當你在凌晨三點收到告警,發現Pod在崩潰循環中掙扎時,如何快速定位問題?本文將為你梳理一套生產環境通用的Pod排錯流程,并附上救火隊員必備的實用命令清單!
一、5分鐘快速定位:四步鎖定問題方向
步驟1:查看Pod狀態特征
kubectl get pod -o wide
# 重點觀察STATUS和RESTARTS列
常見狀態解析表:
| 狀態 | 含義 | 緊急程度 |
|---|---|---|
| CrashLoopBackOff | 容器持續崩潰重啟 | 🔴 立刻處理 |
| ImagePullBackOff | 鏡像拉取失敗 | 🔴 立刻處理 |
| Pending | 調度失敗 | 🟡 30分鐘內處理 |
| Evicted | 節點資源不足被驅逐 | 🟡 30分鐘內處理 |
步驟2:查看事件日志(90%問題可定位)
kubectl describe pod <pod-name>
# 重點關注Events部分的Warning事件
步驟3:查看容器日志
# 查看標準輸出日志(適合Java/Python應用)
kubectl logs <pod-name> --tail=100# 查看多容器中的指定容器日志
kubectl logs <pod-name> -c <container-name># 實時追蹤日志流
kubectl logs <pod-name> -f
步驟4:快速進入調試模式
# 進入容器Shell(需容器有shell環境)
kubectl exec -it <pod-name> -- sh# 調試無Shell容器(使用臨時調試鏡像)
kubectl debug -it <pod-name> --image=nicolaka/netshoot
二、八大經典故障場景與破解之道
場景1:鏡像拉取失敗(ImagePullBackOff)
👉?排查命令:
# 查看鏡像地址是否正確
kubectl get pod <pod-name> -o jsonpath='{.spec.containers[].image}'# 手動模擬拉取測試
docker pull <image-url>
場景2:OOM內存溢出(Exit Code 137)
👉?解決方案:
resources:limits:memory: "512Mi" # 根據監控數據調整requests:memory: "256Mi"
場景3:存活探針配置不當
👉?調優示例:
livenessProbe:httpGet:path: /healthport: 8080initialDelaySeconds: 30 # 避免冷啟動誤殺periodSeconds: 5failureThreshold: 3 # 允許偶發故障
場景4:節點資源不足(Pending狀態)
👉?診斷命令:
kubectl describe node | grep -A 10 Allocated
# 查看CPU/Memory/GPU分配情況
場景5:持久卷掛載失敗
👉?排查流程:
- 檢查PVC狀態?
kubectl get pvc - 驗證StorageClass配置
- 查看Volume錯誤詳情?
kubectl describe pv <pv-name>
場景6:服務依賴故障
👉?網絡連通性測試:
kubectl exec <pod-name> -- nc -zv mysql-service 3306
kubectl exec <pod-name> -- curl -I http://redis-service:6379
場景7:配置文件錯誤(ConfigMap/Secret)
👉?對比檢查:
# 查看容器內掛載的配置文件
kubectl exec <pod-name> -- cat /etc/config/app.properties# 對比集群中的ConfigMap
kubectl get configmap <cm-name> -o yaml
場景8:內核不兼容(CreateContainerError)
👉?典型場景:
- 容器要求內核版本 > 5.x
- Seccomp安全策略限制
- 缺失內核模塊(如nfs.ko)
三、生產環境排錯工具箱
1. 可視化神器推薦
- K9s:終端可視化儀表盤
brew install k9s && k9s - Lens:跨平臺桌面管理工具
- Octant:Web版集群瀏覽器
2. 高級診斷命令
# 查看容器啟動耗時
kubectl get pod <pod-name> -o jsonpath='{.status.containerStatuses[].state.waiting.reason}'# 檢查PID 1進程狀態
kubectl exec <pod-name> -- ps aux# 抓取容器內網絡流量
kubectl debug <pod-name> --image=nicolaka/netshoot -- tcpdump -i eth0 -w /tmp/dump.pcap
3. 監控告警集成
- Prometheus + Grafana看板指標:
# 容器重啟次數統計 sum(kube_pod_container_status_restarts_total{namespace="$namespace"}) by (pod) - Alertmanager規則示例:
- alert: PodCrashLoopexpr: kube_pod_container_status_restarts_total > 3for: 5m
四、排錯流程圖(保存到手機隨時查看)
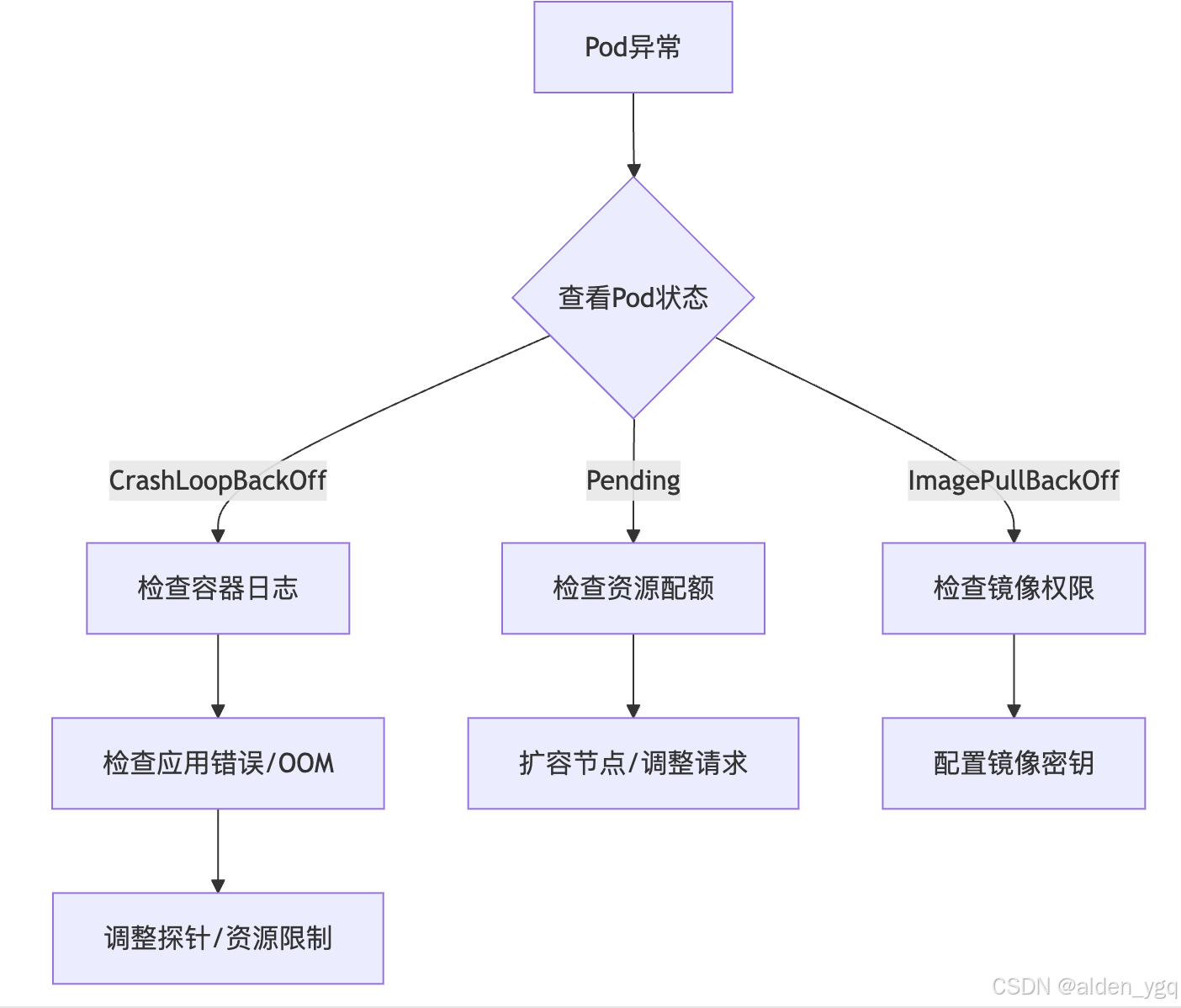
五、防患于未然:三大預防措施
-
混沌工程演練
# 使用Chaos Mesh模擬Pod故障 kubectl apply -f network-delay-experiment.yaml -
健康檢查規范
- 所有服務必須配置readinessProbe/livenessProbe
- 關鍵服務增加startupProbe
-
資源監控基線
# 設置HPA自動擴容 kubectl autoscale deployment myapp --cpu-percent=80 --min=2 --max=10
結語
面對Pod故障,記住三個黃金法則:
- 先恢復再排查?- 優先通過副本數保障服務可用
- 日志是破案線索?- 善用日志收集系統(如ELK)
- 預防優于救火?- 建立完善的監控告警體系
現在,立刻執行以下檢查:
# 檢查集群中所有異常Pod
kubectl get pods --field-selector=status.phase!=Running -A
記住:每個故障都是改進的機會,完善的故障復盤機制能讓你的系統越挫越強!
)




)



)



——版本體系)





