- 🍨 本文為🔗365天深度學習訓練營 中的學習記錄博客
- 🍖 原作者:K同學啊
目標
具體實現
(一)環境
語言環境:Python 3.10
編 譯 器: PyCharm
框 架: Tensorflow
(二)具體步驟
1. 代碼
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model
from tensorflow.keras.layers import ( Input, Conv2D, BatchNormalization, ReLU, Add, MaxPooling2D, GlobalAveragePooling2D, Dense, Concatenate, Lambda
)
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping, TensorBoard
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
from datetime import datetime
import time # 設置GPU內存增長
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus: try: for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) print(f"找到 {len(gpus)} 個GPU,已設置內存增長") except RuntimeError as e: print(f"設置GPU內存增長時出錯: {e}") # 設置中文字體支持
def set_chinese_font(): """配置Matplotlib中文字體支持""" import platform if platform.system() == 'Windows': plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'SimSun'] else: # Linux/Mac plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei', 'Arial Unicode MS', 'Heiti TC'] plt.rcParams['axes.unicode_minus'] = False # 分組卷積塊實現
def grouped_convolution_block(inputs, filters, strides, groups, prefix=None): """ 實現分組卷積 參數: - inputs: 輸入張量 - filters: 過濾器數量 - strides: 步長 - groups: 分組數量 - prefix: 層名稱前綴,用于避免命名沖突 返回: - 輸出張量 """ # 確保過濾器數量可以被分組數整除 assert filters % groups == 0, "過濾器數量必須能被分組數整除" # 計算每組的過濾器數量 group_filters = filters // groups # 初始化保存分組卷積結果的列表 group_convs = [] # 對每個組執行卷積 for group_idx in range(groups): name = f'{prefix}_group_conv_{group_idx}' if prefix else None group_conv = Conv2D( group_filters, kernel_size=(3, 3), strides=strides, padding='same', use_bias=False, name=name )(inputs) group_convs.append(group_conv) # 合并所有組的卷積結果 if len(group_convs) > 1: name = f'{prefix}_concat' if prefix else None output = Concatenate(name=name)(group_convs) else: output = group_convs[0] return output # ResNeXt殘差塊
def block(x, filters, strides=1, groups=32, conv_shortcut=True, block_id=None): """ ResNeXt殘差單元 參數: - x: 輸入張量 - filters: 過濾器數量(最終輸出將是filters*2) - strides: 步長 - groups: 分組數量 - conv_shortcut: 是否使用卷積快捷連接 - block_id: 塊ID,用于唯一命名 返回: - 輸出張量 """ prefix = f'block{block_id}' if block_id is not None else None # 快捷連接 if conv_shortcut: shortcut_name = f'{prefix}_shortcut_conv' if prefix else None shortcut = Conv2D(filters * 2, kernel_size=(1, 1), strides=strides, padding='same', use_bias=False, name=shortcut_name)(x) shortcut_bn_name = f'{prefix}_shortcut_bn' if prefix else None shortcut = BatchNormalization(epsilon=1.001e-5, name=shortcut_bn_name)(shortcut) else: shortcut = x # 三層卷積 # 第一層: 1x1卷積降維 conv1_name = f'{prefix}_conv1' if prefix else None x = Conv2D(filters=filters, kernel_size=(1, 1), strides=1, padding='same', use_bias=False, name=conv1_name)(x) bn1_name = f'{prefix}_bn1' if prefix else None x = BatchNormalization(epsilon=1.001e-5, name=bn1_name)(x) relu1_name = f'{prefix}_relu1' if prefix else None x = ReLU(name=relu1_name)(x) # 第二層: 分組3x3卷積 x = grouped_convolution_block(x, filters, strides, groups, prefix=prefix) bn2_name = f'{prefix}_bn2' if prefix else None x = BatchNormalization(epsilon=1.001e-5, name=bn2_name)(x) relu2_name = f'{prefix}_relu2' if prefix else None x = ReLU(name=relu2_name)(x) # 第三層: 1x1卷積升維 conv3_name = f'{prefix}_conv3' if prefix else None x = Conv2D(filters=filters * 2, kernel_size=(1, 1), strides=1, padding='same', use_bias=False, name=conv3_name)(x) bn3_name = f'{prefix}_bn3' if prefix else None x = BatchNormalization(epsilon=1.001e-5, name=bn3_name)(x) # 添加殘差連接 add_name = f'{prefix}_add' if prefix else None x = Add(name=add_name)([x, shortcut]) relu3_name = f'{prefix}_relu3' if prefix else None x = ReLU(name=relu3_name)(x) return x # 堆疊殘差塊
def stack(x, filters, blocks, strides=1, groups=32, stack_id=None): """ 堆疊多個殘差單元 參數: - x: 輸入張量 - filters: 過濾器數量 - blocks: 殘差單元數量 - strides: 第一個殘差單元的步長 - groups: 分組數量 - stack_id: 堆棧ID,用于唯一命名 返回: - 輸出張量 """ # 第一個殘差單元可能會改變通道數和特征圖大小 block_prefix = f'{stack_id}_0' if stack_id is not None else None x = block(x, filters, strides=strides, groups=groups, block_id=block_prefix) # 堆疊剩余的殘差單元 for i in range(1, blocks): block_prefix = f'{stack_id}_{i}' if stack_id is not None else None x = block(x, filters, groups=groups, conv_shortcut=False, block_id=block_prefix) return x # 構建ResNeXt50模型
def ResNeXt50(input_shape=(224, 224, 3), num_classes=1000, groups=32): """ 構建ResNeXt-50模型 參數: - input_shape: 輸入圖像形狀 - num_classes: 分類數量 - groups: 基數(分組數量) 返回: - Keras模型 """ # 定義輸入 input_tensor = Input(shape=input_shape) # 初始卷積層 x = Conv2D(64, kernel_size=(7, 7), strides=2, padding='same', use_bias=False, name='conv1')(input_tensor) x = BatchNormalization(epsilon=1.001e-5, name='bn1')(x) x = ReLU(name='relu1')(x) # 最大池化 x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same', name='max_pool')(x) # 四個階段的殘差塊堆疊 # Stage 1 x = stack(x, 128, 3, strides=1, groups=groups, stack_id='stage1') # Stage 2 x = stack(x, 256, 4, strides=2, groups=groups, stack_id='stage2') # Stage 3 x = stack(x, 512, 6, strides=2, groups=groups, stack_id='stage3') # Stage 4 x = stack(x, 1024, 3, strides=2, groups=groups, stack_id='stage4') # 全局平均池化 x = GlobalAveragePooling2D(name='avg_pool')(x) # 全連接分類層 x = Dense(num_classes, activation='softmax', name='fc')(x) # 創建模型 model = Model(inputs=input_tensor, outputs=x, name='resnext50') return model # 創建數據生成器
def create_data_generators(data_dir, img_size=(224, 224), batch_size=32): """ 創建訓練、驗證和測試數據生成器 參數: - data_dir: 數據集根目錄 - img_size: 圖像大小 - batch_size: 批次大小 返回: - train_generator: 訓練數據生成器 - validation_generator: 驗證數據生成器 - test_generator: 測試數據生成器 - num_classes: 類別數量 """ # 數據增強設置 - 訓練集 train_datagen = ImageDataGenerator( rescale=1. / 255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) # 僅進行縮放 - 驗證集和測試集 valid_datagen = ImageDataGenerator( rescale=1. / 255 ) # 路徑設置 train_dir = os.path.join(data_dir, 'train') valid_dir = os.path.join(data_dir, 'val') test_dir = os.path.join(data_dir, 'test') # 檢查目錄是否存在 if not os.path.exists(train_dir): raise FileNotFoundError(f"訓練集目錄不存在: {train_dir}") if not os.path.exists(valid_dir): raise FileNotFoundError(f"驗證集目錄不存在: {valid_dir}") # 創建生成器 train_generator = train_datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=batch_size, class_mode='categorical', shuffle=True ) validation_generator = valid_datagen.flow_from_directory( valid_dir, target_size=img_size, batch_size=batch_size, class_mode='categorical', shuffle=False ) # 檢查測試集 test_generator = None if os.path.exists(test_dir): test_generator = valid_datagen.flow_from_directory( test_dir, target_size=img_size, batch_size=batch_size, class_mode='categorical', shuffle=False ) print(f"測試集已加載: {test_generator.samples} 張圖像") num_classes = len(train_generator.class_indices) print(f"類別數量: {num_classes}") print(f"類別映射: {train_generator.class_indices}") return train_generator, validation_generator, test_generator, num_classes # 訓練模型
def train_model(model, train_generator, validation_generator, epochs=20, initial_epoch=0): """ 訓練模型 參數: - model: Keras模型 - train_generator: 訓練數據生成器 - validation_generator: 驗證數據生成器 - epochs: 總訓練輪數 - initial_epoch: 初始輪數(用于斷點續訓) 返回: - history: 訓練歷史 """ # 創建保存目錄 os.makedirs('models', exist_ok=True) os.makedirs('logs', exist_ok=True) # 設置回調函數 callbacks = [ # 保存最佳模型 ModelCheckpoint( filepath='models/resnext50_best.h5', monitor='val_accuracy', save_best_only=True, verbose=1 ), # 學習率調度器 ReduceLROnPlateau( monitor='val_loss', factor=0.5, patience=3, verbose=1, min_delta=0.0001, min_lr=1e-6 ), # 早停 EarlyStopping( monitor='val_loss', patience=8, verbose=1, restore_best_weights=True ), # TensorBoard日志 TensorBoard( log_dir=f'logs/resnext50_{datetime.now().strftime("%Y%m%d-%H%M%S")}', histogram_freq=1 ) ] # 編譯模型 model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'] ) # 設置訓練步數 steps_per_epoch = train_generator.samples // train_generator.batch_size validation_steps = validation_generator.samples // validation_generator.batch_size # 確保至少有一個步驟 steps_per_epoch = max(1, steps_per_epoch) validation_steps = max(1, validation_steps) print(f"開始訓練模型,共 {epochs} 輪...") print(f"訓練步數: {steps_per_epoch}, 驗證步數: {validation_steps}") # 訓練模型 history = model.fit( train_generator, steps_per_epoch=steps_per_epoch, epochs=epochs, initial_epoch=initial_epoch, validation_data=validation_generator, validation_steps=validation_steps, callbacks=callbacks, verbose=1 ) # 保存最終模型 model.save('models/resnext50_final.h5') print("訓練完成,模型已保存為 'models/resnext50_final.h5'") return history # 評估模型
def evaluate_model(model, generator, set_name="測試集"): """ 評估模型 參數: - model: Keras模型 - generator: 數據生成器 - set_name: 數據集名稱(用于打印) 返回: - results: 評估結果 """ if generator is None: print(f"{set_name}不存在,跳過評估") return None print(f"評估模型在{set_name}上的性能...") steps = generator.samples // generator.batch_size steps = max(1, steps) # 確保至少有一個步驟 results = model.evaluate(generator, steps=steps, verbose=1) print(f"{set_name}損失: {results[0]:.4f}") print(f"{set_name}準確率: {results[1]:.4f}") return results # 繪制訓練歷史
def plot_training_history(history): """ 繪制訓練歷史曲線 參數: - history: 訓練歷史 """ set_chinese_font() # 創建圖表 fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5)) # 繪制準確率曲線 ax1.plot(history.history['accuracy'], label='訓練準確率', linewidth=2) ax1.plot(history.history['val_accuracy'], label='驗證準確率', linewidth=2) ax1.set_title('模型準確率', fontsize=14) ax1.set_ylabel('準確率', fontsize=12) ax1.set_xlabel('輪次', fontsize=12) ax1.grid(True, linestyle='--', alpha=0.7) ax1.legend(loc='lower right', fontsize=10) # 繪制損失曲線 ax2.plot(history.history['loss'], label='訓練損失', linewidth=2) ax2.plot(history.history['val_loss'], label='驗證損失', linewidth=2) ax2.set_title('模型損失', fontsize=14) ax2.set_ylabel('損失', fontsize=12) ax2.set_xlabel('輪次', fontsize=12) ax2.grid(True, linestyle='--', alpha=0.7) ax2.legend(loc='upper right', fontsize=10) plt.tight_layout() plt.savefig('training_history.png', dpi=120) plt.show() # 可視化預測結果
def visualize_predictions(model, generator, num_images=5): """ 可視化模型預測結果 參數: - model: Keras模型 - generator: 數據生成器 - num_images: 要顯示的圖像數量 """ set_chinese_font() # 獲取類別標簽 class_indices = generator.class_indices class_names = {v: k for k, v in class_indices.items()} # 獲取一批圖像 x, y_true = next(generator) # 僅使用前num_images張圖像 x = x[:num_images] y_true = y_true[:num_images] # 預測 y_pred = model.predict(x) # 創建圖表 fig = plt.figure(figsize=(15, 10)) for i in range(num_images): # 獲取圖像 img = x[i] # 獲取真實標簽和預測標簽 true_label = np.argmax(y_true[i]) pred_label = np.argmax(y_pred[i]) pred_prob = y_pred[i][pred_label] # 獲取類別名稱 true_class_name = class_names[true_label] pred_class_name = class_names[pred_label] # 創建子圖 plt.subplot(1, num_images, i + 1) # 顯示圖像 plt.imshow(img) # 設置標題 title_color = 'green' if true_label == pred_label else 'red' plt.title(f"真實: {true_class_name}\n預測: {pred_class_name}\n概率: {pred_prob:.2f}", color=title_color, fontsize=10) plt.axis('off') plt.tight_layout() plt.savefig('prediction_results.png', dpi=120) plt.show() # 測試單張圖像
def predict_image(model, image_path, class_names, img_size=(224, 224)): """ 預測單張圖像 參數: - model: Keras模型 - image_path: 圖像路徑 - class_names: 類別名稱字典 - img_size: 圖像大小 返回: - pred_class: 預測的類別 - confidence: 置信度 """ from tensorflow.keras.preprocessing import image # 加載圖像 img = image.load_img(image_path, target_size=img_size) # 轉換為數組 x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = x / 255.0 # 歸一化 # 預測 preds = model.predict(x) # 獲取最高置信度的類別 pred_class_idx = np.argmax(preds[0]) confidence = preds[0][pred_class_idx] # 獲取類別名稱 pred_class = class_names[pred_class_idx] return pred_class, confidence # 打印模型架構并顯示中間特征圖尺寸
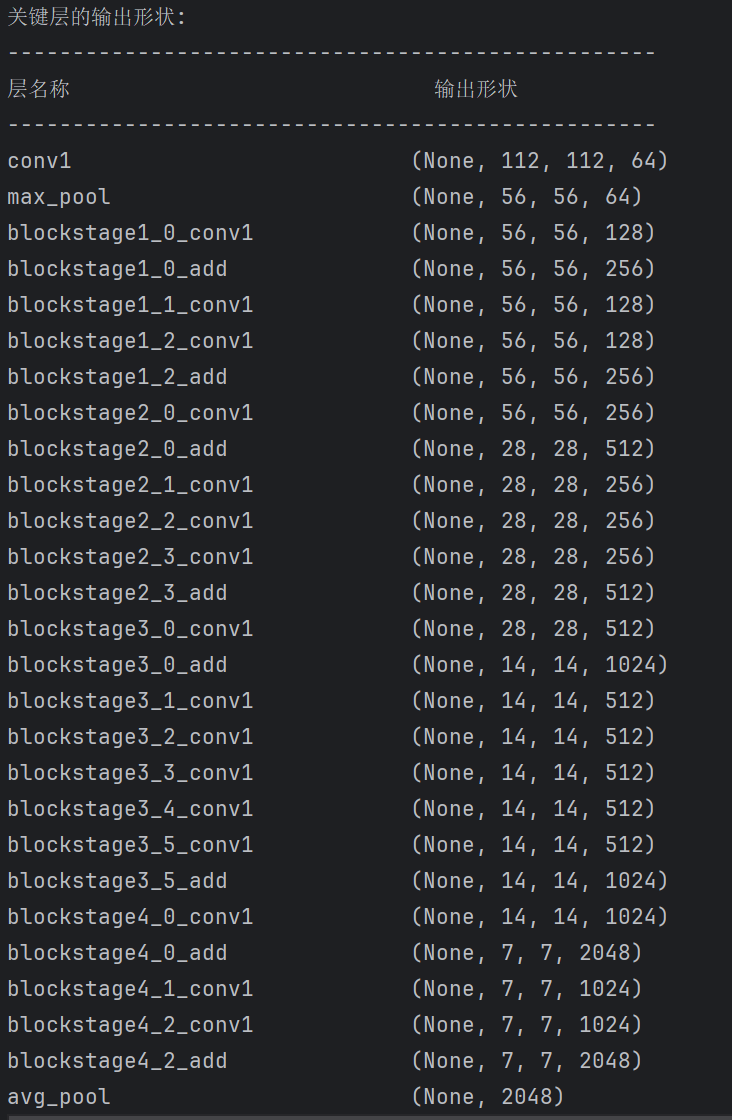
def print_model_architecture(model): """ 打印模型架構信息,包括每層輸出形狀 參數: - model: Keras模型 """ # 打印模型摘要 model.summary() # 顯示每個塊的輸出形狀 layer_outputs = [] layer_names = [] # 選擇要顯示的關鍵層 target_layers = [ 'conv1', 'max_pool', 'stage1_0_add', 'stage1_2_add', 'stage2_0_add', 'stage2_3_add', 'stage3_0_add', 'stage3_5_add', 'stage4_0_add', 'stage4_2_add', 'avg_pool' ] print("\n關鍵層的輸出形狀:") print("-" * 50) print(f"{'層名稱':<30} {'輸出形狀':<20}") print("-" * 50) for layer in model.layers: if any(target_name in layer.name for target_name in target_layers): print(f"{layer.name:<30} {str(layer.output_shape):<20}") # 主函數
def main(): """主函數""" # 設置參數 DATA_DIR = './data' IMG_SIZE = (224, 224) BATCH_SIZE = 32 EPOCHS = 20 CARDINALITY = 32 # 獲取當前設備信息 print(f"TensorFlow版本: {tf.__version__}") print(f"使用設備: {'GPU' if tf.config.list_physical_devices('GPU') else 'CPU'}") try: # 創建數據生成器 print("加載數據集...") train_generator, validation_generator, test_generator, num_classes = create_data_generators( DATA_DIR, IMG_SIZE, BATCH_SIZE ) # 創建模型 print(f"創建ResNeXt-50模型 (基數={CARDINALITY})...") model = ResNeXt50( input_shape=(IMG_SIZE[0], IMG_SIZE[1], 3), num_classes=num_classes, groups=CARDINALITY ) # 顯示模型架構 print_model_architecture(model) # 計算模型參數量 trainable_params = np.sum([np.prod(v.get_shape()) for v in model.trainable_weights]) non_trainable_params = np.sum([np.prod(v.get_shape()) for v in model.non_trainable_weights]) total_params = trainable_params + non_trainable_params print(f"模型參數數量: {total_params:,}") print(f"可訓練參數: {trainable_params:,}") print(f"不可訓練參數: {non_trainable_params:,}") # 檢查是否有已保存的模型,實現斷點續訓 initial_epoch = 0 if os.path.exists('models/resnext50_final.h5'): print("找到已保存的模型,詢問是否繼續訓練...") choice = input("是否繼續訓練已保存的模型?(y/n): ") if choice.lower() == 'y': print("加載已保存的模型...") model = tf.keras.models.load_model('models/resnext50_final.h5') initial_epoch = int(input("請輸入起始輪數: ")) else: print("從頭開始訓練新模型...") # 訓練模型 print("開始訓練模型...") start_time = time.time() history = train_model(model, train_generator, validation_generator, EPOCHS, initial_epoch) training_time = time.time() - start_time print(f"訓練完成,耗時: {training_time:.2f} 秒") # 繪制訓練歷史 plot_training_history(history) # 評估驗證集 evaluate_model(model, validation_generator, "驗證集") # 評估測試集 evaluate_model(model, test_generator, "測試集") # 可視化預測結果 print("可視化預測結果...") visualize_predictions(model, validation_generator) # 找一張測試圖像進行單獨預測 if test_generator: print("查找測試圖像進行單獨預測...") # 獲取測試集中的一張圖像路徑 test_dir = os.path.join(DATA_DIR, 'test') class_dirs = [d for d in os.listdir(test_dir) if os.path.isdir(os.path.join(test_dir, d))] if class_dirs: # 選擇第一個類別目錄 class_dir = class_dirs[0] class_path = os.path.join(test_dir, class_dir) # 獲取目錄中的圖像 images = [f for f in os.listdir(class_path) if f.endswith(('.jpg', '.jpeg', '.png'))] if images: # 選擇第一張圖像 image_path = os.path.join(class_path, images[0]) # 獲取類別名稱 class_indices = test_generator.class_indices class_names = {v: k for k, v in class_indices.items()} # 預測圖像 pred_class, confidence = predict_image(model, image_path, class_names, IMG_SIZE) print(f"測試圖像路徑: {image_path}") print(f"真實類別: {class_dir}") print(f"預測類別: {pred_class}") print(f"預測置信度: {confidence:.4f}") print("所有操作完成!") except Exception as e: print(f"發生錯誤: {e}") import traceback traceback.print_exc() if __name__ == "__main__": main()
2. 關于快捷鏈接
殘差連接是ResNet和ResNeXt架構的核心創新之一,它允許信息直接從一層"跳過"到另一層,繞過中間的卷積操作。這解決了深層網絡中的梯度消失問題,使得非常深的網絡也能有效訓練。
# 快捷連接
if conv_shortcut: shortcut_name = f'{prefix}_shortcut_conv' if prefix else None shortcut = Conv2D(filters * 2, kernel_size=(1, 1), strides=strides, padding='same', use_bias=False, name=shortcut_name)(x) shortcut_bn_name = f'{prefix}_shortcut_bn' if prefix else None shortcut = BatchNormalization(epsilon=1.001e-5, name=shortcut_bn_name)(shortcut)
else: shortcut = x
當conv_shortcut=True:當輸入和輸出的尺寸或通道數不匹配時,需要使用卷積型快捷連接,使用kernel_size=(1, 1)的卷積進行通道轉換,將輸入通道數轉換為filters*2,然后使用批量歸一批標準化卷積輸出。
當conv_shortcut=False: 當輸入和輸出的尺寸和通道數完全匹配時,使用恒等型快捷連接,也就是不做任何的變換。確實這里可能會出現一個問題那就是通道數不匹配的問題,但是我們的代碼是可以正常執行的,為什么呢?按我的理解:通道數不一致肯定不行。看一下殘差堆疊的代碼:
# 堆疊殘差塊
def stack(x, filters, blocks, strides=1, groups=32, stack_id=None): """ 堆疊多個殘差單元 參數: - x: 輸入張量 - filters: 過濾器數量 - blocks: 殘差單元數量 - strides: 第一個殘差單元的步長 - groups: 分組數量 - stack_id: 堆棧ID,用于唯一命名 返回: - 輸出張量 """ # 第一個殘差單元可能會改變通道數和特征圖大小 block_prefix = f'{stack_id}_0' if stack_id is not None else None x = block(x, filters, strides=strides, groups=groups, block_id=block_prefix) # 堆疊剩余的殘差單元 for i in range(1, blocks): block_prefix = f'{stack_id}_{i}' if stack_id is not None else None x = block(x, filters, groups=groups, conv_shortcut=False, block_id=block_prefix) return x
在for之前,第一個殘差單元是確定的:x = block(x, filters, strides=strides, groups=groups, block_id=block_prefix) 這是通道數已經完成了轉換,而后續的殘差單元是通過for在生成的,它并沒有改變通道數,而是使用了第一個殘差單元的通道數。那么最后輸出肯定也是一致的通道數。
因此我們總結:
- 第一個殘差單元總是默認conv_shortcut=True,完成了通道數的轉換。
- 前一個block的返回值成為下一個block的輸入,這樣保證了通道數一致。



![[C++] 大數減/除法](http://pic.xiahunao.cn/[C++] 大數減/除法)


![洛谷P7528 [USACO21OPEN] Portals G](http://pic.xiahunao.cn/洛谷P7528 [USACO21OPEN] Portals G)












