目錄
前言
一、什么是自動化?
二、元素的定位
三、測試對象的操作
3.1輸入文本send_keys()? ? ? ??
3.2按鈕點擊click()
3.3清除文本clear()
3.4獲取文本信息text
3.5獲取頁面的title與URL
四、窗口
4.1窗口的切換switch_to.window()
4.2窗口大小設置
4.3屏幕截圖save_screenshot()
4.4 關閉窗口close()
五、彈窗
?六、等待
6.1強制等待
6.2隱式等待
6.3顯示等待
七、瀏覽器導航
八、文件上傳
九、瀏覽器參數設置
9.1無頭模式
9.2瀏覽器加載策略? ? ? ?
2.?eager?加載策略
3.?none?加載策略
前言
本文主要從元素的定位、測試對象操作、窗口、彈窗、等待、瀏覽器導航、文件上傳、瀏覽器參數設置這幾個方面介紹一下selenium自動化測試工具。
一、什么是自動化?
? ? ? ? 自動化簡單理解一下就是使用工具代替人力勞動,將人從勞動中解放出來。具體到我們的測試工作中就是:我們使用一些工具來代替我們完成一些重復的“點點點”的工作。Selenium就是一款自動化工具,我們可以使用它來解放我們的生產力!
二、元素的定位
? ? ? ? 假設我們想在相對一款瀏覽器的首頁進行測試,我們首先就必須要能夠“找到”對應的元素而后執行相應的操作。

? ? ? ? 比方說,我們現在想測試搜索功能是否正常,我們就需要將想要搜索的文本設置進搜索框中并且點擊搜索按鈕進行搜索,如果瀏覽器能夠返回和我們輸入文本相關性比較強的響應頁,那么我們就可以這次測試的結果是正常的。
? ? ? ? 那么問題來了,在上述的問題中我們如何定位“搜索框”和“按鈕”呢?
? ? ? ? 我們可以按下F12喚出開發者模式或者右鍵瀏覽器頁面按下鼠標右鍵然后選擇“檢查”都可以進入到開發者模式,而后根據圖2所示獲取元素的位置信息即可。
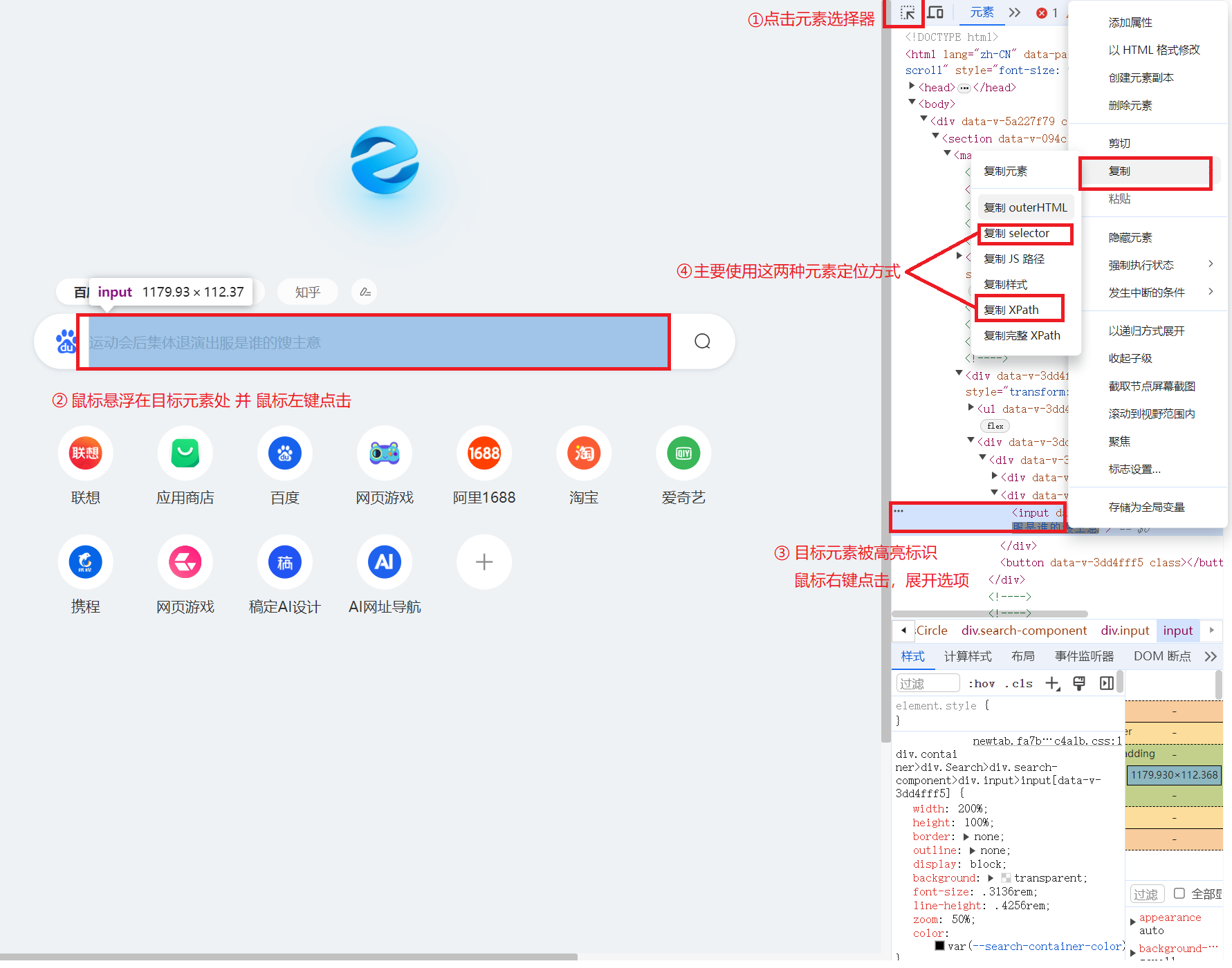
三、測試對象的操作
3.1輸入文本send_keys()? ? ? ??
????????在元素定位的例子中,我們提到了向輸入框中輸入文本并且點擊搜索按鈕。這里的文本輸入和按鈕的點擊操作就是我們對象操作的一部分,我們使用selenium工具來實現一下這兩個動作。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務driver.get("https://www.baidu.com/") #需要測試的網頁
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到輸入框并輸入文本time.sleep(2) #休眠兩秒觀察現象
driver.quit() #關閉瀏覽器? ? ? ?這里簡單解釋一下上面給出的代碼。因為我們的selenium工具主要面向的是Web頁面的自動化測試工具,所以你需要先指定使用你電腦上的哪個瀏覽器來執行測試任務,而后你需要確定你要執行測試的網頁,這兩部都確定好了之后我們就可以先定位元素,然后執行對象操作即可。
???????由于運行過程是一個動態的過程,這里使用圖片貼出來則比較麻煩,所以這里希望讀者自己嘗試一下。
? ? ? ? 這段代碼運行起來整體的效果就是:打開谷歌瀏覽器-》向搜索框中輸入“python”。等待兩秒后瀏覽器退出。
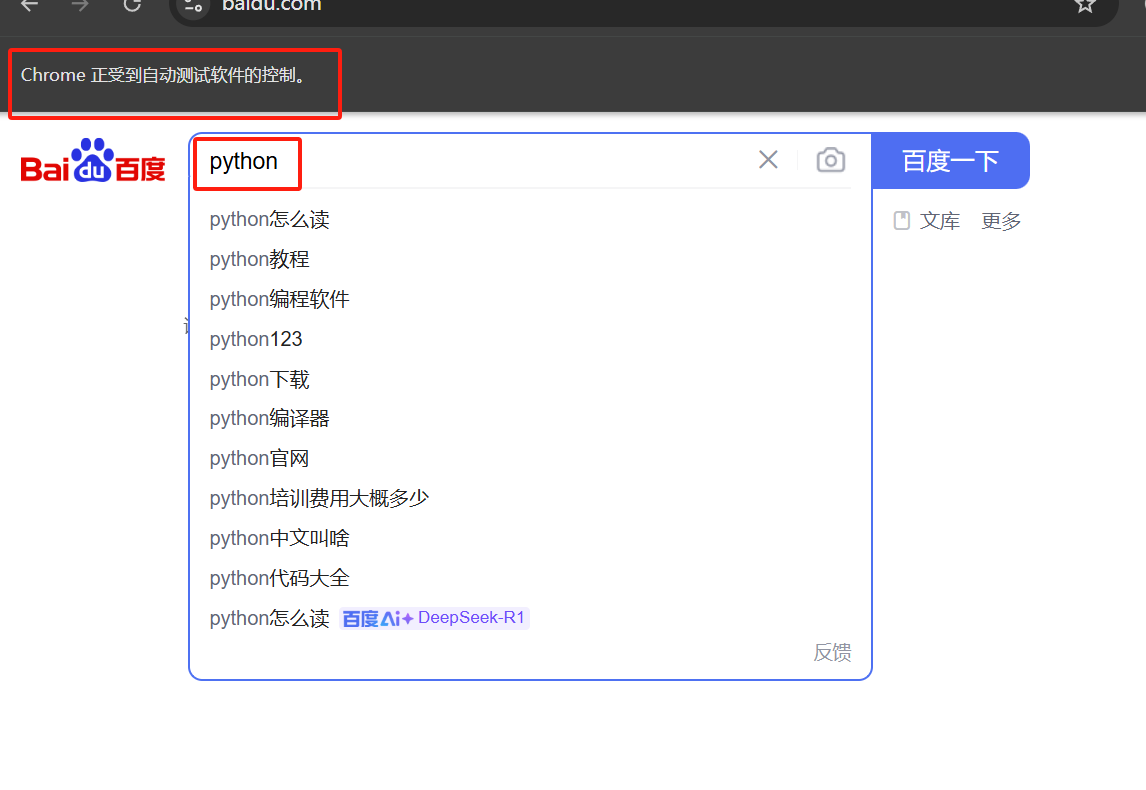
3.2按鈕點擊click()
? ? ? ? 當我們向搜索框中輸入文本后我們需要點擊“百度一下”按鈕來進行搜索操作,還是一樣想要執行點擊操作,就必須要找到指定的按鈕元素。找到按鈕元素之后觸發點擊操作即可。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務driver.get("https://www.baidu.com/") #需要測試的網頁
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按鈕元素并執行點擊操作
driver.maximize_window()
time.sleep(4) #休眠觀察現象
driver.quit() #關閉瀏覽器
3.3清除文本clear()
? ? ? ? 上面的例子中,我們只執行一次搜索測試時,似乎并沒有什么問題,但是如果我們需要進行多次關鍵詞搜索的時候應該如何編寫代碼呢?是下面這種方式嗎?
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁#第一次搜索測試
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按鈕元素并執行點擊操作
time.sleep(2)
#第二次搜索測試
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("C++好學嗎?") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按鈕元素并執行點擊操作
time.sleep(2)driver.maximize_window()
time.sleep(4) #休眠觀察現象
driver.quit() #關閉瀏覽器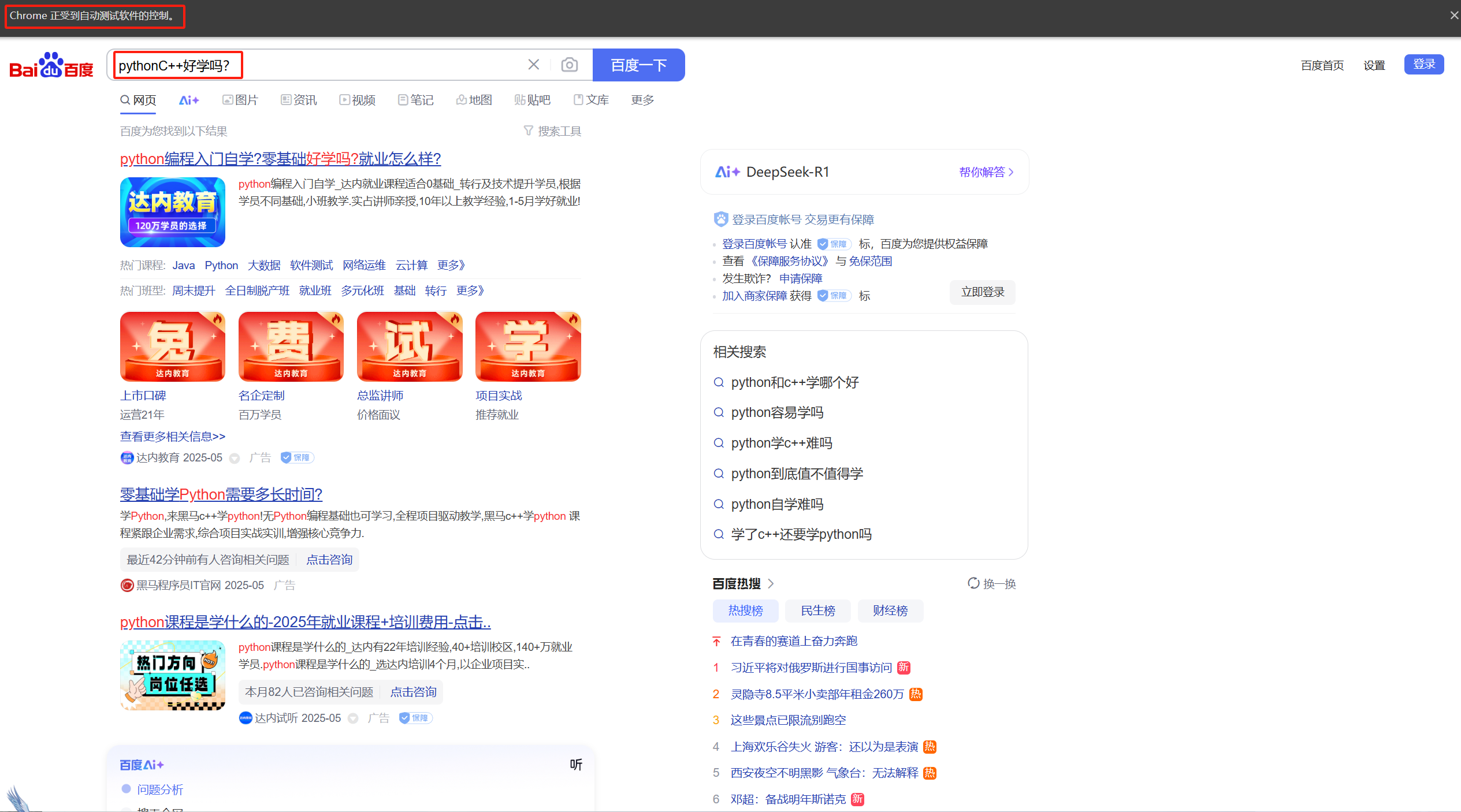
? ? ? ? 我們可以發現上面代碼的寫法,會導致我們的搜索文本發生混疊進而導致搜索不準確的問題,為了解決這種問題,我們應該在每一次搜索文本之后將搜索框中的文本進行清空而后在輸入新的文本,就像這樣。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁#第一次搜索測試
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按鈕元素并執行點擊操作
time.sleep(2)
#第二次搜索測試
driver.find_element(By.CSS_SELECTOR,"#kw").clear() #輸入新的文本前,先對文本進行清空
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("C++好學嗎?") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按鈕元素并執行點擊操作
time.sleep(2)driver.maximize_window()
time.sleep(4) #休眠觀察現象
driver.quit() #關閉瀏覽器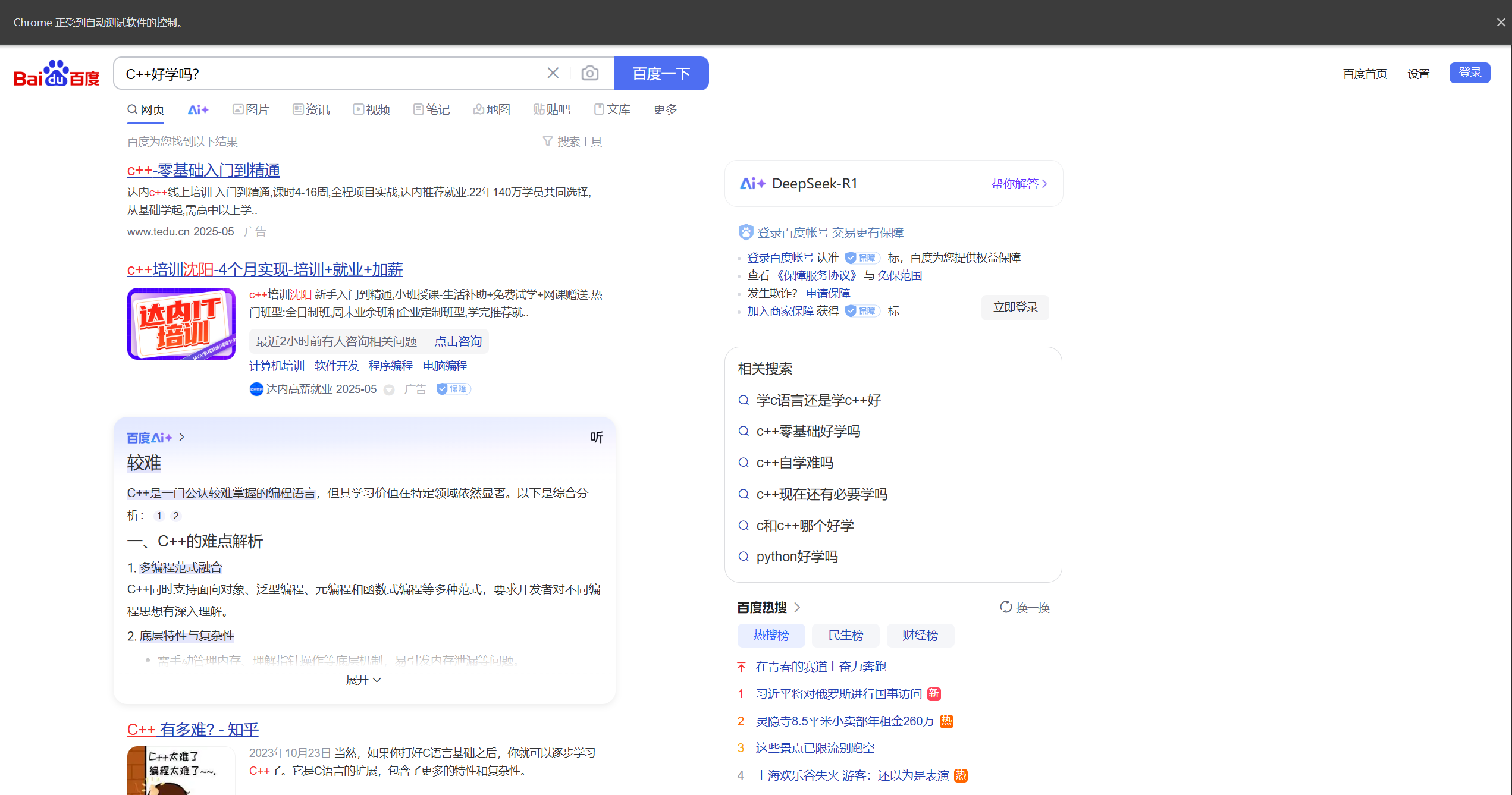
3.4獲取文本信息text
? ? ? ? 如果你在測試工作過程中需要獲取元素所包含的文本可以按照如下的方式來獲取元素的文本信息。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁text=driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(2) > a > span.title-content-title").text
print(text)driver.quit()
? ? ? ? ?如果我們現在想獲取“百度一下”按鈕的文本呢信息,我們應該怎么獲取呢?是下面這種寫法嗎?
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁text=driver.find_element(By.CSS_SELECTOR,"#su").text
print(text)driver.quit()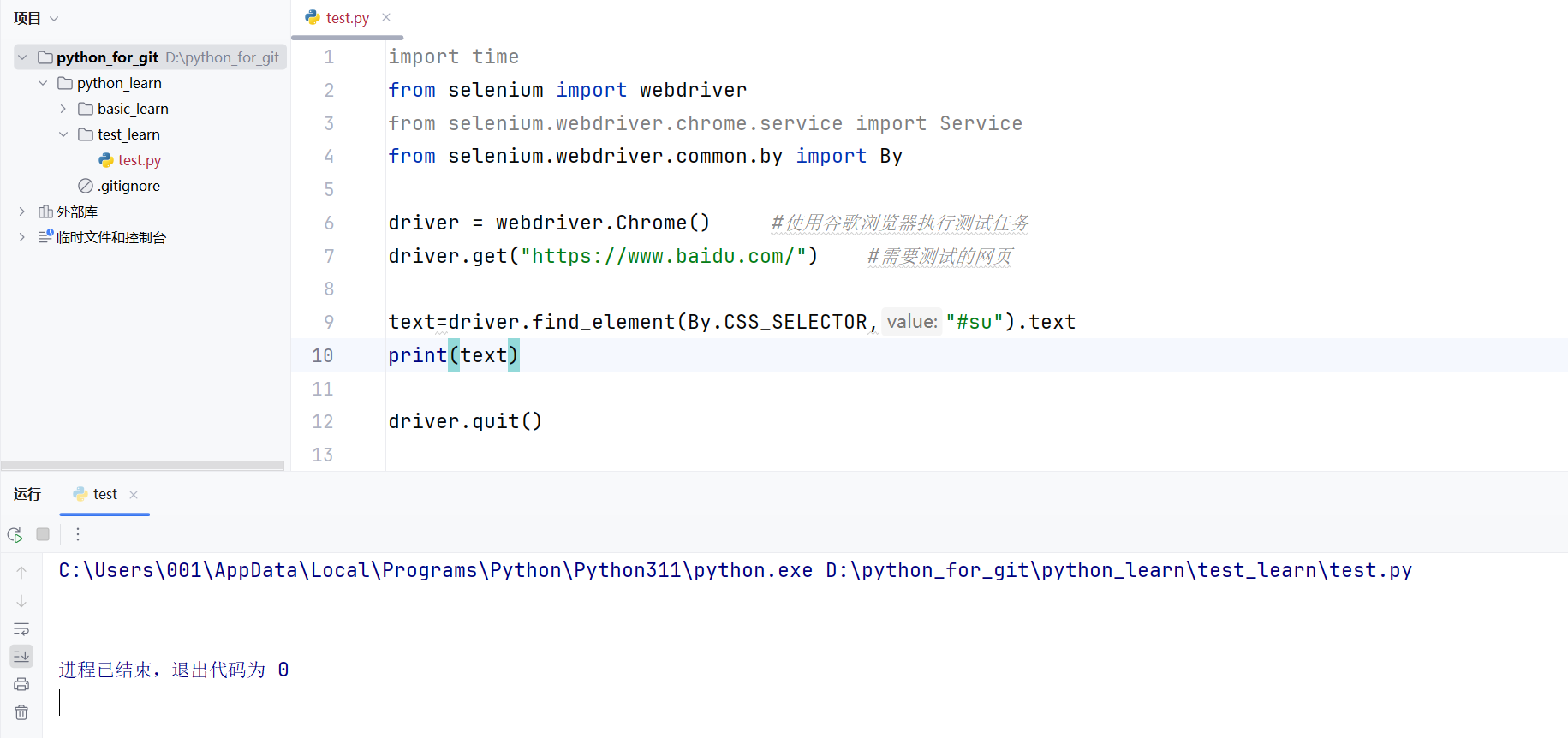
? ? ? ? 從圖8的結果中我們不難看出,最后程序的輸出中并沒有對應的文本信息,這是因為“百度一下”按鈕的文本信息存儲在屬性值value中,我們也可以html標簽初見端倪。
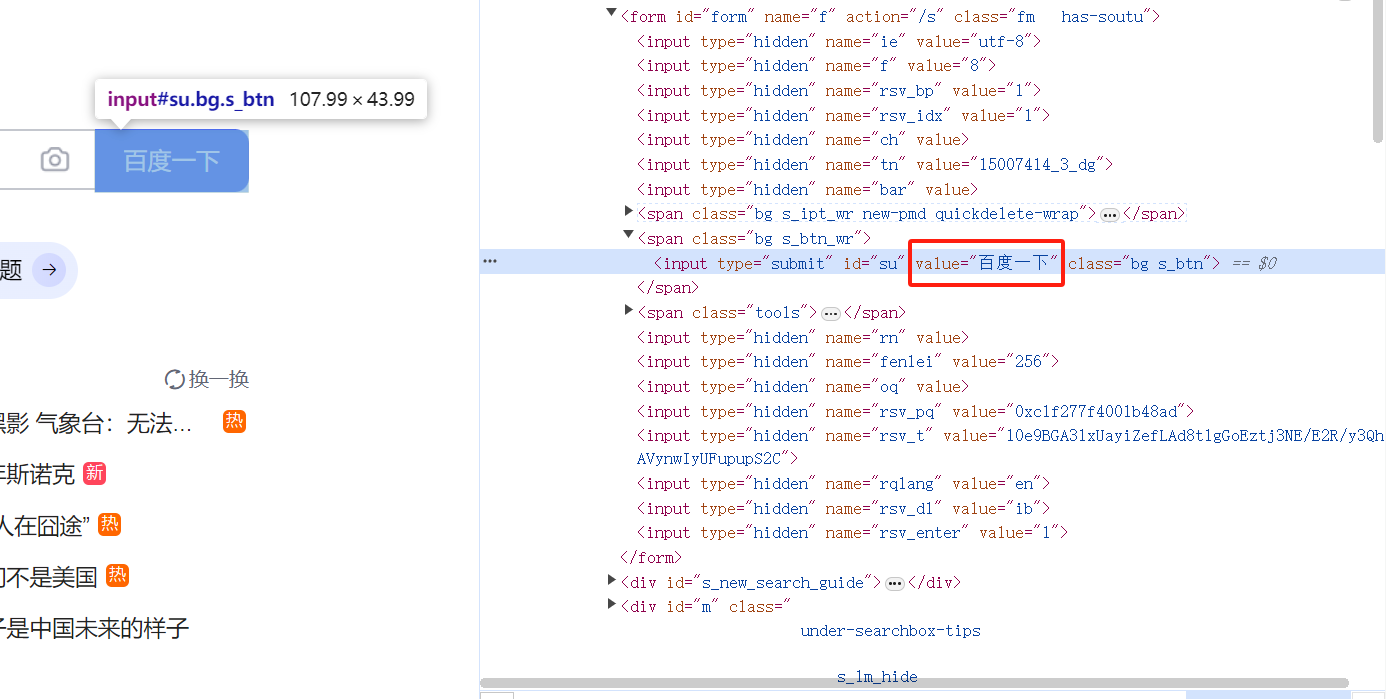
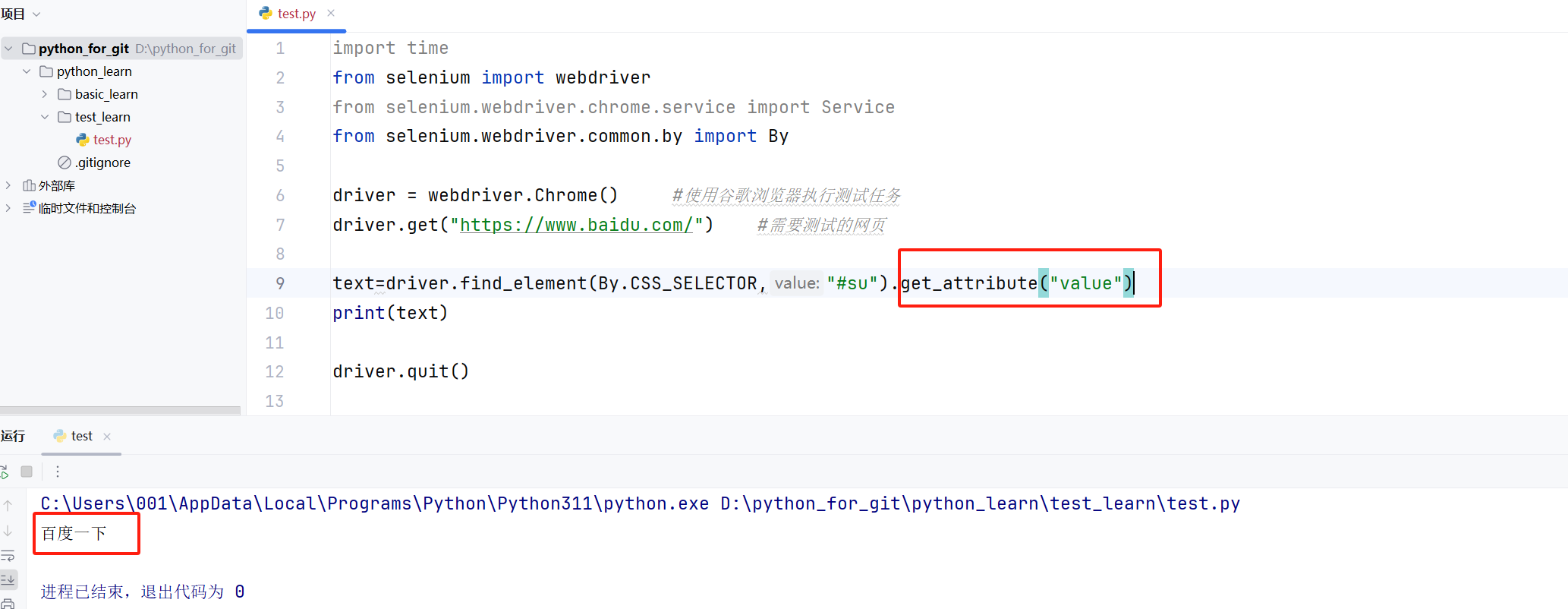
? ? ? ? 所以要獲取這類元素的“文本”,我們就需要使用get_attribute()方法來進行獲取。
3.5獲取頁面的title與URL
? ? ? ? 頁面的title信息和URL信息更多的時候是幫助我們判斷頁面的跳轉是否正確,比如我在搜索頁面點擊了一個今天的熱搜,這個熱搜的地址與我們設置好的地址是不是相對應的,這個時候就可以通過這兩個接口加斷言就可以實現。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁#先獲取一下按鈕點擊之前的URL和title信息
title = driver.title
url = driver.current_url
print("切換前:")
print("title: "+title+' ')
print("URL: "+url+'\n')
#查找對應的熱搜并點擊
driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(2) > a > span.title-content-title").click()
#因為我們的driver定位的是一個頁面,頁面切換了,driver也得切換
cur_page = driver.current_window_handle #獲取當前頁
all_pages = driver.window_handles #獲取所有頁
for handle in all_pages:if(handle != cur_page): #因為一共兩個頁面,不是當前頁就是新開頁driver.switch_to.window(handle)title = driver.title #獲取一下切換后的title
url = driver.current_url #獲取一下切換后的URL
print("切換后:")
print("title: "+title+' ')
print("URL: "+url+'\n')
driver.quit()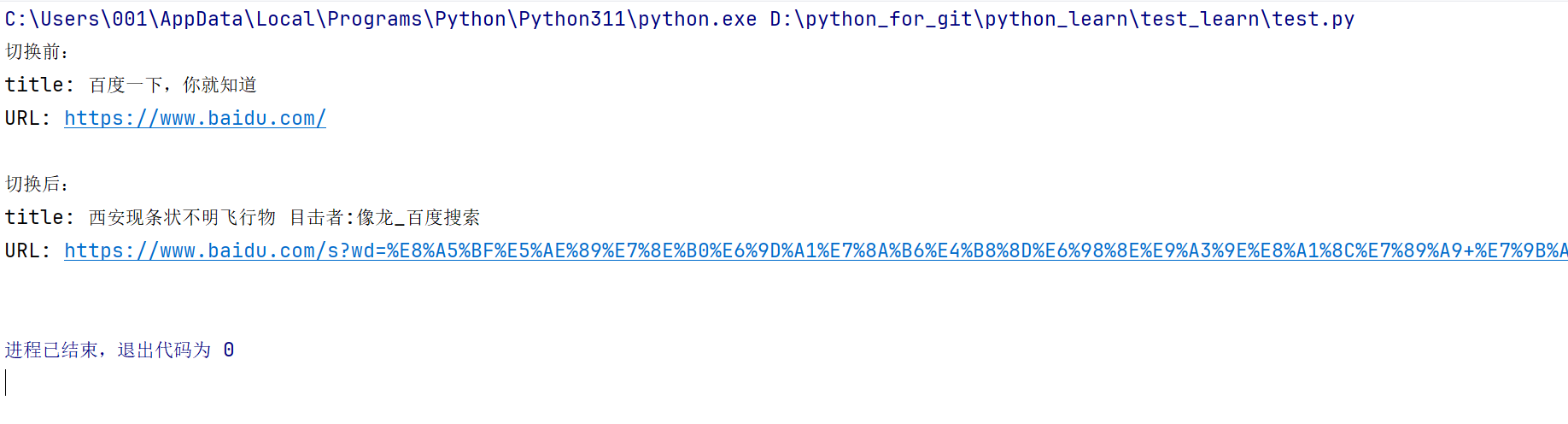
? ? ? ? 至于當有多個窗口的時候,怎么才能確定我要切換到哪個窗口的問題,我想大家暫時不用擔心,一來在實際測試工作中很少會出現多個頁面同時存在的情況,二來,即使真出現了這種情況我們只需要在新開頁之前,就獲取一下現有的頁面記存儲頁面的數組為A,在新開頁之后獲取一下現有的頁面記存儲頁面的數組為B,對比A、B兩個數組的差異不就可以確定新開頁是哪個頁了嗎?
? ? ? ? 甚至,如果你愿意,你也可以將這些頁與特定的標識相綁定,然后在你想操作特定頁的時候遍歷你的映射表去除你想操作的頁后直接切換即可。當然還是那句話,這樣的場景很少見,這里只是提出一些解決問題的方案。?
四、窗口
? ? ? ? 其實有關窗口的知識,我們已經在前面有所鋪墊:比如我們之前所說的頁面切換,實際上就是窗口的切換,頁面是一個窗口,也是一個可以切換的對象。這里我們在說一下有關窗口的知識與操作。
4.1窗口的切換switch_to.window()
? ? ? ? 如3.5所講解的例子,在進行窗口的切換時,需要使用switch類,如果你想要切換到窗口就需要使用switch下的window方法。需要注意的是傳遞給該方法的參數必須是一個handle句柄對象就類似于我們的窗口對象。
driver.switch_to.window(handle)? ? ? ? 我們也可以通過一些方法獲取當前瀏覽器下已經存在的窗口和當前處于哪個窗口下。
cur_page = driver.current_window_handle #獲取當前窗口
all_pages = driver.window_handles #獲取所有窗口? ? ? ? 另外,建議當存在多個頁面的時候,如果你不使用當前頁,在關閉這個頁之后,你最好切換到一個不會被關閉的頁保證操作頁的可預見性。即便是只有兩個頁面,如果你想操控那個未被關閉的頁面也需要進行窗口的切換。
4.2窗口大小設置
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁driver.minimize_window() #將窗口最小化
time.sleep(2)
driver.maximize_window() #將窗口最大化
time.sleep(2)
driver.fullscreen_window() #將窗口全屏
time.sleep(2)
driver.set_window_size(1024, 768) #手動設置窗口大小
time.sleep(2)
driver.close()? ? ? ? 有關窗口的大小變換這里就不過多介紹了,讀者可以將這段運行這段代碼,看看實際的演示效果。
4.3屏幕截圖save_screenshot()
? ? ? ? 這個功能主要是給我測試的人來看的,一種使用場景是在容易出錯的或已經出錯的地方加上這樣的屏幕截圖供測試人員介入后快速的定位問題,有點像調試功能或者說是測試工作中的“紅黑表筆”。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁driver.save_screenshot("./screenshots/baidu.png")
time.sleep(2)
driver.close()? ? ? ? ?屏幕截圖的方式還是比較簡單的,只需要指定保存截圖文件的路徑即可。但是實際測試工作中必然有大量的截圖到來,這個時候我們就不能將圖片的名字設置為一個固定值,所以我們可以在這個圖片名字的前面或后面加上一個唯一的前綴或后綴,這里我就演示一下增加一個前綴。
import time
import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() #使用谷歌瀏覽器執行測試任務
driver.get("https://www.baidu.com/") #需要測試的網頁dirctory = "./screenshots/"
filename = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S_")
picture_name = "baidu"
farmat = ".png"driver.save_screenshot(dirctory+filename+picture_name+farmat)
time.sleep(2)
driver.close()? ? ? ? 當然,這不是嚴格意義上的唯一,因為在同一秒中截圖就會出現覆蓋的情況導致先生成的圖片被覆蓋,所以你也可以使用uuid生成器生成一個uuid,uuid在正常情況下可以說是一個絕對唯一的值了,你當然也可以使用uuid。
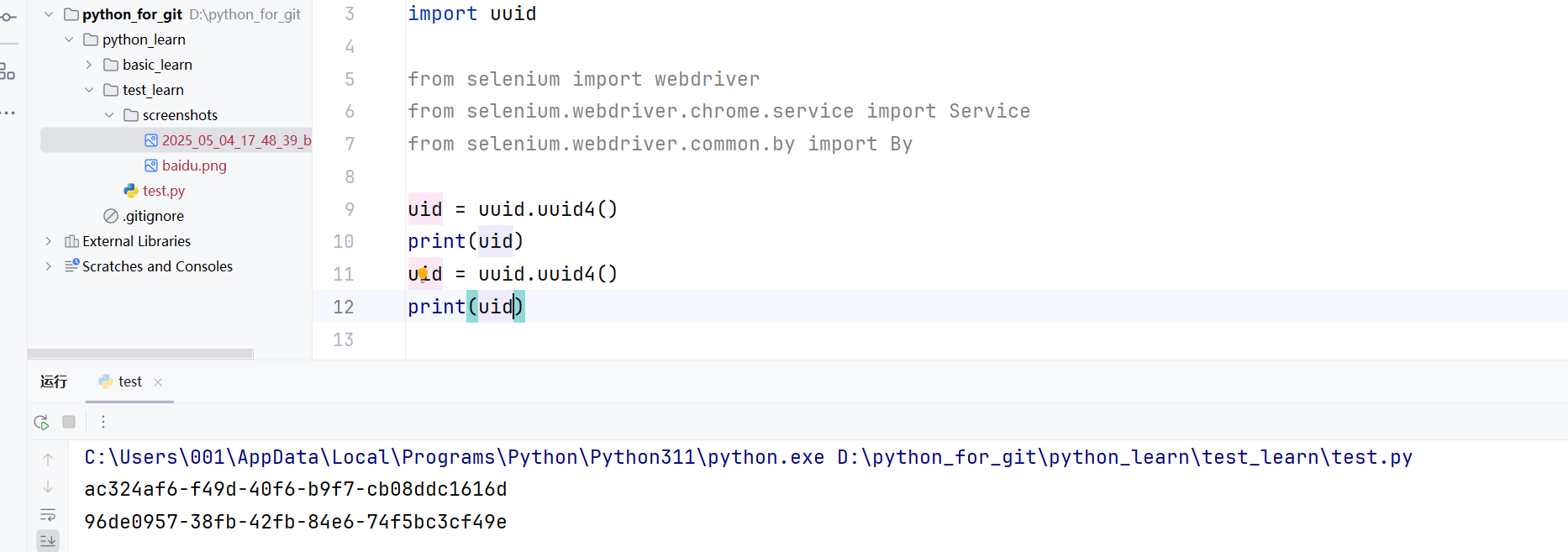
? ? ? ? 當然,這種方式有點殺雞用牛刀的感覺~?
4.4 關閉窗口close()
? ? ? ? 當你使用完窗口之后應該將其關閉,就像你在C語言中malloc空間后需要將其free掉是一個道理。這里就不進行代碼演示了,因為在本文的例子中或多或少都有所體現,但是這里要說明一下close()與quit()的區別
driver.close()
driver.quit()? ? ? ? close是關閉窗口,當存在多個頁面的時候,其只會關閉一個頁面,如果還有其它頁面瀏覽器不會退出,但是quit是指關閉瀏覽器,也就是說無論有多少個頁面都會立即被關閉并且瀏覽器會直接退出。
五、彈窗
? ? ? ? 如圖13所示的就是一個彈窗,如果你不消除這個彈窗就無法進行下一步操作,所以我們如何定位這個彈窗,并且將其關閉呢?
? ? ? ? 需要說明的是,彈窗也是一個窗口,這就意味著我們需要先切換到該窗口上,才能夠對該窗口上的元素進行操作,此外,我們使用開發者模式是沒有辦法定位到這個彈窗的,這是因為彈窗和我們的頁面是兩個窗口,開發者模式只能定位到頁面這個窗口上的元素,彈窗不在頁面上,所以自然也就無法使用元素選擇器選中。
? ? ? ? 但是,無論你是什么窗口,總歸還是會被瀏覽器的驅動所管理的,所以我們使用驅動可以管理這個彈窗的。
import time
import datetime
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
#這是警告彈窗
driver.get("http://localhost:63342/python_for_git/test_learn/alert.html?_ijt=7392b4jk49m4e4vre8ngsni9rr")
driver.find_element(By.CSS_SELECTOR,"body > button").click()
time.sleep(2)
alert = driver.switch_to.alert
time.sleep(2)
alert.accept()
time.sleep(2)
driver.close()# #這是文本彈窗
# driver.get("http://localhost:63342/python_for_git/test_learn/text.html?_ijt=7392b4jk49m4e4vre8ngsni9rr")
# alert = driver.switch_to.alert
# alert.send_keys("你是一個文本彈窗")
# #確認/取消二選一
# alert.accept()
# alert.dismiss()
#
# #這是確認/取消選擇彈窗
# driver.get("http://localhost:63342/python_for_git/test_learn/query.html?_ijt=7392b4jk49m4e4vre8ngsni9rr")
# #確認/取消二選一
# alert.accept()
# alert.dismiss()? ? ? ?(這里由于彈窗并不是在每個頁面都會存在,所以這里作者讓AI生成了幾個生成彈窗的html網頁,如果感興趣,可以查看本文綁定的資源。在使用時先將html網頁運行在本地,然后將網址的地址拷貝到get()方法中,而后像獲取網頁元素一樣定位我給出的網頁中的按鈕,定位后點擊就會出現彈窗)
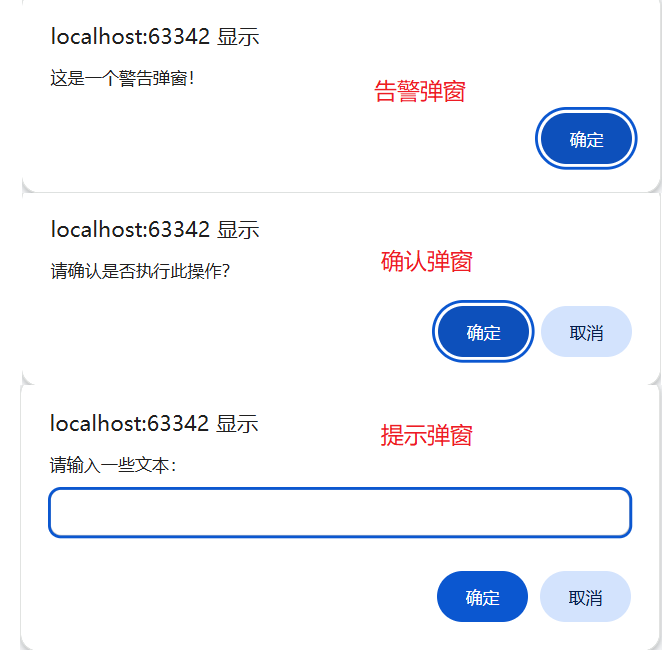
?六、等待
? ? ? ? 講解等待等待之前要清楚為什么要進行等待,關于這一點我相信你一定深有體會,當你在刷網站的時候,是不是有時會遇到一直卡在加載這一步,自己想要瀏覽的頁面遲遲刷新不出來的場景。對于瀏覽器selenium來說也是如此,當我們使用selenium進行網頁自動化測試的時候也是需要發送請求/接收響應的,這就意味著我們的網頁也是需要渲染時間的,如果網頁沒有渲染完成就進行元素的查找,很有可能就會導致本應該存在的元素卻沒有被找到的問題,進而導致自動化程池執行失敗的問題。而等待就是為了解決檢測先于渲染之前的問題。
6.1強制等待
? ? ? ? 強制等待就是我們一直在用的等待。
time.sleep(2)? ? ? ? 這種等待,只有等待的時間到了才會繼續向下執行,否則保持等待行為。
6.2隱式等待
? ? ? ? 隱式等待是一種“智能等待”,智能等待就是如果你請求查找的元素們在規定時間之內能找到就繼續程序的執行,如果你請求查找的元素們在規定時間之內沒有被找到,那么將會報錯退出(不使用異常機制捕獲)。
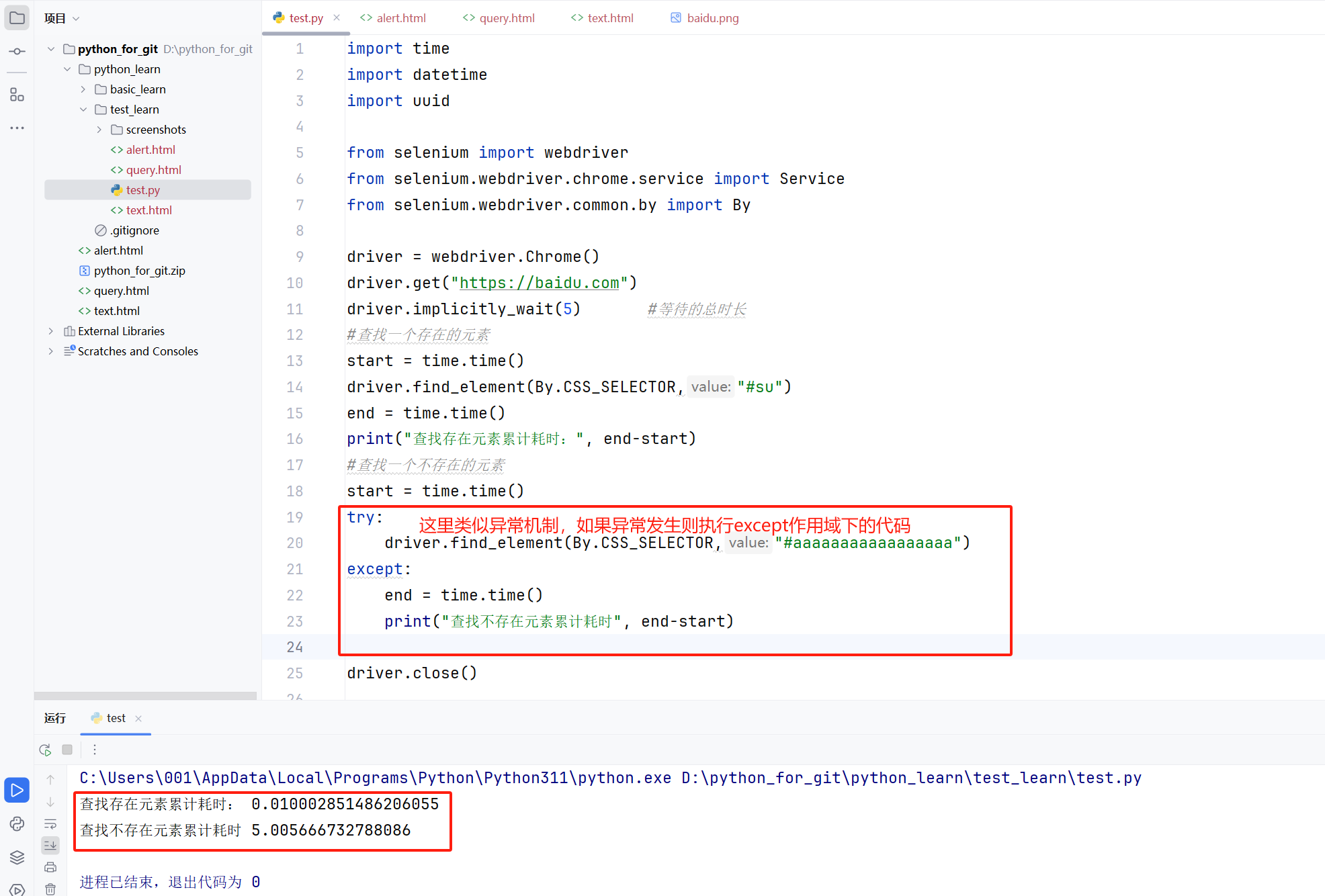
? ? ? ? 可以看到,智能等待不同于強制等待,智能等待作用于全局,這也就意味這你可以在程序的開始就定義等待的總時長且不會造成阻塞,這個時長是所有需要等待元素等待的時間之和。
import time
import datetime
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get("https://baidu.com")
driver.implicitly_wait(5) #等待的總時長
#查找一個存在的元素
start = time.time()
driver.find_element(By.CSS_SELECTOR,"#su")
end = time.time()
print("查找存在元素累計耗時:", end-start)
#查找一個不存在的元素
start = time.time()
try:driver.find_element(By.CSS_SELECTOR,"#aaaaaaaaaaaaaaaaa")
except:end = time.time()print("查找不存在元素累計耗時", end-start)driver.close()6.3顯示等待
? ? ? ? 顯示等待與隱式等待都屬于智能等待,這意味著顯示等待也是“設置一個等待總時長,如果成功等待繼續執行,否則報錯退出(不使用異常機制捕獲)”。但是顯示等待與隱式等待不同的是:顯示等待增加了更多與校驗有關的函數。
| 方法 | 說明 |
|---|---|
| title_is(title) | 檢查標題是否是期望值 |
| title_contains(title) | 檢查標題是否包含期望值 |
| visibility_of_element_located(locator,str]) | 檢查目標元素的可見性與期望值 |
| presence_of_element_located(locator,str]) | 檢查目標元素的可見性與期望值 |
| visibility_of(element) | 檢查已知存在于頁面DOM上的元素是否可見的期望 |
| alert_is_present() | 檢查是否出現彈窗 |
關于visibility_of_element_located()與presence_of_element_located()的額外說明:
presence_of_element_located:????????該方法用于等待指定元素在 DOM(文檔對象模型)中出現。也就是說,只要元素存在于 HTML 結構里,即便它在頁面上不可見(比如被隱藏、未加載完全等),這個方法也會判定元素已找到。
????????當你只需要確認元素已經被加載到 DOM 中,而不關心它是否可見時,就可以使用這個方法。例如,在等待一個動態加載的元素開始加載時。
visibility_of_element_located:????????此方法用于等待指定元素在頁面上可見。元素不僅要存在于 DOM 中,還得滿足一定的可見性條件,例如元素的寬度和高度大于 0、不被隱藏(
display屬性不為none,visibility屬性不為hidden)等。????????????????當你需要確保元素不僅存在于 DOM 中,還能在頁面上被用戶看到時,就應該使用這個方法。例如,在進行頁面交互之前,需要確保按鈕、輸入框等元素是可見的。
DOM (Document Object Model)將文檔解析為一個由節點和對象(包含屬性和方法)組成的結構集合。簡單來說,它把網頁文檔轉換為一個樹形結構,其中每個部分(如元素、屬性、文本等)都可以被看作是樹中的一個節點,開發者可以通過編程的方式對這些節點進行訪問、修改、刪除或添加等操作。
? ? ? ? 這里就不對顯示等待做演示了,智能等待的場景性比較強,讀者遇到了需要根據情況自行定奪。此外,需要說明的是:顯示等待與隱式等待不能混合使用!這樣做會導致意料之外的問題。
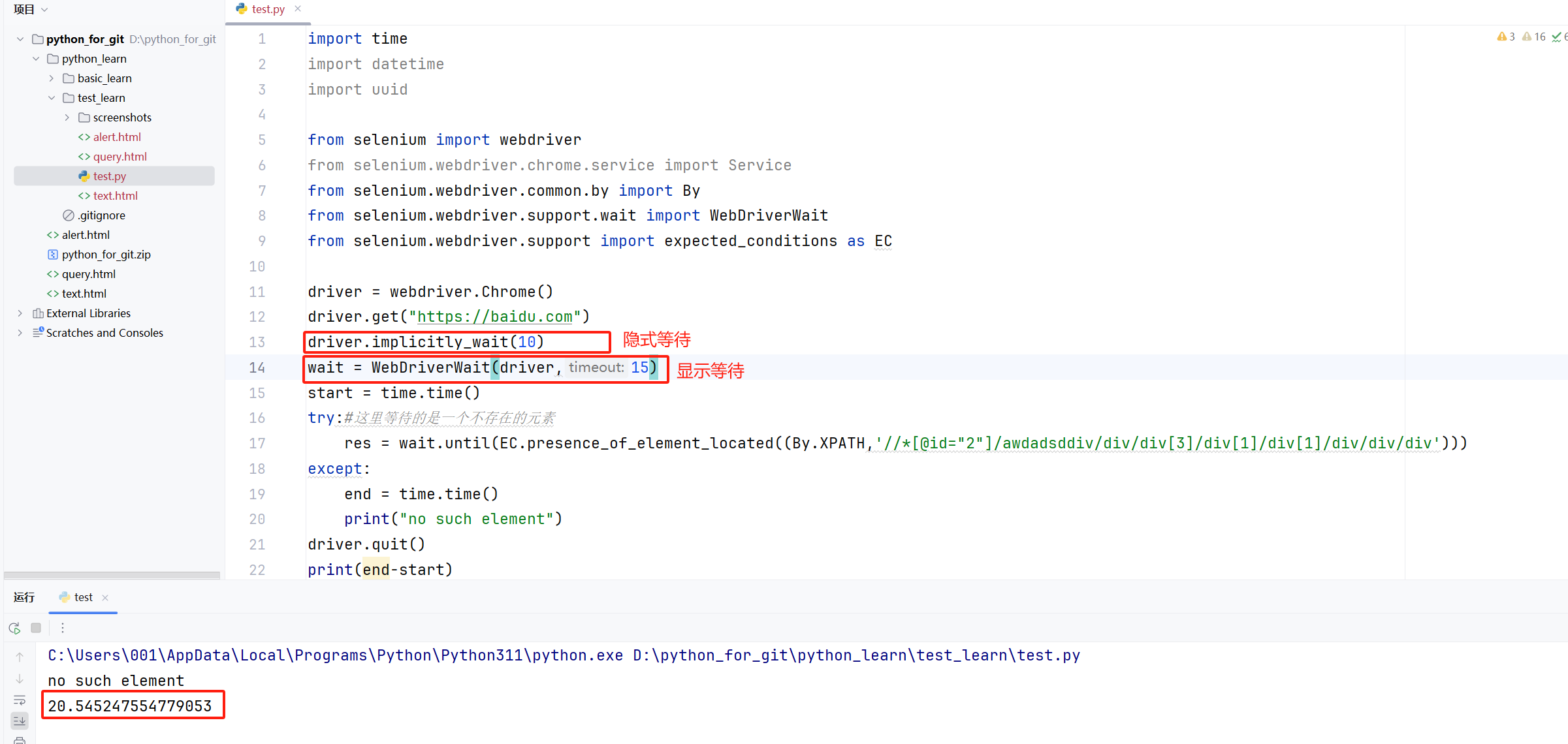
import time
import datetime
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()
driver.get("https://baidu.com")
driver.implicitly_wait(10)
wait = WebDriverWait(driver,15)
start = time.time()
try:#這里等待的是一個不存在的元素res = wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="2"]/awdadsddiv/div/div[3]/div[1]/div[1]/div/div/div')))
except:end = time.time()print("no such element")
driver.quit()
print(end-start)七、瀏覽器導航
? ? ? ? 這部分操作就比較常規了,主要是對瀏覽器導航欄中的內容進行操作,比如瀏覽器的刷新、前進、后退操作。這里就不粘貼結果了,感興趣的讀者可以自行運行查看結果。
import time
import datetime
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()
driver.get("https://baidu.com")
driver.find_element(By.CSS_SELECTOR,"#su").click()
driver.refresh() #刷新操作
time.sleep(2)
driver.back() #后退操作
time.sleep(2)
driver.forward() #前進操作
time.sleep(2)八、文件上傳
? ? ? ? 當我們需要上傳一個文件到網頁的時候,我們點擊上傳,就會彈出我們Windows的文件管理器讓我們選擇上傳文件,文件管理器又不是瀏覽器的一部分,我們的selenium怎么測試呢?
? ? ? ? 這就其實也有辦法,我們只需要將文件的路徑作為參數傳遞給send_keys方法就可以將本地的文件上傳。不過這也需要前端設計要進行配合否則也無法完成這個工作。(頁面在綁定資源里)
import time
import datetime
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()
driver.get("http://localhost:63342/python_for_git/test_learn/fileupload.html?_ijt=7mc670vp975dm5a1jdasgc0co2")
driver.find_element(By.CSS_SELECTOR,"#filePath").send_keys("C:/Users/001/Desktop/20241108191217.png")
time.sleep(2)
driver.find_element(By.CSS_SELECTOR,"body > button:nth-child(2)").click()
time.sleep(5)
driver.find_element(By.CSS_SELECTOR,"body > button:nth-child(3)").click()
time.sleep(5)
driver.close()九、瀏覽器參數設置
9.1無頭模式
? ? ? ? 無頭模式的主要目的是,想讓我們的檢測程序不發生將瀏覽器喚出的動作,即程序仍然正常執行,但是無需向我展示過程時,可以使用這個選項。這個選項開啟后,你將不會看到瀏覽器被換出并執行你提前定義好的行為,但是這些行為確實被執行了,只不過你很難進行感知了。
? ? ? ? 你可以嘗試“注釋無頭模式選項”和“不注釋無頭模式選項”對比差異。
import time
import datetime
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECoptions = webdriver.ChromeOptions()
options.add_argument('--headless') #設置無頭模式
driver = webdriver.Chrome(options=options)
driver.get("http://baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("python") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#su").click() #找到按鈕元素并執行點擊操作
time.sleep(2)9.2瀏覽器加載策略? ? ? ?
????????這里主要講解三種瀏覽器加載內容的模式,實際上與等待也有著一定的影響~~
| 策略 | 說明 |
|---|---|
| normal | 默認選項,表示等待每一個資源加載 |
| eager | 省略加載,開始檢測的時,DOM加載完畢,但可能存在較大的資源未加載完畢。 |
| none | 不對任何資源進行等待,不會被任何事務阻塞 |
? ? ? ? 下面主要說一下這幾種策略對等待時間的影響:
1.?normal?加載策略
- 原理:
normal?是默認的加載策略,它會等待頁面上的所有資源(包括 HTML、CSS、JavaScript、圖片等)都加載完成后,才會認為頁面加載完畢。這意味著瀏覽器會等待每一個資源加載,直到?onload?事件觸發。 - 對等待時間的影響:這種策略會消耗隱式等待和顯示等待的時間。因為在頁面資源加載過程中,Selenium 會持續等待,直到頁面完全加載。如果頁面上有大量的資源需要加載,等待時間可能會很長,從而導致隱式等待或顯示等待超時。例如,若頁面上有一個大尺寸的圖片加載緩慢,在?
normal?策略下,Selenium 會一直等待該圖片加載完成,期間可能會消耗掉隱式等待或顯示等待設置的時間。?
2.?eager?加載策略
- 原理:
eager?策略會省略一些資源的加載等待,當 DOM 加載完畢(即?DOMContentLoaded?事件觸發)時,就認為頁面加載完成,而不等待所有的資源(如圖片等大資源)加載完成。 - 對等待時間的影響:相比?
normal?策略,eager?策略通常會減少等待時間。因為它不需要等待所有資源加載,只要 DOM 準備好就可以開始后續操作。不過,它仍然可能消耗隱式等待和顯示等待的時間。例如,如果在 DOM 加載完成后,某些元素的動態內容還需要通過 JavaScript 進一步加載,而你使用了顯示等待來等待這些元素滿足特定條件,那么在這個過程中就會消耗等待時間。
3.?none?加載策略
- 原理:
none?策略不對任何資源進行等待,瀏覽器不會被任何事務阻塞,在開始執行后續操作時,頁面可能還在加載中。 - 對等待時間的影響:
none?策略一般不會消耗隱式等待和顯示等待的時間用于頁面加載。因為它不會等待頁面資源加載完成,而是立即開始執行后續的代碼。但是,如果你在后續代碼中使用了隱式等待或顯示等待來等待特定元素或條件,那么等待時間將取決于這些元素或條件的實際情況,而不是頁面加載的情況。例如,你使用顯示等待來等待一個元素可見,即使頁面還在加載中,Selenium 也會在指定的時間內嘗試查找該元素,直到滿足條件或超時。
? ? ? ? 我們之前講到在某些情況下不建議混用 “顯式等待” 與 “隱式等待”,原因在于可能會出現等待時間不確定的問題。當隱式等待和顯式等待都在等待同一個內容的加載時,即出現 “交叉” 情況,兩者都會對等待時間產生影響,但其具體的時間消耗并非簡單的相加,可能會因多種因素而變得復雜,從而導致最終等待時間難以準確預估。而當隱式等待和顯式等待的內容相互獨立,也就是 “無關” 的情況時,它們各自按照自己的規則消耗等待時間,這也會使得整個等待過程的總時間變得不確定,增加了測試用例執行時間的不可控性。
? ? ? ? 這里我們在展示一下如何對加載策略進行設置。
import uuidfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECoptions = webdriver.ChromeOptions()
options.page_load_strategy = 'eager'
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(4)begin = time.time()
driver.get("https://www.bilibili.com/")
driver.find_element(By.CSS_SELECTOR,"#nav-searchform > div.nav-search-content > input").send_keys("python") #找到輸入框并輸入文本
time.sleep(2) #休眠兩秒觀察現象
driver.find_element(By.CSS_SELECTOR,"#nav-searchform > div.nav-search-btn").click() #找到按鈕元素并執行點擊操作
time.sleep(2)
end_time = time.time()
print(end_time - begin)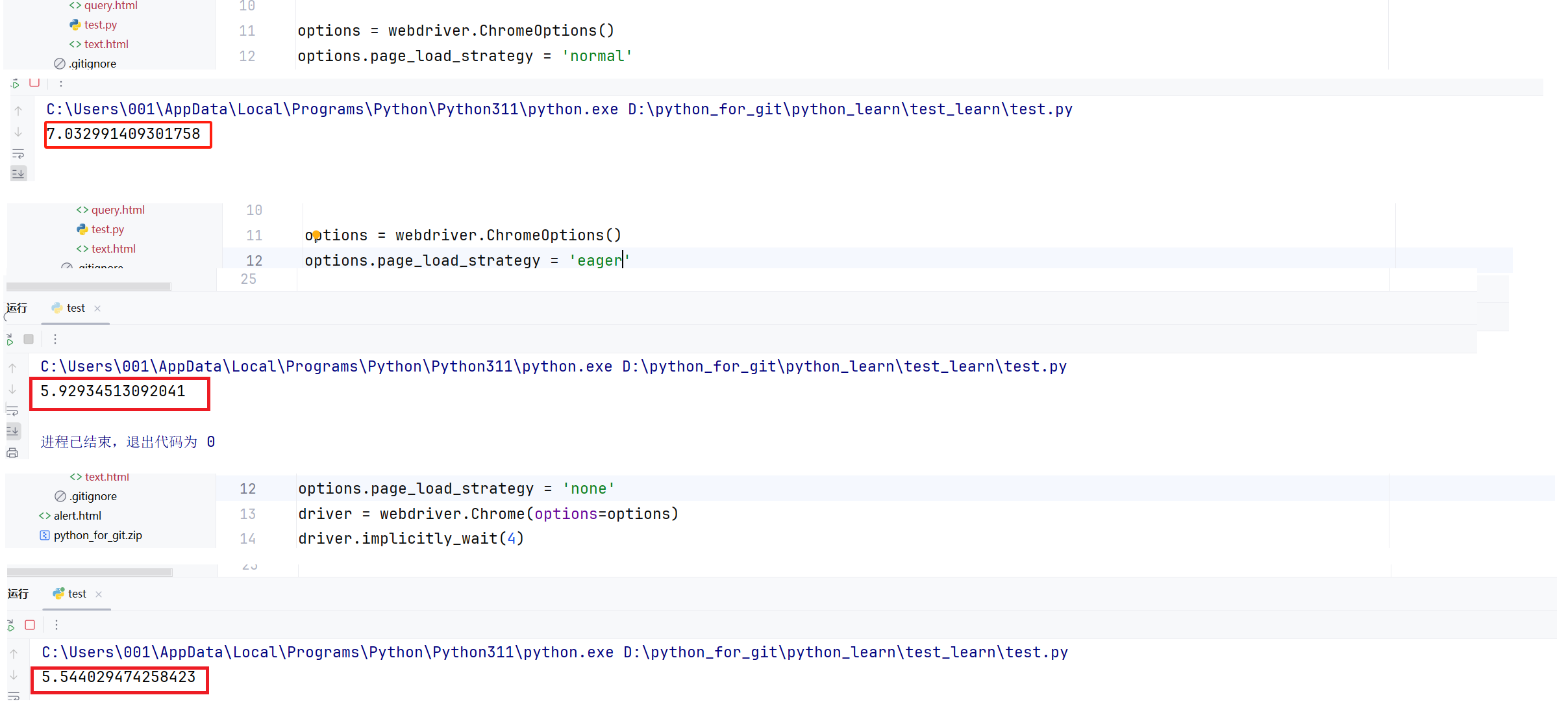
? ? ? ? 這里的有關時間的測試,實際上相當不嚴謹,一方面受限于網絡狀況與網絡波動,另一方面受限于本地內存資源等,這里正常應該多次實驗取平均值,來進行驗證,但是這里作者就不這么嚴謹了,如果你自己去進行數學統計來得出一個更嚴謹的結論。
? ? ? ? 這里作者測試的時間是,打開B站,在搜索框中搜素“python”并進行搜索的整體時間。?









相同,為某個對象設置disabled屬性)

什么是MCP?)





)
)
