課程原地址:
https://github.com/WenjieDu/PyPOTS(Package地址)
https://github.com/WenjieDu/BrewPOTS/tree/datawhale/202505_datawhale(Tutorial地址)?
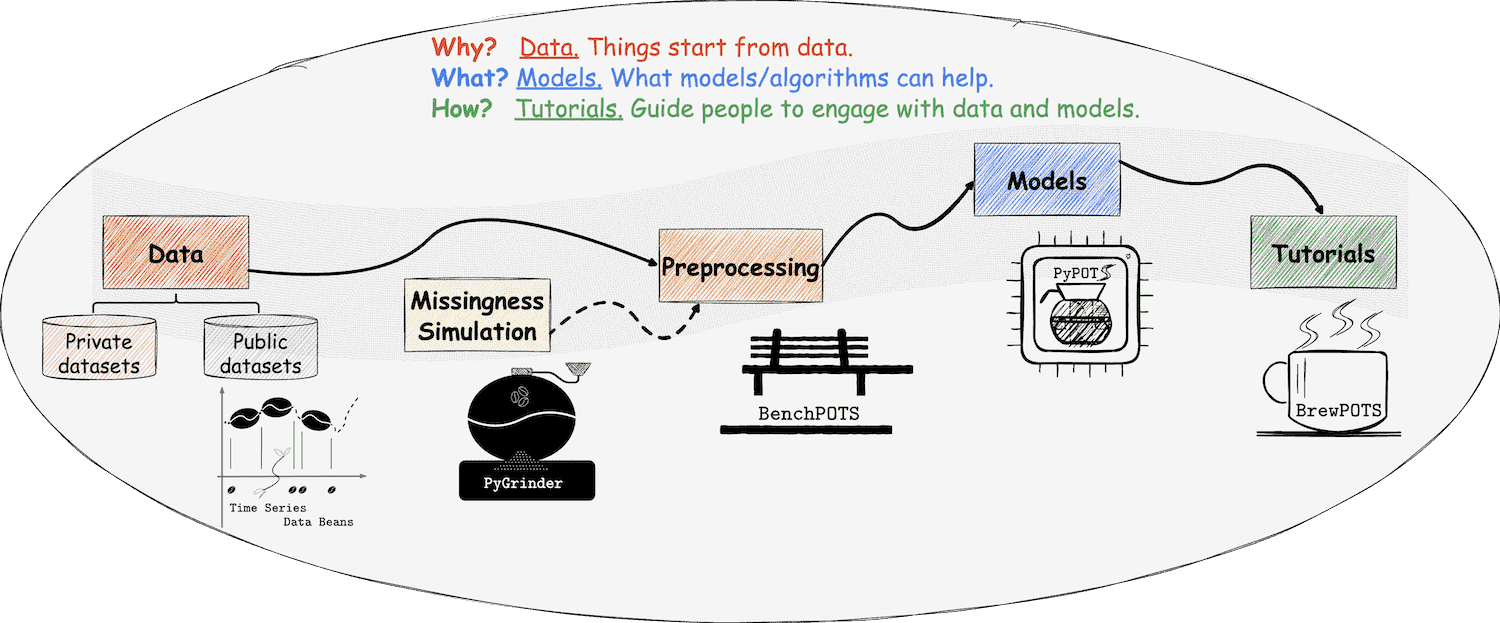
2.1 PyPOTS簡介
PyPOTS 是一個專為處理部分觀測時間序列(Partially-Observed Time Series, 簡稱 POTS)而設計的開源 Python 工具箱。在現實世界中,由于傳感器故障、通信錯誤或其他不可預見的原因,時間序列數據中常常存在缺失值。這些缺失值會影響數據分析和建模的準確性。PyPOTS 的目標是為工程師和研究人員提供一個便捷的工具,使他們能夠專注于核心問題,而無需過多擔心數據中的缺失部分。工程師和研究人員可以通過PyPOTS輕松地處理POTS數據建模問題, 此外PyPOTS會持續不斷的更新關于部分觀測多變量時間序列的經典算法和先進算法. 除此之外, PyPOTS還提供了統一的應用程序接口,詳細的算法學習指南和應用示例。
2.2 PyPOTS 支持的核心任務
PyPOTS 針對帶有缺失值的多變量時間序列數據,提供了五大類核心任務支持,幾乎覆蓋了時間序列數據挖掘的各類典型應用場景。這些任務背后都配備了經過驗證的高質量算法,涵蓋傳統方法、深度學習模型以及概率圖模型等。
1. 🧩 缺失值填補(Imputation)
這是 PyPOTS 最重要的功能之一,主要目標是在數據中存在缺失的情況下,最大程度恢復原始信號。PyPOTS 實現了超過?12 種填補算法,既有傳統方法,也有現代深度學習模型:
-
傳統方法:
- 前向填充(Forward Filling)
- 后向填充(Backward Filling)
- 線性插值(Linear Interpolation)
-
深度學習方法:
- SAITS(Self-Attention based Imputation for Time Series):PyPOTS 自主實現的 Transformer 風格模型;
- BRITS:基于雙向 RNN 的填補方法,兼顧因果一致性;
- GRU-D:引入時間衰減機制,特別適合處理醫療場景;
- MRNN、CSDI、Transformer-Denoising Autoencoder?等
-
概率模型:
- BTTF(Bayesian Temporal Tensor Factorization):使用貝葉斯推斷的張量分解方法,適合建模數據不確定性。
這些方法可根據數據特性靈活選擇,并通過統一接口進行調用和評估。
2. 🔮 預測(Forecasting)
PyPOTS 支持基于不完整觀測值的序列預測任務。在訓練時可以同時學習時間依賴性和缺失機制。支持的模型主要有:
- Impute-then-Forecast?方法鏈:先填補再進行預測(支持組合 SAITS+LSTM 等);
- 端到端預測模型:如 Transformer 與 GRU 基模型;
- 與 Benchmark 模塊結合,支持將任何模型進行標準化評估。
目前框架內已集成了多種典型預測結構,并可與填補模塊無縫連接。
3. 🏷? 分類(Classification)
對于需要將時間序列分為不同類別的任務(如疾病分類、用戶行為識別等),PyPOTS 提供了適配部分觀測數據的時間序列分類器:
- 基于 RNN、Transformer 的深度分類模型;
- 可結合填補模塊預處理后的數據進行分類;
- 支持多任務學習,將分類與預測或填補結合。
目前至少支持?5 種深度分類結構,同時提供高擴展性,便于接入外部分類器。
4. 🧭 聚類(Clustering)
聚類任務在探索性分析中非常重要,PyPOTS 提供了處理缺失值時間序列聚類的支持:
- 填補 + 聚類:先使用 SAITS 等模型填補缺失,再進行 K-Means、DBSCAN 等聚類;
- 特征提取 + 聚類:通過 Transformer 等模型提取潛在特征后進行聚類;
- 支持對比學習風格的時間序列表示學習,用于后續聚類。
該模塊提供標準化聚類評估指標,如 Silhouette Score、NMI 等。
5. ?? 異常檢測(Anomaly Detection)
異常檢測主要用于識別時間序列中不符合正常模式的行為,PyPOTS 可處理帶缺失的異常檢測任務:
- 填補 + Reconstruction-Based 方法:如使用自動編碼器重構序列,比較原始與預測誤差;
- 基于統計的方法:結合滑動窗口與動態閾值;
- Transformer-based 模型:學習時間依賴與異常模式,例如結合 CSDI 等模型進行異常點估計;
- 可與 BenchPOTS 一起評估各類異常檢測算法的性能。




)
![[FA1C4] 博客鏈接](http://pic.xiahunao.cn/[FA1C4] 博客鏈接)








)




