繼續上一節的學習,上一節學習了RabbitMQ的基本內容,本節學習RabbitMQ的高級特性。
RocketMQ的高級特性學習見這篇博客
目錄
- 1.消息可靠性
- 1.1生產者消息確認
- 1.2消息持久化
- 1.3消費者消息確認
- 1.4消費失敗重試機制
- 1.5消息可靠性保證總結
- 2.什么是死信交換機
- 2.1利用死信交換機接收死信
- 2.2TTL結合死信交換機實現延遲消息
- 2.3延遲隊列
- 3.消息堆積問題與惰性隊列
- 4.MQ集群
- 4.1普通集群
- 4.2鏡像集群
- 4.3仲裁隊列
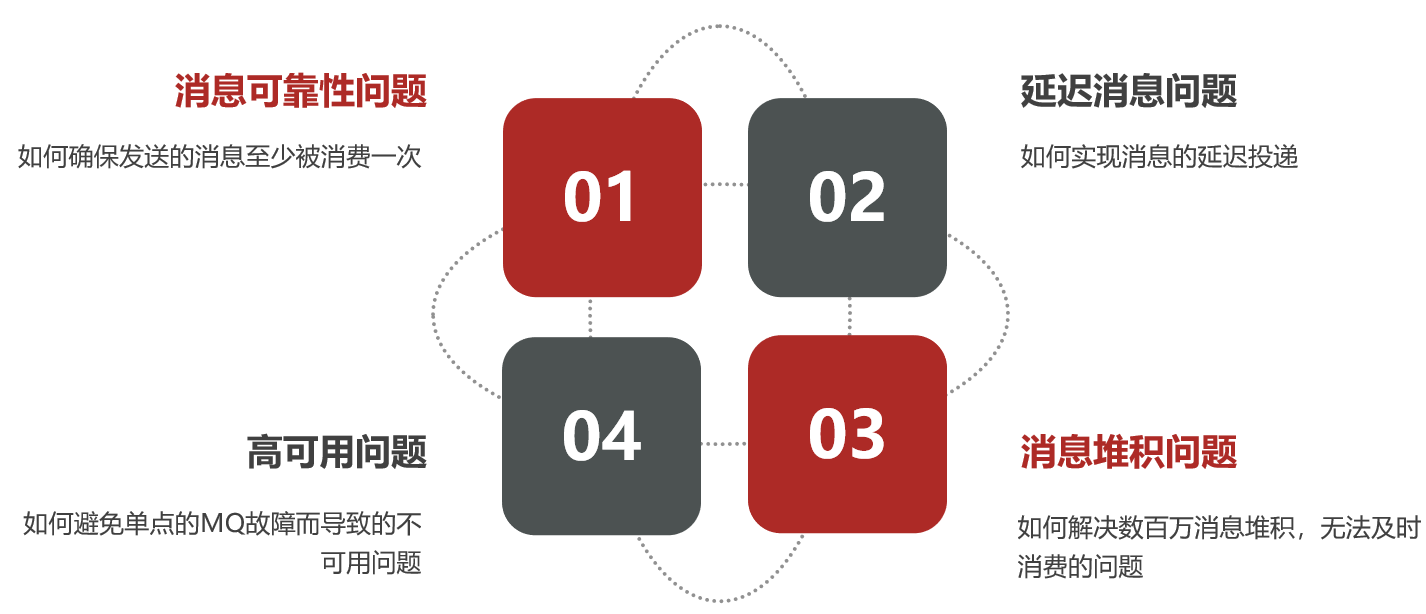
1.消息可靠性
消息從發送,到消費者接收,會經理多個過程:
其中的每一步都可能導致消息丟失,常見的丟失原因包括:
- 發送時丟失:
- 生產者發送的消息未送達exchange
- 消息到達exchange后未到達queue
- MQ宕機,queue將消息丟失
- consumer接收到消息后未消費就宕機
針對這些問題,RabbitMQ分別給出了解決方案:
- 生產者確認機制
- mq持久化
- 消費者確認機制
- 失敗重試機制
下面我們就通過案例來演示每一個步驟。

項目結構如下:
1.1生產者消息確認
RabbitMQ提供了publisher confirm機制來避免消息發送到MQ過程中丟失。這種機制必須給每個消息指定一個唯一ID。消息發送到MQ以后,會返回一個結果給發送者,表示消息是否處理成功。
返回結果有兩種方式:
- publisher-confirm,發送者確認
- 消息成功投遞到交換機,返回ack
- 消息未投遞到交換機,返回nack
- publisher-return,發送者回執
- 消息投遞到交換機了,但是沒有路由到隊列。返回ACK,及路由失敗原因。
如下圖所示,只有成功投遞到交換機并且路由到隊列才是投遞成功:
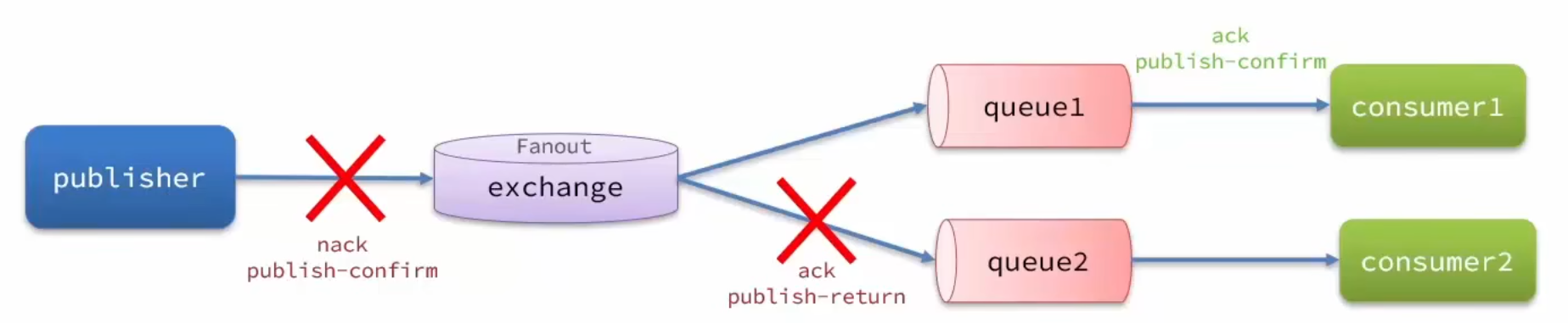
注意:確認機制發送消息時,需要給每個消息設置一個全局唯一id,以區分不同消息,避免ack沖突
下面我們進行演示。mq的安裝和配置信息,以及yml中的基本配置信息比如ip端口等,前面文章已經敘述不再贅述。
1.修改配置
首先,修改publisher服務中的application.yml文件,添加下面的內容:
spring:rabbitmq:publisher-confirm-type: correlatedpublisher-returns: truetemplate:mandatory: true
publish-confirm-type:開啟publisher-confirm,在AMQP這里支持兩種生產者確認類型:
simple:同步等待confirm結果,直到超時。不推薦correlated:異步回調,定義ConfirmCallback,MQ返回結果時會回調這個ConfirmCallback。推薦publish-returns:開啟publish-return功能,同樣是基于callback機制,這里是定義ReturnCallback而非上面的ConfirmCallback,但是返回結果返不返回取決于template.mandatory的配置。template.mandatory:定義消息路由到隊列失敗時的策略。true,則調用ReturnCallback;false:則直接丟棄消息
2.定義Return回調
開啟生產者消息確認功能之后,既然說了要通過回調機制來實現,那就得編寫這個回調函數,怎么編寫呢?首先是ReturnCallback的編寫。
每個RabbitTemplate(由spring創建的,所以是單例)只能配置一個ReturnCallback,所以不能在每次發消息時來陪,需要在項目加載時配置:
修改publisher服務,添加一個:
package cn.itcast.mq.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.annotation.Configuration;@Slf4j
@Configuration
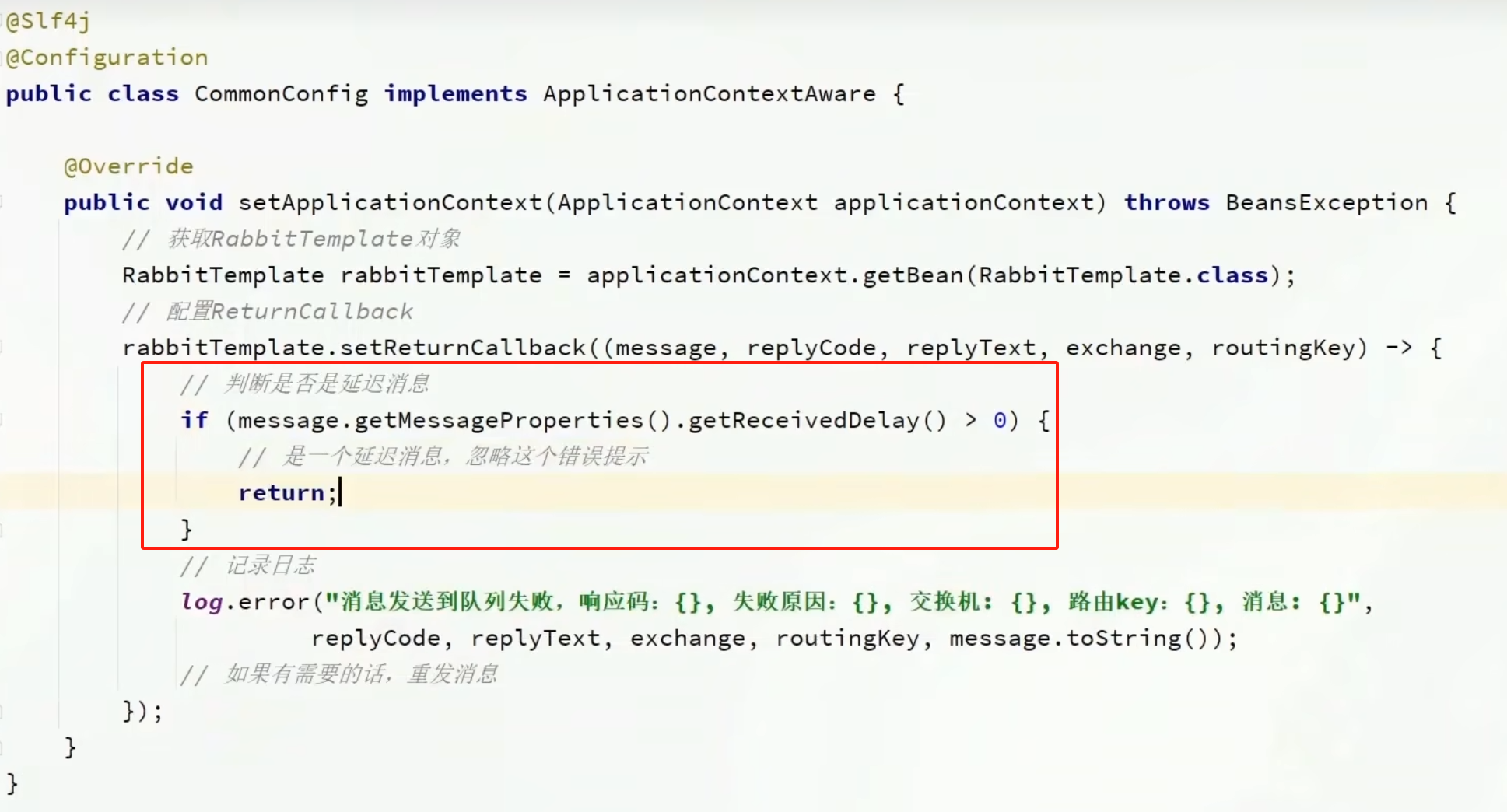
public class CommonConfig implements ApplicationContextAware {@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 獲取RabbitTemplate對象RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);// 配置ReturnCallbackrabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {// 投遞失敗,記錄日志log.info("消息發送失敗,應答碼{},原因{},交換機{},路由鍵{},消息{}",replyCode, replyText, exchange, routingKey, message.toString());// 如果有業務需要,可以重發消息});}
}
ApplicationContextAware是bean容器或者說bean工廠的通知接口,意思就是當spring的bean工廠準備好了以后它會來通知你,并且你實現了這個接口,你一定要實現上面的方法叫setApplicationContext。那么他在通知你的時候就會把spring這個容器ApplicationContext傳遞給你。那你想呀spring的bean工廠創建完了通知我,是不是拿到這個工廠了,我是不是就可以從工廠里取到我想要的bean了。
這里就我就取到了這個RabbitTemplate,就可以給他設置callback,我們講的是這個代碼是在并工廠創建完了以后運行,即在項目啟動時就會去執行了,就是個全局callback了。
這里的回調邏輯是什么呢?lambda有五個參數,你現在不是消息路由失敗了嗎,好我會給你一個回執,在回執中我會告訴你誒,你發的消息message是什么,失敗的狀態碼replyCode是什么,失敗的原因replyText是什么,消息投遞到了哪個交換機exchange,然后你投遞時routingKey用的是什么。
那這五個參數給我可以干什么呢?第一,我可以去記錄日志記錄一下;第二,我既然拿到了這個失敗的消息體,失敗的交換機,失敗的routingKey,也當然可以重發消息了,即失敗的重試。
以上就是消息到達了交換機但是路由到隊列失敗時的ReturnCallback,另外呢我們還有一個ConfirmCallback,定義消息根本就沒有到達交換機的回調策略
3.定義ConfirmCallback
ConfirmCallback可以在發送消息時指定,因為每個業務處理confirm成功或失敗的邏輯不一定相同。
在publisher服務的cn.itcast.mq.spring.SpringAmqpTest類中,定義一個單元測試方法:
public void testSendMessage2SimpleQueue() throws InterruptedException {// 1.準備好一條消息消息體,在發送過程中去添加回調邏輯String message = "hello, spring amqp!";// 1.2全局唯一的消息ID(使用UUID),需要封裝到CorrelationData中CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 1.3添加callback,就是我們的ConfirmCallbackcorrelationData.getFuture().addCallback(result -> {// 接收到了mq的回執if(result.isAck()){// 1.3.1.ack,消息成功投遞到交換機log.debug("消息發送成功, ID:{}", correlationData.getId());}else{// 1.3.2.nack,消息沒能投遞到交換機log.error("消息發送失敗, ID:{}, 原因{}",correlationData.getId(), result.getReason());}},// 1.4發送失敗連回調都收不到ex -> log.error("消息發送異常, ID:{}, 原因{}",correlationData.getId(),ex.getMessage()));// 2.發送消息,三個參數:交換機名稱;routingKey名稱;消息體// 之前就傳前三,這里多了第四個參數:correlationData,對應我們在yml里配置的correlated// correlationData封裝了消息唯一id和回調邏輯rabbitTemplate.convertAndSend("task.direct", "task", message, correlationData);// 休眠一會兒,等待ack回執Thread.sleep(2000);
}
發送之前得將交換機跟隊列綁定好,,否則即使消息到了交換機,也會因為找不到隊列而觸發回退機制ReturnCallback。
方式一:通過代碼方式進行綁定(推薦),前面文章有介紹。
方式二:手動在 RabbitMQ 管理界面中綁定。這種方式適用于測試或臨時使用,但不推薦用于生產,因為無法版本控制和自動部署。
測試發現提示投遞成功,修改投遞的交換機名稱模擬寫錯,模擬投遞失敗,測試ConfirmCallback是否正常觸發;修改投遞的routingKey模擬寫錯,模擬路由失敗,測試ReturnCallback是否正常觸發。
1.2消息持久化
生產者確認可以確保消息投遞到RabbitMQ的隊列中,但是消息發送到RabbitMQ以后,如果突然宕機,也可能導致消息丟失。要想確保消息在RabbitMQ中安全保存,必須開啟消息持久化機制。
我們先去看一下現象,這是我們之前準備的一條隊列,然后在這個隊列里面已經有一條消息了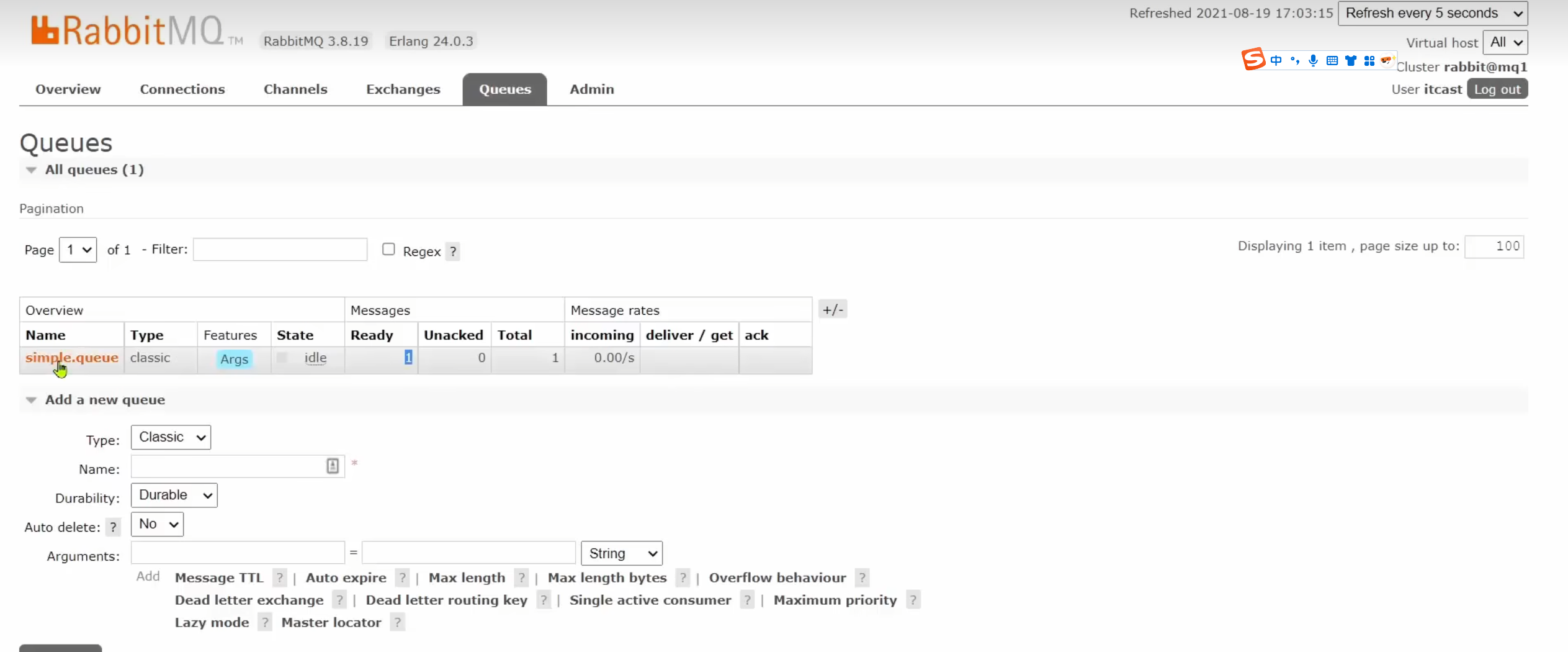
交換機界面如下,這些交換機啊是我們系統自動創建的交換機:
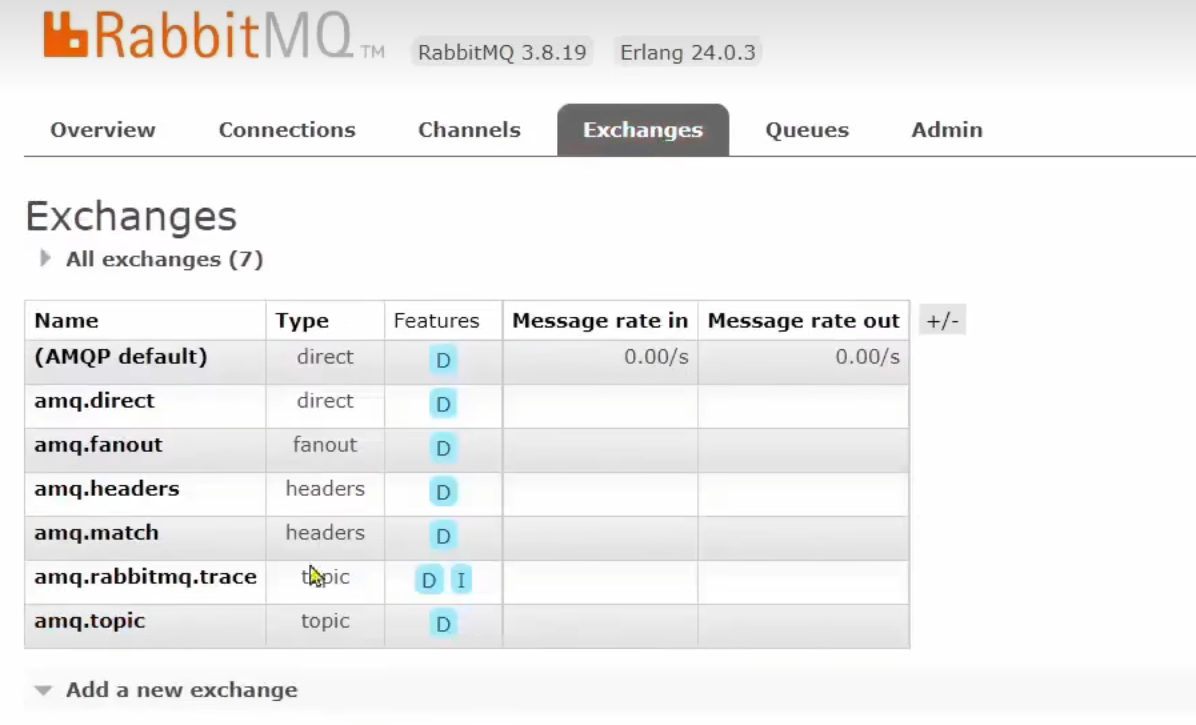
然后我們通過過docker restart mq完成重啟mq,重啟完成發現交換機都在,但是隊列沒了,隊列都沒了何談隊列當中的消息呢。那為什么我們自己創建的隊列消息都沒了但系統的交換機還在呢。這說明系統的交換機是持久化的。
我們觀察可知其實系統創建的交換機都帶了一個特征(Features)——D,對應持久化。那因此呢我們要想讓我們的隊列也能持久化,讓我們的交換機也能持久化,都應該帶上這個durable的參數,在前端我們創建一個交換機的時候Durability參數設置為Durable即可,創建隊列時同理。控制代碼去創建我們這節將會學習。
消息持久化分為:
- 交換機持久化
- 隊列持久化
- 消息持久化
1.交換機持久化
RabbitMQ中交換機默認是非持久化的,mq重啟后就丟失。SpringAMQP中聲明交換機時可以通過代碼指定交換機持久化:
@Bean
public DirectExchange simpleExchange(){// 三個參數:交換機名稱、是否持久化、當沒有queue與其綁定時是否自動刪除return new DirectExchange("simple.direct", true, false);
}
事實上,默認情況下,由SpringAMQP聲明的交換機都是持久化的。
可以在RabbitMQ控制臺看到持久化的交換機都會帶上D的標示:
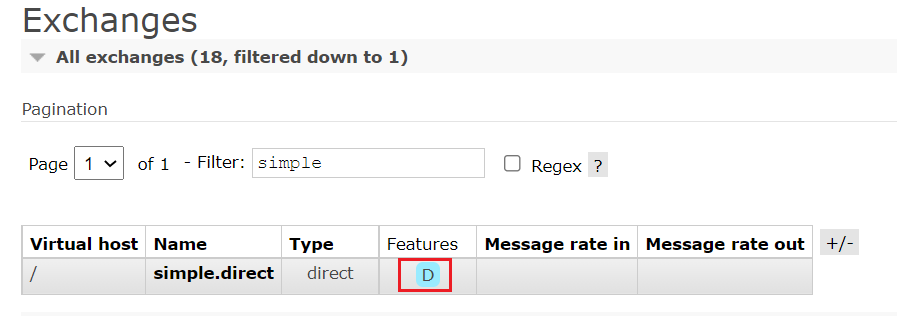
2.隊列持久化
RabbitMQ中隊列默認是非持久化的,mq重啟后就丟失。
SpringAMQP中聲明隊列時可以通過代碼指定交換機持久化:
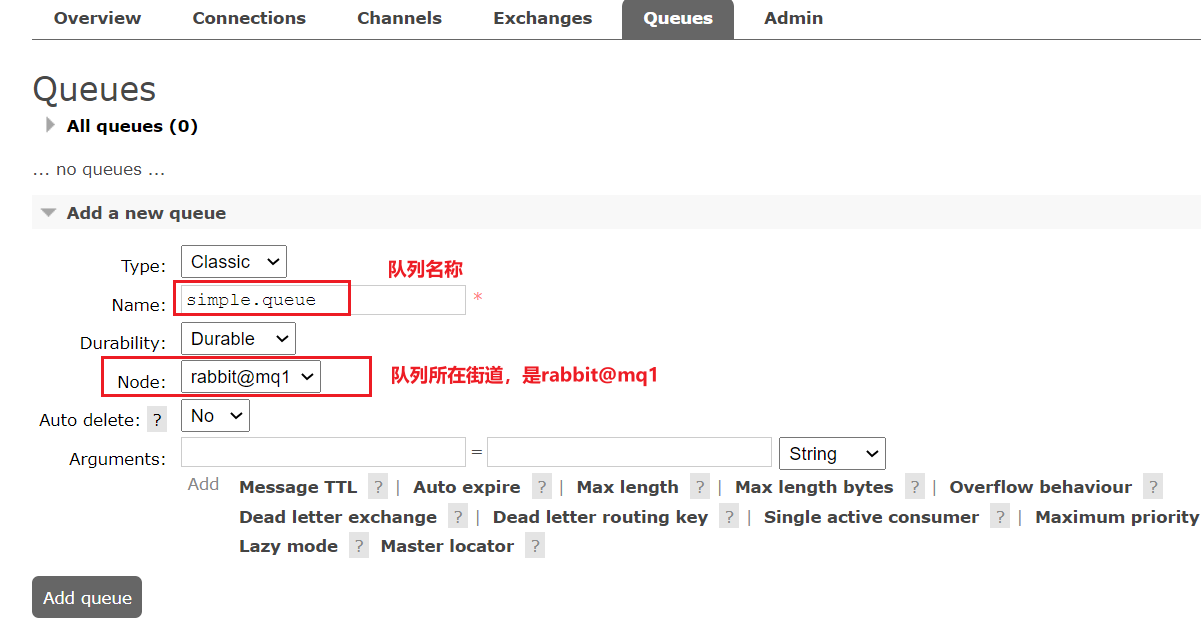
@Bean
public Queue simpleQueue(){// 使用QueueBuilder構建隊列,durable就是持久化的return QueueBuilder.durable("simple.queue").build();
}
事實上,默認情況下,由SpringAMQP聲明的隊列都是持久化的。
可以在RabbitMQ控制臺看到持久化的隊列都會帶上D的標示:

3.消息持久化
隊列持久化不代表消息就持久化,當交換機和隊列持久化時如果宕機,消息仍然會丟失。
利用SpringAMQP發送消息時,可以設置消息的屬性(MessageProperties),指定delivery-mode:
- 1:非持久化
- 2:持久化
用java代碼指定:
// @Test
public void testDurableMessage() {// 創建消息Message message = MessageBuilder.withBody("hello, ttl queue".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();// 消息ID,需要封裝到CorrelationData中CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 發送消息rabbitTemplate.convertAndSend(routingKey: "simple.queue", message, correlationData);// 記錄日志log.debug("發送消息成功");
}
我們之前的文章中發消息沒使用MessageBuilder那么麻煩。默認情況下,SpringAMQP發出的任何消息
都是持久化的,不用特意指定。
1.3消費者消息確認
RabbitMQ是閱后即焚機制,RabbitMQ確認消息被消費者消費并ACK 后會立刻刪除。
RabbitMQ是通過消費者回執來確認消費者是否成功處理消息的:消費者獲取消息后,應該向RabbitMQ發送ACK回執,表明自己已經處理消息。
設想這樣的場景:
- 1)RabbitMQ投遞消息給消費者
- 2)消費者獲取消息后,返回ACK給RabbitMQ
- 3)RabbitMQ刪除消息
- 4)消費者宕機,消息尚未處理
這樣,消息就丟失了。因此消費者返回ACK的時機非常重要。而SpringAMQP則允許配置三種確認模式:
-
manual:手動ack,需要在業務代碼結束后,調用api發送ack。- 即自己根據業務情況,判斷什么時候該ack。一般情況下先寫處理消息的業務,處理完了最后一行發送ack,如果業務執行過程中拋了異常則在catch里發nack,這種模式有代碼侵入,不推薦。
-
auto:自動ack,由spring監測listener代碼(即消費者的業務邏輯)是否出現異常,沒有異常則返回ack;拋出異常則返回nack- auto模式類似事務機制,出現異常時返回nack,消息回滾到mq;沒有異常,返回ack。不需要我們自己try,底層用了spring的aop技術。推薦使用。
-
none:關閉ack,MQ假定消費者獲取消息后會成功處理,因此消息投遞后立即被刪除- none模式下,消息投遞是不可靠的,可能丟失
一般,我們都是使用默認的auto即可。
1.演示none模式
修改consumer服務的application.yml文件,添加下面內容:
spring:rabbitmq:listener:simple:acknowledge-mode: none # none,關閉ack;manual,手動ack;auto,自動ack
修改consumer服務的SpringRabbitListener類中的方法,模擬一個消息處理異常:
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg) {log.info("消費者接收到simple.queue的消息:【{}】", msg);// 模擬異常System.out.println(1 / 0);log.debug("消息處理完成!");
}
測試可以發現,當消息處理拋異常時,消息依然被RabbitMQ刪除了。
2.演示auto模式
再次把確認機制修改為auto:
spring:rabbitmq:listener:simple:acknowledge-mode: auto # 關閉ack
在異常位置打斷點,再次發送消息,程序卡在斷點時,可以發現此時消息狀態為unack(未確定狀態):

拋出異常后,因為Spring會自動返回nack,所以消息恢復至Ready狀態,并且沒有被RabbitMQ刪除:

1.4消費失敗重試機制
當消費者出現異常后,消息會不斷requeue(重入隊)到隊列,再重新發送給消費者,然后再次異常,再次requeue,無限循環,導致mq的消息處理飆升,帶來不必要的壓力,怎么辦呢?

1.本地重試
我們可以利用Spring的retry機制,在消費者出現異常時利用本地重試,而不是無限制的requeue到mq隊列。
以前是拋了異常就把消息重新投遞給mq,mq再把消息給消費者,消費者再處理,消費者再拋異常返回nack…來回去做)。現在是利用Spring自己的retry機制,消費者拋了異常后不再返回nack,而是在本地去做重試,直到成功或者達到重試上限,達到上限時可以采用其他策略,比如說再把消息投遞給mq或者是把消息放到一個額外的地方將來由人工介入。
修改consumer服務的application.yml文件,添加內容:
spring:rabbitmq:listener:simple:retry:enabled: true # 開啟消費者失敗重試initial-interval: 1000 # 初始的失敗等待時長為1秒multiplier: 1 # 失敗的等待時長倍數,下次等待時長 = multiplier * 上一次等待時長,這里等待時長永遠是1s;若設置為2就是1 2 4 8s...max-attempts: 3 # 最大重試次數stateless: true # 代表有無狀態,默認為true無狀態;false為有狀態。一般情況下用不到,如果業務中包含事務,一定要改為false,即有狀態。因為這個時候spring需要在重試的時候保留事務,不會去導致事務失效,對業務性能產生影響
重啟consumer服務,重復之前的測試。可以發現:
- 在重試3次后,SpringAMQP會拋出異常
AmqpRejectAndDontRequeueException,說明本地重試觸發了 - 查看RabbitMQ控制臺,發現消息被刪除了,說明最后SpringAMQP返回的是ack,mq刪除消息了
結論:
-
開啟本地重試時,消息處理過程中拋出異常,不會requeue到隊列,而是在消費者本地重試
-
重試達到最大次數后,Spring會返回ack,消息會被丟棄
2.失敗策略
在之前的測試中,達到最大重試次數后,消息會被丟棄,這是由Spring內部機制決定的。
在開啟重試模式后,重試次數耗盡,如果消息依然失敗,則需要有MessageRecovery接口來處理,它包含三種不同的實現:
-
RejectAndDontRequeueRecoverer:重試耗盡后,直接reject,丟棄消息。默認就是這種方式 -
ImmediateRequeueMessageRecoverer:重試耗盡后,返回nack,消息重新入隊 -
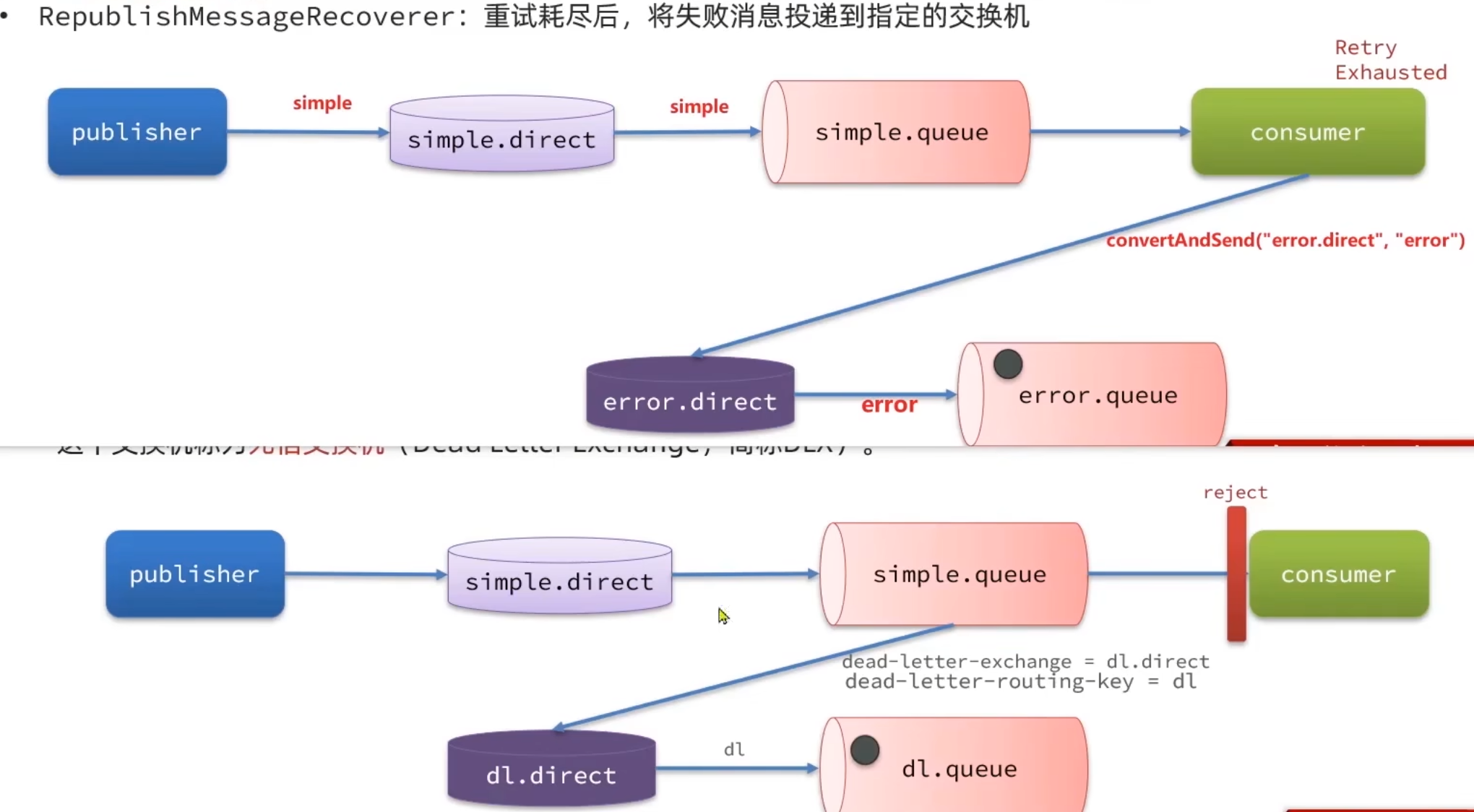
RepublishMessageRecoverer:重試耗盡后,將失敗消息投遞到指定的交換機
比較優雅的一種處理方案是RepublishMessageRecoverer,失敗后將消息投遞到一個指定的,專門存放異常消息的隊列,后續由人工集中處理。下面演示
1)在consumer服務中定義處理失敗消息的交換機和隊列
@Bean
public DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
2)定義一個RepublishMessageRecoverer,關聯隊列和交換機
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
完整代碼:
package cn.itcast.mq.config;import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.retry.MessageRecoverer;
import org.springframework.amqp.rabbit.retry.RepublishMessageRecoverer;
import org.springframework.context.annotation.Bean;@Configuration
public class ErrorMessageConfig {@Beanpublic DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");}@Beanpublic Queue errorQueue(){return new Queue("error.queue", true);}@Beanpublic Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");}@Beanpublic MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");}
}
1.5消息可靠性保證總結
如何確保RabbitMQ消息的可靠性?
- 開啟生產者確認機制,確保生產者的消息能到達隊列
- 開啟持久化功能,確保消息未消費前在隊列中不會丟失
- 開啟消費者確認機制為auto或maual,由spring確認消息處理成功后完成ack
- 開啟消費者失敗重試機制,并設置MessageRecoverer,多次重試失敗后將消息投遞到異常交換機,交由人工處理
2.什么是死信交換機
什么是死信?當一個隊列中的消息滿足下列情況之一時,可以成為死信(dead letter):
- 消費者使用
basic.reject或basic.nack聲明消費失敗,并且消息的requeue參數設置為false - 消息是一個過期消息,超時無人消費
- 要投遞的隊列消息滿了,無法投遞
如果這個包含死信的隊列配置了dead-letter-exchange屬性,指定了一個交換機,那么隊列中的死信就會投遞到這個交換機中,而這個交換機稱為死信交換機(Dead Letter Exchange,檢查DLX)。
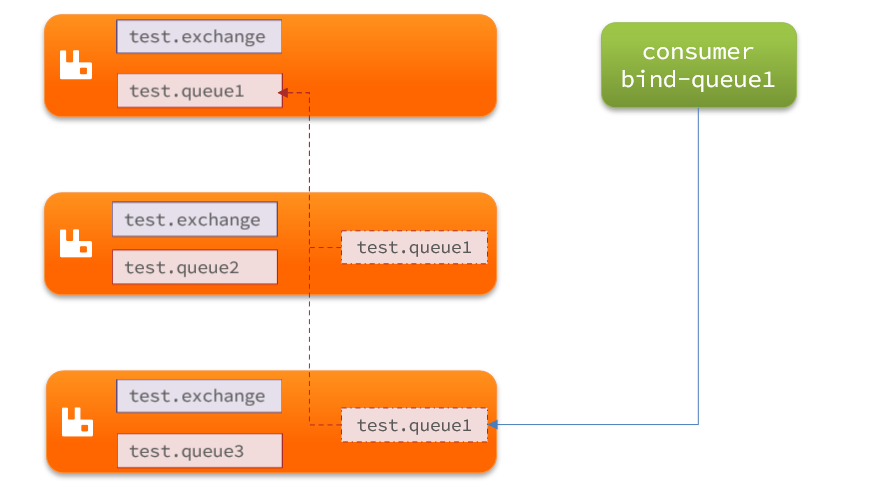
如圖,一個消息被消費者拒絕了,變成了死信,因為simple.queue綁定了死信交換機 dl.direct,因此死信會投遞給這個交換機:
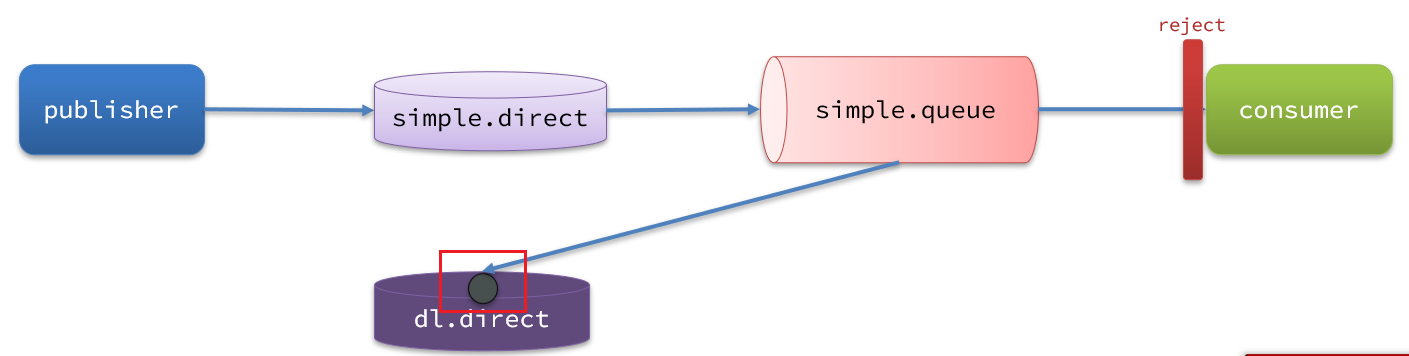
如果這個死信交換機也綁定了一個隊列,則消息最終會進入這個存放死信的隊列:
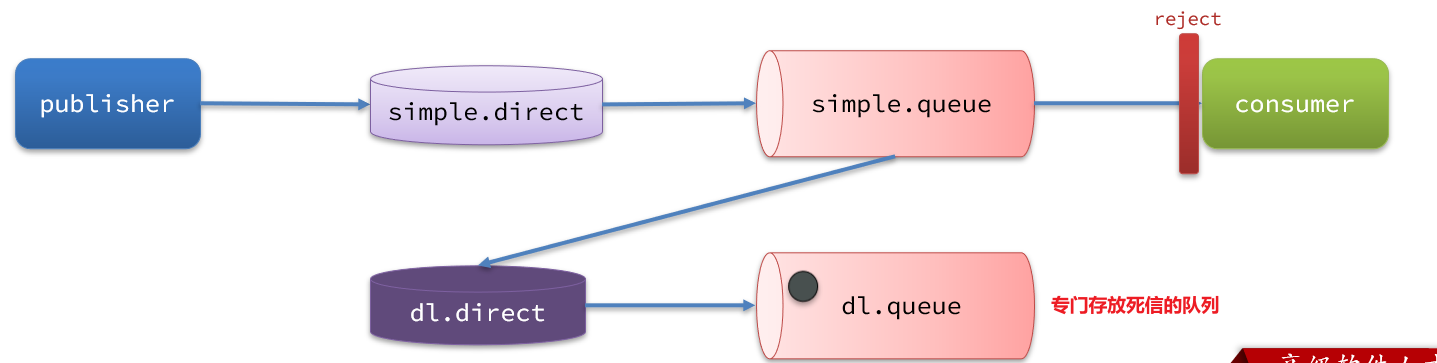
另外,隊列將死信投遞給死信交換機時,必須知道兩個信息,這樣才能確保投遞的消息能到達死信交換機,并且正確的路由到死信隊列。
- 死信交換機名稱
- 死信交換機與死信隊列綁定的RoutingKey
聊到這可能感覺跟上節中的
RepublishMessageRecoverer模式很相似,但上節中消息最終到達消費者并在重試次數耗盡的情況下消息被丟棄,同樣把消息發送到一個交換機,再到一個隊列,我們稱之為異常消息的交換機和異常消息隊列,專門去接收無法處理的消息去做獨立處理。
但兩者還是有差異的,如下圖所示。在RepublishMessageRecoverer模式中所有的失敗消息是由消費者去做投遞的,而在本節是由隊列投遞到死信交換機的,這是兩者的差異。
所以死信交換機也能做到RepublishMessageRecoverer模式這種兜底的效果,只不過死信交換機還會有一些其他的功能和作用。
所以如果只做消息的兜底和異常消息的處理,其實建議只用RepublishMessageRecoverer模式就可以了。
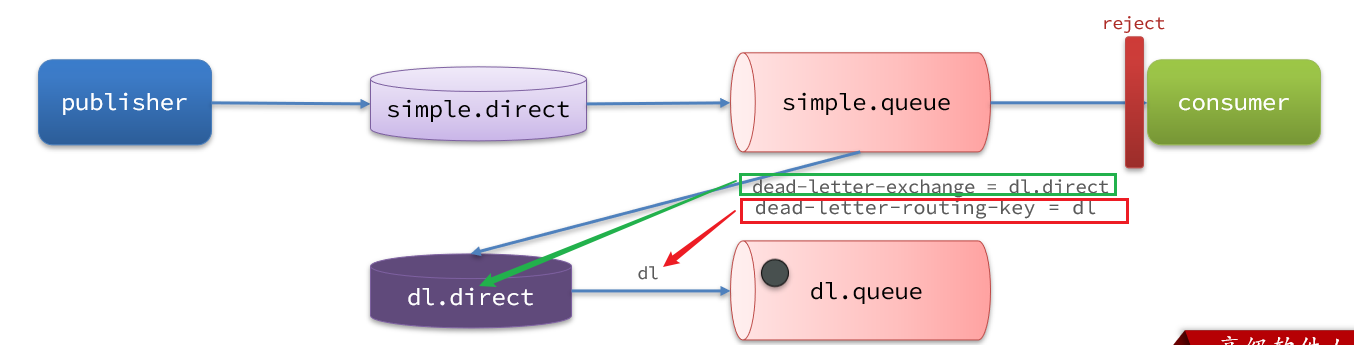
另外這里的小細節需要注意,在RepublishMessageRecoverer模式中,消息是由消費者重新投遞到交換機的,在投遞過程中我們必須指定交換機的名稱,還有就是routingkey,弄錯了就無法到達隊列。而現在我們在死信交換機當中投遞消息的人不是消費者了,而是我們的隊列(如圖中的simple.queue),那隊列再去做消息投遞的時候除了要知道交換機的名字,還得知道死信交換機與死信隊列綁定的key,否則不知道routingkey消息也不能到達死信隊列。
2.1利用死信交換機接收死信
在失敗重試策略中,默認的RejectAndDontRequeueRecoverer失敗策略會在本地重試次數耗盡后,發送reject給RabbitMQ,消息變成死信,被丟棄。
我們可以給simple.queue添加一個死信交換機,給死信交換機綁定一個隊列。這樣消息變成死信后也不會丟棄,而是最終投遞到死信交換機,路由到與死信交換機綁定的隊列。
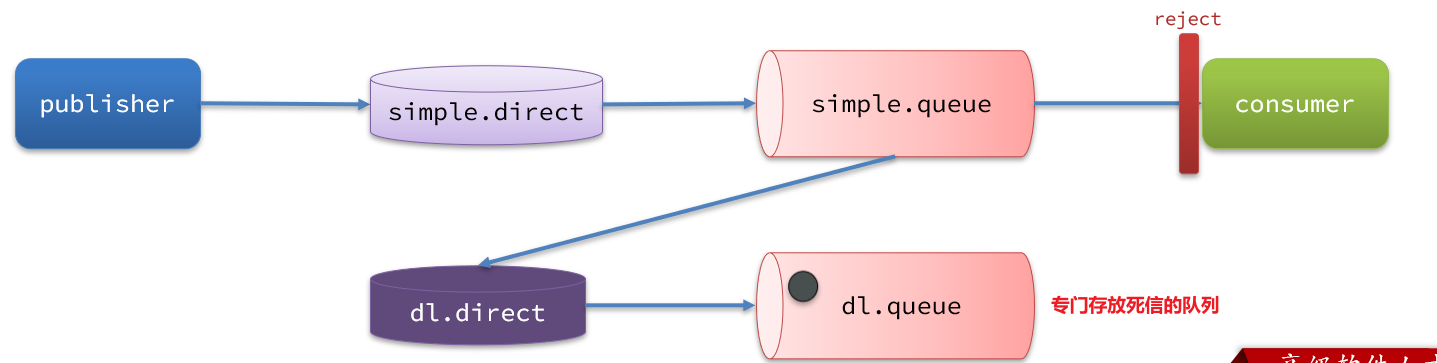
我們在consumer服務中,定義一組死信交換機、死信隊列:
// 聲明普通的 simple.queue隊列,并且為其指定死信交換機:dl.direct
@Bean
public Queue simpleQueue2(){return QueueBuilder.durable("simple.queue") // 指定隊列名稱,并持久化.deadLetterExchange("dl.direct") // 指定死信交換機.build();
}
// 聲明死信交換機 dl.direct
@Bean
public DirectExchange dlExchange(){return new DirectExchange("dl.direct", true, false);
}
// 聲明存儲死信的隊列 dl.queue
@Bean
public Queue dlQueue(){return new Queue("dl.queue", true);
}
// 將死信隊列 與 死信交換機綁定
@Bean
public Binding dlBinding(){return BindingBuilder.bind(dlQueue()).to(dlExchange()).with("simple");
}
總結
什么樣的消息會成為死信?
- 消息被消費者reject或者返回nack
- 消息超時未消費
- 隊列滿了
如何給隊列綁定死信交換機?
- 給隊列設置
dead-letter-exchange屬性,指定一個交換機;- 給隊列設置
dead-letter-routing-key屬性,設置死信交換機與死信隊列的RoutingKey
死信交換機的使用場景是什么?
- 如果隊列綁定了死信交換機,死信會投遞到死信交換機;
- 可以利用死信交換機收集所有消費者處理失敗的消息(死信),交由人工處理,進一步提高消息隊列的可靠性
2.2TTL結合死信交換機實現延遲消息
上一節我們已經簡單認識了死信交換機,它的作用就是來接收隊列中的死信,而死信有三種情況。
第一就是指這個消息消費者處理的時候失敗了且最終呢被拒絕了,而且也不重入隊就變成死信了,那死信交換機就可以用來作為一種兜底的方案來去用;第二種是要投遞的隊列消息滿了,無法投遞;第三種是指消息超時沒有被消費,結果過期了變成了死信,這個就跟我們的延遲消息啊有關系了,所以呢這節我們就一起來了解一下MQ中的TTL超時機制,來實現一下這種延遲消息效果。
TTL,也就是Time-To-Live。如果一個隊列中的消息在TTL結束時仍未消費,則會變為死信,ttl超時分為兩種情況:
- 消息所在的隊列設置了存活時間
- 消息本身設置了存活時間
如下圖所示,有一個消息的發布者,他把消息投遞給一個ttl.direct交換機,而這個交換機呢再與一個叫ttl.queue的隊列形成了一個綁定,ttl.queue呢又綁定了一個死信交換機dl.direct,同時呢這個交換機也綁定了一個死信隊列dl.queue。
現在假設我們有一個消息他自己設置了ttl時間為5000單位是毫秒,那么當我們消息發出去到達了隊列的那一刻他就可以開始倒計時了,倒計時結束啊這個消息就變成了死信,從而投遞到死信交換機,最終到達了我們的死信隊列。這個時候如果恰好有一個消費者在監聽死信隊列,那他肯定就能夠收到這個消息了,那從最后的結果來看是不是生產者發了個消息,結果呢五秒鐘后消費者才拿到,實現了一個延遲投遞消息的效果呀。
除了我們給消息設置ttl以外,我們也可以給這個隊列去設置啊,比如說我給ttl.queue去設置一個ttl,x-message-ttl=10000,那如果說我們的消息和隊列都有自己的ttl,這個時候呢我們就會看哪一個更短,以較小的那個數值為準啊。這個呢就是用死信交換機結合ttl實現延遲消息的原理。
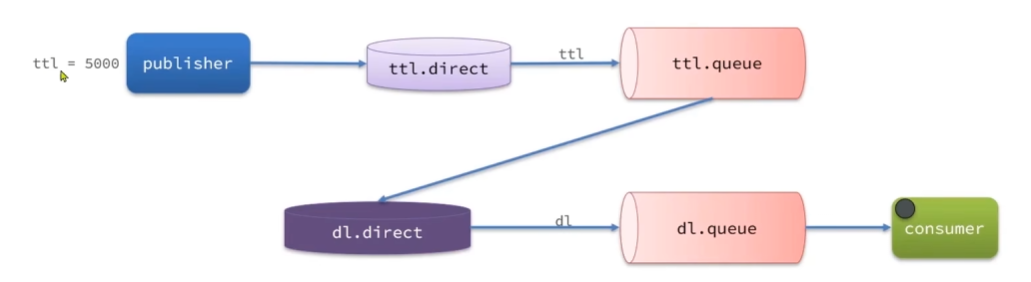
下面根據上圖,我們來實現一下用死信交換機結合ttl實現延遲消息。
1.接收超時死信的死信交換機
在consumer服務的SpringRabbitListener中,定義一個新的消費者,并且聲明 死信交換機、死信隊列:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "dl.ttl.queue", durable = "true"),exchange = @Exchange(name = "dl.ttl.direct"),key = "ttl"
))
public void listenDlQueue(String msg){log.info("接收到 dl.ttl.queue的延遲消息:{}", msg);
}
2.聲明一個隊列,并且指定TTL
要給隊列設置超時時間,需要在聲明隊列時配置x-message-ttl屬性:
@Bean
public Queue ttlQueue(){return QueueBuilder.durable("ttl.queue") // 指定隊列名稱,并持久化.ttl(10000) // 設置隊列的超時時間,10秒.deadLetterExchange("dl.ttl.direct") // 指定死信交換機.build();
}
注意,這個隊列設定了死信交換機為dl.ttl.direct。聲明交換機,將ttl與交換機綁定:
@Bean
public DirectExchange ttlExchange(){return new DirectExchange("ttl.direct");
}
@Bean
public Binding ttlBinding(){return BindingBuilder.bind(ttlQueue()).to(ttlExchange()).with("ttl");
}
發送消息,但是不要指定TTL:
@Test
public void testTTLQueue() {// 創建消息String message = "hello, ttl queue";// 消息ID,需要封裝到CorrelationData中CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 發送消息rabbitTemplate.convertAndSend("ttl.direct", "ttl", message, correlationData);// 記錄日志log.debug("發送消息成功");
}
發送消息的日志:

查看下接收消息的日志:

因為隊列的TTL值是10000ms,也就是10秒。可以看到消息發送與接收之間的時差剛好是10秒。
3.發送消息時,設定TTL
在發送消息時,也可以指定TTL:
@Test
public void testTTLMsg() {// 創建消息Message message = MessageBuilder.withBody("hello, ttl message".getBytes(StandardCharsets.UTF_8)).setExpiration("5000").build();// 消息ID,需要封裝到CorrelationData中CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 發送消息rabbitTemplate.convertAndSend("ttl.direct", "ttl", message, correlationData);log.debug("發送消息成功");
}
查看發送消息日志:

接收消息日志:

這次,發送與接收的延遲只有5秒。說明當隊列、消息都設置了TTL時,任意一個到期就會成為死信。
總結
消息超時的兩種方式是?
- 給隊列設置ttl屬性,進入隊列后超過ttl時間的消息變為死信
- 給消息設置ttl屬性,隊列接收到消息超過ttl時間后變為死信
如何實現發送一個消息20秒后消費者才收到消息?
- 給消息的目標隊列指定死信交換機
- 將消費者監聽的隊列綁定到死信交換機
- 發送消息時給消息設置超時時間為20秒
2.3延遲隊列
利用TTL結合死信交換機,我們實現了消息發出后,消費者延遲收到消息的效果。這種消息模式就稱為延遲隊列(Delay Queue)模式。
延遲隊列的使用場景包括:
- 延遲發送短信
- 用戶下單,如果用戶在15 分鐘內未支付,則自動取消
- 預約工作會議,20分鐘后自動通知所有參會人員
因為延遲隊列的需求非常多,所以RabbitMQ的官方也推出了一個插件,原生支持延遲隊列效果。
這個插件就是DelayExchange插件。參考RabbitMQ的插件列表頁面:
為什么叫DelayExchange呢,使用這個插件的時候它不是基于隊列去做的,而是是基于交換機去做的,我們發消息到交換機,而交換機呢會將這個消息幫你延遲的投遞到隊列里。使用方式可以參考官網地址
下面進行這部分的學習。
1.安裝DelayExchange插件
官方的安裝指南地址
上述文檔是基于linux原生安裝RabbitMQ,然后安裝插件。
因為我們之前是基于Docker安裝RabbitMQ,所以下面我們會講解基于Docker來安裝RabbitMQ插件。
RabbitMQ有一個官方的插件社區,地址,其中包含各種各樣的插件,包括我們要使用的DelayExchange插件
大家可以去對應的GitHub頁面下載3.8.9版本的插件,地址
因為我們是基于Docker安裝,所以需要先查看RabbitMQ的插件目錄對應的數據卷。如果不是基于Docker的,請參考第一章部分,重新創建Docker容器。
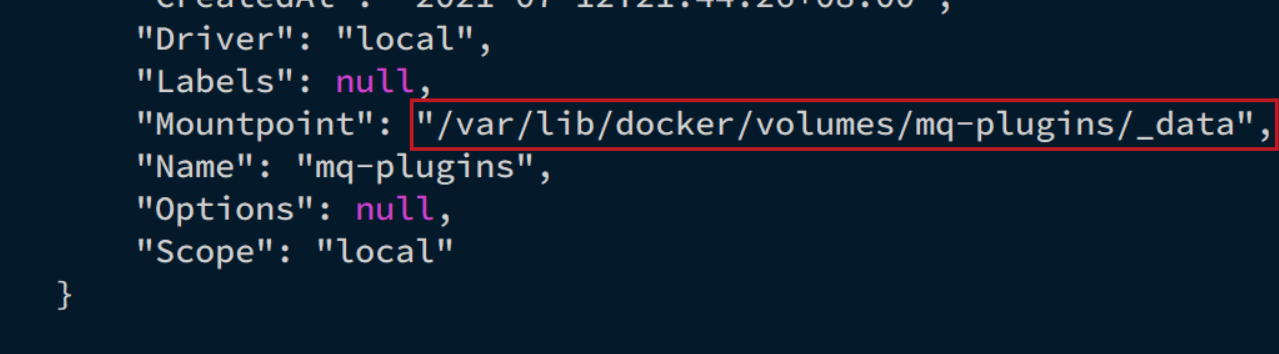
我們之前設定的RabbitMQ的數據卷名稱為mq-plugins,所以我們使用下面命令查看數據卷:
docker volume inspect mq-plugins
可以得到下面結果:
接下來,將插件上傳到這個目錄即可:
最后就是安裝了,需要進入MQ容器內部來執行安裝。我的容器名為mq,所以執行下面命令:
docker exec -it mq bash
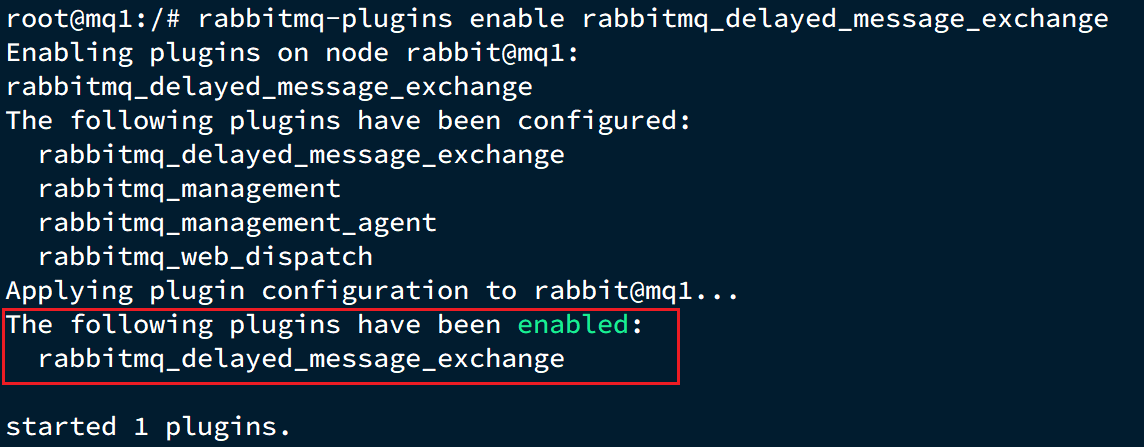
執行時,請將其中的 -it 后面的mq替換為你自己的容器名.進入容器內部后,執行下面命令開啟插件:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
結果如下:
2.DelayExchange原理
DelayExchange插件的原理是對官方原生的Exchange做了功能的升級:
- 將DelayExchange接受到的消息暫存在內存中(官方的Exchange是無法存儲消息的)
- 在DelayExchange中計時,超時后才投遞消息到隊列中
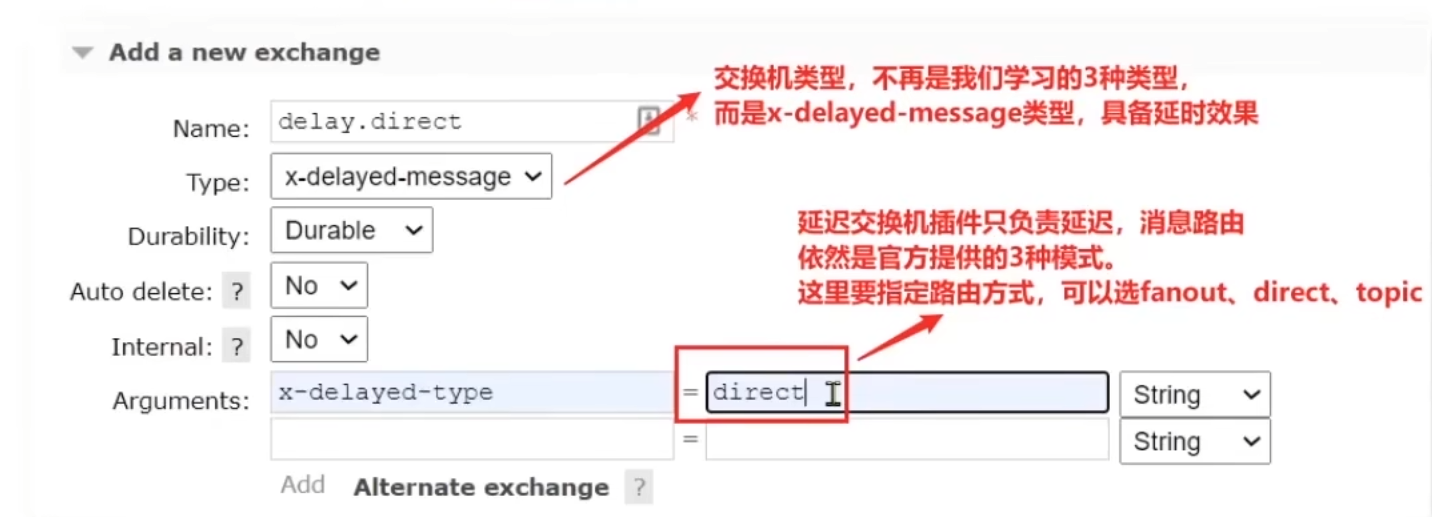
在RabbitMQ的管理平臺聲明一個DelayExchange:
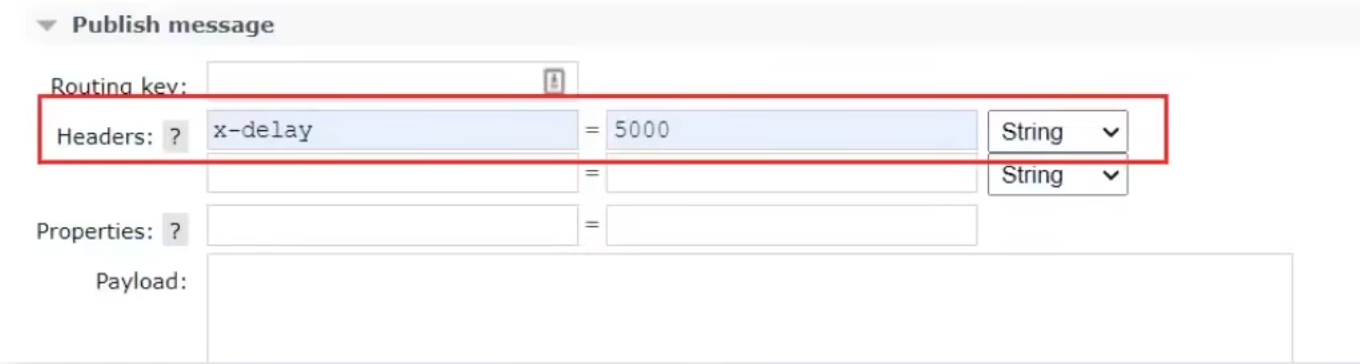
消息的延遲時間需要在發送消息的時候指定:
DelayExchange需要將一個交換機聲明為delayed類型。當我們發送消息到delayExchange時,流程如下:
- 接收消息
- 判斷消息是否具備
x-delay屬性 - 如果有
x-delay屬性,說明是延遲消息,持久化到硬盤,讀取x-delay值,作為延遲時間 - 返回
routing not found結果給消息發送者 x-delay時間到期后,重新投遞消息到指定隊列
消息發送者發送完消息后:
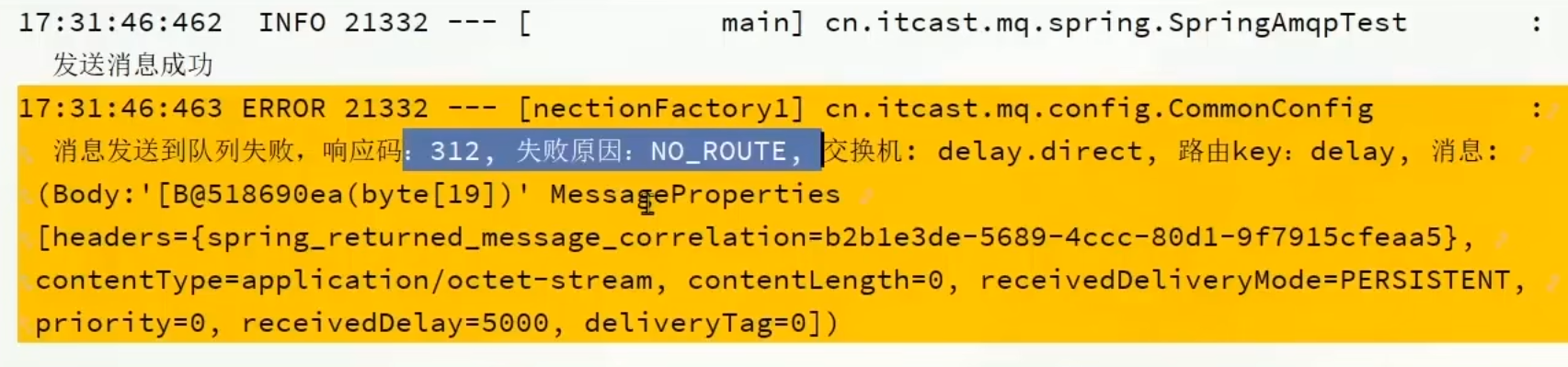
但是這個報錯是我們不需要的,可以去ReturnCallback中配置一下不報這個錯:
3.使用DelayExchange
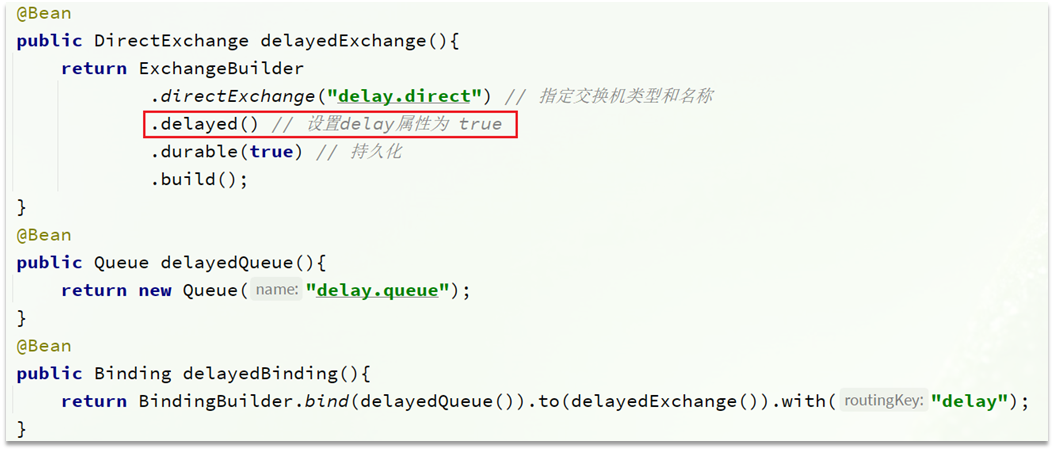
插件的使用也非常簡單:聲明一個交換機,交換機的類型可以是任意類型,只需要設定delayed屬性為true即可,然后聲明隊列與其綁定即可。
1)聲明DelayExchange交換機
基于注解方式(推薦):

也可以基于@Bean的方式:
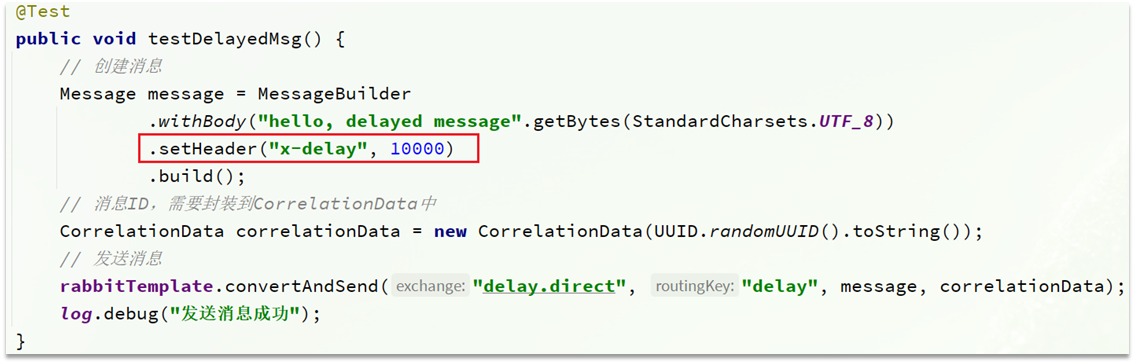
2)發送消息
發送消息時,一定要攜帶x-delay屬性,指定延遲的時間:
總結
延遲隊列插件的使用步驟包括哪些?
- 聲明一個交換機,添加delayed屬性為true
- 發送消息時,添加x-delay頭,值為超時時間
3.消息堆積問題與惰性隊列
當生產者發送消息的速度超過了消費者處理消息的速度,就會導致隊列中的消息堆積,直到隊列存儲消息達到上限。之后發送的消息就會成為死信,可能會被丟棄,這就是消息堆積問題。
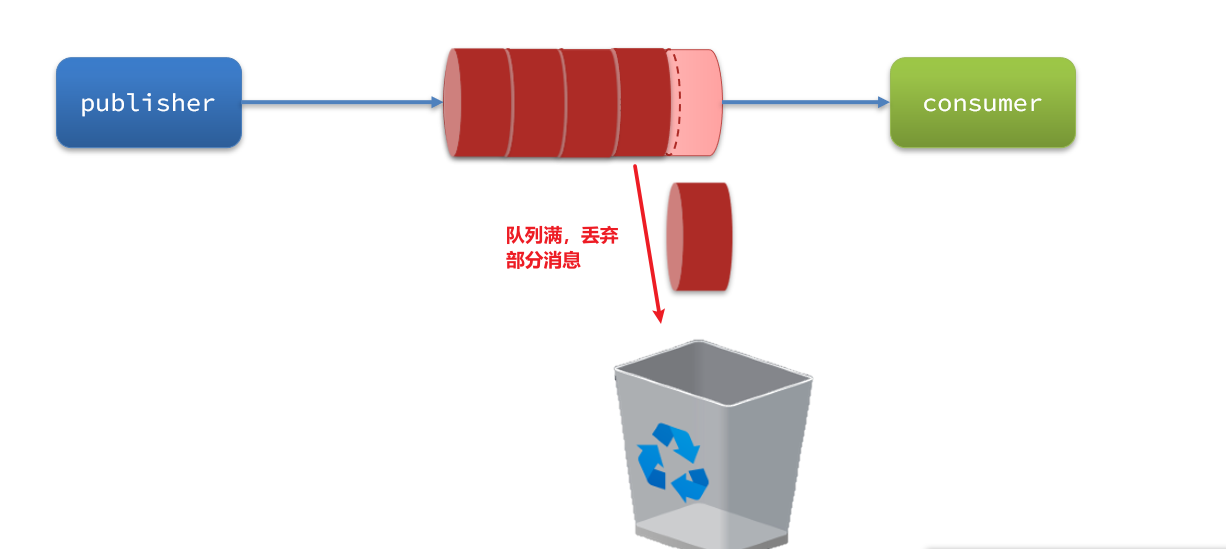
解決消息堆積有兩種思路:
- 增加更多消費者,提高消費速度。也就是我們之前說的work queue模式
- 擴大隊列容積,提高堆積上限
要提升隊列容積,把消息保存在內存中顯然是不行的。
從RabbitMQ的3.6.0版本開始,就增加了Lazy Queues的概念,也就是惰性隊列。惰性隊列的特征如下:
- 接收到消息后直接存入磁盤而非內存
- 消費者要消費消息時才會從磁盤中讀取并加載到內存
- 支持數百萬條的消息存儲
下面進行學習。
1.基于命令行設置lazy-queue
而要設置一個隊列為惰性隊列,只需要在聲明隊列時,指定x-queue-mode屬性為lazy即可。可以通過命令行將一個運行中的隊列修改為惰性隊列:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
命令解讀:
rabbitmqctl:RabbitMQ的命令行工具set_policy:添加一個策略Lazy:策略名稱,可以自定義"^lazy-queue$":用正則表達式匹配隊列的名字'{"queue-mode":"lazy"}':設置隊列模式為lazy模式--apply-to queues:策略的作用對象,是所有的隊列
2.基于@Bean聲明lazy-queue

3.基于@RabbitListener聲明LazyQueue
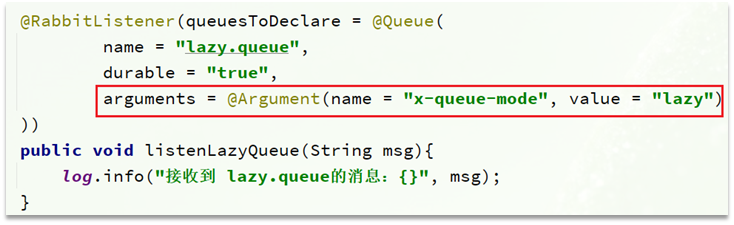
下面測試普通隊列和惰性隊列的區別:

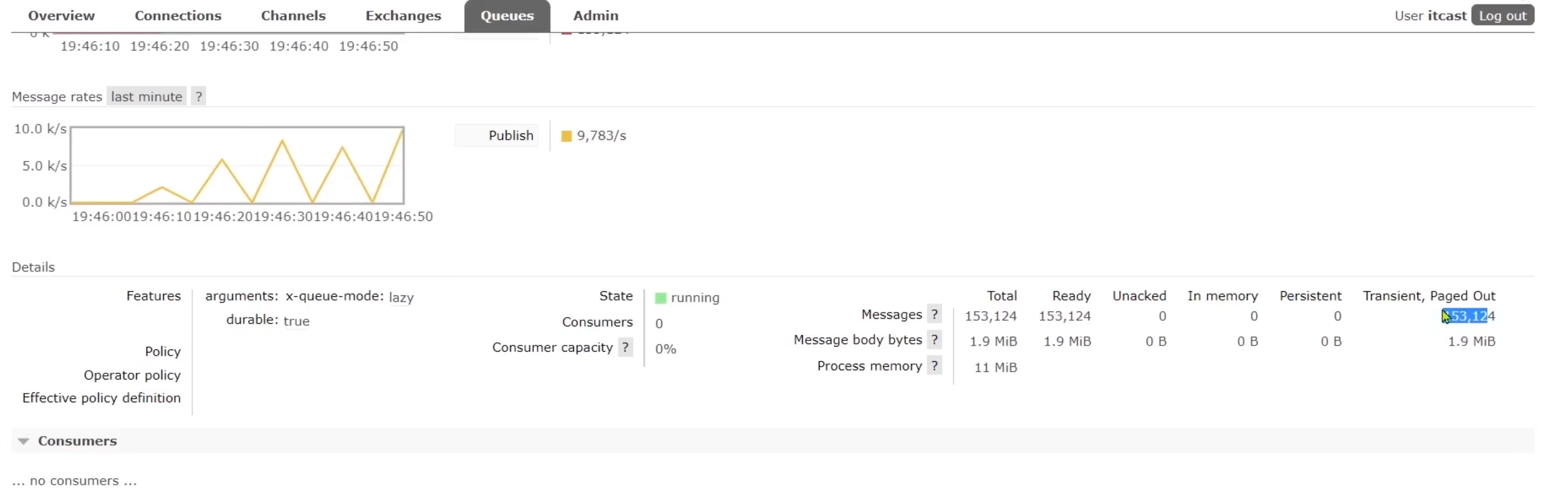
快速向兩個隊列發送100萬條消息,觀察控制臺發現惰性隊列的消息全在磁盤中,內存中一條都沒有。
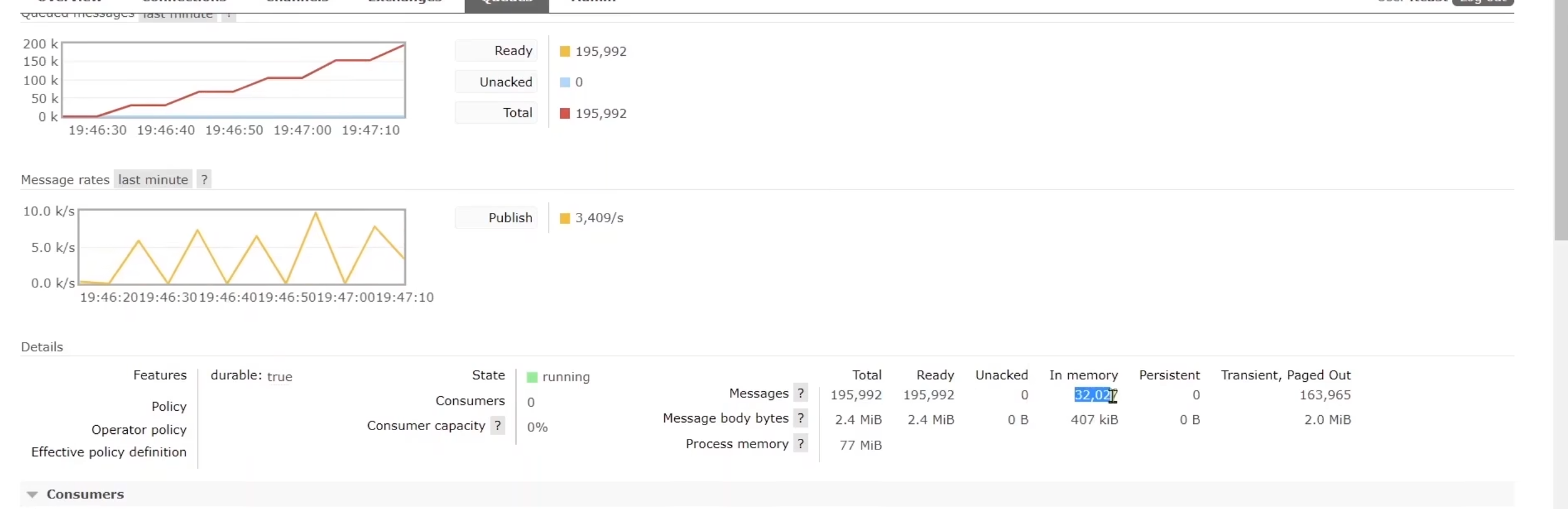
而普通隊列中是內存在波動,每次達到了3萬多條的時候就會刷去一部分到磁盤,會有一個暫停,刷出去了再允許消息來,所以他的穩定性就不是很好。
總結
消息堆積問題的解決方案?
- 隊列上綁定多個消費者,提高消費速度
- 使用惰性隊列,可以再mq中保存更多消息
惰性隊列的優點有哪些?
- 基于磁盤存儲,消息上限高
- 沒有間歇性的page-out,性能比較穩定
惰性隊列的缺點有哪些?
- 基于磁盤存儲,消息時效性會降低
- 性能受限于磁盤的IO
4.MQ集群
RabbitMQ的是基于Erlang語言編寫,而Erlang又是一個面向并發的語言,天然支持集群模式。RabbitMQ的集群有兩種模式:
-
普通集群:是一種分布式集群,將隊列分散到集群的各個節點,從而提高整個集群的并發能力。
-
- 普通模式集群不進行數據同步,每個MQ都有自己的隊列、數據信息(其它元數據信息如交換機等會同步)。例如我們有2個MQ:mq1,和mq2,如果你的消息在mq1,而你連接到了mq2,那么mq2會去mq1拉取消息,然后返回給你。如果mq1宕機,消息就會丟失。
-
鏡像集群:是一種主從集群,普通集群的基礎上,添加了主從備份功能,提高集群的數據可用性。如果一個節點宕機,并不會導致數據丟失。不過,這種方式增加了數據同步的帶寬消耗。
鏡像集群雖然支持主從,但主從同步并不是強一致的,某些情況下可能有數據丟失的風險。因此在RabbitMQ的3.8版本以后,推出了新的功能:使用仲裁隊列來代替鏡像集群,底層采用Raft協議確保主從的數據一致性。
4.1普通集群
普通集群,或者叫標準集群(classic cluster),具備下列特征:
- 會在集群的各個節點間共享部分數據,包括:交換機、隊列元信息。不包含隊列中的消息。
- 當訪問集群某節點時,如果隊列不在該節點,會從數據所在節點傳遞到當前節點并返回
- 隊列所在節點宕機,隊列中的消息就會丟失
我們先來部署普通模式集群,我們的計劃部署3節點的mq集群:
| 主機名 | 控制臺端口 | amqp通信端口 |
|---|---|---|
| mq1 | 8081 —> 15672 | 8071 —> 5672 |
| mq2 | 8082 —> 15672 | 8072 —> 5672 |
| mq3 | 8083 —> 15672 | 8073 —> 5672 |
這里控制臺端口的暴露是8081~8083,為什么暴露成8081~8083而不是15672呢?因為我們是在一個虛擬機的機器里,都是15672就沖突了。除了控制臺端口還有一個mq的通信端口,也是一樣的,mq通信端口默認是5672,這里用8071~8073進行區分。
集群中的節點標示默認都是:rabbit@[hostname],因此以上三個節點的名稱分別為:
- rabbit@mq1
- rabbit@mq2
- rabbit@mq3
1.獲取cookie
RabbitMQ底層依賴于Erlang,而Erlang虛擬機就是一個面向分布式的語言,默認就支持集群模式。集群模式中的每個RabbitMQ 節點使用 cookie 來確定它們是否被允許相互通信。
要使兩個節點能夠通信,它們必須具有相同的共享秘密,稱為Erlang cookie。cookie 只是一串最多 255 個字符的字母數字字符。
每個集群節點必須具有相同的 cookie。實例之間也需要它來相互通信。
我們先在之前啟動的mq容器中獲取一個cookie值,作為集群的cookie。執行下面的命令:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.cookie
可以看到cookie值如下:
FXZMCVGLBIXZCDEMMVZQ
接下來,停止并刪除當前的mq容器,我們重新搭建集群。
docker rm -f mq
清理一下數據卷:
docker volume prune
# 刪除所有未使用的數據卷(最好別隨便用)
2.準備集群配置
在/tmp目錄新建一個配置文件 rabbitmq.conf:
cd /tmp
# 創建文件
touch rabbitmq.conf
文件內容如下:
loopback_users.guest = false
listeners.tcp.default = 5672
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@mq1
cluster_formation.classic_config.nodes.2 = rabbit@mq2
cluster_formation.classic_config.nodes.3 = rabbit@mq3
loopback_users.guest = false禁用guest用戶,rabbitmq默認有個guest用戶,禁用防止不法分子訪問
listeners.tcp.default = 5672監聽的端口,5672mq消息通信用的這個端口
下面三個配的是集群中的節點信息
再創建一個文件,記錄cookie
cd /tmp
# 創建cookie文件
touch .erlang.cookie
# 寫入cookie
echo "FXZMCVGLBIXZCDEMMVZQ" > .erlang.cookie
# 修改cookie文件的權限,改成只讀,只有root能讀寫
chmod 600 .erlang.cookie
準備三個目錄,mq1、mq2、mq3:
cd /tmp
# 創建目錄
mkdir mq1 mq2 mq3
然后拷貝rabbitmq.conf、cookie文件到mq1、mq2、mq3:
# 進入/tmp
cd /tmp
# 拷貝
cp rabbitmq.conf mq1
cp rabbitmq.conf mq2
cp rabbitmq.conf mq3
cp .erlang.cookie mq1
cp .erlang.cookie mq2
cp .erlang.cookie mq3
3.啟動集群
創建一個網絡以供三個mq互聯:
docker network create mq-net
運行命令,第一個mq結點:
docker run -d --net mq-net \
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq1 \
--hostname mq1 \
-p 8071:5672 \
-p 8081:15672 \
rabbitmq:3.8-management
docker run -d --net mq-net \加入網絡
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \數據卷掛載:將當前的配置文件掛載到容器里
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \再掛載cookie文件到容器中的cookie文件中去
-e RABBITMQ_DEFAULT_USER=itcast \用戶名與密碼
--name mq1 \容器名
--hostname mq1 \主機名
-p 8071:5672 \端口映射 5672映射成8071
-p 8081:15672 \15672映射成8081
第二個mq結點:
docker run -d --net mq-net \
-v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq2 \
--hostname mq2 \
-p 8072:5672 \
-p 8082:15672 \
rabbitmq:3.8-management
容器名、主機名還有端口映射改了
第三個mq結點:
docker run -d --net mq-net \
-v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq3 \
--hostname mq3 \
-p 8073:5672 \
-p 8083:15672 \
rabbitmq:3.8-management
4.測試
可以通過下面的命令看mq1的運行狀態
docker logs -f mq1
前端訪問mq:192.168.150.101:8081,在mq1這個節點上添加一個隊列:
如圖,在mq2和mq3兩個控制臺也都能看到:
1)數據共享測試
點擊這個隊列,進入管理頁面:
然后利用控制臺發送一條消息到這個隊列:
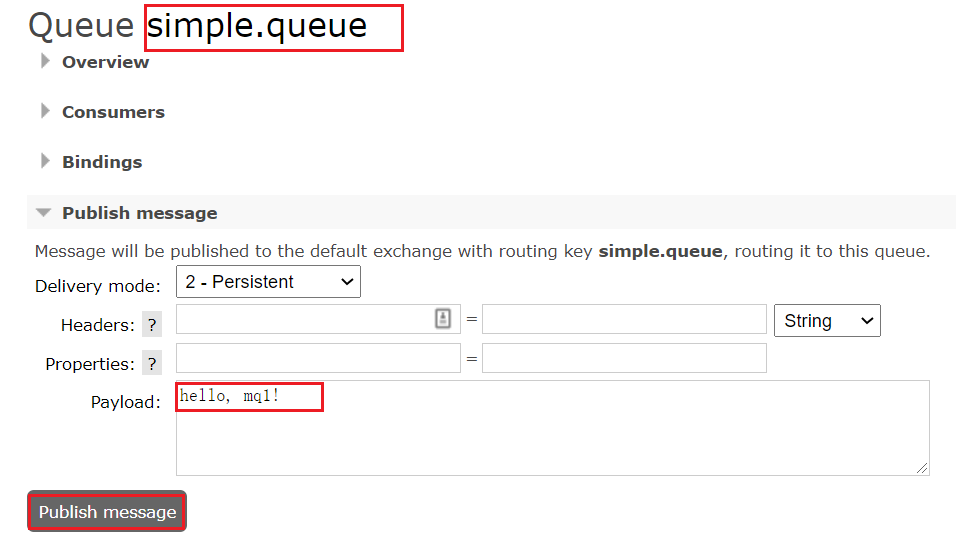
結果在mq2、mq3上都能看到這條消息,因為之前介紹了,雖然在mq2和3里這僅僅是個引用,但是當我來取消息的時候可以從另外一節點把消息傳過來給你,所以你在任意一個節點其實都能看到這個數據。
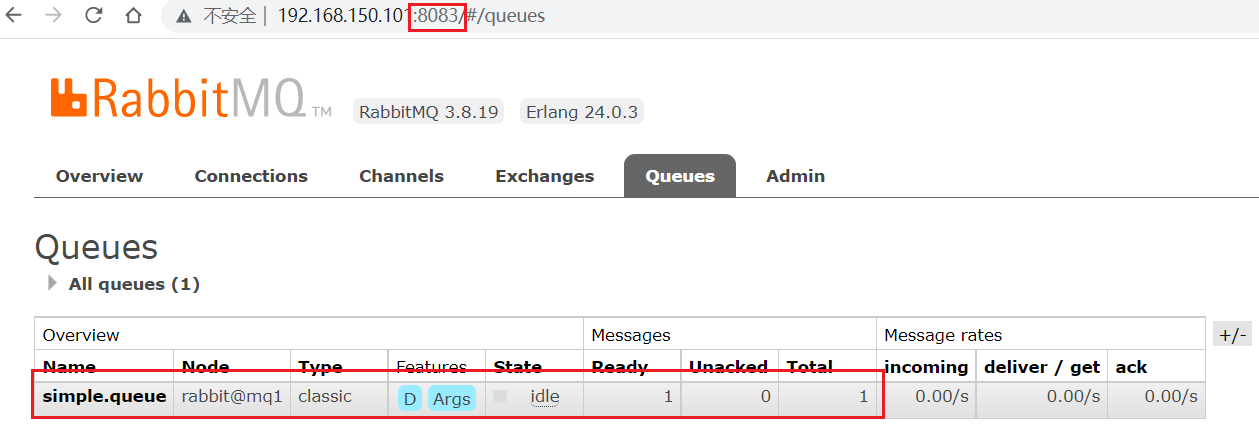
我們讓其中一臺節點mq1宕機:
docker stop mq1
然后登錄mq2或mq3的控制臺,發現simple.queue也不可用了:
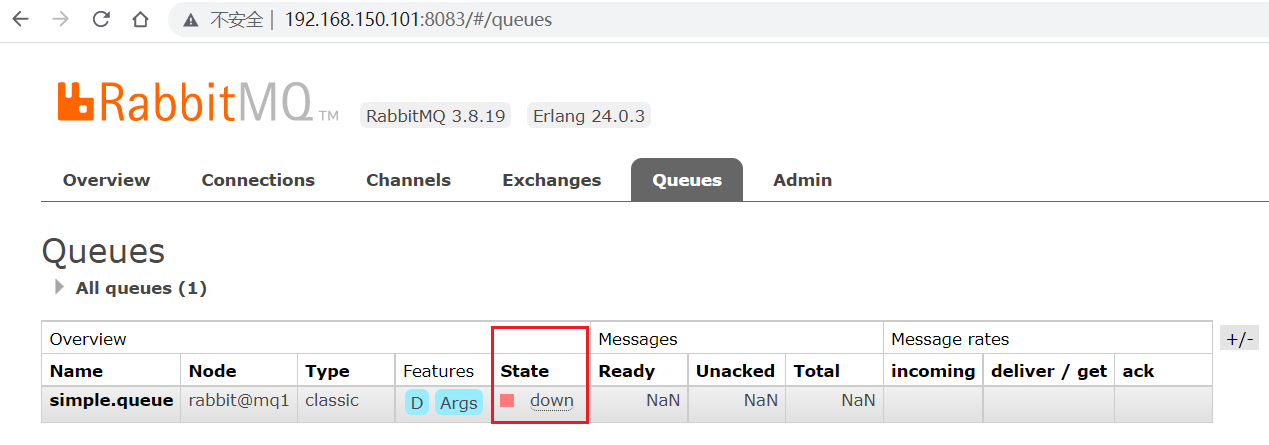
因為他其實只是個引用,如果聲明這個隊列的節點掛了,那這個隊列就不能用了。說明普通集群的隊列是沒有實現共享的。要想數據恢復,除非mq1重新啟動。
4.2鏡像集群
鏡像集群:本質是主從模式,具備下面的特征:
- 交換機、隊列、隊列中的消息會在各個mq的鏡像節點之間同步備份。
- 創建隊列的節點被稱為該隊列的主節點,備份到的其它節點叫做該隊列的鏡像節點。
- 一個隊列的主節點可能是另一個隊列的鏡像節點
- 所有操作都是主節點完成,然后同步給鏡像節點
- 主宕機后,鏡像節點會替代成新的主
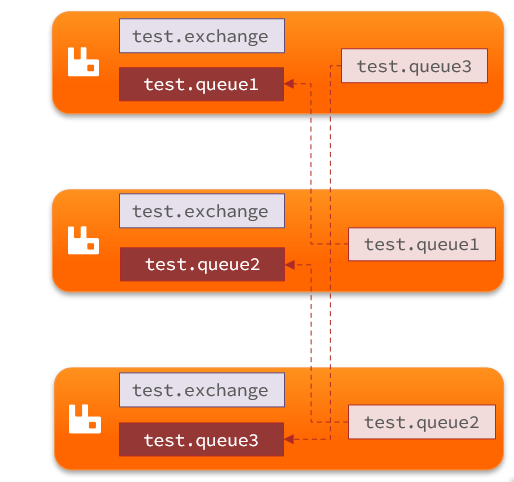
比如上圖,q1的備份在節點2上,又來個q2在結點2上,但是它在結點3上有個備份,q3在結點3上,可以在結點1上有個備份。
此時,結點1是隊列1的主節點,同時又是隊列3的鏡像節點,這種相互備份也可以保證安全性。
在剛剛的案例中,一旦創建隊列的主機宕機,隊列就會不可用。不具備高可用能力。如果要解決這個問題,必須使用官方提供的鏡像集群方案。官方文檔地址
1.鏡像模式的特征
默認情況下,隊列只保存在創建該隊列的節點上。而鏡像模式下,創建隊列的節點被稱為該隊列的主節點,隊列還會拷貝到集群中的其它節點,也叫做該隊列的鏡像節點。
但是,不同隊列可以在集群中的任意節點上創建,因此不同隊列的主節點可以不同。甚至,一個隊列的主節點可能是另一個隊列的鏡像節點。
用戶發送給隊列的一切請求,例如發送消息、消息回執默認都會在主節點完成,如果是從節點接收到請求,也會路由到主節點去完成。鏡像節點僅僅起到備份數據作用。
當主節點接收到消費者的ACK時,所有鏡像都會刪除節點中的數據。
總結如下:
- 鏡像隊列結構是一主多從(從就是鏡像)
- 所有操作都是主節點完成,然后同步給鏡像節點
- 主宕機后,鏡像節點會替代成新的主(如果在主從同步完成前,主就已經宕機,可能出現數據丟失)
- 不具備負載均衡功能,因為所有操作都會有主節點完成(但是不同隊列,其主節點可以不同,可以利用這個提高吞吐量)
2.鏡像模式的配置
鏡像模式的配置有3種模式,通過ha-mode指定模式,分別是exactly、all和nodes三種模式。
比如使用exactly模式,那么需要指定一個count參數,count = 鏡像數量 + 1,如果count為1,那么鏡像數量就為0,所以一般count大于等于2。比如說我現在有一個三節點形成的mq集群,count為2,除了我當前主節點以外,還會從另外兩個節點里隨機挑一個作為鏡像,這就是準確模式的含義。
all模式就簡單了,我不管三七二十一,比如說你有三個節點,現在呢你在第一個節點上創建了隊列,那剩下兩個自然就成為我的鏡像了。同樣的我在第二個節點創建的隊列,那么其他兩個節點一和三也會成為我的鏡像,即全部節點都會去備份。這個模式對磁盤和網絡都會有額外的壓力。
nodes模式就是我在去創建主節點和鏡像節點的時候,不再隨機了,而他是個指定說哎我就要那個節點,把節點的名稱,就是它的標識而設置出來(比如之前我們搭建的某個節點rabbit@mq1),那這種呢一般情況下就是你對這個機器的特征,比如說它的硬件配置你有詳細的了解才去指定。
| ha-mode | ha-params | 效果 |
|---|---|---|
| 準確模式exactly | 隊列的副本量count | 集群中隊列副本(主服務器和鏡像服務器之和)的數量。count如果為1意味著單個副本:即隊列主節點。count值為2表示2個副本:1個隊列主和1個隊列鏡像。換句話說:count = 鏡像數量 + 1。如果群集中的節點數少于count,則該隊列將鏡像到所有節點。如果有集群總數大于count+1,并且包含鏡像的節點出現故障,則將在另一個節點上創建一個新的鏡像。 |
| all | (none) | 隊列在群集中的所有節點之間進行鏡像。隊列將鏡像到任何新加入的節點。鏡像到所有節點將對所有群集節點施加額外的壓力,包括網絡I / O,磁盤I / O和磁盤空間使用情況。推薦使用exactly,設置副本數為(N / 2 +1)。 |
| nodes | node names | 指定隊列創建到哪些節點,如果指定的節點全部不存在,則會出現異常。如果指定的節點在集群中存在,但是暫時不可用,會創建節點到當前客戶端連接到的節點。 |
這里我們以rabbitmqctl命令作為案例來講解配置語法。
1)exactly模式
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy:固定寫法ha-two:策略名稱,自定義"^two\.":匹配隊列的正則表達式,符合命名規則的隊列才生效,這里是任何以two.開頭的隊列名稱'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}': 策略內容"ha-mode":"exactly":策略模式,此處是exactly模式,指定副本數量"ha-params":2:策略參數,這里是count=2,就是副本數量為2,1主1鏡像"ha-sync-mode":"automatic":同步策略,默認是manual,即新加入的鏡像節點不會同步舊的消息。如果設置為automatic,則新加入的鏡像節點會把主節點中所有消息都同步,會帶來額外的網絡開銷
2)all模式
rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'
ha-all:策略名稱,自定義"^all\.":匹配所有以all.開頭的隊列名'{"ha-mode":"all"}':策略內容"ha-mode":"all":策略模式,此處是all模式,即所有節點都會稱為鏡像節點
3)nodes模式
rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
rabbitmqctl set_policy:固定寫法ha-nodes:策略名稱,自定義"^nodes\.":匹配隊列的正則表達式,符合命名規則的隊列才生效,這里是任何以nodes.開頭的隊列名稱'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}': 策略內容"ha-mode":"nodes":策略模式,此處是nodes模式"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略參數,這里指定副本所在節點名稱
3.測試
我們測試使用exactly模式的鏡像,因為集群節點數量為3,因此鏡像數量就設置為2.
運行下面的命令,進入任意一個結點都行:
docker exec -it mq1 bash
然后輸入命令:
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
或者直接一個命令:
docker exec -it mq1 rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
此時隨便訪問一個結點的Admin的Policies界面可以看到我們配的策略:
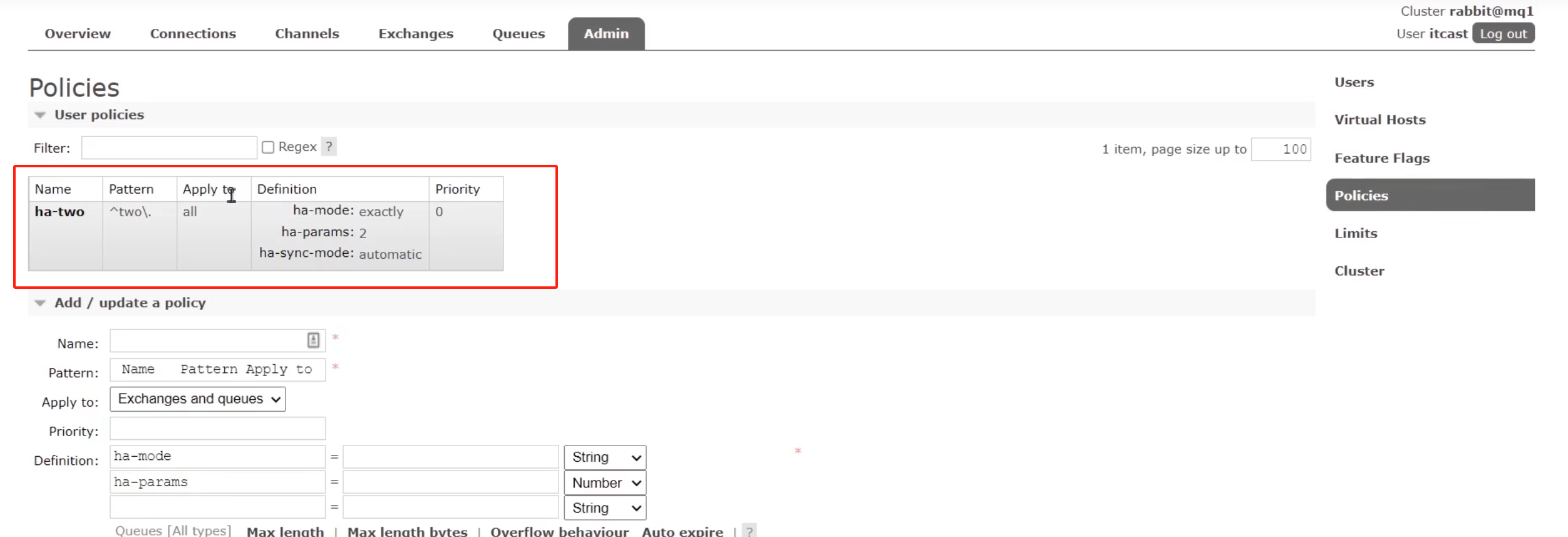
下面,我們創建一個新的隊列:
在任意一個mq控制臺查看隊列,這個節點它的名稱后面來了個加一,就是有一個mirror,鏡像的意思,那不用說,我在這個節點上去寫消息,另外的鏡像節點也能看到了。這里節點2是節點1的鏡像節點,節點3也能看到,但僅僅是引用(類似普通集群)。
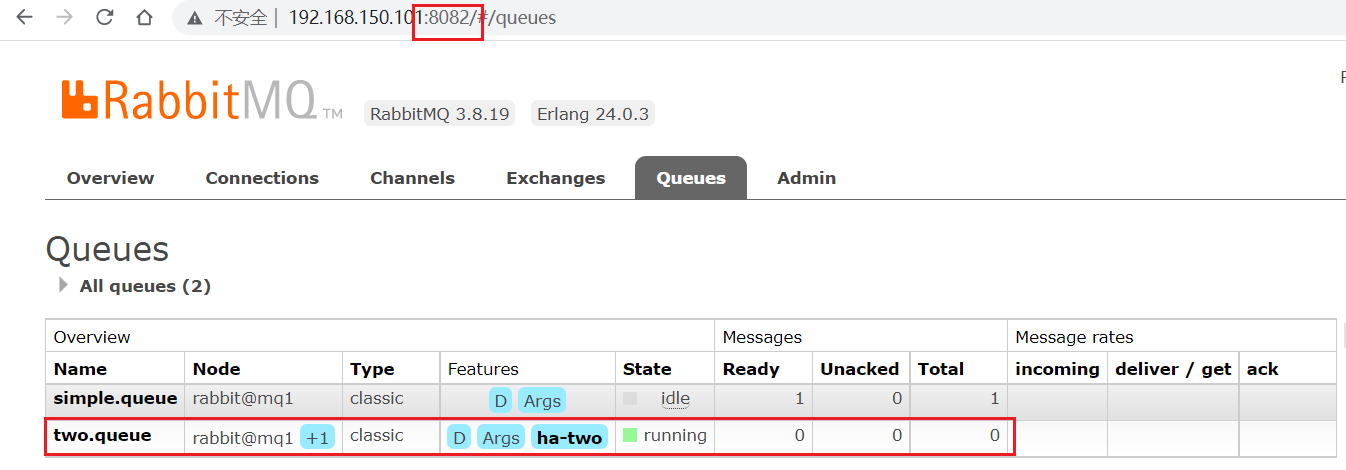
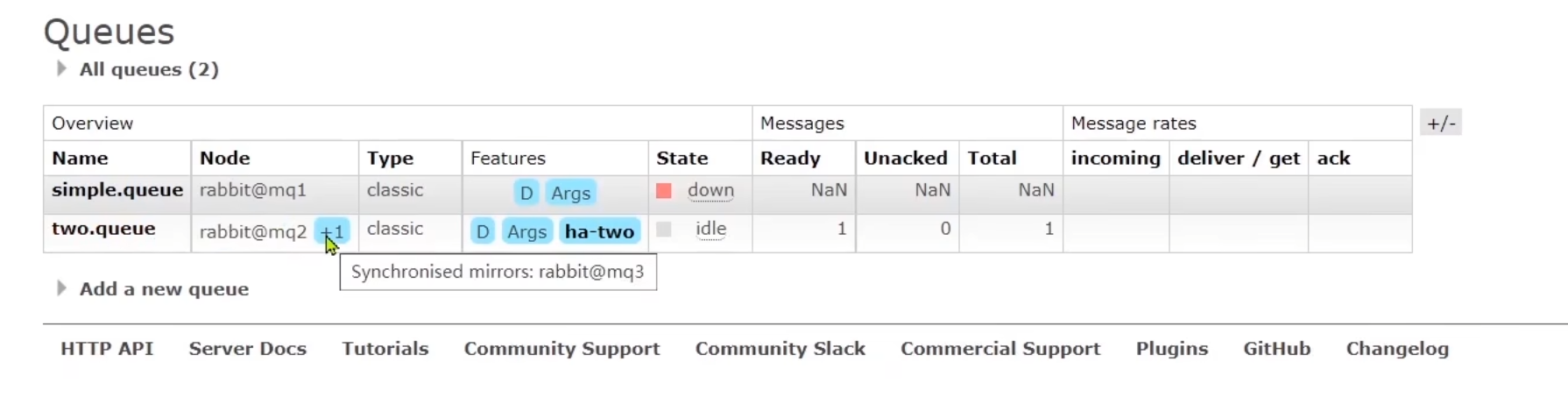
此時讓mq1宕機,mq2就成為了該隊列的主節點,并且mq3成為了鏡像節點,非常強大。此時再啟動mq1,這個隊列就跟它沒關系了。
4.3仲裁隊列
鏡像隊列他雖然能夠做主從,但是啊主從同步時可能會有數據丟失的風險,因為它不是這種強一致的啊,但仲裁隊列了就可以解決這些問題。
仲裁隊列:仲裁隊列是3.8版本以后才有的新功能,用來替代鏡像隊列,但使用更加方便,具備下列特征:
- 與鏡像隊列一樣,都是主從模式,支持主從數據同步
- 使用非常簡單,沒有復雜的配置(鏡像隊列命令復雜,設置模式、還有模式對應參數),而仲裁隊列已經把這些東西設成默認的了,默認count=5
- 主從同步基于Raft協議,強一致,不用擔心數據丟失
1.添加仲裁隊列
仲裁隊列的配置非常簡單,直接在任意控制臺添加一個隊列,但是一定要選擇隊列類型為Quorum類型。這里我們的集群已有三個健康的結點,我們進行配置,設置mq1為主節點:
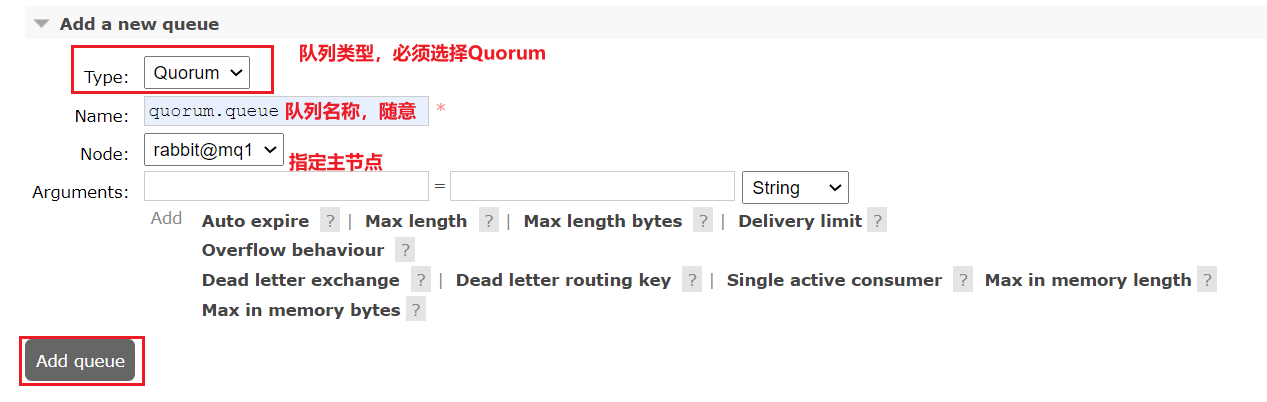
在任意控制臺查看隊列:
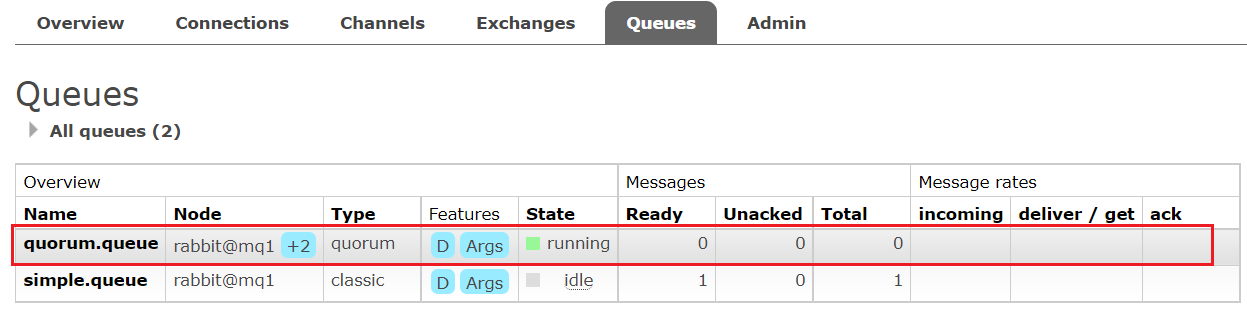
可以看到,仲裁隊列的 + 2字樣。代表這個隊列有2個鏡像節點。
因為仲裁隊列默認的鏡像數為5。如果你的集群有7個節點,那么從結點數肯定是4;而我們集群只有3個節點,那就成all模式了,因此從結點數量就是2.
2.測試
測試這里省略。可以參考對鏡像集群的測試,效果是一樣的。
3.集群擴容
(1)加入集群
啟動一個新的MQ容器:
docker run -d --net mq-net \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq4 \
--hostname mq5 \
-p 8074:15672 \
-p 8084:15672 \
rabbitmq:3.8-management
進入容器控制臺:
docker exec -it mq4 bash
停止mq進程
rabbitmqctl stop_app
重置RabbitMQ中的數據:
rabbitmqctl reset
加入mq1:
rabbitmqctl join_cluster rabbit@mq1
再次啟動mq進程:
rabbitmqctl start_app

(2)增加仲裁隊列副本
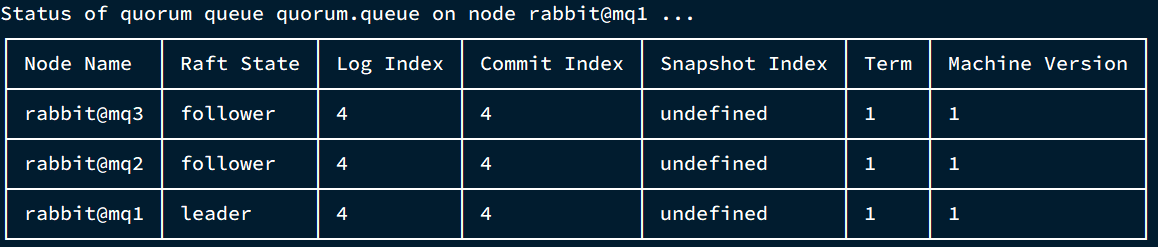
我們先查看下quorum.queue這個隊列目前的副本情況,進入mq1容器:
docker exec -it mq1 bash
執行命令:
rabbitmq-queues quorum_status "quorum.queue"
結果:
現在,我們讓mq4也加入進來:
rabbitmq-queues add_member "quorum.queue" "rabbit@mq4"
結果:

再次查看:
rabbitmq-queues quorum_status "quorum.queue"
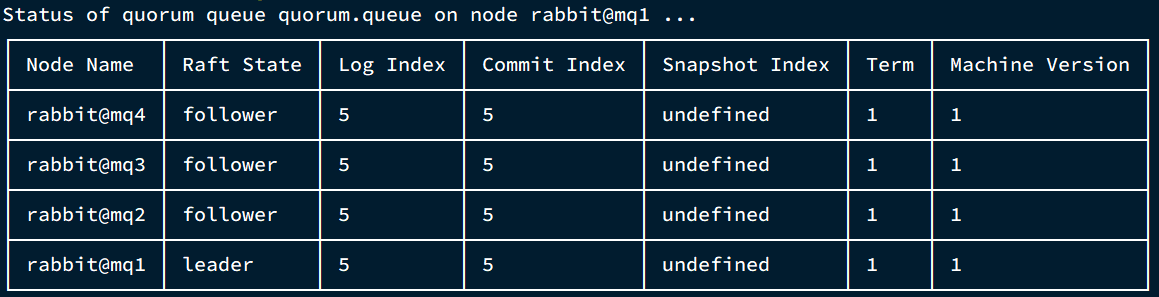
查看控制臺,發現quorum.queue的鏡像數量也從原來的 +2 變成了 +3:
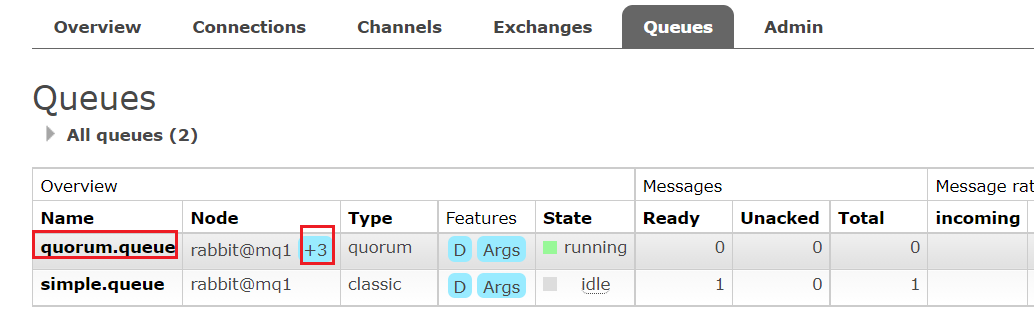
4.Java代碼創建仲裁隊列
上面搭建了仲裁隊列集群,是基于瀏覽器的控制臺去做的。但最終我們肯定還要用iava代碼來做。
其實啊仲裁隊列本身就是一個普通的隊列,集群搭建好了以后你只要創建它就能形成集群了,那因此呢我們這里的代碼也非常的簡單,僅僅是聲明了一個bean,然后呢就是一個隊列,區別在于我們這里多了一個.quorum(),那么這個就是標記當前隊列是一個仲裁隊列,那么將來呢我們的集群就會自動給它形成主和鏡像了,所以非常的簡單。
@Bean
public Queue quorumQueue() {return QueueBuilder.durable("quorum.queue") // 持久化.quorum() // 仲裁隊列.build();
}
5.SpringAMQP連接MQ集群
之前的代碼我們連接的是單點mq:
那你連一個mq這么寫,但現在是集群呀,有8071、8072、8073好幾個,怎么寫呢?
注意,這里用address來代替host、port方式
spring:rabbitmq:addresses: 192.168.150.105:8071, 192.168.150.105:8072, 192.168.150.105:8073username: itcastpassword: 123321virtual-host: /
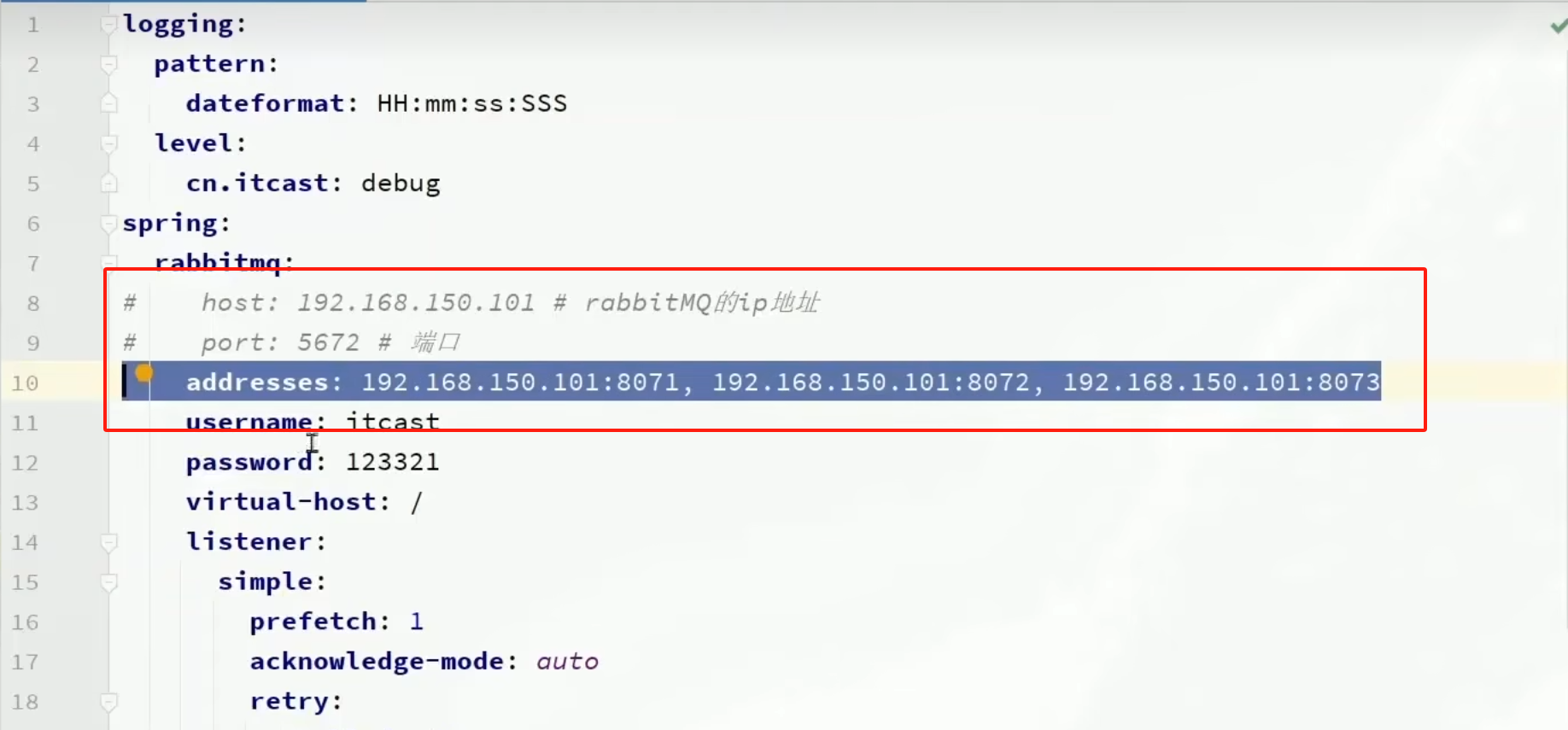
這個時候啟動項目(記得把之前聲明的一些配置類給注釋掉),前端控制臺就能看到我們在代碼里聲明的仲裁隊列了。
)

全面解析)






關鍵點檢測)





![[C++] 大數減/除法](http://pic.xiahunao.cn/[C++] 大數減/除法)


![洛谷P7528 [USACO21OPEN] Portals G](http://pic.xiahunao.cn/洛谷P7528 [USACO21OPEN] Portals G)
