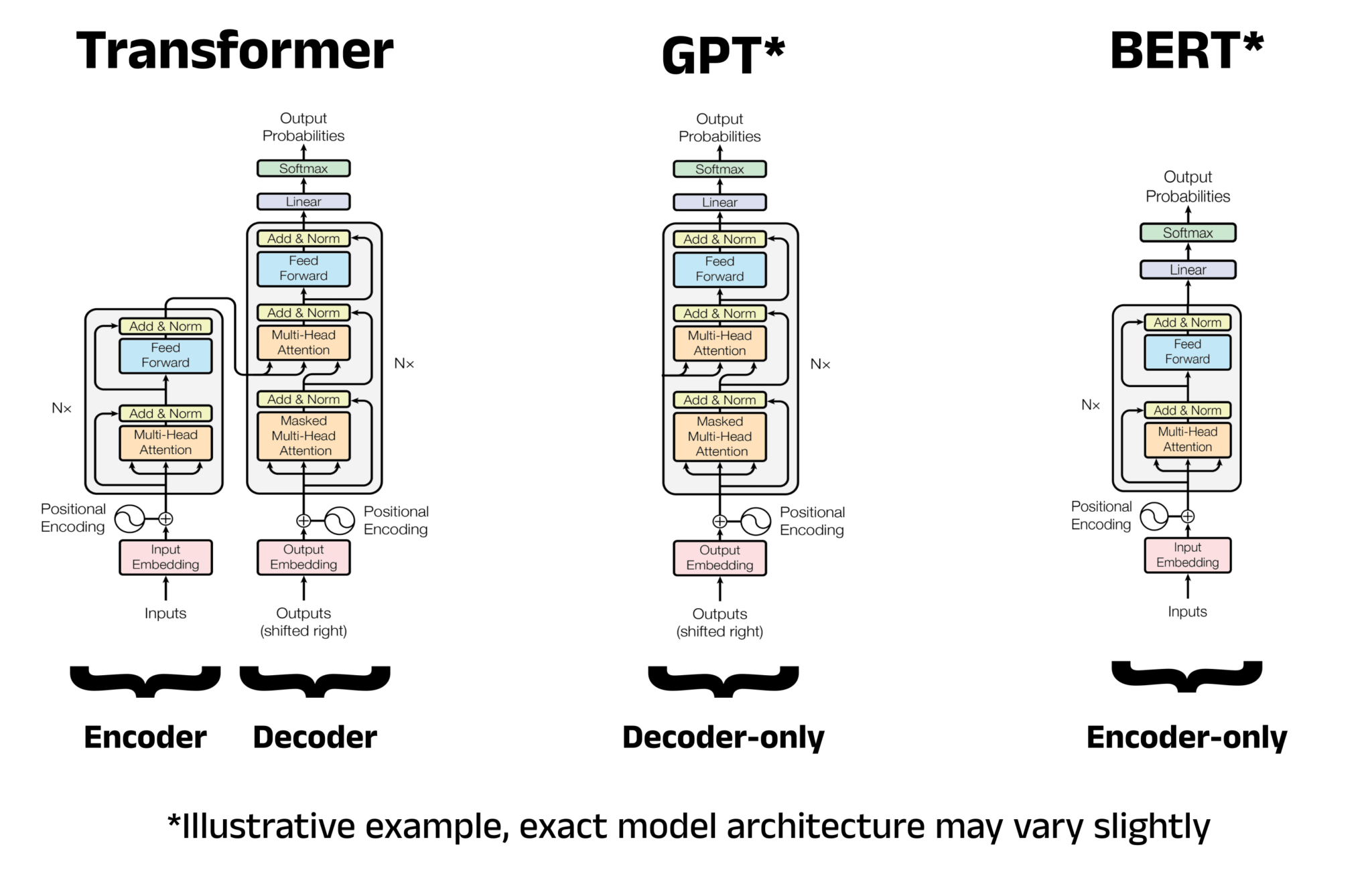
BERT的模型架構
BERT: Bidirectional Encoder Representations from Transformers
BERT這個名稱直接反映了:它是一個基于Transformer編碼器的雙向表示模型。BERT通過堆疊多層編碼器來構建深度模型。舉例來說:
- BERT-Base:堆疊了12層Encoder,12個注意力頭,768維隱藏層,參數量約110M
- BERT-Large:堆疊了24層Encoder,16個注意力頭,1024維隱藏層,參數量約340M
BERT的輸入表示
BERT的輸入表示是其獨特之處,包含三部分:
- Token Embedding:詞元嵌入,將輸入的單詞轉換為向量表示
- Segment Embedding:段落嵌入,用于區分輸入中的不同句子
- Position Embedding:位置嵌入,編碼詞元在序列中的位置信息
與原始Transformer使用三角函數計算的Position Encoding不同,BERT的Position Embedding是需要學習的參數。
BERT預訓練方法
同時進行兩項無監督任務的訓練來學習語言,即:
- 掩碼語言模型MLM
- 下一句預測NSP
接下來我們展開講解兩種任務
掩碼語言模型(Masked Language Model, MLM)
即完形填空從而讓大模型可以學到上下文。具體做法是(論文中并沒講述為何用這個比例,可能是因為這個比例效果更佳):
- 隨機選擇輸入tokens中的15%
- 對于被選中的tokens:
策略1- 80%的情況下,將其替換為特殊標記[MASK]
策略2- 10%的情況下,將其替換為隨機詞
策略3- 10%的情況下,保持不變
舉例:我愛大語言模型

下一句預測(Next Sentence Prediction, NSP)
NSP任務要求模型判斷兩個給定句子是否為原文中的相鄰句子。這可以讓模型理解句子間的關系。是與不是,這也就是轉為了二分類任務。
舉例:我愛大語言模型







![[Windows] 能同時打開多個圖片的圖像游覽器JWSEE v2.0](http://pic.xiahunao.cn/[Windows] 能同時打開多個圖片的圖像游覽器JWSEE v2.0)
![[AI Tools] Dify 工具插件上傳指南:如何將插件發布到官方市場](http://pic.xiahunao.cn/[AI Tools] Dify 工具插件上傳指南:如何將插件發布到官方市場)


--- GPT2: Language Models are Unsupervised Multitask Learners?)
![數字孿生[IOC]常用10個技術棧(總括)](http://pic.xiahunao.cn/數字孿生[IOC]常用10個技術棧(總括))

![[Windows] 東芝存儲診斷工具1.30.8920(20170601)](http://pic.xiahunao.cn/[Windows] 東芝存儲診斷工具1.30.8920(20170601))





