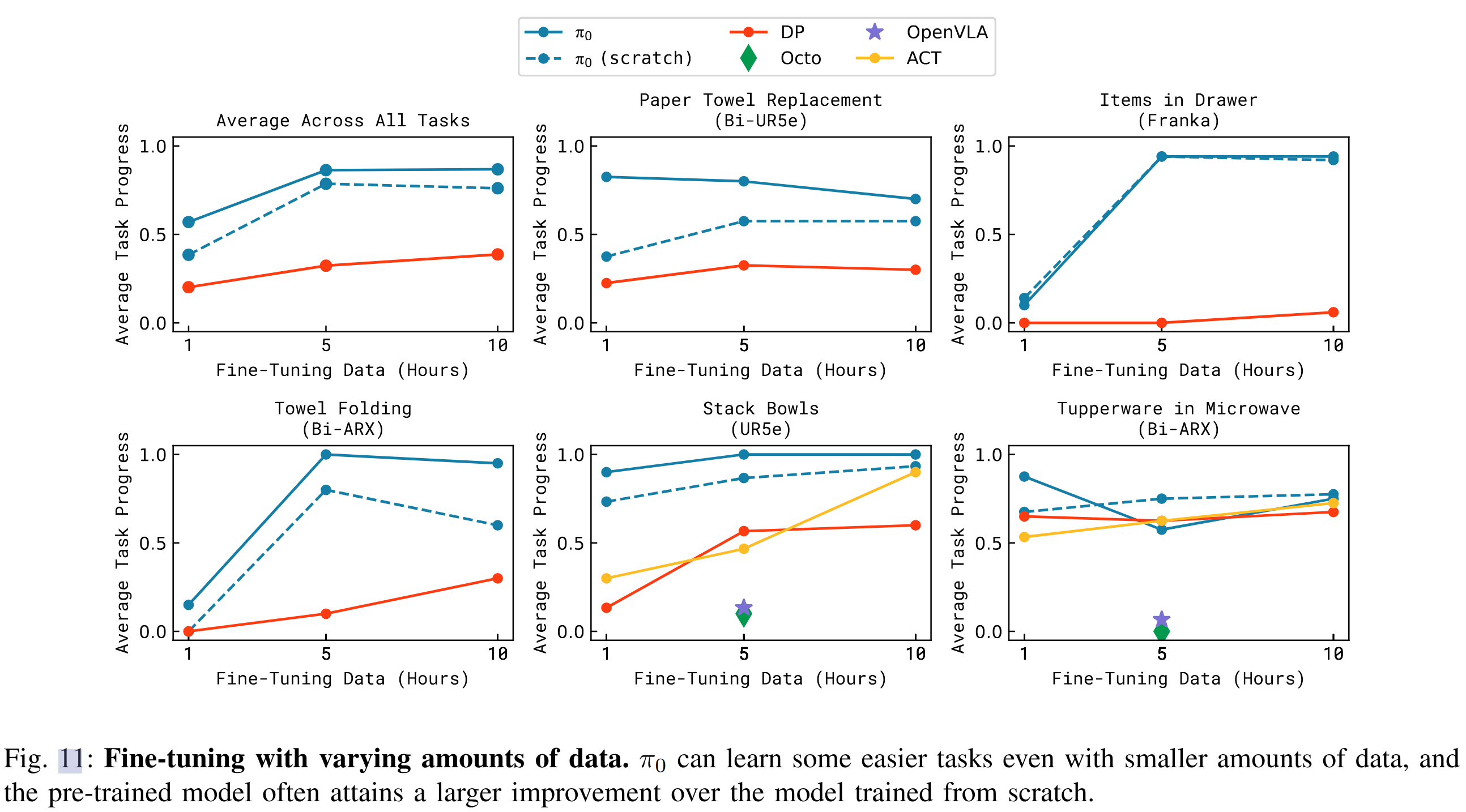
- 微調還是能帶來很大提升
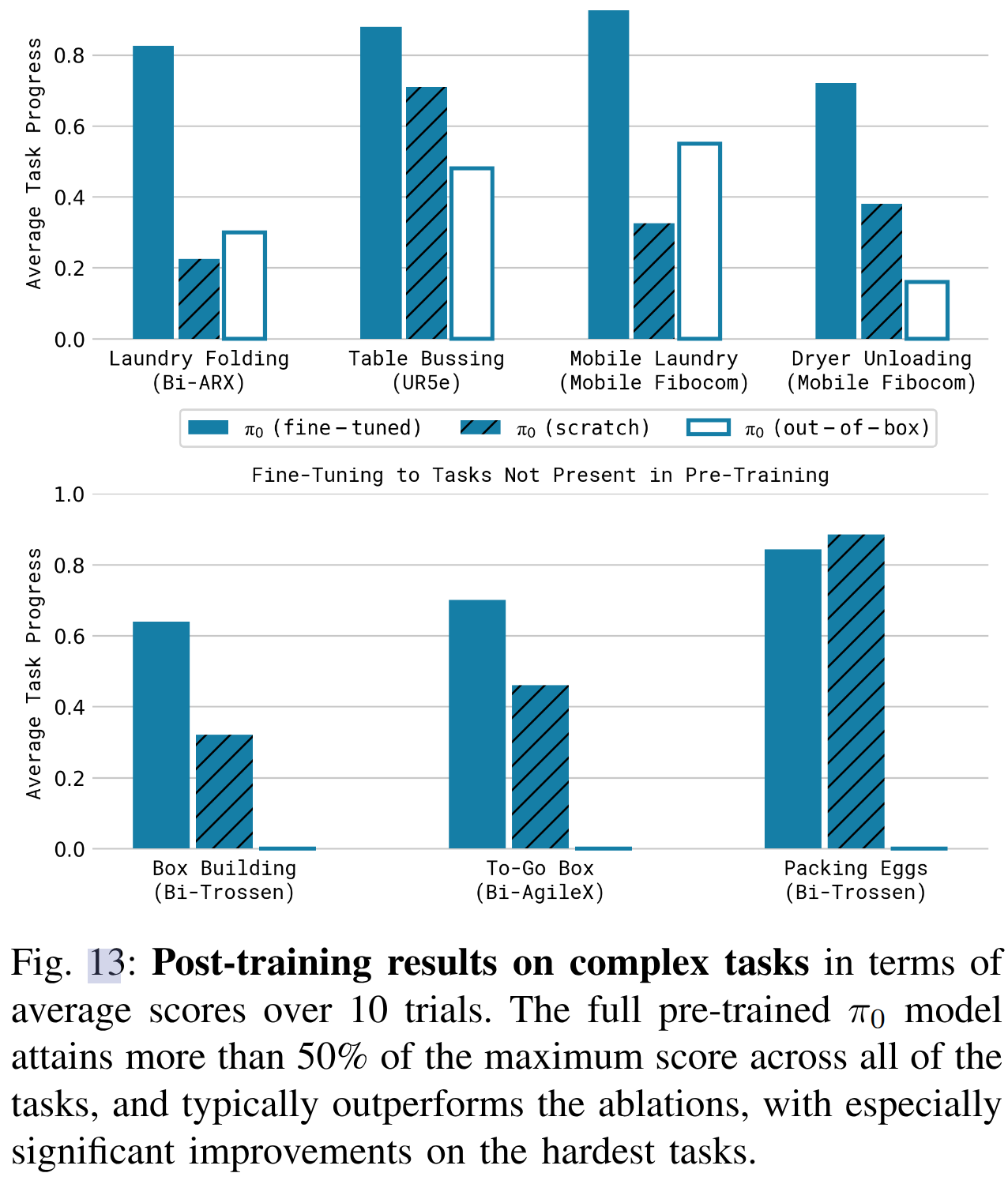
Conclusion
- 提出了 π0 的訓練框架,通過海量預訓練和精調,可執行多階段、需要策略與精細操作的任務。其關鍵特點包括:
- 結合 Internet 規模的 VLM 預訓練與流匹配方法表達高頻動作塊;
- 使用超過 1 萬小時數據、涵蓋 7 種機器人配置與 68 個任務;
- 精調覆蓋 20 多個任務,超越多種現有方法;
- 類似 LLM 的訓練流程,預訓練提供知識,精調對齊模型策略。
:LeetCode 41. 缺失的第一個正數(First Missing Positive)詳解)



(HTML資源交互、網頁管理、搜索引擎))
)







)



系統)

