模板進階
- 一、非類型模板參數
- 1、模板參數的分類
- 2、應用場景
- 3、array
- 4、注意
- 二、模板的特化
- 1、概念
- 2、函數模板特化
- 3、類模板特化
- (1)、全特化:全部模板參數都特化成具體的類型
- (2)、偏/半特化:部分模板參數特化成具體的類型,還可以是對參數的進一步限制
- (3)、priority_queue中使用類模板特化
- 三、typename的特性
- 四、模板的分離編譯
- 五、模板的優缺點
一、非類型模板參數
1、模板參數的分類
- 模板參數分為非類型模板參數和類型模板參數:
-
類型模板參數:出現在模板參數列表中,跟在class或者typename之后的參數類型名稱。我們之前定義的都是類型模板參數。
-
非類型模板參數:常量作為類(函數)模板的參數,在類(函數)模板中可將該參數當成常量來使用。
2、應用場景
為什么要有非類型模板參數?
例如,定義一個靜態的棧。靜態棧需要確定大小,假設兩個棧分別是10、100個空間,但是靜態棧不能同時做到一個是10個,一個是100個,宏常量只能是一個大小;與typedef是一樣的道理,只能保證是一個類型。若將N改成100#define N 100,對于第一個棧就浪費了90個空間。
#define N 10
template<class T>
class Stack
{
private:T _a[N];size_t _top;
};
int main()
{Stack<int> st1;// 10Stack<int> st2;// 100return 0;
}
所以C++又增加了一個非類型模板參數,非類型模板參數與宏很類似但是比宏更靈活,本質還是由Stack實例化出的兩個類:
template<class T, size_t N>
class Stack
{
private:T _a[N];size_t _top;
};
int main()
{Stack<int, 10> st1;// 10Stack<int, 100> st2;// 100return 0;
}

非類型模板參數也可以給缺省值:
template<class T, size_t N = 10>
class Stack
{
private:T _a[N];size_t _top;
};
int main()
{Stack<int> st1;// 10Stack<int, 100> st2;// 100return 0;
}
3、array
看看庫里面使用非類型模板參數的容器:C++11新增的容器array(靜態數組),與vector形成對照。

沒有提供頭插頭刪尾插尾刪接口,因為空間是一定的,用下標隨機訪問就行。
嚴格來說,array對比的不是vector,因為vector是動態的,二者本質還是不一樣的,array對比的是C語言中的靜態數組。
array與C中的靜態數組很像:存儲的數據類型可以是自定義類型,也可以是內置類型的;sizeof出來的大小是一樣的;只不過array中多了個迭代器,其實就是原生指針,C中靜態數組可以用范圍for,也是可以轉換成原生指針。
int main()
{// C++中用類封裝的靜態數組arrayarray<int, 10> a1;array<int, 100> a2;array<string, 100> a3;// C中靜態數組int aa1[10];int aa2[100];string aa3[100];cout << sizeof(a1) << endl;cout << sizeof(aa1) << endl;return 0;
}

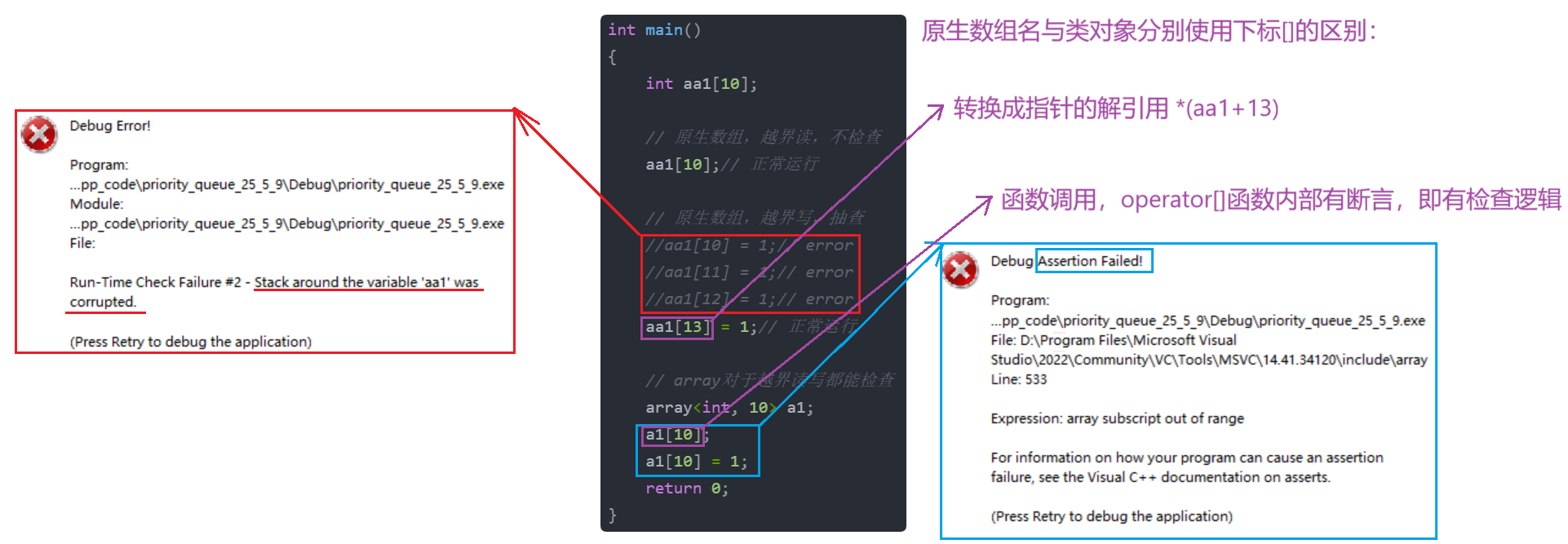
array與C中靜態數組真正的區別只有一個:越界的檢查方式不同。
- C中靜態數組:
- 原生數組,越界讀,不檢查。
- 原生數組,越界寫,抽查。一般在結束位置附近可以檢查出來,但是再往后的位置越界就會檢查不出來。
- array:
- array對于越界讀寫都能檢查
那么array是怎么做到越界讀寫都能檢查到的?自定義類型對象調用 operator[] ,函數里面有assert斷言檢查,所以報錯報的是斷言錯誤。
但是array用的很少,一般用的是vector。vector有初始化;array連初始化都沒有,都是隨機值。而且array實參N的值不能太大,棧空間不大,會棧溢出。若就想用靜態數組,那么就可以用array替代C中靜態數組。
4、注意
- 非類型模板參數一般要求只能是整型。浮點數、類對象以及字符串等其他類型是不允許作為非類型模板參數的。但是C++20以后可以支持其他類型作為非類型模板參數。
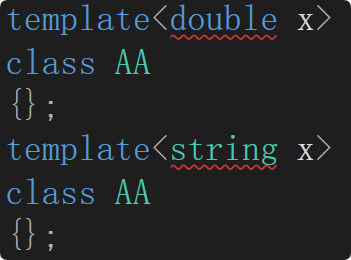
- 非類型的模板參數必須在編譯期間就能確認結果。
二、模板的特化
1、概念
特化:特殊化處理。
通常情況下,使用模板可以實現一些與類型無關的代碼,但對于一些特殊類型可能會得到一些錯誤的結果,需要特殊處理,比如:實現了一個專門用來進行小于比較的函數模板。
// 函數模板 -- 參數匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
int main()
{cout << Less(1, 2) << endl;// 可以比較,結果正確Date d1(2025, 5, 11);Date d2(2025, 5, 12);cout << Less(d1, d2) << endl;// 可以比較,結果正確Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl;// 可以比較,結果錯誤return 0;
}

可以看到,Less絕大多數情況下都可以正常比較,但是在特殊場景下就得到錯誤的結果。上述示例中,p1指向的d1顯然小于p2指向的d2對象,但是Less內部并沒有比較p1和p2指向的對象內容,而比較的是p1和p2指針的地址,這就無法達到預期而錯誤。
此時,就需要對模板進行特化。即:在原模板的基礎上,對特殊類型進行特殊化的處理。模板特化分為函數模板特化與類模板特化。
2、函數模板特化
函數模板的特化步驟:
- 必須要先有一個基礎的函數模板
- 關鍵字template后面接一對空的尖括號<>
- 函數名后跟一對尖括號,尖括號中指定需要特化的類型
- 函數形參表:必須要和函數模板的基礎參數類型完全相同,如果不同編譯器可能會報一些奇怪的錯誤。
(類模板的特化步驟與之類似,不過類模板特化和類模板里的函數參數列表沒有必要完全相同)
函數模板本質是一種參數匹配,對函數模板進行特化本質也是一種參數匹配。
// 函數模板 -- 參數匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
// 對Less函數模板進行特化 -- 參數匹配
template<>
bool Less<Date*>(Date* left, Date* right)// T實例化成Date*
{return *left < *right;
}
int main()
{cout << Less(1, 2) << endl;Date d1(2025, 5, 11);Date d2(2025, 5, 12);cout << Less(d1, d2) << endl;Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl;// 調用特化之后的版本,而不走模板生成了return 0;
}
注意:一般情況下如果函數模板遇到不能處理或者處理有誤的類型,為了實現簡單通常都是將該函數直接給出。普通函數可以與函數模板同時存在,有現成吃現成,就會直接調用現有的函數,所以函數模板不建議特化,直接寫普通函數即可。
bool Less(Date* left, Date* right)
{return *left < *right;
}
為什么不建議函數模板特化呢?函數模板的坑:
傳值傳參,若T是有深拷貝的自定義類型,代價太大了,所以會加引用。加了引用一般就會加const,這樣普通對象、const對象都可以作為參數傳遞過來。對上述函數模板改造如下:
但是報錯了,會不會是參數列表沒有對上?但是加上了引用也還是報錯了。
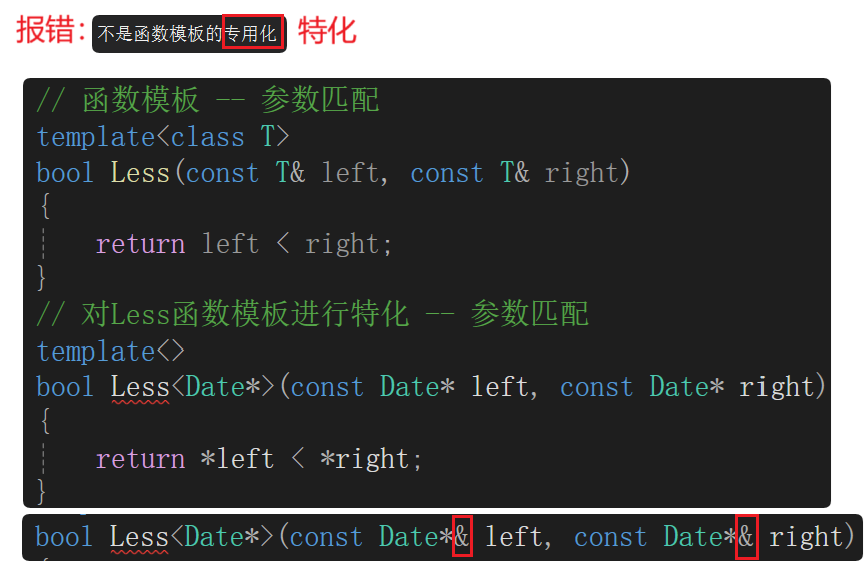
問題出現在const上,"不是函數模板的專用化"的原因是const修飾的匹配不上。所以特化的const的正確位置如右圖。

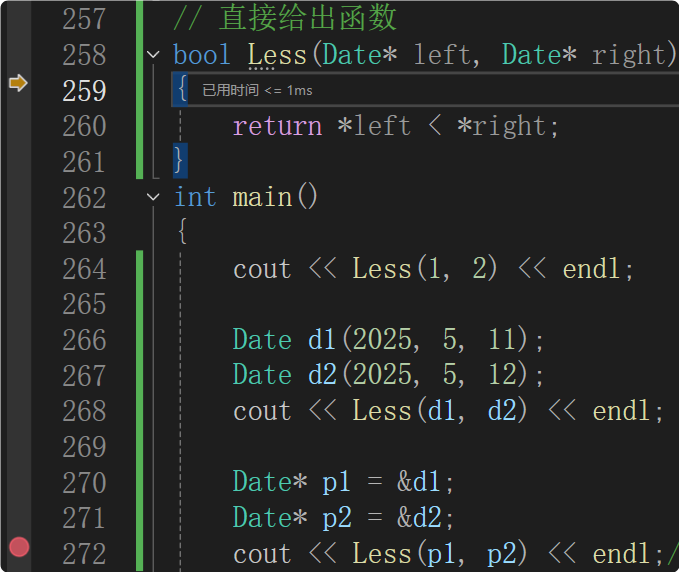
所以函數模板特化是很容易出現問題的,直接寫成普通函數即可。
借助調試理解普通函數與函數模板特化同時存在時,會優先匹配普通函數。
3、類模板特化
(1)、全特化:全部模板參數都特化成具體的類型
函數模板可以特化,也可以寫出普通函數。而對于類模板特化,沒有普通類的概念,必須走類模板特化。因為函數與函數模板可以參數匹配,而類模板必須顯示實例化。
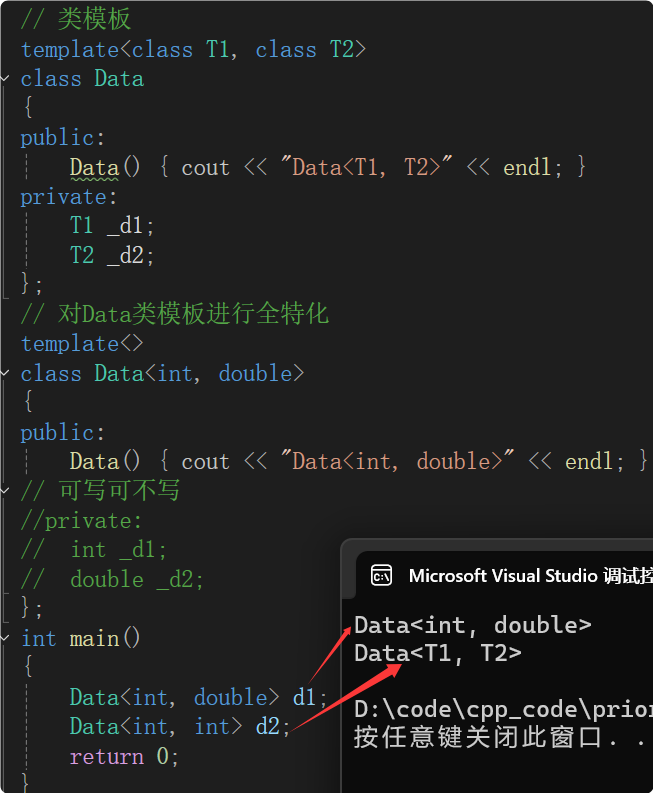
Data<int, double> d1;實例化出的類的數據類型T1是int、T2是double,就會優先匹配上面類模板特化的版本。
(2)、偏/半特化:部分模板參數特化成具體的類型,還可以是對參數的進一步限制
部分模板參數特化成具體的類型:
// 將第二個參數特化為char
template<class T1>
class Data<T1, char>
{
public:Data() { cout << "Data<T1, char>" << endl; }
};
對模板參數的進一步限制:
// 特化 -- 偏特化,實例化出的模板參數只要都是指針就會走這個版本
// 兩個參數偏特化為指針類型
template<class T1, class T2>
class Data<T1*, T2*>
{
public:Data() { cout << "Data<T1*, T2*>" << endl; }
private:T1 _d1;T2 _d2;
};
// 特化 -- 偏特化,實例化出的模板參數只要都是引用就會走這個版本
// 兩個參數偏特化為引用類型
template<class T1, class T2>
class Data<T1&, T2&>
{
public:Data() { cout << "Data<T1&, T2&>" << endl; }
private:T1 _d1;T2 _d2;
};
// 特化 -- 偏特化,還能特化成指針和引用混在一起的版本
// 實例化出的模板參數只要前一個是指針、后一個是引用就會走這個版本
template<class T1, class T2>
class Data<T1*, T2&>
{
public:Data() { cout << "Data<T1*, T2&>" << endl; }
private:T1 _d1;T2 _d2;
};
上面所有的類模板特化與類模板是同時存在的。

(3)、priority_queue中使用類模板特化
例如上一講中的內容,是需要顯示給出模板參數的:
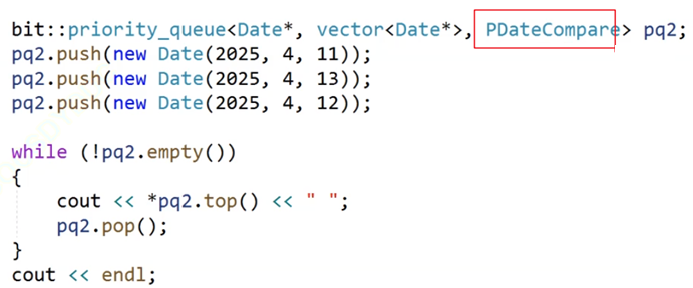
這里給的模板參數解決了日期類指針的問題,但是要是有int*等其他類型的指針呢?都去寫仿函數就太多了,內容繁瑣,而特化就能解決。
int main()
{zsy::priority_queue<Date> pq1;pq1.push({ 2025, 5, 10 });pq1.push({ 2025, 5, 19 });pq1.push({ 2025, 5, 23 });while (!pq1.empty()){cout << pq1.top() << " ";pq1.pop();}cout << endl;zsy::priority_queue<Date*> pq2;pq2.push(new Date(2025, 5, 10));pq2.push(new Date(2025, 5, 19));pq2.push(new Date(2025, 5, 23));while (!pq2.empty()){cout << *pq2.top() << " ";pq2.pop();}cout << endl;zsy::priority_queue<int*> pq3;pq3.push(new int(1));pq3.push(new int(2));pq3.push(new int(3));while (!pq3.empty()){cout << *pq3.top() << " ";pq3.pop();}cout << endl;return 0;
}
模擬實現的less仿函數:
template<class T>
class less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};
這樣寫會報錯,因為當T是指針時,const修飾的不是指針,而是指向的內容,前面講解過了解決辦法。
// 特化
template<class T>
class less<T*>
{
public:bool operator()(const T& x, const T& y){return *x < *y;}
};
這里還有一個解決辦法:
// 特化
template<class T>// 這里的T保留
class less<T*>// 意思是T是指針T*時,就按照指向的內容去比較
{
public:bool operator()(const T* const & x, const T* const & y){return *x < *y;}
};
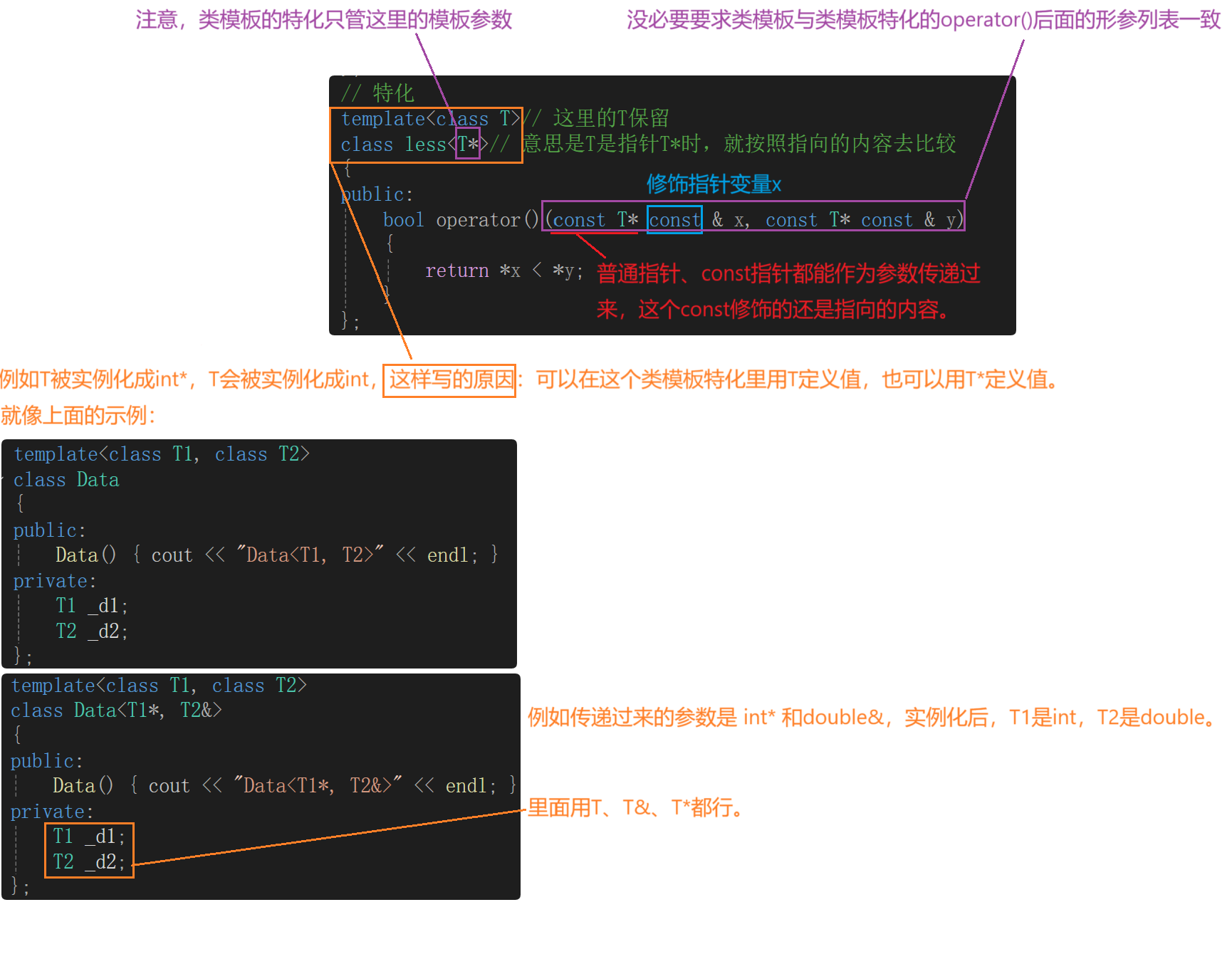
所以上一講中對于priority_queue的模擬實現的仿函數改進如下:
template<class T>
class less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};
// 特化
template<class T>
class less<T*>
{
public:bool operator()(const T* const & x, const T* const & y){return *x < *y;}
};
template<class T>
class greater
{
public:bool operator()(const T& x, const T& y){return x > y;}
};
// 特化
template<class T>
class greater<class T*>
{
public:bool operator()(const T* const& x, const T* const& y){return *x > *y;}
};
三、typename的特性
定義模板參數用關鍵字class/typename都行。最常用class,例如庫里面的模板聲明中大多都是用class定義模板參數的:

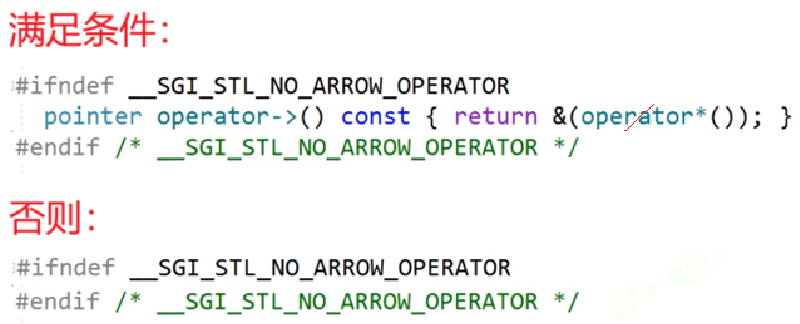
但是有一個場景下必須用typename定義:模板參數里面取內嵌類型時前面必須加typename,無論是用這個內嵌類型定義/聲明對象。
示例1,想打印一些容器。vector、list提供了迭代器但是沒有提供cout打印,我們現在想寫一個通用的函數去對它們進行打印,比如寫一個通用的打印容器的Print函數模板,但是會報編譯錯誤:
#include <iostream>
#include <list>
#include <vector>
using namespace std;
template<class Container>
void Print(const Container& con)
{Container::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
int main()
{vector<int> v = { 1, 2, 3, 4, 5 };list<int> lt = { 10, 20, 30 };Print(v);Print(lt);return 0;
}

問題所在:

前面加typename才會通過:

原因:從上往下編譯,編譯到Container::const_iterator it = con.begin();時,因為Container是模板參數,在未實例化時,編譯器不知道Container到底是什么東西,根據域作用限定符,猜測Container可能是命名空間/類,因為是從上往下編譯的,知道class后面是類型參數名,所以知道Container是個類型,故而編譯器確定Container是個類。但是編譯器不知道 :: 取的const_iterator是類型還是靜態成員變量,既然不確定是什么,那么const_iterator就是不合法的。若const_iterator是個類型,編譯就能通過,也不敢去Container里面找,因為不確定Container實例化是什么。而前面加個typename就是程序員先告訴編譯器typename后面的Container::const_iterator肯定是個類型,讓編譯先通過,等到Container實例化時編譯器再去確認Container::const_iterator具體的類型。
示例2:
雖然知道容器是vector,但是vector< T >還是沒有實例化的。所以只要記住模板參數里面取內嵌類型前加typename即可。
typename vector<T>::const_iterator it = con.begin();
#include <iostream>
#include <list>
#include <vector>
using namespace std;
template<class Container>
void Print(const Container& con)
{typename Container::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
template<class T>
void Print(const vector<T>& con)
{typename vector<T>::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
int main()
{vector<int> v = { 1, 2, 3, 4, 5 };list<int> lt = { 10, 20, 30 };Print(v);Print(lt);return 0;
}
庫里用到typename的容器:

四、模板的分離編譯
分離編譯:一個程序(項目)由若干個源文件共同實現,而每個源文件單獨編譯生成目標文件,最后將所有目標文件鏈接起來形成單一的可執行文件的過程稱為分離編譯模式。
模板的定義和聲明可以分離在同一個文件中,但是不能分離在兩個文件中,會有鏈接錯誤。
我們從簡單的聲明和定義的分離再逐漸過渡到為什么模板不支持聲明和定義分離到兩個文件進行講解。
不支持分離在.h和.cpp里。
- 簡單的聲明和定義的分離:
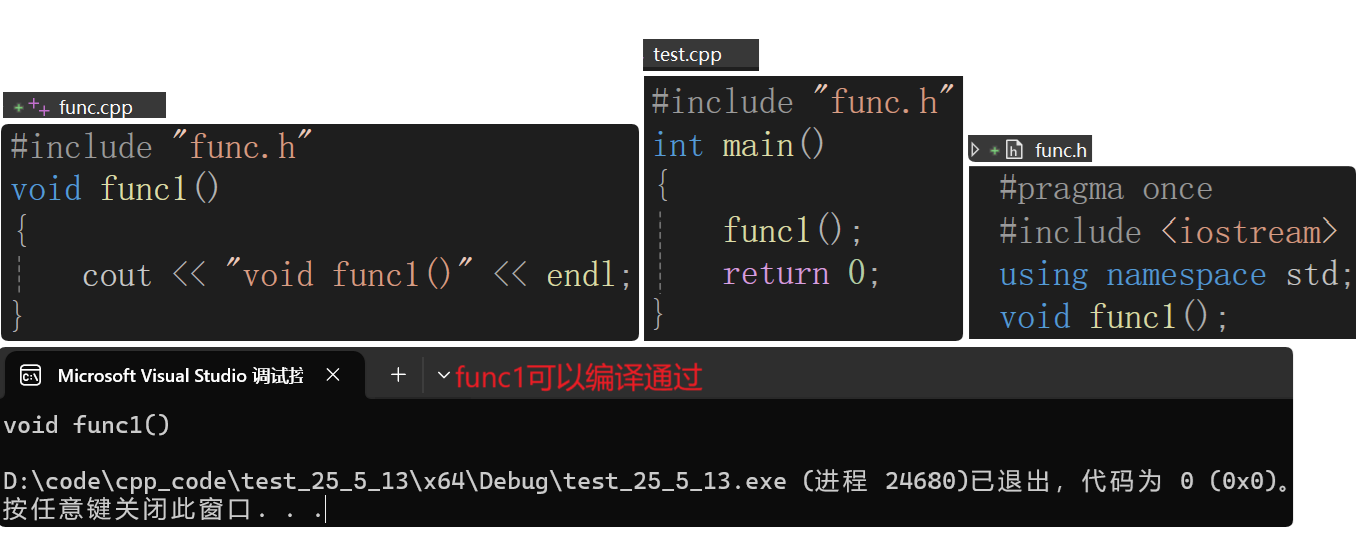
以下編譯鏈接的過程按照Linux來講:

條件編譯:#ifdef、#ifndef、#endif等。寫了一個需要跨平臺的代碼,例如分別在Windows、Linux調用,那么這個代碼中就有條件編譯。由于Windows、Linux接口不同,需要借助條件編譯跨平臺。例如:
在預處理階段,如果滿足if后面的宏,就會把這段代碼放出來,否則就不放:
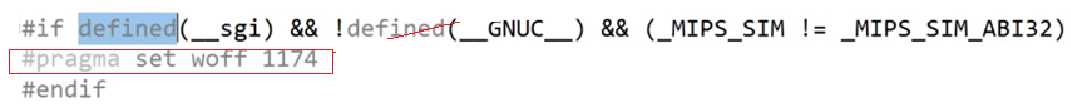
預處理期間,滿足后面的條件,代碼留下,否則就相當于把這段代碼刪去:
預處理階段:.h在func.cpp和test.cpp下分別展開,展開頭文件,相當于在新的文件中把.h文件拷貝到.cpp中,這一過程不在源文件中處理。所以編譯時就沒有.h了:

編譯后會生成匯編代碼,但是CPU看不懂匯編代碼,"匯編代碼"是一種"符號指令"級別的語言,是人們能看懂的符號,例如call、jump、add…,但是這些符號機器(CPU)看不懂,CPU(機器)只認識二進制語言0、1。所以我們還需要對符號指令進行翻譯(翻譯的例子:move指令假如叫111、add指令叫112,CPU看到112就知道是add)。所以編譯后生成的.s文件需要進行匯編(與"匯編代碼"區分),匯編是編譯鏈接中的一個步驟,是將匯編代碼轉換成二進制機器碼,CPU認識二進制機器碼,這一步驟生成.o文件。
發現除了在"預處理"階段會有.h的展開,func.h和func.cpp一起生成func.i、test.cpp和func.h一起生成test.i。其他步驟中.cpp與.cpp之間是各自生成各自的。"鏈接"是生成可執行程序,不是僅僅把它們合并在一起,而是把它們"鏈接"在一起。鏈接后,Linux下會生成a.out(具體會在學習到Linux時講解),Windows下會生成xxx.exe,a.out和xxx.exe就是可執行程序了。
鏈接錯誤通常就是沒有定義
這里報鏈接錯誤的原因是只有函數聲明,沒有函數定義。那么為什么會有這樣的問題呢?

.h在預處理階段會在func.cpp和test.cpp下分別展開,展開了之后func.i和test.i各有一份聲明:

func.i沒有問題,有func1函數的定義和聲明;但是test.i會有問題,"編譯"階段檢查語法,調用函數時,要找到它的出處,要有函數的定義,或者至少有函數的聲明。調用函數func1()時,有它的函數聲明,所以語法沒有問題。
之后要在test.s中生成匯編代碼,函數調用生成的匯編代碼是"call一個地址",形象一點就是"call func1(?)"。函數的地址類似數組的地址,數組的地址就是第一個數據的地址,函數的定義被編譯后是一串指令(好多句指令),每一句指令都會對應一個地址,第一句指令就是函數的地址。所以call這個函數的地址就是,先到一個jump指令,再跳轉過去執行函數,再函數建立棧幀…
之前除預處理階段各個.cpp之間不會交互,只有在鏈接階段交互。
若.h里有這個函數的定義,預處理.cpp文件包了定義,有了定義就有這個函數的地址,函數定義被編譯成一段指令,取第一句指令填寫到"call func1(?)"中的?上,指令完整,即有了定義那么函數地址在編譯階段就能確定。但是示例中的情況是沒有函數定義,只有函數聲明,首先語法沒有問題"編譯"直接通過了,由于只有函數聲明,所以不可能有函數地址,那么(定義)地址在哪里呢?在其他文件。這時會在"鏈接"階段確定地址:利用func1函數名去其他文件找,為了更快速找到,每個.o文件都會有對應的一個符號表,每個符號表會把對應.o文件中的函數及其地址填進來,這樣就不用在文件里找了,直接拿func1函數名去符號表找func1地址0x00112233,填在call func1(?)里call func1(0x00112233),這句指令才算完整。所以"鏈接"階段不止把多個.o鏈接到一起,還有本段落的過程。然后就生成了可執行程序。
所以上面的鏈接錯誤的原因:拿func1函數名找不到函數的地址,沒有定義所以沒有函數的地址,所以鏈接錯誤通常就是沒有定義。
順便提一句編譯好的動態庫,平時編譯鏈接程序就直接生成的是可執行程序,Windows下可以設置編譯鏈接后生成的是動態庫。比如一個多人寫的項目,有多個動態庫,只走鏈接的部分,可以加快編譯的速度。(Linux講解)
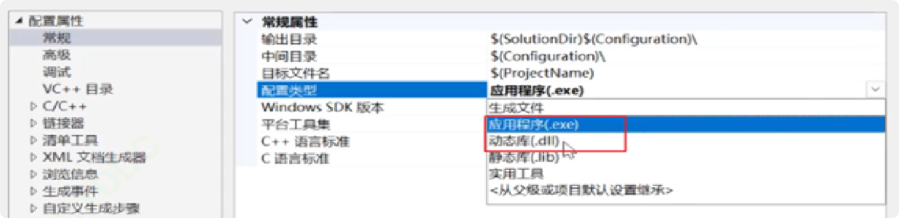
- 為什么模板不能聲明和定義分離在.h和.cpp?
若聲明和定義不分離,程序沒問題;若聲明和定義分離在.h文件是沒問題的,.cpp包了.h既有聲明,又有定義;
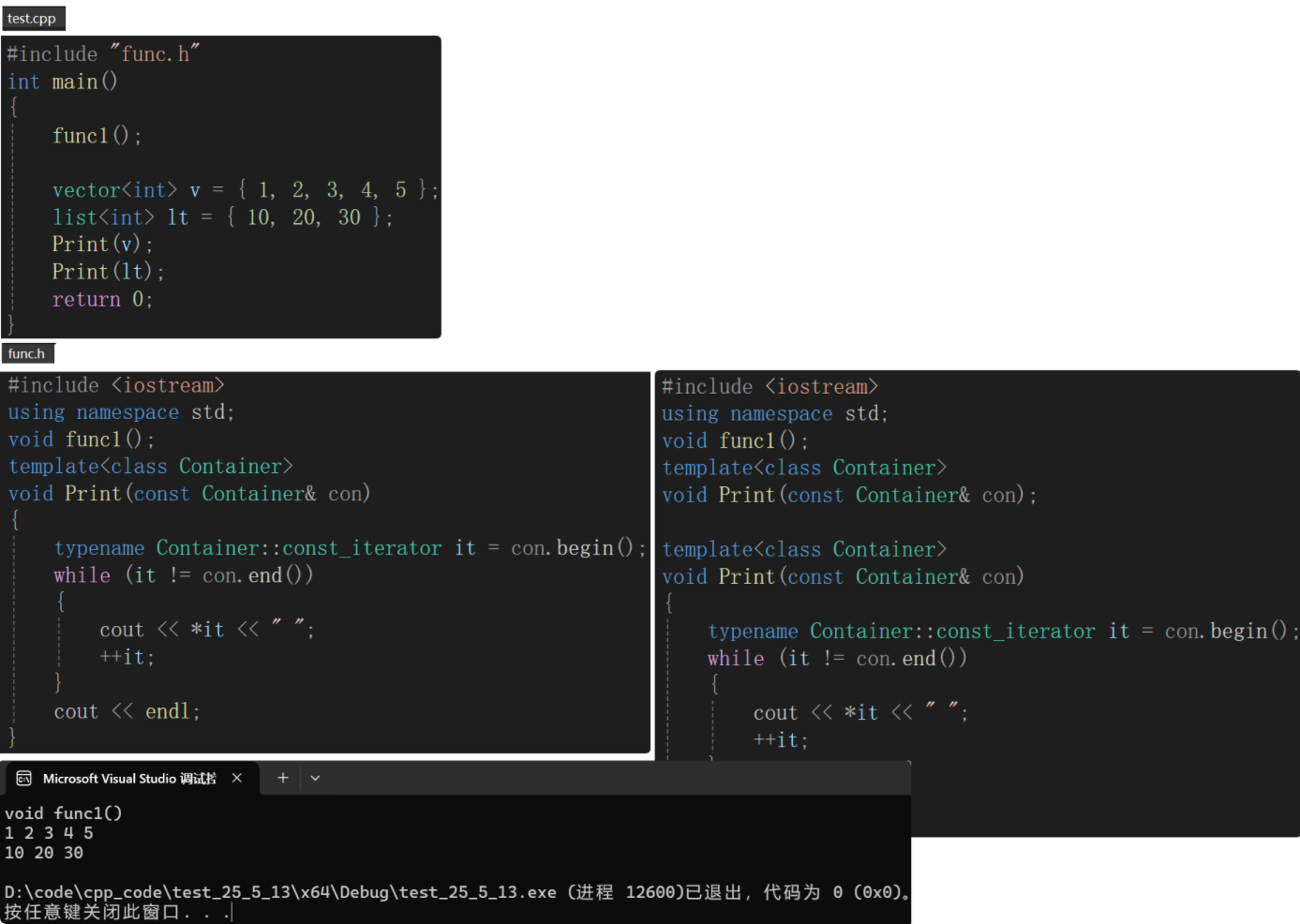
若聲明和定義分離在兩個文件,會出現鏈接錯誤,即找不到定義。func1鏈接錯誤是因為沒有定義,但是為什么定義了Print模板還報鏈接錯誤?—— Contianer沒有實例化。模板不能直接調用,是需要實例化模板參數Container的。
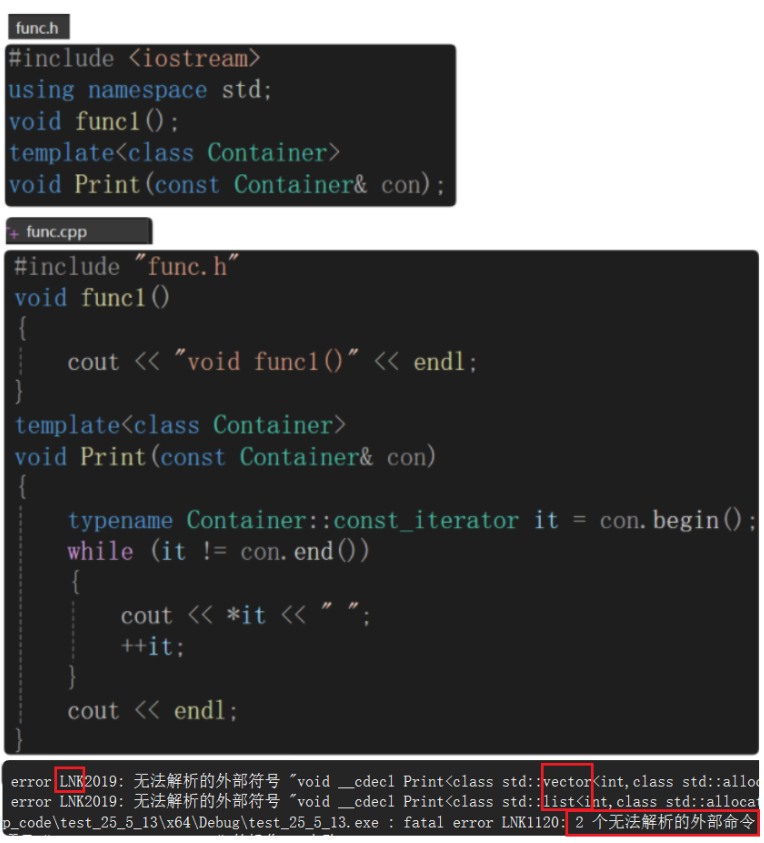
調用的地方Print()語法沒有問題,出處是Print的聲明,編譯通過。
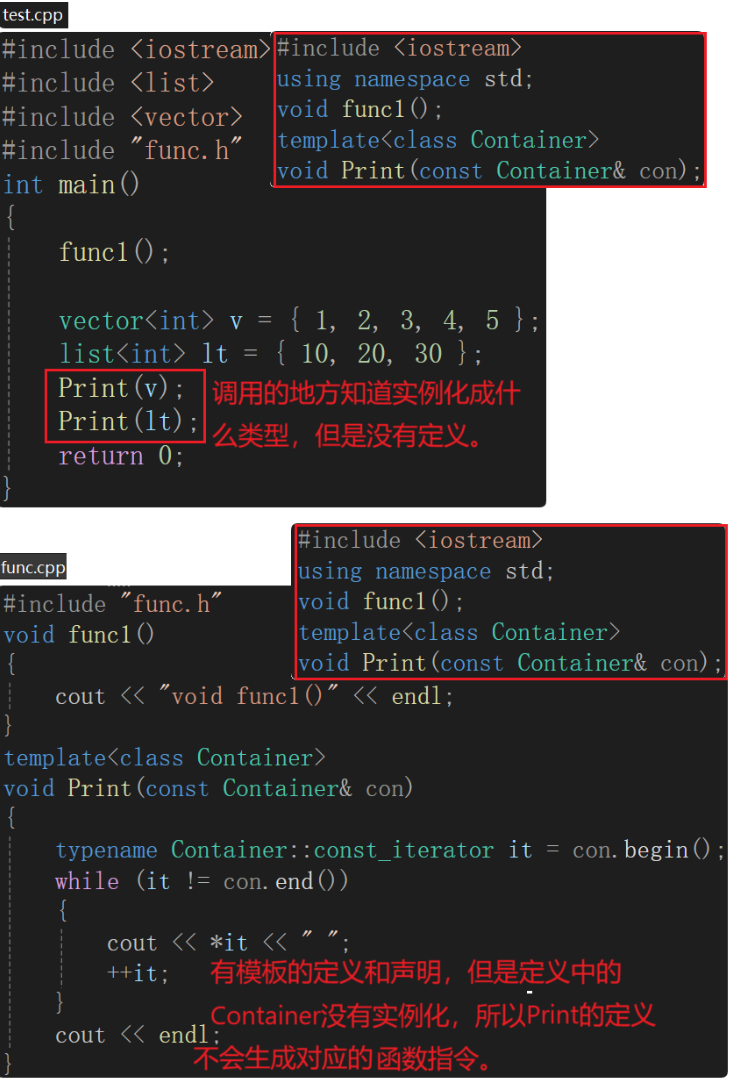
由于鏈接之前不會交互不會有問題,而在鏈接階段會交互,用Print函數名去找定義會找不到,因為Print函數的定義沒有實例化,在鏈接階段出現的錯誤,即鏈接錯誤。
解決方案:
- 方法一:顯示實例化
上面出現鏈接錯誤的原因就是Print函數的定義中的模板參數Contianer沒有實例化,那就告訴編譯器模板參數Container實例化為vector< int >
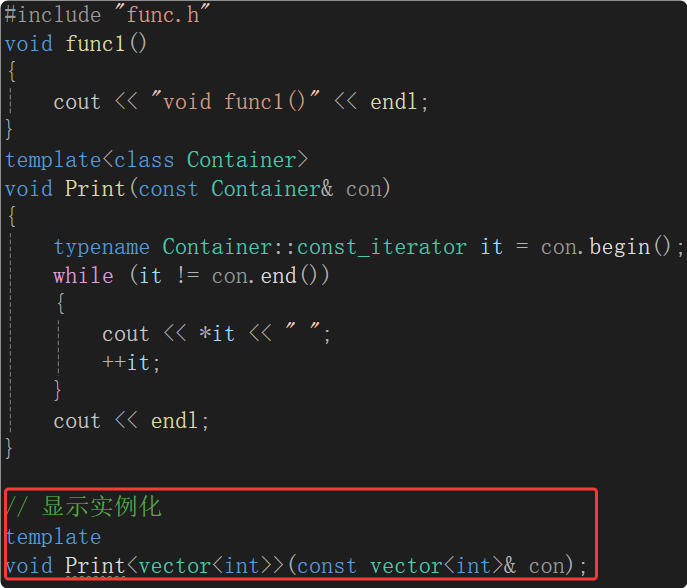
只會報一個鏈接錯誤了:

說明函數調用 Print(v); 找到對應的定義了,能鏈接上。
顯示實例化,實例化生成一份Container為vector< int >的Print,知道了Print的實例化定義,編譯生成它的地址,鏈接時在test.o的符號表里找Print<vector< int >>地址,call 一個地址。所以模板的定義和聲明可以分離到兩個文件中,不過實際上不會這么做的,太麻煩了,還有其他的類型就還需要顯示實例化。
因此,"顯示實例化"這種方式可行但不可取。
- 方法二,正確解決辦法:模板直接在.h里定義,或者定義和聲明在.h/.hpp里,不要分離到.cpp里。
為什么這樣可以解決問題?
首先明確什么情況下需要鏈接?.h只有聲明,哪個.cpp包含了這個.h在預處理后也只包了聲明,編譯階段語法沒有問題,但是(沒有實例化)就沒辦法生成對應的指令,這時需要鏈接。
若.h就有模板定義,哪個.cpp包含了這個.h就會在預處理后也有定義,那么在調用的地方就知道實例化成什么,實例化后模板定義經過編譯直接生成指令,這樣編譯階段就有了地址,這時就不用鏈接確認地址了。所以沒有鏈接錯誤,因為根本不用鏈接、不用到符號表里找。
看一個list的源代碼。模板沒有.cpp,list是個模板,模板只會聲明和定義都在.h里:

短小函數直接定義在類里,成為內聯:

長一點的函數,在當前文件做了聲明和定義的分離:
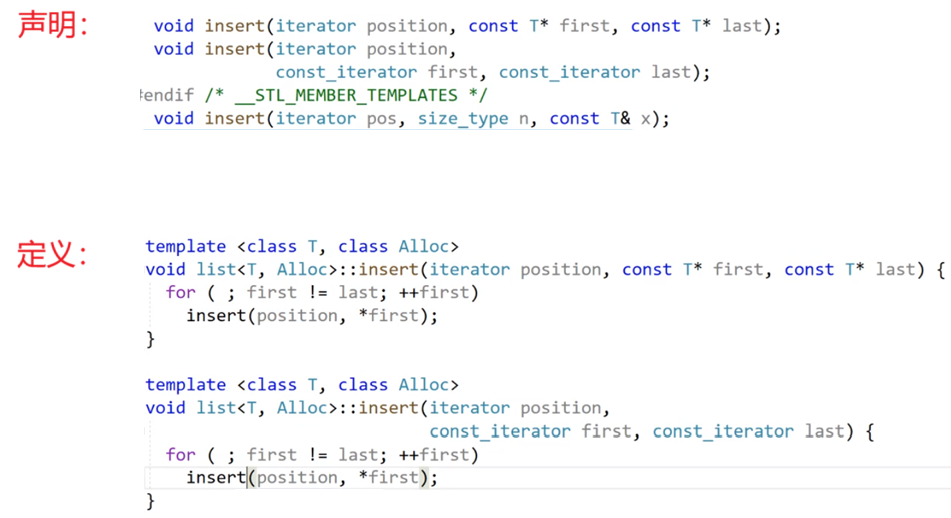
普通的函數和類都需要寫.h、.cpp聲明和定義的分離;模板就只定義在.h,后綴是.h,還有一些模板后綴是.hpp,就是.h和.cpp的合體,把聲明和定義放在了一起,例如,boost庫里好多模板就是這樣的:
弄清楚:
1、模板的聲明和定義分離在.h、.cpp為什么會報錯?
2、解決方案?有兩種:(1)、顯示實例化 (2)、模板直接定義在.h
五、模板的優缺點
【優點】
- 模板復用了代碼,節省資源,更快的迭代開發,C++的標準模板庫(STL)因此而產生。
- 增強了代碼的靈活性。
【缺陷】
- 模板會導致代碼膨脹問題,也會導致編譯時間變長。
- 出現一處模板編譯錯誤時,可能就會導致一堆錯誤。錯誤信息非常凌亂,不易定位錯誤。
代碼膨脹避免不了,比如寫了一個vector模板有100行代碼,實例化成多個不同類型時,就會導致有更多代碼。


(HTML資源交互、網頁管理、搜索引擎))
)







)



系統)



