用于視覺任務的判別性和域不變子空間對齊
作者:Samaneh Rezaei,Jafar Tahmoresnezhad
文章于2018年12月4日收到,2019年5月24日被接受,2019年6月3日在線發表于Iran Journal of Computer Science期刊,DOI: 10.1007/s42044-019-00037-y,? Springer Nature Switzerland AG 2019
摘要
遷移學習和域適應是解決訓練集(源域)和測試集(目標域)分布不同問題的有效方案。在本文中,我們研究了無監督域適應問題,即目標樣本沒有標簽,而源域樣本標簽完整。我們通過尋找不同的轉換矩陣,將源域和目標域都轉換到不相交的子空間中,使得轉換空間中每個目標樣本的分布與源樣本相似。此外,通過非參數準則(最大平均差異,MMD)最小化轉換后的源域和目標域之間的邊際和條件概率差異。因此,利用類間最大化和類內最小化來區分源域中的不同類別。另外,通過樣本標簽保留源數據和目標數據的局部信息,包括數據的幾何結構。我們通過各種視覺基準實驗驗證了所提方法的性能。在三個標準基準測試中,我們所提方法的平均準確率達到70.63%。與其他最先進的域適應方法相比,結果證明我們的方法性能更優,提升了22.9%。
關鍵詞:無監督域適應;全局適應;局部適應;獨特轉換;最大平均差異
1 引言
機器學習(ML)算法在有標簽的訓練數據上訓練分類模型,以對未知的測試數據進行標注。當訓練數據量充足且訓練數據和測試數據的分布相似時,這些算法表現出較高的性能。然而,在視覺分類任務中,由于相機位置和角度以及圖像統計信息的差異,獲取足夠的有標簽數據較為困難。這種差異在視覺應用中被稱為分布差異、域轉移或跨域問題。因此,用第一組圖像訓練的ML分類器在預測第二組圖像的標簽時表現不佳。
解決跨域問題的一種簡單方法是手動標注樣本,重新訓練分類器,但在大多數情況下,這既耗費人力又成本高昂。域適應是克服跨域問題的一種新解決方案,旨在減小訓練數據集和測試數據集之間的分布差異,以提高模型性能。根據目標域中是否存在有標簽數據,域適應可分為半監督問題和無監督問題。在半監督問題中,目標域有少量有標簽數據,而源域數據標簽完整;在無監督問題中,源域數據標簽完整,目標域數據則完全沒有標簽。在大多數實際視覺問題中,無法獲取目標域的有標簽數據,因此,本文重點研究無監督域適應(DA)。
DA方法遵循三種策略。基于模型的方法將基于源域模型學習到的參數適配到目標域;基于實例的方法對與目標域分布最相似的源樣本重新加權;基于特征的方法則改變域的特征空間,使源域和目標域更加接近。
基于特征的方法分為數據對齊和子空間對齊兩類。數據對齊方法尋找統一的投影矩陣,將源域和目標域轉換到共享子空間中,以降低域間的分布差異。這些方法利用源域和目標域的共享特征,找到分布差異最小的公共子空間。另一類方法則使用共享特征和特定域特征,為每個域尋找統一的投影矩陣。
在本文中,我們提出了一種子空間對齊方法,即用于視覺域的判別性和不變子空間對齊(DISA),它在保留數據幾何和統計信息的同時,對源域和目標域進行適配。DISA通過統計和幾何適配,為每個域找到統一的獨立子空間:(1)在統計適配中,DISA通過一種流行的非參數方法——最大平均差異(MMD),減小源域和目標域之間的邊際和條件分布差異;(2)此外,利用統計信息增加不同類別之間的可分性和決策區域,減小類內距離,增大類間距離;(3)在幾何適配中,DISA利用類和域流形信息提高不同類別之間的判別力。通過縮小具有局部結構和相同標簽的樣本之間的距離,DISA適配源域和目標域的幾何分布和判別結構。
我們在32個跨域視覺分類任務上的結果表明,DISA通過同時適配幾何和統計分布,優于其他最先進的域適應方法。
本文的其余部分安排如下:第2節回顧近年來發表的DA領域相關工作;第3節介紹我們提出的方法;第4節討論實驗及結果;第5節給出結論和未來工作方向。
2 相關工作
基于特征的方法作為DA的一個廣泛類別,將數據的原始特征空間轉換為潛在特征空間,從而減小源域和目標域之間的分布差異。在本文中,我們關注具有數據對齊和子空間對齊趨勢的基于特征的方法。
視覺域適應(VDA)是一種數據對齊方法,它尋找一個共同的潛在子空間,共同減小源域和目標域之間的邊際和條件分布差異。VDA使用域不變聚類來最大化類間距離,并區分不同類別。然而,VDA忽略了在潛在子空間中保留數據的幾何屬性。
Yong等人提出了低秩和稀疏表示(LRSR),以找到一個嵌入子空間,在該子空間中每個目標樣本可以由源域樣本線性重構。在LRSR中,源域或目標域中的每個樣本都可以由其鄰域重構。因此,當源域和目標域轉換到具有相同分布的潛在子空間時,可以使用源域中的相同鄰域來重構數據,而不是目標樣本的鄰域。通過這種方式,LRSR使用具有低秩和稀疏約束的重構矩陣和一個誤差矩陣來避免負遷移。然而,LRSR并沒有最小化源域和目標域之間的分布差異。緊密且可判別域適應(CDDA)尋找一個共同空間,在該空間中邊際和條件概率分布差異都減小,并且類間樣本相互排斥。魯棒數據結構對齊緊密且可判別域適應(RSA - CDDA)改進了CDDA,在統一框架中使用具有低秩和稀疏約束的重構矩陣,用源域重構目標域。Liu等人提出了耦合局部 - 全局適應(CLGA),通過全局和局部適應來適應源域和目標域之間的分布轉移。CLGA在全局適應中,使用MMD減小源域和目標域之間的邊際和條件分布差異;在局部適應中,構建圖結構,利用域的標簽和流形結構。最后,將局部和全局適應表述為一個統一的優化問題。
聯合幾何和統計對齊(JGSA)是一種子空間對齊方法,旨在通過利用共享特征和特定域特征,為每個域找到統一的子空間。JGSA在保留源域信息的同時,減小嵌入子空間之間的邊際和條件概率差異。盡管JGSA保留了源樣本的信息,但在幾何分布適應過程中沒有使用源標簽。子空間分布對齊(SDA)旨在通過主成分分析(PCA)將源域和目標域轉換到各自的特征空間。PCA改變新子空間中每個維度的方差,使源域和目標域在新基上具有不同的方差。SDA使用子空間轉換矩陣將源子空間映射到目標子空間,通過矩陣對齊域間分布。SDA用均值和方差描述每個分布,使均值為零并對齊源域和目標域之間的方差。當域間協變量轉移較大時,SDA會失效。
在本文中,DISA作為一種基于子空間的方法,旨在將源域和目標域轉換到相關的嵌入子空間中。DISA通過最小化域間的條件和邊際分布差異,對兩個域進行全局適配。此外,DISA通過最小化類間距離和最大化類內距離來區分不同類別。在局部適應方面,DISA保留兩個域的幾何信息。然后,使用在源域上訓練的模型來預測目標域的標簽。
3 判別性和不變子空間對齊
3.1 動機
DISA的主要思想如圖1所示。DISA通過保留樣本的統計和幾何信息,迭代地適配源域和目標域。
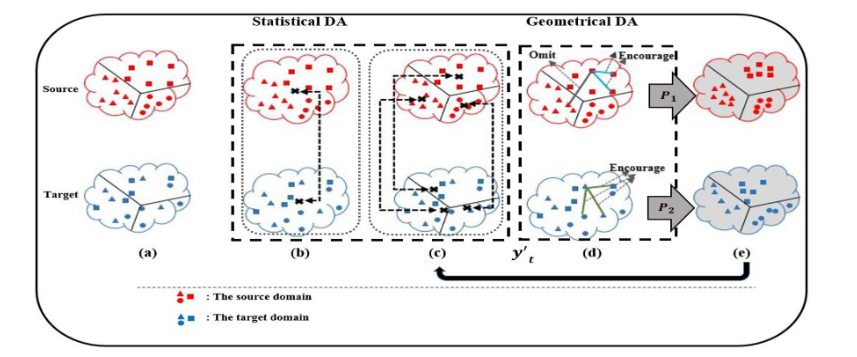
3.2 問題陳述
我們從域和任務的定義開始,然后闡述問題。
一個域D由兩部分組成,即(D = {X, P(x)}),其中(X = {x_1, x_2, \ldots, x_{n_s}}),(x \in X),(n_s)是源樣本的數量。
給定一個特定的域D,一個任務定義為(T = {Y, f(x)}),其中Y是樣本的標簽集,(f(x))是一個分類器,用于為樣本分配標簽。(f(x))可解釋為每個樣本的條件概率分布,即(f(x) = P(y|x)),其中(y \in Y)。我們給定一個源域(D_S = {(x_i^s, y_i^s)}{i = 1}^{n_s}),包含(n_s)個有標簽的源樣本,以及一個目標域(D_T = {x_i^t}{i = 1}^{n_t}),包含(n_t)個無標簽的目標樣本。假設源域和目標域的分布不同,具體來說(X_s = X_t),(Y_s = Y_t),(P_s(x_s) \neq P_t(x_t)),(P_s(y_s|x_s) \neq P_t(y_t|x_t))。我們的問題是為源樣本和目標樣本找到一個潛在特征空間,使得:(1)源域和目標域之間的邊際和條件分布差異減小;(2)類間距離最大化,類內距離最小化;(3)源樣本和目標樣本的幾何信息得以保留。
3.3 DISA
在本節中,我們介紹DISA,以找到分別用于投影源域和目標域的投影矩陣(P_1)和(P_2)。DISA在統計和幾何適配中,減小源域和目標域之間的域轉移。
3.3.1 (統計適配)目標重構誤差最小化
我們通過最大化目標域在相應嵌入子空間中的方差,來鼓勵減小映射后的目標樣本的重構誤差。基于PCA方法,方差最大化可表示為:
[ \max_{P_2^T P_2 = I} \text{tr}(P_2^T X_t H_t X_t^T P_2) ]
其中(H_t = I_t - \frac{1}{n_t} 1_t 1_t^T)是中心矩陣,用于保留目標樣本的方差信息,(1_t \in \mathbb{R}^{n_t})是列向量全為1的向量,(X_t \in \mathbb{R}^{m \times n_t}),m是目標域的原始維度。PCA旨在找到一個投影矩陣(P_2),以最大化數據方差。
3.3.2 (統計適配)源統計判別學習
由于不同類別的源樣本具有不同的結構,用源域訓練的模型可能會對目標樣本預測不準確的標簽。為了提高預測模型的性能,我們將源樣本投影到一個潛在子空間中,在該子空間中不同類別可以被區分。因此,我們根據以下關系最大化類間距離,最小化類內距離:
[ \min_{P_1} \frac{\text{tr}(P_1^T (\sum_{c = 1}^{C} n_s^c (m_s^c - \overline{m}s)(m_s^c - \overline{m}s)T))}{\text{tr}(P_1T (\sum{c = 1}^{C} X_s^c H_s^c (X_sc)T) P_1)} ]
其中(X_s^c \in \mathbb{R}^{m \times n_sc})包含源樣本中屬于類c的子集,(m_sc = \frac{1}{n_s^c} \sum{i = 1}{n_sc} x_ic)和(n_sc)分別是(X_s^c)中樣本的均值和數量,(\overline{m}s = \frac{1}{n_s} \sum{i = 1}^{n_s} x_i)是(X_s)中源樣本的均值。(H_s^c = I_s^c - \frac{1}{n_s^c} (1_sc)T)是類c中樣本的中心矩陣,(I_s^c \in \mathbb{R}{n_sc \times n_sc})和(1_sc \in \mathbb{R}{n_sc})分別是單位矩陣和全1向量。
3.3.3 (統計適配)邊際分布差異最小化
將源域和目標域投影到各自的子空間后,域間的邊際和條件分布差異并沒有減小。為了度量邊際分布差異,我們使用非參數方法MMD來計算映射后的源域和目標域之間的距離。在計算源域和目標域樣本均值在希爾伯特空間中的經驗距離時,DISA為每個域找到兩個投影(P_1)和(P_2),如下所示:
[ D_1(X_s, X_t) = \left| \frac{1}{n_s} \sum_{x_i \in X_s} P_1^T x_i - \frac{1}{n_t} \sum_{x_j \in X_t} P_2^T x_j \right|^2 ]
上述方程可改寫為封閉形式:
[ D_1(X_s, X_t) = \min_{P_1, P_2} \text{tr}([P_1^T \ P_2^T] X M_0 X^T \begin{bmatrix} P_1 \ P_2 \end{bmatrix}) ]
其中(X = [X_s, X_t] \in \mathbb{R}^{m \times (n_s + n_t)}),(M_0 = \begin{bmatrix} (M_0)s & (M_0){st} \ (M_0)_{ts} & (M_0)t \end{bmatrix} \in \mathbb{R}^{(n_s + n_t) \times (n_s + n_t)})是MMD系數矩陣,((M_0)s = \frac{1}{n_s^2}),((M_0){st} = -\frac{1}{n_s n_t}),((M_0){ts} = -\frac{1}{n_t n_s}),((M_0)_t = \frac{1}{n_t^2}),(\text{tr})表示矩陣的跡。
3.3.4 (統計適配)條件分布差異最小化
減小域間的邊際分布差異并不能保證源域和目標域之間的類條件分布差異也減小。我們通過計算每個類中源域和目標域之間的經驗距離,來緩解域間的類條件分布差異。因此,DISA為每個域找到兩個投影(P_1)和(P_2),如下所示:
[ \begin{aligned} D_2(X_s, X_t) &= \sum_{c = 1}^{C} \left| \frac{1}{n_s^c} \sum_{x_i \in X_s^c} P_1^T x_i - \frac{1}{n_t^c} \sum_{x_j \in X_t^c} P_2^T x_j \right|^2 \end{aligned} ]
其中(n_sc)和(n_tc)分別是屬于類c的源樣本和目標樣本的數量。公式(5)可以寫成封閉形式:
[ D_2(X_s, X_t) = \min_{P_1, P_2} \text{tr}([P_1^T \ P_2^T] X M_c X^T \begin{bmatrix} P_1 \ P_2 \end{bmatrix}) ]
其中(M_c = \begin{bmatrix} (M_c)s & (M_c){st} \ (M_c)_{ts} & (M_c)_t \end{bmatrix} \in \mathbb{R}^{(n_s + n_t) \times (n_s + n_t)})是MMD系數矩陣,計算方式為((M_c)s = \frac{1}{(n_sc)2}),((M_c){st} = -\frac{1}{n_s^c### 3.3.5(幾何適配)通過源樣本進行判別學習
樣本的統計信息,即樣本均值和方差,由于映射域的內在結構存在偏移,不足以最小化源域和目標域之間的域偏移。因此,DISA利用樣本的局部信息進行幾何分布適配。根據流形定理,幾何分布相近的樣本具有相同的標簽。因此,DISA對跨域的幾何分布進行適配。
由于源樣本標簽完備,DISA同時利用源樣本的流形和標簽結構,保留數據內在結構的信息,并提高源樣本在潛在空間中的可分離性。通過這種方式,我們創建一個具有 n s n_s ns?個節點的圖結構,其中每個節點對應于 X s X_s Xs?中的一個樣本。然后,對于每個節點,我們考慮其 p p p個最近鄰。如果樣本對具有相同的類別和相同的流形,我們用一條帶有相應權重的邊連接它們。樣本對 i i i和 j j j之間的權重通過 W i j = e ? ∥ x i ? x j ∥ 2 W_{ij}=e^{-\left\|x_{i}-x_{j}\right\|^{2}} Wij?=e?∥xi??xj?∥2來度量,其中 W ∈ R n s × n s W \in \mathbb{R}^{n_{s}×n_{s}} W∈Rns?×ns?是權重矩陣,包含每個樣本對之間的歐幾里得距離。 L = D ? W L = D - W L=D?W是圖拉普拉斯矩陣,其中 D i i = ∑ j = 1 n s W i j D_{ii}=\sum_{j = 1}^{n_{s}}W_{ij} Dii?=∑j=1ns??Wij?是一個對角矩陣。為了在嵌入空間中區分映射后的源樣本,DISA找到 P 1 P_1 P1?,基于流形結構最小化每個類中源樣本之間的距離,如下所示:
[ \min_{P_1} \sum_{i, j = 1}{n_{s}}(P_1T x_{i} - P_1^T x_{j})W_{s_{ij}} = \min_{P_1} \text{tr}(P_1^T X_{s} L_{s} X_{s}^T P_1) ]
L s L_s Ls?作為源數據的拉普拉斯矩陣,包含源樣本的幾何信息。因此, P 1 P_1 P1?將幾何分布相似的源樣本映射到相關子空間中,并使它們彼此靠近。
3.3.6(幾何適配)通過目標樣本進行流形學習
為了保留目標樣本的幾何結構,DISA在目標域上構建一個具有 n t n_t nt?個節點的最近鄰圖。由于沒有目標樣本的相應標簽,根據流形定理,我們將每個節點與其 P P P個最近鄰連接。因此,DISA通過以下方式找到 P 2 P_2 P2?:
[ \min_{P_2} = \sum_{i, j = 1}{n_{t}}(P_2T x_{i} - P_2^T x_{j})W_{t_{ij}} = \min_{P_2} \text{tr}(P_2^T X_{t} L_{t} X_{t}^T P_2) ]
目標樣本的拉普拉斯矩陣 L t L_t Lt?包含目標數據的幾何信息。實際上, P 2 P_2 P2?將目標樣本轉換到相關的潛在子空間中,同時保留了樣本的局部信息。
3.3.7(幾何適配)子空間生成過程中的散度最小化
DISA通過統計和幾何學習為源域和目標域找到成對的投影。為了最小化嵌入子空間中數據的散度,DISA使兩個潛在子空間 P 1 P_1 P1?和 P 2 P_2 P2?更加接近。因此,在子空間生成過程中,域的局部和全局信息都得以保留。這一目標可表示為:
[ \min_{P_1, P_2} \left| P_1 - P_2 \right|_{F}^{2} ]
其中 ∥ ? ∥ F 2 \|\cdot\|_{F}^{2} ∥?∥F2?是弗羅貝尼烏斯范數。
3.4 優化問題
DISA通過結合公式(1)到(9)找到源投影 P 1 P_1 P1?和目標投影 P 2 P_2 P2?。我們基于瑞利商開發了最終模型,以對齊跨域偏移,如下所示:
[ \min_{P_1, P_2} \frac{\text{Tr}\left(P^T\left[\begin{array}{cc} \beta S_{w}+\gamma X_{s} L_{s} X_{s}^T+\lambda I & -\lambda I \ -\lambda I & \gamma X_{t} L_{t} X_{t}^T+(\lambda+\mu) I\end{array}\right] + X\left(\sum_{c = 0}^{C} M_{c}\right) XT\right)P}{\text{tr}\left(PT\left[\begin{array}{cc} \beta S_{b} & 0_{(m, m)} \ 0_{(m, m)} & \mu S_{t} \end{array}\right] P\right)} ]
其中 S w = ∑ c = 1 C n s c ( m s c ? m  ̄ s ) ( m s c ? m  ̄ s ) T S_{w}=\sum_{c = 1}^{C} n_{s}^{c}(m_{s}^{c}-\overline{m}_{s})(m_{s}^{c}-\overline{m}_{s})^T Sw?=∑c=1C?nsc?(msc??ms?)(msc??ms?)T和 S b = ∑ c = 1 C X s c H s c ( X s c ) T S_{b}=\sum_{c = 1}^{C} X_{s}^{c} H_{s}^{c}(X_{s}^{c})^T Sb?=∑c=1C?Xsc?Hsc?(Xsc?)T用于學習源域的判別信息。 ∑ c = 0 C M c \sum_{c = 0}^{C} M_{c} ∑c=0C?Mc?在 c = 0 c = 0 c=0時計算邊際分布的MMD系數矩陣,在 c = 1 c = 1 c=1到 c c c時計算條件分布模式下的MMD系數矩陣。 X = [ X s 0 ( m , n t ) 0 ( m , n s ) X t ] X=\left[\begin{array}{cc}X_{s} & 0_{(m, n_{t})} \\ 0_{(m, n_{s})} & X_{t}\end{array}\right] X=[Xs?0(m,ns?)??0(m,nt?)?Xt??], I ∈ R m × m I \in \mathbb{R}^{m×m} I∈Rm×m是單位矩陣。此外, S t = X t H t X t T S_{t}=X_{t} H_{t} X_{t}^T St?=Xt?Ht?XtT?用于尋找矩陣 P 2 P_2 P2?,以最大化目標域在相關嵌入子空間中的方差。 P = [ P 1 P 2 ] ∈ R 2 m × k P=\left[\begin{array}{l}P_{1} \\ P_{2}\end{array}\right] \in \mathbb{R}^{2m×k} P=[P1?P2??]∈R2m×k,其中 P 1 P_1 P1?和 P 2 P_2 P2?由公式(10)的特征值分解給出。算法1設計用于實現DISA策略。
3.5 時間復雜度
在本節中,我們分析算法1的計算復雜度如下:對于步驟3和4,在源數據上訓練分類器和預測目標樣本偽標簽的時間復雜度分別為 O ( m n s ) O(mn_{s}) O(mns?)和 O ( m n t ) O(mn_{t}) O(mnt?)。對于步驟5和6,在全局適配階段構建邊際和條件矩陣需要 O ( ( n s + n t ) 2 ) O((n_{s}+n_{t})^{2}) O((ns?+nt?)2)。在步驟7和8的局部適配階段,計算源樣本和目標樣本的拉普拉斯矩陣分別需要 O ( ( n s ) 2 ) O((n_{s})^{2}) O((ns?)2)和 O ( ( n t ) 2 ) O((n_{t})^{2}) O((nt?)2)。步驟10中計算耦合變換矩陣的時間復雜度為 O ( k 3 ) O(k^{3}) O(k3),其中 k k k是潛在特征的數量。對于步驟11和12,在映射后的源樣本上訓練最近鄰(NN)分類器和預測映射后的目標樣本分別需要 O ( k n s ) O(kn_{s}) O(kns?)和 O ( k n t ) O(kn_{t}) O(knt?)。綜上所述,DISA的計算復雜度為 O ( ( n s + n t ) 2 + k 3 ) O((n_{s}+n_{t})^{2}+k^{3}) O((ns?+nt?)2+k3) 。
算法1 視覺域的判別性和不變子空間對齊(DISA)
- 輸入:源數據 X s X_s Xs?,目標數據 X t X_t Xt?,源域標簽 Y s Y_s Ys?,正則化參數: λ , μ , k , T , β \lambda, \mu, k, T, \beta λ,μ,k,T,β
- 輸出:投影矩陣 P 1 P_1 P1?和 P 2 P_2 P2?,目標域標簽 y t y_t yt?
- 基于 ( X s , Y s ) (X_s, Y_s) (Xs?,Ys?)學習1-NN分類器 f f f
- 使用分類器 f f f預測目標域 ( X t ) (X_t) (Xt?)中的偽標簽 Y t 0 Y_{t0} Yt0?
- 根據公式(4)構建 M 0 M_0 M0?
- 根據公式(5)構建 M c M_c Mc?
- 根據公式(7)計算 L s L_s Ls?
- 根據公式(8)計算 L t L_t Lt?
- 重復直至收斂:
10. 根據公式(5)更新矩陣 M c M_c Mc?
11. 求解公式(10),選擇 k k k個最小的特征向量作為 P 1 P_1 P1?和 P 2 P_2 P2?
12. 基于 ( P 1 T X s , Y s ) (P_1^T X_s, Y_s) (P1T?Xs?,Ys?)學習分類器 f f f
13. 更新 ( P 2 T X t ) (P_2^T X_t) (P2T?Xt?)上的偽標簽 Y t 0 Y_{t0} Yt0? - 結束重復
- 基于 ( P 1 T X s , Y s ) (P_1^T X_s, Y_s) (P1T?Xs?,Ys?)學習最終分類器 f ′ f' f′
- 使用 f ′ f' f′預測 X t X_t Xt?的標簽
- 返回由分類器 f ′ f' f′確定的目標域標簽 y t y_t yt?
4 實驗
在本節中,我們評估所提方法與基線方法以及其他最先進的域適應方法在圖像分類任務中的有效性。
4.1 基準數據集描述
Office數據集是最常用的目標識別基準數據集,由4652張真實世界圖像組成,分為3個不同的域:Amazon(A:從amazon.com下載的圖像)、DSLR(D:由單反相機拍攝的高分辨率圖像)和Webcam(W:由網絡攝像頭拍攝的低分辨率圖像),每個域有31個類別,包括相機、帽子、自行車、鍵盤、剪刀等。Caltech - 256由30607張圖像組成,有256個類別。我們從四個域中選擇10個常見類別,即計算器、筆記本電腦、鍵盤、鼠標、顯示器、投影儀、耳機、背包、杯子和自行車。我們數據集的配置與文獻[24]相同,從圖像中提取800維的SURF特征,然后通過z - score歸一化作為輸入向量。最后,每兩個不同的域分別作為源域和目標域,可構建12個域適應任務,即 C → A C→A C→A、 C → W C→W C→W、…、 D → W D→W D→W。CMU - PIE是一個人臉識別基準數據集,由68個人的41368張灰度圖像組成,包含不同的光照和姿態。我們與文獻[24]一樣使用5種姿態,P1、P2、P3、P4和P5,分別對應左側、上側、下側、正面和右側姿態。由于CMU - PIE數據集包含5個域,可構建20個跨域任務,即 P 1 → P 2 P1→P2 P1→P2、 P 1 → P 3 P1→P3 P1→P3、…、 P 5 → P 4 P5→P4 P5→P4。MNIST和USPS是數字識別基準數據集,分別由2000張和1800張灰度圖像組成。MNIST(M)圖像收集自美國高中生和美國人口普查局員工;USPS(U)數據集由美國郵政服務信封上掃描的手寫數字組成。我們與文獻[24]一樣使用兩個數據集中的10個常見類別。由于數字識別基準數據集有兩個域,可構建兩個域適應任務,即 U → M U→M U→M和 M → U M→U M→U(圖2)。
【此處插入原文圖2:Fig. 2 The first row demonstrates the Office+Caltech - 256 dataset, and the second row demonstrates CMU - PIE and MNIST and USPS datasets, respectively (from left to right)】
4.2 實現細節
與其他最先進方法比較DISA性能時,使用的評估指標與文獻[20]相同,即準確率,公式如下:
[ \text{Accuracy} =\frac{\left|x: x \in X_{t} \land f(x)=y(x)\right|}{n_{t}} ]
其中 f ( x ) f(x) f(x)是每個目標樣本 x x x的預測標簽, y ( x ) y(x) y(x)是其真實標簽。DISA有五個參數: λ , μ , k , T , β \lambda, \mu, k, T, \beta λ,μ,k,T,β和 r r r。我們通過經驗設置,對于Office + Caltech - 256數據集, λ = 0.5 \lambda = 0.5 λ=0.5, μ = 5 \mu = 5 μ=5, β = 0.1 \beta = 0.1 β=0.1;對于CMU - PIE數據集, λ = 5 \lambda = 5 λ=5, μ = 0.5 \mu = 0.5 μ=0.5, β = 0.0005 \beta = 0.0005 β=0.0005;對于數字識別數據集(Digits), λ = 1 \lambda = 1 λ=1, μ = 5 \mu = 5 μ=5, β = 0.001 \beta = 0.001 β=0.001 。Office + Caltech - 256數據集的子空間數量 k k k設置為30,數字識別數據集的 k k k設置為110。兩個基準測試中,使DISA收斂的迭代次數 T T T均設置為10。
4.3 實驗結果評估與討論
DISA和其他9種對比方法(NN、JDA、SA、TJM、LRSR、VDA、CDDA、CLGA)在三個基準數據集(Office + Caltech - 256、CMU - PIE和Digits)上的性能分別如表1、表2和表3所示。每個跨域適應對的最高準確率以粗體突出顯示。我們根據其他方法論文中報告的結果,將DISA與它們的最佳結果進行比較。所有方法都使用最近鄰分類器在有標簽的源樣本上進行訓練,并預測目標樣本的標簽。根據表1中的結果,在Office + Caltech - 256數據集上,DISA與最先進方法中表現最佳的VDA相比,平均準確率提高了3.35%,并且在12個跨域適應任務中的9個任務上優于VDA。
DISA與最近鄰分類器(NN)相比,準確率提高了21.01%,這表明DISA能有效地適配不匹配的源域和目標域。
JDA和TJM將兩個域映射到共享的潛在子空間中,以減小域間的邊際分布差異。TJM使用 l 2 , 1 l_{2,1} l2,1?范數為源樣本設置權重,以便更有效地學習模型,JDA則減小條件分布差異。然而,DISA同時適配邊際和條件分布差異,并在潛在子空間中保留樣本的局部信息。在Office + Caltech - 256、CMU - PIE和Digits數據集上,DISA的性能分別比JDA提高了6.07%、20.71%和13.42%,比TJM提高了7.97%、45.39%和19.12%。
SA是一種基于子空間的方法,將源域和目標域映射到潛在子空間中。SA使用線性變換矩陣使映射后的源域基向量與映射后的目標域基向量對齊,但它忽略了減小分布差異,而DISA同時減小了邊際和條件分布差異。在Office + Caltech - 256、CMU - PIE和Digits數據集上,DISA相對于SA的性能分別提高了7.66%、27.77%和18.6%。
雖然LRSR最小化了重構誤差,但域間的分布差異仍然很大。DISA使兩個域更接近,在Office + Caltech - 256、CMU - PIE和Digits數據集上,其平均準確率相對于LRSR分別提高了6.99%、17.42%和12.72%。
雖然VDA利用統計信息對域進行適配,但它忽略了保留樣本的局部信息。然而,DISA同時利用樣本的局部和全局信息使兩個域更接近。在Office + Caltech - 256、CMU - PIE和Digits數據集上,DISA相對于VDA的平均準確率分別提高了3.35%、9.95%和7.94%。
CDDA通過統計方法對域進行適配,并區分不同類別。DISA減小了邊際和條件分布差異,并進行局部域適配。在Office + Caltech - 256、CMU - PIE和Digits數據集上,DISA的平均準確率分別比CDDA高4.16%、17.85%和7.75%。
CLGA在幾何和統計適配中對源域和目標域進行適配。在統計適配中,CLGA減小了域間的邊際和條件分布差異;在幾何適配中,CLGA利用樣本的流形和標簽信息對兩個域進行適配。然而,DISA在統計層面上對兩個域進行適配,并利用源域的標簽和流形信息進行局部適配。在Office + Caltech - 256數據集上,DISA的性能提高了4.15%,在CMU - PIE和Digits數據集上,相對于CLGA的性能分別提高了8.80%和12.08%。
基于圖3a和圖3b,與Office + Caltech - 256數據集上表現最佳的VDA相比,DISA在12個問題中的9個上表現更優。DISA在所有12個實驗中均優于NN和JDA(基線方法)。圖3c和圖3d表明,與CMU - PIE數據集上表現最佳的CLGA相比,DISA在20個問題中的20個上表現更優。圖3e顯示,DISA在所有情況下均優于其他所有最先進的方法。
【此處插入原文圖3:Fig. 3 Accuracy (%) of DISA in comparison against cross - domain approaches. a, b Office+Caltech - 256, c, d CMU - PIE, e USPS+MNIST (best viewed in color)】
4.4 參數的影響
DISA的有效性取決于參數的最優值。為了調整潛在子空間維度 k k k、迭代次數 T T T以及正則化參數 μ , β , λ \mu, \beta, \lambda μ,β,λ和 γ \gamma γ的最優值,我們在各種適應任務上對DISA進行評估。我們通過在[0.0001, 5]的廣泛范圍內進行經驗搜索來設置正則化參數 μ , β , λ \mu, \beta, \lambda μ,β,λ和 r r r,計算拉普拉斯矩陣時的鄰居數量設置為5。圖4a展示了在Office+Caltech-256數據集上評估k影響的實驗。我們報告了k∈[20,150]時DISA的平均準確率,其中k=30是Office+Caltech-256數據集潛在子空間的最優維度。圖4b、c、d和f分別描繪了參數λ、μ、β和γ對Office+Caltech-256數據集的影響。通過這種方式,選擇λ=0.5、μ=1、β=0.1和γ=0.1作為DISA的最優參數。圖4e展示了每次迭代對Office+Caltech-256數據集的影響結果。我們選擇T=10作為最優參數。
圖5a、b、c、d、e和f分別展示了不同參數值k、λ、μ、β、T和γ對CMU-PIE數據集的影響。因此,k=110、λ=5、μ=0.5、β=0.0005、γ=0.001和T=10是CMU-PIE數據集的最優參數。
圖6a展示了在Digits數據集上評估參數k敏感性的結果。我們報告了k∈[20,140]時DISA的平均準確率,其中k=110是Digits數據集潛在子空間的最優維度。圖6b、c、d和f分別展示了參數λ、μ、β和r對Digits數據集的影響。通過這種方式,選擇λ=1、μ=5、β=0.001和γ=0.05作為DISA的最優參數。圖6e展示了Digits數據集上迭代敏感性的結果,其中T=10被設置為最優參數。
5 結論與展望
在本文中,我們提出了一種新穎的視覺域適應方法——判別性和不變子空間對齊(DISA),以解決跨域偏移問題。DISA在潛在子空間中找到兩個域的相關特征,通過最小化邊際和條件分布距離來適應轉換后的源域和目標域,從而解決跨域問題。DISA利用域的流形信息來保留樣本的幾何信息。我們在常見視覺數據集的各種任務上對DISA進行了評估,結果表明,與其他最先進的視覺域適應方法相比,該方法具有優越性。
我們打算將DISA擴展為一種在線方法,用于預測視覺問題中實時數據的標簽。作為未來的工作,我們考慮將DISA應用于缺失模態和深度學習問題。




)














)