DeepResearcher:通過強化學習在真實環境中擴展深度研究
- 一、引言
- 二、技術原理
- (一)強化學習與深度研究代理
- (二)認知行為的出現
- (三)模型架構
- 三、實戰運行方式
- (一)環境搭建
- (二)啟動Ray
- (三)運行后端處理器
- (四)模型訓練
- (五)模型評估
- 四、重要邏輯代碼
- (一)模型訓練代碼
- (二)后端處理器代碼
- 五、執行報錯及解決方法
- (一)環境依賴問題
- (二)Ray啟動失敗
- (三)后端處理器連接失敗
- 六、相關論文信息
- 七、總結
一、引言
在當今快速發展的科技時代,人工智能(AI)和機器學習(ML)技術正在不斷改變我們的生活和工作方式。其中,自然語言處理(NLP)領域的發展尤為引人注目。隨著大型語言模型(LLMs)的出現,如GPT系列、LLaMA等,我們看到了AI在理解和生成人類語言方面的巨大潛力。然而,這些模型在實際應用中仍然面臨一些挑戰,尤其是在處理復雜的、需要多步驟推理和信息檢索的任務時。DeepResearcher項目正是為了解決這些問題而誕生的。
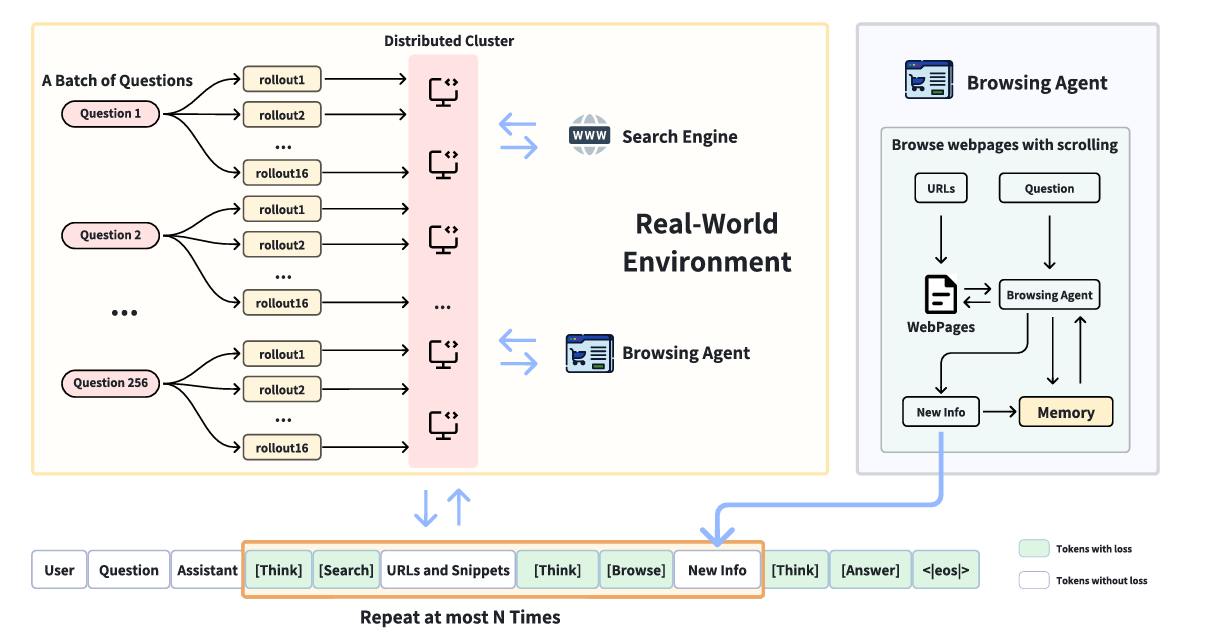
DeepResearcher是一個開創性的框架,旨在通過強化學習(RL)在真實世界環境中訓練基于LLM的深度研究代理。這個項目的目標是讓AI代理能夠像人類研究人員一樣,通過互聯網搜索、信息驗證和自我反思來完成復雜的任務。本文將詳細介紹DeepResearcher項目的各個方面,包括其技術原理、實戰運行方式、重要邏輯代碼以及可能遇到的問題和解決方法。
二、技術原理
(一)強化學習與深度研究代理
強化學習是一種讓智能體通過與環境的交互來學習最優行為策略的方法。在DeepResearcher中,強化學習被用來訓練深度研究代理,使其能夠在真實世界環境中進行有效的信息檢索和任務完成。具體來說,代理通過與搜索引擎交互,獲取信息,并根據反饋調整自己的行為策略。
(二)認知行為的出現
DeepResearcher的一個重要特點是它能夠展示出一些類似人類的認知行為。這些行為包括:
- 制定計劃:代理能夠根據任務目標制定出合理的行動步驟。
- 信息交叉驗證:從多個來源獲取信息,并驗證信息的準確性。
- 自我反思:在任務執行過程中,代理能夠根據結果反思自己的行為,并調整策略。
- 誠實回答:當無法找到確切答案時,代理能夠誠實地表示不知道,而不是給出錯誤的答案。
這些行為的出現表明,通過強化學習訓練的代理不僅能夠完成任務,還能夠以一種更加智能和靈活的方式進行操作。
(三)模型架構
DeepResearcher目前提供了7B參數的模型版本,名為DeepResearcher-7b。這個模型基于Transformer架構,并通過強化學習進行了微調,使其能夠更好地適應復雜的任務需求。
三、實戰運行方式
(一)環境搭建
在開始使用DeepResearcher之前,我們需要先搭建好運行環境。以下是詳細的步驟:
-
克隆項目倉庫:
git clone https://github.com/GAIR-NLP/DeepResearcher.git -
創建并激活虛擬環境:
conda create -n deepresearcher python=3.10 conda activate deepresearcher -
安裝依賴:
cd DeepResearcher pip3 install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu124 pip3 install flash-attn --no-build-isolation pip3 install -e . pip3 install -r requirements.txt
(二)啟動Ray
Ray是一個用于分布式計算的框架,DeepResearcher使用它來進行模型訓練。在開始訓練之前,我們需要啟動Ray。以下是啟動Ray的步驟:
-
設置環境變量:
export PET_NODE_RANK=0 -
啟動Ray:
ray start --head
(三)運行后端處理器
后端處理器是DeepResearcher與搜索引擎交互的關鍵組件。以下是運行后端處理器的步驟:
-
修改配置文件:
- 修改
./scrl/handler/config.yaml中的serper_api_key或azure_bing_search_subscription_key和search_engine。 - 在
./scrl/handler/server_handler.py中添加qwen-plusAPI密鑰。
- 修改
-
啟動服務器處理器:
python ./scrl/handler/server_handler.py -
啟動處理器:
python ./scrl/handler/handler.py
(四)模型訓練
模型訓練是DeepResearcher的核心步驟。以下是訓練模型的步驟:
- 準備訓練數據:將訓練數據放置在指定目錄下。
- 運行訓練腳本:使用以下命令啟動訓練:
python train.py
(五)模型評估
模型評估用于驗證訓練結果的有效性。以下是評估模型的步驟:
-
生成rollout文件:
- 在訓練完成后,您可以在
./outputs/{project_name}/{experiment_name}/rollout/rollout_step_0.json中找到rollout文件。 - 將該文件重命名并復制到
./evaluate/{experiment_name}_result.json。
- 在訓練完成后,您可以在
-
運行評估腳本:
python ./evaluate/cacluate_metrics.py {experiment_name} -
查看評估結果:評估結果將保存在
./evaluate/{experiment_name}_score.json中。
四、重要邏輯代碼
(一)模型訓練代碼
以下是模型訓練的核心代碼片段:
# train.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from deepresearcher import DeepResearcherAgentdef train_model():# 加載預訓練模型和分詞器model_name = "DeepResearcher-7b"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)# 初始化深度研究代理agent = DeepResearcherAgent(model, tokenizer)# 加載訓練數據train_data = load_data("train.json")# 訓練模型agent.train(train_data)if __name__ == "__main__":train_model()
(二)后端處理器代碼
以下是后端處理器的核心代碼片段:
# server_handler.py
from deepresearcher.handler import SearchHandlerdef start_server_handler():# 初始化搜索引擎處理器handler = SearchHandler(api_key="your_api_key", search_engine="your_search_engine")# 啟動服務器handler.start_server()if __name__ == "__main__":start_server_handler()
五、執行報錯及解決方法
(一)環境依賴問題
問題描述:在安裝依賴時,可能會遇到某些包無法安裝的問題。
解決方法:
- 確保您的網絡連接正常,能夠訪問PyPI和conda倉庫。
- 如果某些包無法安裝,可以嘗試使用
--pre選項安裝預發布版本,或者從源代碼安裝。
(二)Ray啟動失敗
問題描述:在啟動Ray時,可能會遇到錯誤。
解決方法:
- 確保您已經正確設置了
PET_NODE_RANK環境變量。 - 如果您使用的是多節點環境,請確保所有節點的配置正確,并且網絡連接正常。
(三)后端處理器連接失敗
問題描述:在運行后端處理器時,可能會遇到連接搜索引擎失敗的問題。
解決方法:
- 確保您已經正確配置了API密鑰和搜索引擎。
- 檢查網絡連接,確保您的服務器能夠訪問搜索引擎的API。
六、相關論文信息
DeepResearcher項目的相關論文是《DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments》。以下是論文的關鍵信息:
- 作者:Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu
- 年份:2025
- 論文鏈接:https://arxiv.org/abs/2504.03160
論文詳細介紹了DeepResearcher的設計原理、技術實現和實驗結果。通過閱讀論文,您可以更深入地了解該項目的背景、目標和貢獻。
七、總結
DeepResearcher項目通過強化學習在真實世界環境中訓練基于LLM的深度研究代理,展示了AI在復雜任務處理方面的巨大潛力。通過本文的介紹,您應該對該項目的技術原理、實戰運行方式、重要邏輯代碼以及可能遇到的問題和解決方法有了全面的了解。希望DeepResearcher能夠為您的研究和開發工作提供有價值的參考和幫助。
注意:本文中的代碼片段和命令僅為示例,實際運行時可能需要根據項目文檔和實際情況進行調整。在使用DeepResearcher項目時,請務必仔細閱讀項目文檔,以確保正確安裝和使用。


)
![[FA1C4] 博客鏈接](http://pic.xiahunao.cn/[FA1C4] 博客鏈接)








)






