文章目錄
- TLDR;
- 量化分類
- 量化時機
- 量化粒度
- ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
- 細粒度硬件感知量化
- 低成本逐層知識蒸餾(Layer-by-layer Knowledge Distillation, LKD)
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
- 量化維度
- 激活平滑
- 量化效果
- OBS(Optimal Brain Surgeon)
- OBQ(Optimal Brain Quantization)
- 優化1:使用L2重建量化損失
- 優化2:行并行與遞歸求解 H ? 1 H^{-1} H?1
- 算法實現
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- 步驟1: 任意順序量化(Arbitrary Order Insight)
- 步驟2: 批量量化(Lazy Batch-Updates)
- 步驟3: Cholesky矩陣分解(Cholesky Reformulation)
- 算法過程
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
- 保留1%重要性參數可提升量化性能
- 激活感知縮放保護重要權重
參考論文
- 2022.01 - ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
- 2022.08 - LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- 2022-10 - GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- 2022.11 - SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
- 2023.06 - AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
參考文章
- LLM 量化技術小結
- OBS: LLM模型量化世界觀(上)
- 真的從頭到尾弄懂量化之GPTQ
TLDR;
ZeroQuant 對權重使用group-wise量化,對激活采用dynamic per-token量化,并實現fusion kernel,加速量化。同時,設計了逐層知識蒸餾LKD,進一步提高量化精度。
LLM.int() 驗證了尺寸大于6.7B模型激活值中的離群點對模型性能影響的顯著性,它根據啟發式規則(激活值較大并且存在于一定比例的網絡層和序列中)找到離群特征,采用混合精度(離群FP16、其他INT8)量化。
SmoothQuant發現激活中存在離群點,導致方差比較大,比權重難量化。發現離群特征在不同token之間的方差比較小,但由于硬件加速內核的限制,無法在矩陣運算內圍進行縮放。使用數學變換 ( X diag ( s ) ? 1 ) ? ( diag ( s ) W ) (\mathbf X\text{diag}(\mathbf s)^{-1})\cdot(\text{diag}(\mathbf s)\mathbf W) (Xdiag(s)?1)?(diag(s)W),將激活的量化難度轉移到權重,同時還能使用高效的GeMM內核。
OBS屬于剪枝算法,利用二階導數信息貪婪地一步一步移除剪枝損失最小的權重,剪枝損失約為 0.5 ? δ w ? H δ w 0.5*\delta_w^\top H\delta_w 0.5?δw??Hδw?。每次移除一個權重后,更新其他未剪枝的權重,以補償剪枝帶來的損失。
OBQ將OBS應用到模型量化,將量化損失重構為量化激活的L2損失,損失近似為 0.5 ? ( quant ( w ) ? w ) 2 / H q q ? 1 0.5*{(\text{quant}(w) - w)^2}/{H_{qq}^{-1}} 0.5?(quant(w)?w)2/Hqq?1?,也就是說,優先選擇量化后權重數值變化小、Hessian對角元素比較小(通常對應的逆比較大)的權重。同時使用迭代方式更新 H ? 1 H^{-1} H?1,降低量化后更新Hessian逆矩陣的時間復雜度。
GPTQ不是RTN簇量化算法(縮放到緊鄰整數,如LLM.int8()、SmoothQuant、AWQ等),它是對OBQ的改進,認為OBS、OBQ貪婪依次選擇剪枝/量化誤差比較小的權重和隨機選擇權重相比,最終的量化性能差異不大,可能的原因是OBQ中影響較大的權重都留在比較靠后的位置才量化,而此時能補償量化誤差的參數所剩無幾,因此參數的量化順序沒那么重要。GPTQ采用從左到右分組的固定順序量化,并對Hessian逆矩陣Cholesky分解,使得分步量化時不需要顯示更新 H ? 1 H^{-1} H?1,避免量化大模型時反復矩陣求逆帶來的累積誤差,并且相比OBQ時間復雜度下降一個數量級。
GPTQ代碼實現中act-order參數是按照Hessian矩陣對角元素大小逆序排列,意味著優先量化Hessian矩陣對角元素比較大的特征。而Hessian對角元素值表示特征對損失的曲率,值越大對損失影響越大,這與OBQ優先選擇量化損失最小的權重的觀念相反。AWQ中給出的解釋時,優先量化重要性權重,避免補償重要性權重。
AWQ認為權重具有不同的重要性,量化時僅保留1%重要性權重為FP16,就可以達到很好的量化效果。量化之前對重要性權重進行一定程度的放大,可提高量化性能。為避免使用混合精度量化,采用激活感知搜索為不同通道的權重設置不同的縮放率,從而保護重要性權重,實現單精度INT3/INT4量化。
不同量化方法一覽表
| 量化方法 | 量化類型 | 權重 | 激活 | Hessian矩陣 | 描述 |
|---|---|---|---|---|---|
| ZeroQuant | Any | group-wise | dynamic per-token | 否 | 小模型尚可,不能量化大模型 |
| LLM.int8() | W8A8 | per-channel | dynamic per-token | 否 | 混合精度分解,動態量化激活,不能硬件加速,速度比FP16慢約20%,但175B以下模型可達無損量化 ,bitsandbytes庫有實現 |
| SmoothQuant-O3 | W8A8 | per-tensor | static per-tensor | 否 | 效果與LLM.int8()差不多,但是速度更快 |
| GPTQ | W4A16 | group-wise | / | 是 | |
| AWQ | W4A16 | group-wise | / | 否 |
量化分類
根據量化后的目標區間,量化(也稱為離散化)可分為二值化、三值化、定點化(INT4, INT8)等,常用的是定點量化,就是把16位浮點數轉化為低精度的8位或4位整數。
根據量化節點的分布,又可以把量化分為均勻量化和非均勻量化。非均勻量化是根據量化參數的概率分布分配量化節點,參數密集的區域分配更多的量化節點,其余部分少一些,這樣量化精度較高,但計算復雜。
現在LLM主要采用的是均勻量化,它又可以分為對稱量化和非對稱量化。比較常見的FP => INT量化方式是minmax量化。令 x \bm x x表示原始值, s s s表示縮放比例, q m a x q_{max} qmax?表示目標區間最大值(目標區間為 [ ? 2 n , 2 n ? 1 ] [-2^n,2^n-1] [?2n,2n?1]), n n n表示位數。對稱性量化計算簡單,非對稱量化的量化區間利用率更高。
對稱性量化(Symmetric Quantization/Absmax Quantization)
縮放比例為原始數值的最大絕對值映射到目標區間的最大值:
x q = clamp ( ? x s ? , ? q m a x , q m a x ) , s = max ? ( ∣ x ∣ ) q m a x \bm x_q=\text{clamp}\Big(\Big\lceil\frac{\bm x}{s}\Big\rfloor,-q_{max}, q_{max} \Big), \quad s=\frac{\max(|\bm x|)}{q_{max}} xq?=clamp(?sx??,?qmax?,qmax?),s=qmax?max(∣x∣)?
非對稱量化 (Asymmetric Quantization/Zeropoint Quantization)
縮放比例為原始數值區間縮放到目標數值區間:
x q = clamp ( ? x s ? + z , ? q m a x , q m a x ) , s = x m a x ? x m i n q m a x ? q m i n , z = q m i n ? x m i n s \bm x_q=\text{clamp}\Big(\Big\lceil\frac{\bm x}{s}\Big\rfloor+z, -q_{max}, q_{max}\Big), \quad s=\frac{x_{max}-x_{min}}{q_{max}-q_{min}},\quad z=q_{min}-\frac{x_{min}}{s} xq?=clamp(?sx??+z,?qmax?,qmax?),s=qmax??qmin?xmax??xmin??,z=qmin??sxmin??
其中, z z z表示零點,區間映射中的平移量。
區間映射
把數值區間[xmin, xmax]映射到[ymin, ymax]:
y = x ? x m i n s + y m i n , s = x m a x ? x m i n y m a x ? y m i n y=\frac{x - x_{min}}{s} + y_{min},\quad s=\frac{x_{max}-x_{min}}{y_{max}-y_{min}} y=sx?xmin??+ymin?,s=ymax??ymin?xmax??xmin??
如果 y m i n = 0 y_{min}=0 ymin?=0,則
y = x ? x m i n x m a x ? x m i n ? y m a x y=\frac{x-x_{min}}{x_{max}-x_{min}}*y_{max} y=xmax??xmin?x?xmin???ymax?
量化時機
根據量化的時機,量化可分為量化感知訓練和訓練后量化。
量化感知訓練(Quantization Aware Training, QAT) 是在訓練過程中對權重和激活先量化再反量化,引入量化誤差,在優化Training Loss時兼顧Quantization Error。方法雖好,但訓練成本大大增加。
訓練后量化(Post Training Quantization, PTQ) 是在訓練結束后對權重和激活進行量化,是LLM主流量化方法。在推理前事先計算好權重量化的參數,但對于激活而言,由于取決于具體輸入,量化比較復雜。激活量化又可以分為動態量化和靜態量化。動態量化,on-the-fly方式,推理過程中,實時計算激活的量化系數。靜態量化,推理前,利用校準集事先計算好激活的量化系數,推理時直接應用。
量化粒度
量化粒度是指計算量化縮放因子 s s s的數據范圍。數據范圍越小,量化誤差越小;數據范圍越大,更多的待量化參數共享一個縮放因子 s s s,誤差越大,但額外占用顯存越少、計算速度越快。
- per-tensor: 最簡單、最大的量化粒度,單個張量(權重/激活值)中所有數據共享一個量化參數。
- per-token: 僅針對激活值,單獨量化每個時間步的激活值。
- per-channel: 針對激活值的輸出通道和權重矩陣的輸入輸出通道的向量,單獨量化單個向量。比如對于矩陣乘 X @ W \mathbf X @\mathbf W X@W, X ∈ R T × h _ i n \mathbf X\in\R^{T\times h\_in} X∈RT×h_in, W ∈ R h _ i n × h _ o u t \mathbf W\in\R^{h\_in\times h\_out} W∈Rh_in×h_out,對 X X X的h_in和 W \mathbf W W的h_in和h_out維度的向量單獨量化,但因硬件加速限制,不易對h_in維度向量單獨量化。
- group-wise: 將tensor按照某一維按照group size劃分組,每組單獨量化,可提高計算效率。量化粒度位于per-tensor和vertor-wise之間,vector-wise是per-token和per-channel的統稱。如GPTQ和AWQ中默認組大小是128,即每次處理128列。權重矩陣以row-major存儲,shape是[out_features, in_features],權重分組是對輸入特征分組。SmoothQuant也提到,激活在序列維度上高方差,在輸入維度上低方差,因此按輸入維度分組是合理的。在輸入維度上分組,離群特征(重要特征)會保留精度,但舍棄了其他多數非重要特征的量化精度。
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
細粒度硬件感知量化
Group-wise Quantization for Weights
分組量化權重矩陣,考慮硬件加速。
Token-wise Quantization for Activations
大語言模型激活方差比較大,使用校準集事先獲取量化因子,推理時靜態量化,會導致性能下降。解決這一問題的自然想法就是,動態、細粒度地量化每一個token。
動態量化激活值,就是Zero名稱的由來?
現有的深度學習框架使用per-token量化,會增加內存和GPU之間數據交換頻率,增加量化和反量化開銷。本文開發了kernel-fusion算子,將量化和LayerNorm等運算融合,將GeMM乘法和反量化融合,以緩解顯存帶寬瓶頸(硬件感知)。

反量化融合
量化模式下,輸入(激活值)和權重執行INT8矩陣乘,為避免數值溢出,輸出通過INT32累加器存儲。反量化時,將INT32乘以兩個量化尺度(激活和權重的縮放因子),再轉回FP16。這期間涉及中間結果INT32的讀寫。
反量化融合就是一步到位:
FP16?=?INT32? × S w × S a \text{FP16 = INT32 }\times S_w \times S_a FP16?=?INT32?×Sw?×Sa?
低成本逐層知識蒸餾(Layer-by-layer Knowledge Distillation, LKD)
知識蒸餾(Knowledge Distillation, KD)是緩解模型壓縮后精度下降的重要方法。
傳統KD的限制: 訓練過程中,需要加載教室和學生模型,增加了存儲和計算成本;KD通常需要從頭訓練學生模型,需要存儲梯度、一/二階動量副本; 需要訓練教師模型的原始數據,對于私有模型,通常無法獲取。
逐層知識蒸餾/逐層量化: 假定輸入是 X \mathbf X X,需量化第 L k L_k Lk?層,量化版本是 L ^ k \hat L_k L^k?,則該層的量化損失為
L L K D , k = MSE ? ( L k ? L k ? 1 ? L k ? 2 ? … ? L 1 ( X ) ? L ^ k ? L k ? 1 ? L k ? 2 ? … ? L 1 ( X ) ) \mathcal{L}_{L K D, k}=\operatorname{MSE}\left(L_k \cdot L_{k-1} \cdot L_{k-2} \cdot \ldots \cdot L_1(\boldsymbol{X})-\widehat{L}_k \cdot L_{k-1} \cdot L_{k-2} \cdot \ldots \cdot L_1(\boldsymbol{X})\right) LLKD,k?=MSE(Lk??Lk?1??Lk?2??…?L1?(X)?L k??Lk?1??Lk?2??…?L1?(X))
訓練過程中每次只更新第 L k L_k Lk?層參數,顯存需求很少。
直通估計器(Straight-Through Estimator ,STE)
STE常用與量化感知訓練(QAT),將量化操作視為恒等變換。前向過程執行量化(round、clamp等操作)得到離散張量,模擬模型量化推理。反向傳播時,將round(x)的梯度近似為1,即恒等映射,保證梯度傳播。
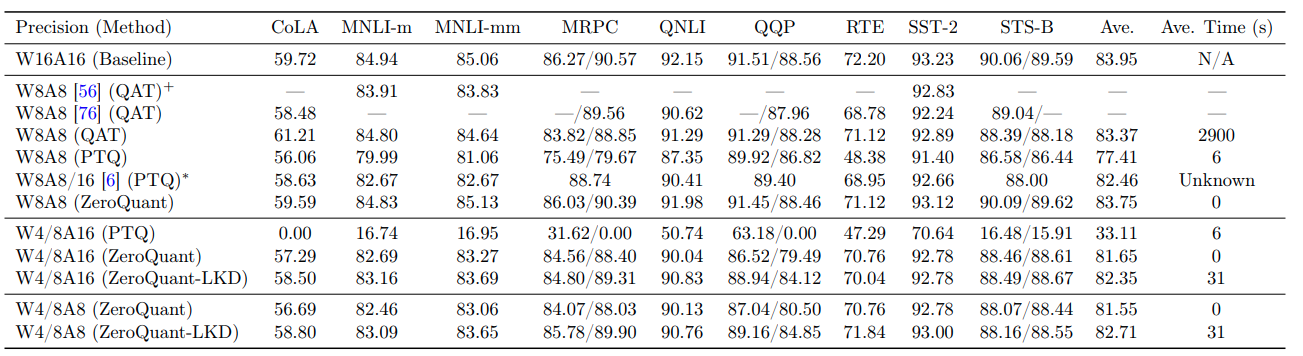
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
vector-wise可輕松應對參數兩小于2.7B的模型,但當模型尺寸超過這一數值,受離群值影響,量化性能下降。
離群點的分布
對于超過6.7B的LLMs,推理時激活會出現離群點。其他值20x的離群點首次大概出現深度為25%的網絡層,當模型大小逐漸增至6.7B,所有的網絡層都有離群點,序列中75%的位置都受離群點影響。對于6.7B模型,離群點呈系統性分步(要么不出現,要么大多數層中出現),每個輸入序列大致有150,000個離群點,它們僅分布在整個transformer的6個特征維度。
離群點的重要性
若將離群點設置0,會導致self-attn softmax的top-1概率下降20%,語言困惑度增加600%以上,盡管這些離群點僅占輸入特征的0.1%。
隨著模型尺寸增加,PPL逐漸降低,離群點顯現,可以推測離群點對模型性能影響很重要。
如何找到離群點
規則:特征大于6、影響25%以上的網絡層以及影響序列中6%以上的token。
具體地說,對于 L L L層網絡和隱狀態 X l ∈ R s × h \mathbf X_l\in\R^{s\times h} Xl?∈Rs×h, h i h_i hi?表示任意層的第 i i i個特征, 0 ≤ i ≤ h 0\le i\le h 0≤i≤h。如果 h i h_i hi?是離群點,則至少25%的網絡層和5%的token在位置 i i i的特征值大于6。
LLM.int8()的工作
- 混合精度分解,99.9%的矩陣乘中單獨量化每對內積(vector-wise),0.1%離群點使用FP16矩陣乘。
- 在高達175B的模型上推理幾乎沒有損失。

LLM.int8()的步驟
- 給定16位的輸入和權重,將其分解為離群值和其他值兩個子矩陣。
- 常規輸入矩陣的行向量和權重矩陣的列向量執行Absmax INT8量化(歸一化),執行INT8矩陣乘,再乘以各自的縮放因子反量化回FP16。此處行列是相對的,如果矩陣乘是WX形式(圖中所示),則對輸入列和權重行分別執行INT8量化。
- 離群矩陣執行FP16矩陣乘。
- 兩部分結果在FP16精度下合并。
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
當LLMs尺寸超過6.7B時,激活值會出現大量離群點,比小模型(BERT)更難量化。ZeroQuant使用per-token量化激活值,使用group-wise量化權重,在小模型(小于6B)上表現優異,但在175B大模型上性能嚴重下降。LLM.int8()使用混合精度分解(激活離群點使用FP16,其它使用INT8)解決了大模型量化準確率下降問題,但這種混合精度分解不能很好利用硬件加速。
大模型每個token的激活值因離群點的存在(其他多數激活值的100x),激活值離群點擴展了數據范圍,增加了通道方差,導致其它多數激活值被分配到很窄的量化區間,增加了量化難度。觀察發現這些離群點大多位于小部分固定通道,通道內部方差較小。權重值分步均勻、方差小,比激活容易量化。
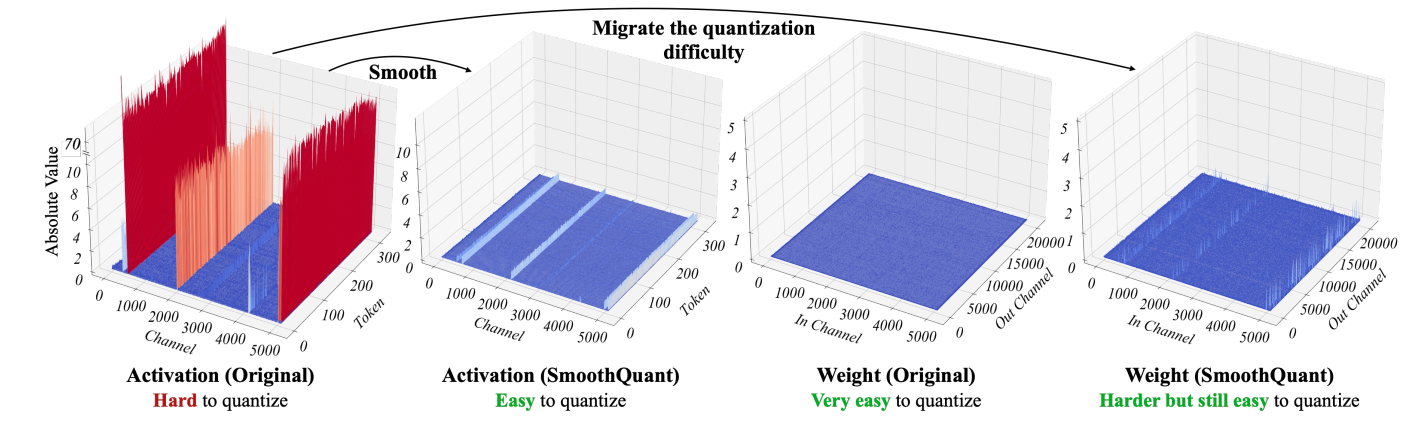
從單個token來看,若某個通道存在離群點,那其他token的這個通道也會是離群點,但各token在這個通道上的方差較小。因此,執行per-channel量化的預期效果會比per-tensor量化效果要好。
SmoothQuant的工作
- 使用校準集離線量化,通過數學變換將激活的量化難度遷移到權重,平滑了激活離群點,調整后的激活和權重都容易量化。
- 間接實現per-channel量化,并且能夠GEMM內核,相比現有權重激活量化或僅權重量化,硬件利用效率更高。
- 支持對所有GEMMs大模型進行INT8的權重和激活量化,如OPT-175B、BLOOM-176B和GLM-130B等。
相比FP16,INT8對GPU顯存需求減半,矩陣乘的吞吐量加倍。
量化維度
 |  |
|---|
上右圖顯示量化的不同細粒度:per-tensor、per-token和per-channel。per-tensor對整個tensor統一量化,per-token對輸入的每個時間步( T T T維)單獨量化,per-channel對權重的每個輸出維度( C o C_{o} Co?)單獨量化。
為了利用硬件加速的GEMM內核,只能在矩陣乘的外圍進行per-channel量化,比如輸入矩陣的序列維度和權重矩陣的輸出維度,不能對 C i C_i Ci?維單獨量化。現有方法多使用per-token量化線性層,無法解決各時間步激活方差大的問題,效果比per-tensor僅好一點點。

量化維度的限制
對于矩陣乘 X @ W X@W X@W, X ∈ R n × i n X\in \R^{n\times in} X∈Rn×in, W ∈ R i n × o u t W\in \R^{in\times out} W∈Rin×out, X X X的每一行和 W W W的每一行做內積。如果對 X X X執行per-channel量化,會導致 X X X的每一列都有獨立的縮放因子,內積運算中每一項都需要做縮放,不能有效利用GEMM內核。
也就說,為了高效利用GEMM內核,只能在矩陣乘的外圍(n維和out維)做縮放,不能在內圍(in維)。縮放因子不能從in維提取。
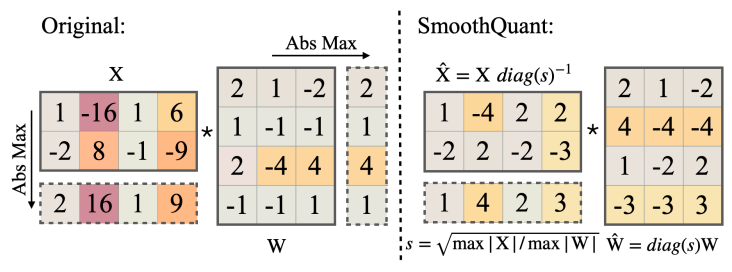
激活平滑
由于per-channel量化不可行,我們將輸入激活的每個channel各除以一個平滑因子,為保證數學等價性,需在反方向縮放權重矩陣。
Y = ( X diag ( s ) ? 1 ) ? ( diag ( s ) W ) = X ^ W ^ \mathbf Y=(\mathbf X\text{diag}(\mathbf s)^{-1})\cdot(\text{diag}(\mathbf s)\mathbf W)=\hat{\mathbf X}\hat{\mathbf W} Y=(Xdiag(s)?1)?(diag(s)W)=X^W^
X有乘對角矩陣,列縮放;W左乘對角矩陣,行縮放。
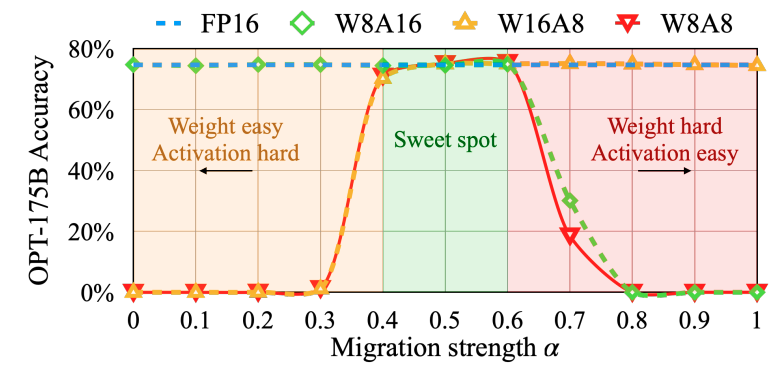
當所有通道縮放之后的最大值相同,則總的量化效率最高。令 s j = max ? ( ∣ X j ∣ ) s_j=\max(|\mathbf X_j|) sj?=max(∣Xj?∣),縮放后激活的各通道的最大值為1。激活的量化難度轉移到權重矩陣,導致權重量化變難。因此,需要將量化難度均攤到激活和權重,公式如下:
s j = max ? ( ∣ X j ∣ ) α / max ? ( ∣ W j ∣ ) 1 ? α s_j=\max(|\mathbf X_j|)^\alpha/\max(|\mathbf W_j|)^{1-\alpha} sj?=max(∣Xj?∣)α/max(∣Wj?∣)1?α
 |  |
|---|
對于多數模型 α \alpha α取0.5表現良好, α \alpha α越大,權重的量化難度越大。論文中在Pile驗證集進行了網格搜索。GLM130B激活比較難量化, α \alpha α選取0.75,其他模型則選取0.5。
Transformer Block的量化
Softmax和LayerNorm使用FP16運算,其他運算使用INT8。

量化效果
SmoothQuant-O1-3效率逐漸增加。



OBS(Optimal Brain Surgeon)
1992年發表,從數學角度推導如何對模型剪枝(參數置0)。
泰拉展開式
函數 f ( x ) f(x) f(x)在指定點 x 0 x_0 x0?附近的展開式
f ( x ) = f ( x 0 ) 0 ! + f ′ ( x 0 ) 1 ! ( x ? x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x ? x 0 ) 2 + ? + f ( n ) ( x 0 ) n ! x n + R n ( x ) f(x)=\frac{f(x_0)}{0!}+\frac{f'(x_0)}{1!}(x-x_0)+\frac{f''(x_0)}{2!}(x-x_0)^2+\cdots +\frac{f^{(n)}(x_0)}{n!}x^n+R_n(x) f(x)=0!f(x0?)?+1!f′(x0?)?(x?x0?)+2!f′′(x0?)?(x?x0?)2+?+n!f(n)(x0?)?xn+Rn?(x)
f ( x 0 + Δ x ) f(x_0+\Delta x) f(x0?+Δx)在 x 0 x_0 x0?處的二階泰勒展開式
f ( x 0 + Δ x ) ≈ f ( x 0 ) + f ′ ( x 0 ) Δ x + f ′ ′ ( x 0 ) 2 ( Δ x ) 2 + O ( ∣ ∣ Δ w ∣ ∣ 3 ) f(x_0+\Delta x)\approx f(x_0)+f'(x_0)\Delta x+\frac{f''(x_0)}{2}(\Delta x)^2+O(||\Delta_w||^3) f(x0?+Δx)≈f(x0?)+f′(x0?)Δx+2f′′(x0?)?(Δx)2+O(∣∣Δw?∣∣3)
W q W_q Wq?可看作為 W W W加擾動,函數 E ( W q ) E(W_q) E(Wq?)在 W W W處的二階泰勒展開式為
E ( W q ) = E ( W + Δ W ) ≈ E ( W ) + 1 2 δ w ? H δ w E(W_q)=E(W+\Delta W)\approx E(W)+\frac{1}{2}\delta_w^\top H\delta_w E(Wq?)=E(W+ΔW)≈E(W)+21?δw??Hδw?
訓練好意味著參數 W W W位于局部極小值附近,也就是一階導數為0。 H H H是Hessian矩陣。 Δ x \Delta x Δx和 δ w \delta_w δw?表示擾動量/增量,只是記法不同。
因此,剪枝帶來的損失為
L = Δ E ≈ 1 2 δ w ? H δ w \mathcal L=\Delta E\approx \frac{1}{2}\delta_w^\top H\delta_w L=ΔE≈21?δw??Hδw?
OBS的核心思想:對于參數向量 w = [ w 1 , ? , w n ] w=[w_1,\cdots,w_n] w=[w1?,?,wn?],依次去除影響最小的分量 w q w_q wq?,并修正其它分量 w i ( i ≠ q ) w_{i(i\ne q)} wi(i=q)?,以補償去除分量 w q w_q wq?帶來的擾動,重復直到裁剪到目標大小。分步裁剪時, Δ w \Delta_w Δw?中每次僅有一個元素非0。
對于量化則是依次量化影響最小的參數,并修正其它參數,直到所有參數完成量化。
如何找到剪枝影響最小的參數?
什么是剪枝?剪枝就是將某個參數置0,也就是參數增量是它的相反數,即 δ w q + w q = 0 \delta_{w_q}+w_q=0 δwq??+wq?=0,這里 q q q表示 w w w的第 q q q維元素。
怎么找到影響最小的 q q q?這屬于約束極值問題,就是在 δ w q + w q = 0 \delta_{w_q}+w_q=0 δwq??+wq?=0的約束下,求 L \mathcal L L的極小值。更一般地,令 e q e_q eq?表示除 q q q維為1,其他維均為0的列向量,則 δ w q = e q ? δ w \delta_{w_q}=e_q^\top \delta_w δwq??=eq??δw?。
現在問題的約束變為 e q ? δ w + w q = 0 e_q^\top \delta_w+w_q=0 eq??δw?+wq?=0,引入拉格朗日乘子將約束優化問題轉為無約束優化:
L = 1 2 δ w ? H δ w + λ ( e q ? δ w + w q ) \mathcal L=\frac{1}{2}\delta_w^\top H\delta_w + \lambda(e_q^\top \delta_w+w_q) L=21?δw??Hδw?+λ(eq??δw?+wq?)
L \mathcal L L在極小值 δ w \delta_w δw?處的一階導為0,可得 δ w = ? λ H ? 1 e q \delta_w=-\lambda H^{-1}e_q δw?=?λH?1eq?。由于 e q e_q eq?是僅在維度 q q q為1的單位向量,帶入約束可得
w q = λ e q ? H ? 1 e q , λ = w q H q q ? 1 ? δ w = ? w q H q q ? 1 H ? 1 e q w_q=\lambda e_q^\top H^{-1}e_q,\quad \lambda=\frac{w_q}{H_{qq}^{-1}} \implies \delta_w=-\frac{w_q}{H_{qq}^{-1}}H^{-1}e_q wq?=λeq??H?1eq?,λ=Hqq?1?wq???δw?=?Hqq?1?wq??H?1eq?
因此,剪枝損失可表示為
L = 1 2 δ w ? H δ w = 1 2 ( ? w q H q q ? 1 H ? 1 e q ) ? H ( ? w q H q q ? 1 H ? 1 e q ) = 1 2 w q 2 ( H q q ? 1 ) 2 e q ? ( H ? 1 ) ? H H ? 1 e q = 1 2 w q 2 H q q ? 1 \begin{align*} \mathcal L &=\frac{1}{2}\delta_w^\top H\delta_w\\ &=\frac{1}{2}\Big(-\frac{w_q}{H_{qq}^{-1}}H^{-1}e_q\Big)^\top H\Big(-\frac{w_q}{H_{qq}^{-1}}H^{-1}e_q\Big)\\ &=\frac{1}{2}\frac{w_q^2}{(H_{qq}^{-1})^2}e_q^\top (H^{-1})^\top HH^{-1}e_q\\ &=\frac{1}{2}\frac{w_q^2}{H_{qq}^{-1}} \end{align*} L?=21?δw??Hδw?=21?(?Hqq?1?wq??H?1eq?)?H(?Hqq?1?wq??H?1eq?)=21?(Hqq?1?)2wq2??eq??(H?1)?HH?1eq?=21?Hqq?1?wq2???
更一般地,第 q q q維參數的量化損失為
L = ( quant ( w q ) ? w q ) 2 2 H q q ? 1 L=\frac{(\text{quant}(w_q)-w_q)^2}{2H_{qq}^{-1}} L=2Hqq?1?(quant(wq?)?wq?)2?
直觀意義就是,每一項損失的增量大致與“該項平方除以Hessian逆矩陣對應位置對角線元素”相關。也就是說, H q q ? 1 H_{qq}^{-1} Hqq?1?越大, q q q維能容忍的變化越大,對損失的影響小,更適合量化/裁剪。
如何修正其它參數?
OBS在裁剪 q q q維元素后,同步地調整其它參數使裁剪后增加損失最小(損失補償),第 i i i個非裁剪參數的調整幅度為
δ w i = ? w q ( H ? 1 ) q q ( H ? 1 ) i q \delta_{w_i} = -\frac{w_q}{(H^{-1})_{qq}} (H^{-1})_{iq} δwi??=?(H?1)qq?wq??(H?1)iq?
總結

OBS沒有一次性對所有參數進行裁剪,而是逐步調整,逐步裁剪影響最小參數,并修正其它參數。
OBS需要計算 H ? 1 H^{-1} H?1,時間復雜度是 O ( d 3 ) O(d^3) O(d3),分步裁剪/量化每一維,復雜度是 O ( d ) O(d) O(d),總時間復雜度是 O ( d 4 ) O(d^4) O(d4)。
對于參數矩陣W,這里的維度d應該是行數?列數。
OBQ(Optimal Brain Quantization)
將OBS應用到模型量化,逐行量化、遞歸求解 H ? 1 H^{-1} H?1,降低OBS時間復雜度。
每行單獨計算剪枝順序,再綜合所有行確定最終裁剪行列。OBS算法每剪枝一個權重,需要重新計算 H ? 1 H^{-1} H?1,OBQ提出遞歸式求解法(行列消除法),時間復雜度為 O ( d col 2 ) O(d_\text{col}^2) O(dcol2?)。
優化1:使用L2重建量化損失
對于線性層權重矩陣 W W W,剪枝/量化的權重矩陣為 W ^ \hat W W^,目標是盡量降低激活的差異:
W ^ = arg?min ? ∣ ∣ W ^ X ? W X ∣ ∣ 2 2 \hat W =\argmin||\hat WX - WX||^2_2 W^=argmin∣∣W^X?WX∣∣22?
X X X使用小批量估計。
采用激活值的平方誤差作為量化損失
L = 1 2 ∣ ∣ W ^ X ? W X ∣ ∣ 2 2 , ? W 2 L = H = 2 X X ? \mathcal L=\frac{1}{2}||\hat W X - WX||_2^2,\quad \nabla_W^2 \mathcal L=H=2XX^\top L=21?∣∣W^X?WX∣∣22?,?W2?L=H=2XX?
采用分行量化時,每一行權重 W i W_i Wi?獨立量化,Hessian(線性層的平方損失對權重的二階導數)近似為塊對角矩陣,每個塊 H i H_i Hi?對應與第 i i i行權重的Hessian,即 H i = 2 X X ? H_i=2XX^\top Hi?=2XX?,大小為 d col × d col d_\text{col}\times d_\text{col} dcol?×dcol?。

對于線性層網絡,每行參數的輸入相同,初始Hessian相同。
優化2:行并行與遞歸求解 H ? 1 H^{-1} H?1
每行獨立量化,每次貪婪地選擇最小損失參數 w q w_q wq?去量化,并使用 δ F \delta_F δF?修正未量化的參數:
w q = argmin w q ( quant ( w q ) ? w q ) 2 [ H F ? 1 ] q q , δ F = ? w q ? quant ( w q ) [ H F ? 1 ] q q ? ( H F ? 1 ) : , q . (2) w_q = \text{argmin}_{w_q} \frac{(\text{quant}(w_q) - w_q)^2}{[\mathbf{H}_F^{-1}]_{qq}}, \quad \delta_F = -\frac{w_q - \text{quant}(w_q)}{[\mathbf{H}_F^{-1}]_{qq}} \cdot (\mathbf{H}_F^{-1})_{:,q}. \tag{2} wq?=argminwq??[HF?1?]qq?(quant(wq?)?wq?)2?,δF?=?[HF?1?]qq?wq??quant(wq?)??(HF?1?):,q?.(2)
使用上面兩個公式迭代量化所有參數。為避免重新計算 H ? 1 \mathbf H^{-1} H?1,通過以下公式更新Hessian:
H ? q ? 1 = ( H ? 1 ? 1 [ H ? 1 ] q q H : , q ? 1 H q , : ? 1 ) ? p (3) \mathbf{H}_{-q}^{-1} = \left( \mathbf{H}^{-1} - \frac{1}{[\mathbf{H}^{-1}]_{qq}} \mathbf{H}_{:,q}^{-1} \mathbf{H}_{q,:}^{-1} \right)_{-p} \tag{3} H?q?1?=(H?1?[H?1]qq?1?H:,q?1?Hq,:?1?)?p?(3)
對于 d row × d col d_\text{row}\times d_\text{col} drow?×dcol?的參數矩陣,OBQ的時間復雜度為 O ( d row ? d col 3 ) O(d_\text{row}\cdot d_\text{col}^3) O(drow??dcol3?)。
算法實現
裁剪過程
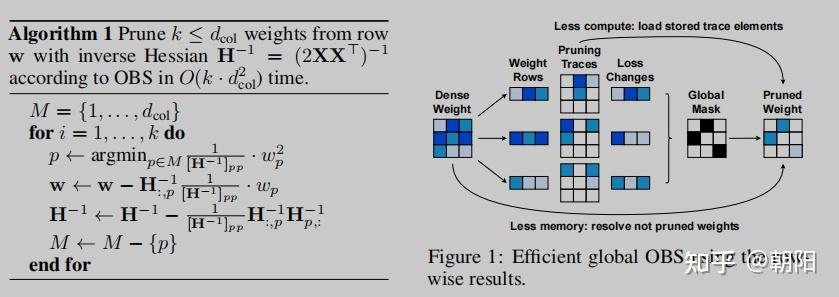
裁剪與量化的轉換
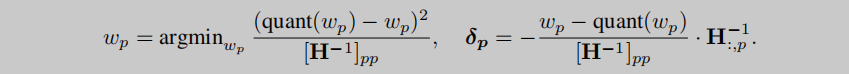
量化過程

GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
步驟1: 任意順序量化(Arbitrary Order Insight)
OBQ貪婪地嚴格選擇當前產生最小量化誤差的參數進行量化,對于參數量大的網絡層,這種嚴格選擇順序的量化結果相比于按隨機順序量化結果差異不大。 原因可能是產生較大誤差的參數始終留在最后,這時已沒有多少參數可以參與補償,也就是說,量化順序對最終效果的影響有限。
GPTQ對所有行都按從左到右的順序量化,所有行的 H F ? 1 \mathbf H_F^{-1} HF?1?僅與輸入有關,始終一致,整個量化過程中只需要按照公式 2 2 2更新 d col d_\text{col} dcol?次。如果不同行按不同順序,則需要更新 d row ? d col d_\text{row}\cdot d_\text{col} drow??dcol?次。
步驟2: 批量量化(Lazy Batch-Updates)
OBQ算法每一步都需要按公式 3 3 3更新 H ? 1 \mathbf H^{-1} H?1中的所有參數,受內存帶寬影響很大,計算/訪存比很低,未有效利用GPU的并行計算能力。
列 i i i的量化與左側已量化的列無關,僅需考慮右側列。GPTQ每次量化權重矩陣相鄰的128列,這與單列量化在計算結果上無差異,但可以充分利用GPU算力,提高計算/訪存比。
使用以下公式更新參數:
δ F = ? ( w Q ? quant ? ( w Q ) ) ( [ H F ? 1 ] Q Q ) ? 1 ( H F ? 1 ) : , Q (4) \boldsymbol{\delta}_F =-(\mathbf{w}_Q-\operatorname{quant}(\mathbf{w}_Q))([\mathbf{H}_F^{-1}]_{QQ})^{-1}(\mathbf{H}_F^{-1})_{:, Q} \tag{4} δF?=?(wQ??quant(wQ?))([HF?1?]QQ?)?1(HF?1?):,Q?(4)
使用以下公式更新 H ? 1 \mathbf H^{-1} H?1:
H ? Q ? 1 = ( H ? 1 ? H : , Q ? 1 ( [ H ? 1 ] Q Q ) ? 1 H Q , : ? 1 ) ? Q (5) \mathbf{H}_{-Q}^{-1} =\left(\mathbf{H}^{-1}-\mathbf{H}_{:, Q}^{-1}([\mathbf{H}^{-1}]_{Q Q})^{-1} \mathbf{H}_{Q,:}^{-1}\right)_{-Q}\tag{5} H?Q?1?=(H?1?H:,Q?1?([H?1]QQ?)?1HQ,:?1?)?Q?(5)
步驟3: Cholesky矩陣分解(Cholesky Reformulation)
當模型參數規模在數十億以上時, H F ? 1 \mathbf H_F^{-1} HF?1?非正定,使用block策略量化參數時,可能會因為重復利用公式 5 5 5,求逆會產生累積誤差,導致未量化參數的更新方向不正確。
對于小模型,常在 H \mathbf H H的對角元素上加入大約特征均值1%的噪聲,以解決數值不穩定的問題。
推理過程略,大致思想就是 δ F \delta_F δF?和 H ? 1 H^{-1} H?1的更新都可以用 L \mathcal L L表示,每次迭代把 H ? 1 H^{-1} H?1的變化累加到 L \mathcal L L,通過 L L L去更新參數。
算法過程

AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
AWQ認為每個權重的重要性不一樣,僅保護大約1%的重要性參數能顯著降低量化誤差。AWQ遵循激活感知原則,通過觀察激活值判斷權重的重要性(大的激活值對應重要的權重),搜索最優的per-channel縮放因子,以最小化量化誤差。
AWQ不需要后向傳播和重構模型,不會在校準集上過擬合,能夠保留模型不同模態、不同領域的泛化性。僅量化所有權重參數,能夠利用硬件加速。
GPTQ使用二階導數信息補償量化誤差,但對部分模型(如LLaMA-7B)需要開啟重排序(硬件利用率低2x)。GPTQ利用校準集重構模型,可能會出現過擬合,從而丟失泛化性,特別對于多模態模型。AWQ是reorder-free算法,開發的在線反量化tensor core,比GPTQ快1.45x,比cuBLAS FP16快1.85x。
保留1%重要性參數可提升量化性能
相比絕對大多參數,有小部分參數非常影響模型的性能。如果不量化這部分參數,有助于緩解量化其他參數帶來的誤差。
如下表所示,基于激活值、權重參數和隨機性選擇不同比例的重要性參數保留為FP16精度,其他參數量化為INT3,觀測對PPL的影響。
對于超過6.7B的模型,保留通過激活值選擇的0.1%的重要性參數就可以獲得較好的性能;根據權重數值選擇重要性參數與隨機選擇差不多。雖然僅保留少部分重要性權重為FP16就可以獲得較好的量化性能,但是混合精度實現比較復雜。
根據權重數值或者L2-Norm判斷權重的重要性可能不準確!
激活感知縮放保護重要權重
對重要性權重執行per-channel縮放。
啟發式縮放
minmax量化方法(非對稱量化),在最大最小值處無量化損失。因此可見,保護離群權重通道比較直接的方式就是直接放大這些權重通道的縮放系數,但這與直接保留1%的FP16權重相比,還是存在差異。隨著縮放系數的增加,量化效果不斷變好,但大到一定尺度,其他參數能利用的量化點位過少,性能開始下降。因此,需要找到能降低重要性權重的量化誤差,而又不增加其他參數的量化誤差的方法。
搜索縮放
s ? = arg ? min ? s L ( s ) , L ( s ) = ∥ Q ( W ? s ) ( s ? 1 ? X ) ? W X ∥ \mathbf{s}^*=\underset{\mathbf{s}}{\arg \min } \mathcal{L}(\mathbf{s}), \quad \mathcal{L}(\mathbf{s})=\left\|Q(\mathbf{W} \cdot \mathbf{s})\left(\mathbf{s}^{-\mathbf{1}} \cdot \mathbf{X}\right)-\mathbf{W} \mathbf{X}\right\| s?=sargmin?L(s),L(s)= ?Q(W?s)(s?1?X)?WX ?
式中, Q Q Q表示組大小為128的INT3/INT4量化函數, X \mathbf X X表示小校準集的輸入特征, s \mathbf s s是per-in-channel的量化縮放因子。 Q Q Q不可微,現有一些近似梯度的方法,但收斂較差,還存在過擬合風險。
通過分析影響縮放因子選擇的因素來設計搜索空間,直覺上來說,最優縮放因子的關聯因素有:
- 激活尺度: 之前已驗證激活尺度與參數的重要性相關,首先計算將激活尺度的均值作為重要性因子,即 s x = mean c _ o u t ∣ X ∣ \mathbf s_{\mathbf x}=\text{mean}_{c\_out}|\mathbf X| sx?=meanc_out?∣X∣。
- 權重尺度: 為降低非重要性權重的量化損失,應當使這些通道的分布扁平化,從而更容易量化。自覺的做法就是將這些通道各自除以其均值,即 s w = mean c _ o u t ∣ W ^ ∣ \mathbf s_{\mathbf w}=\text{mean}_{c\_out}|\hat{\mathbf W}| sw?=meanc_out?∣W^∣,其中 W ^ \hat{\mathbf W} W^是指每組內歸一化的 W \mathbf W W。
最終考慮這兩個尺度的縮放因子表示為
s = f ( s X , s W ) = s X α ? s W ? β , α ? , β ? = arg ? min ? α , β L ( s X α ? s W ? β ) \mathbf s=f(\mathbf s_{\mathbf X}, \mathbf s_{\mathbf W})=\mathbf s_{\mathbf X}^{\alpha} \cdot \mathbf s_{\mathbf W}^{-\beta}, \quad \alpha^{*},\beta^{*}=\underset{\alpha,\beta}{\arg\min}\mathcal L(\mathbf s_{\mathbf X}^{\alpha} \cdot \mathbf s_{\mathbf W}^{-\beta}) s=f(sX?,sW?)=sXα??sW?β?,α?,β?=α,βargmin?L(sXα??sW?β?)
α , β \alpha,\beta α,β是位于 [ 0 , 1 ] [0, 1] [0,1]之間的超參數,可通過網格搜索獲得。 s X \mathbf s_{\mathbf X} sX?的重要性遠超 s W \mathbf s_{\mathbf W} sW?, s W \mathbf s_{\mathbf W} sW?的提升有限。
通過搜索收縮率(表示為“+clip”)來調整裁剪范圍有時也能進一步提升量化性能,調整裁剪范圍可以輕微移動縮放因子,這可能有助于保護重要性權重。



)
的介紹和使用)
)

)



(含模型、代碼、數據))
)






