文章目錄
- 一、引言
- 二、熱點查詢定義與場景
- 三、主從復制——垂直擴容
- 四、應用內前置緩存
- 4.1 容量上限與淘汰策略
- 4.2 延遲刷新:定期 vs. 實時
- 4.3 逃逸流量控制
- 4.4 熱點發現:被動 vs. 主動
- 五、降級與限流兜底
- 六、前端/接入層其他應對
- 七、模擬壓測Code
- 八、總結

一、引言
在前面的幾篇博客中,
架構思維:使用懶加載架構實現高性能讀服務
架構思維:利用全量緩存架構構建毫秒級的讀服務
架構思維:異構數據的同步一致性方案
我們依賴全量緩存與 Binlog 同步,實現了零毛刺、百毫秒級延遲的讀服務,且分布式部署后輕松承載百萬 QPS。但這里的“百萬”是指 百萬不同用戶 的并發請求。
百萬請求屬于不同用戶的架構圖
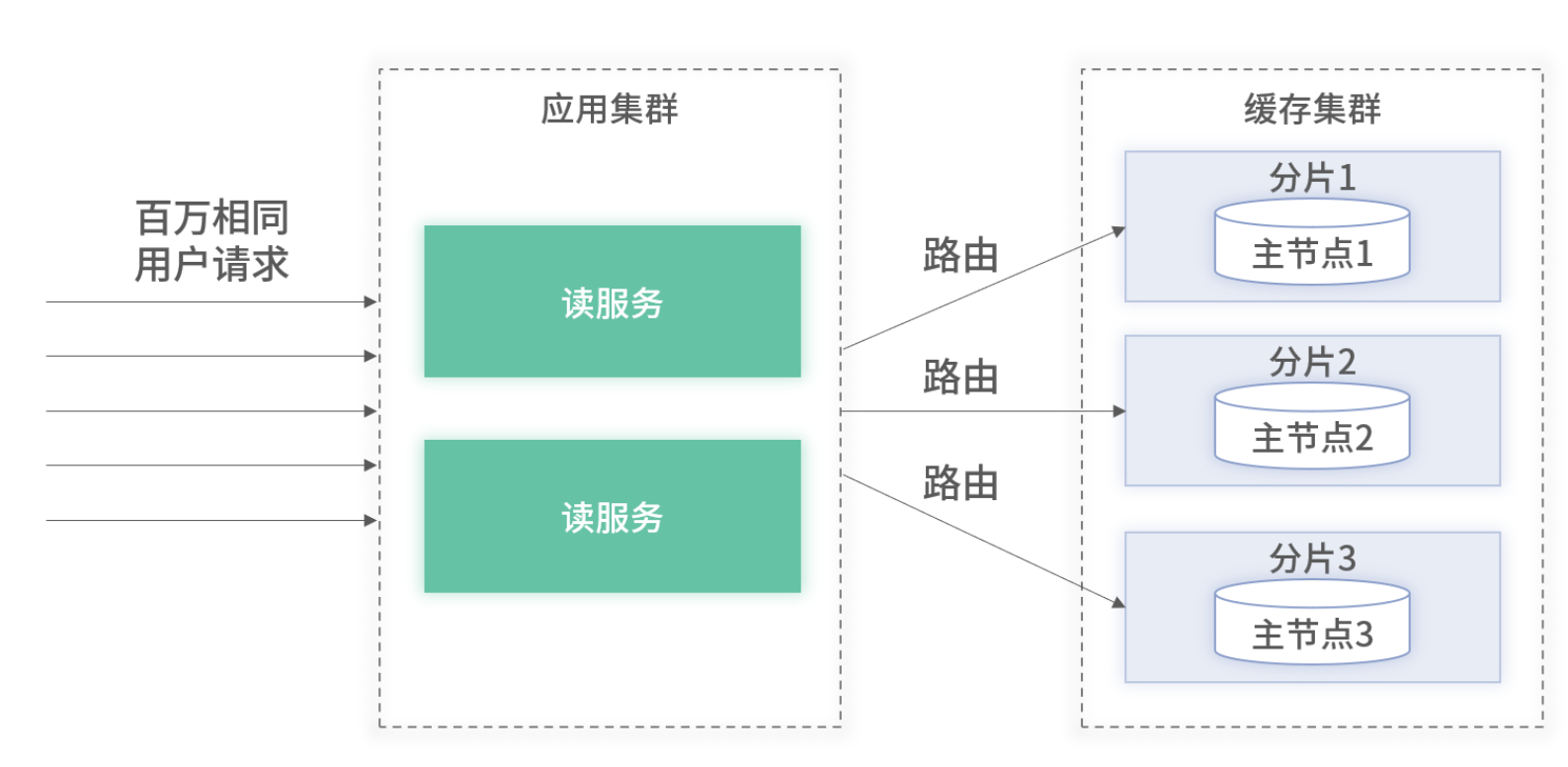
假設一個節點最大能夠支撐 10W QPS,我們只需要在集群中部署 10 臺節點即可支持百萬流量。
當這百萬請求都集中到同一用戶時(即同一鍵熱點查詢),傳統集群方案將不堪重負——單節點路由所有流量,硬件和程序性能都無法無限擴容。
當百萬 QPS 都屬于同一用戶時,即使緩存是集群化的,同一個用戶的請求都會被路由至集群中的某一個節點
百萬請求屬于相同用戶的架構圖
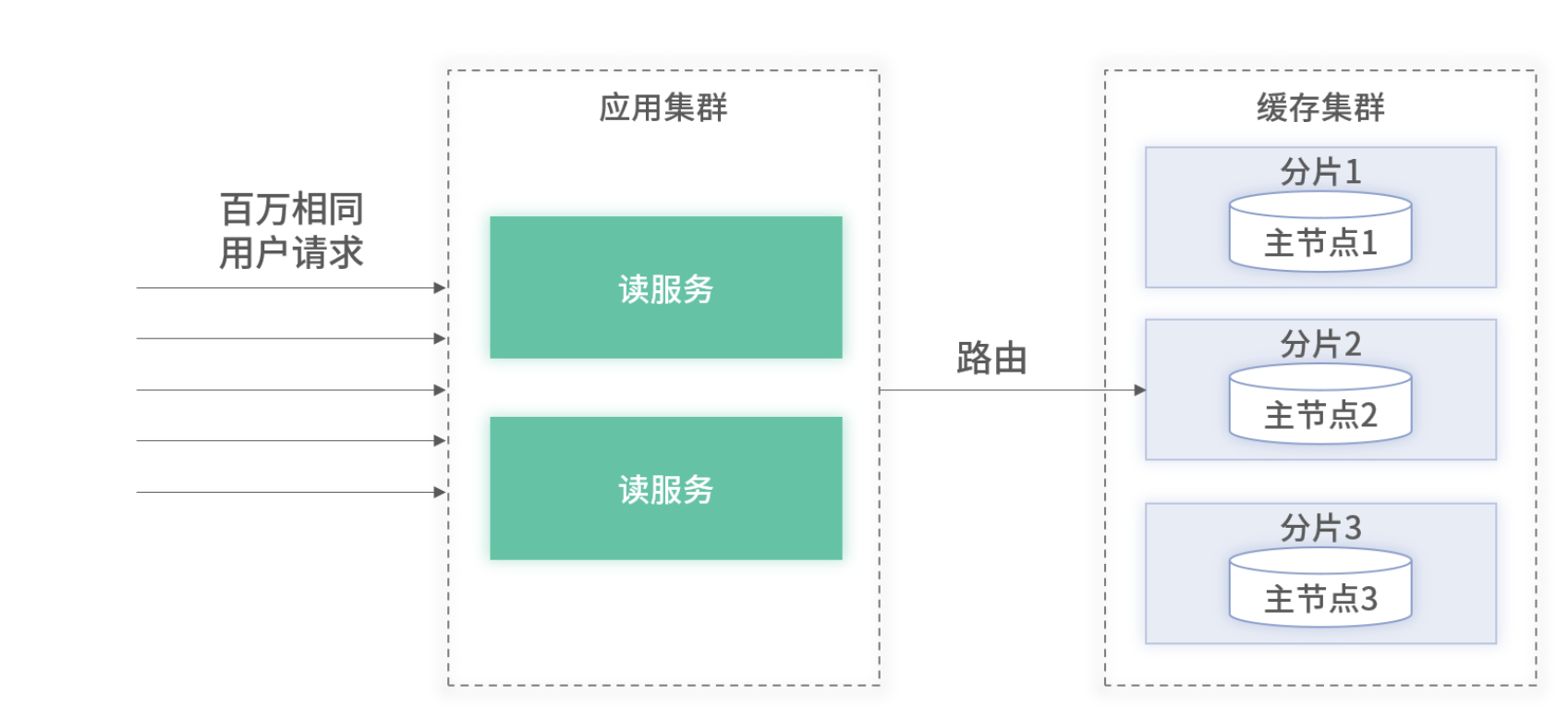
即使此節點的機器配置非常好,當前能夠支持住百萬 QPS。但隨著流量上漲,它也無法滿足未來的流量訴求。原因有 2 點:
-
單臺機器無法無限升級;
-
緩存程序本身也是有性能上限的。
這里我們講將聚焦**單用戶百萬并發(熱點查詢)**場景,剖析架構瓶頸并給出多層次應對策略。
二、熱點查詢定義與場景
熱點查詢:對同一數據項發生極高頻率的重復讀取。
典型場景:
- 社交媒體熱點內容(某條微博、熱搜話題)。
- 電商秒殺商品詳情持續刷新。
- 網站排行榜頁/直播間房間信息。
這些場景下,同一個 Key 的請求會被路由到同一緩存分片或服務實例,導致“集中過載”。
三、主從復制——垂直擴容
主從復制應對熱點的架構圖
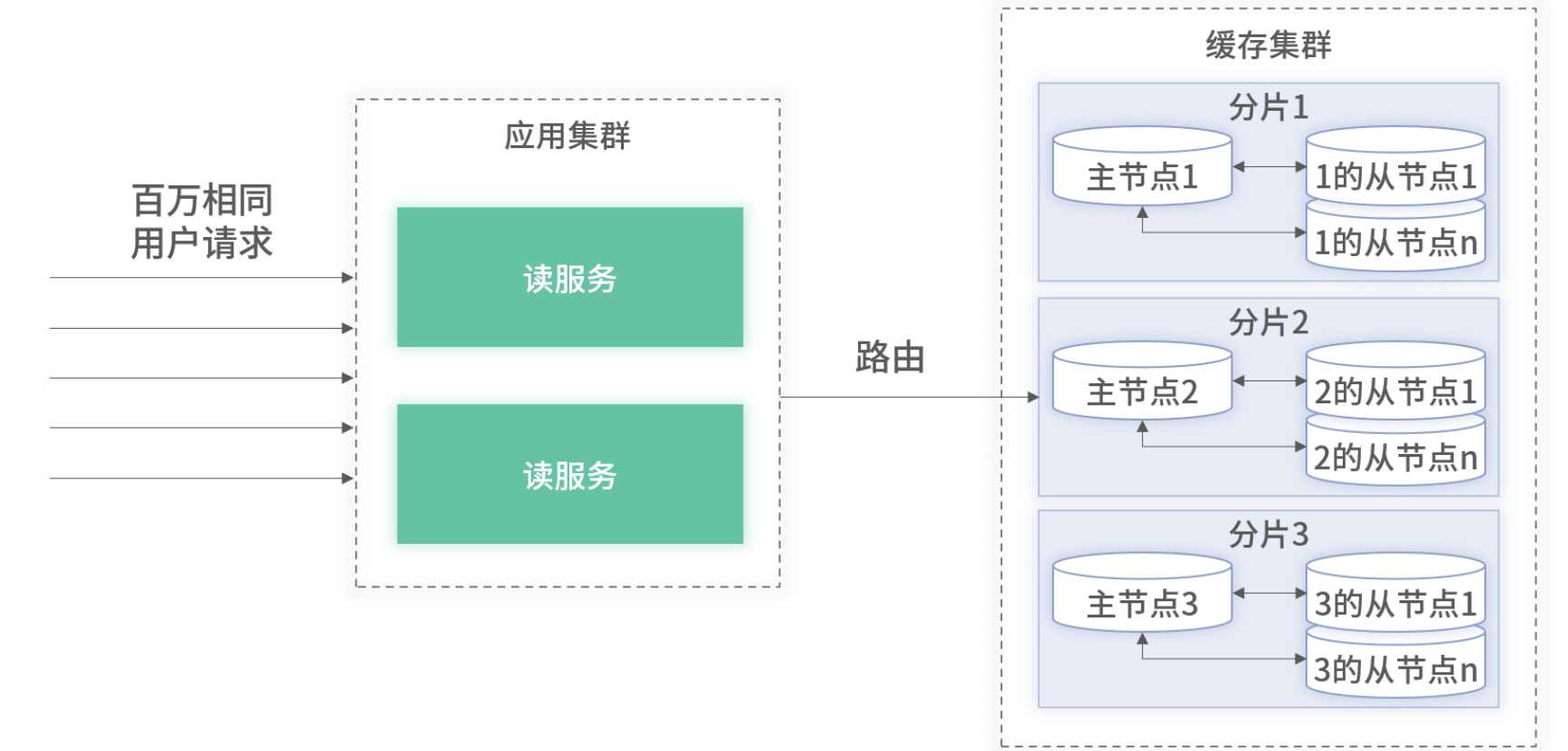
思路:利用緩存的主從復制機制,開啟 隨機讀 策略,讓同一 Key 的并發請求分散到主+多個從節點。
在查詢時,將應用內的緩存客戶端開啟主從隨機讀。此時,包含一個從的分片的并發能力,可以提升至原來的一倍。隨著從節點的增加,單分片的并發性能會不斷翻倍。這對于所有請求只會命中某一個固定單分片的熱點查詢能夠很好地應對。
但此方案存在一個較大的問題,就是浪費資源。
主從復制除了有應對熱點的功能,另外一個主要作用是為了高可用。當集群中的某一個主節點發生故障后,集群高可用模塊會自動對該節點進行故障遷移,從該節點所屬分片里選舉一個從節點為主節點。為了高可用模塊在故障轉移時的邏輯能夠簡單清晰并做到統一,會將集群的從節點數量設置為相同數量。
相同從節點數量也帶來了較大的資源浪費。為了應對熱點查詢,需要不斷擴容從分片。但熱點查詢只會命中其中一個分片,這就導致所有其他分片的從節點全部浪費了。為了節約資源,可以對高可用模塊進行改造,不強制所有分片的從節點必須相同,但這個代價也是非常高昂的。另外,熱點查詢很多時候是隨時出現的,并不能提前預測,所以提前擴容某一個分片意義并不大。
- 優點:實現簡單,只需客戶端配置;
- 擴展:每加一個從節點,分片吞吐線性提升;
- 缺點:資源浪費——為熱點單一分片預留大量從節點,而其他分片則閑置;
- 改造:可自定義高可用中間件配置,按需增減分片,從而降低浪費。
總的來說,主從復制能夠解決一定流量的熱點查詢且實施起來較簡單。但不具備擴展性,在應對更大流量的熱點時會有些吃力。
四、應用內前置緩存
熱點查詢特點:請求次數多、數據項少。可在業務應用進程內維護一份本地緩存,徹底分散熱流量。
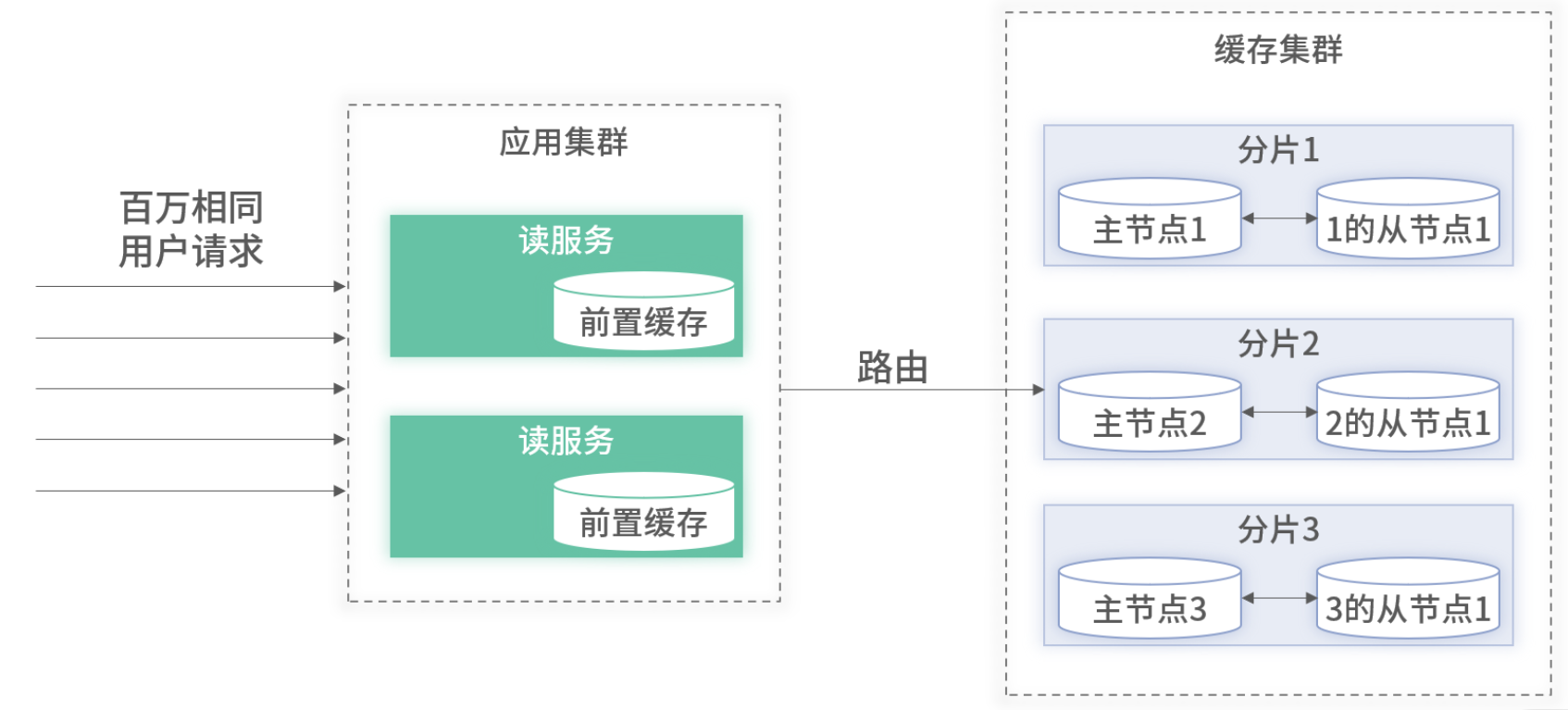
4.1 容量上限與淘汰策略
- 設置緩存上限,采用 LRU 淘汰最少訪問條目;
- 配合 TTL,過期未訪問的數據自動釋放。
4.2 延遲刷新:定期 vs. 實時
- 定期刷新:設置過期時間后,按周期批量更新,簡單高效;
- 實時刷新:借助異構判斷層+MQ,主動推送變更,僅針對熱點更新,需額外組件支持。
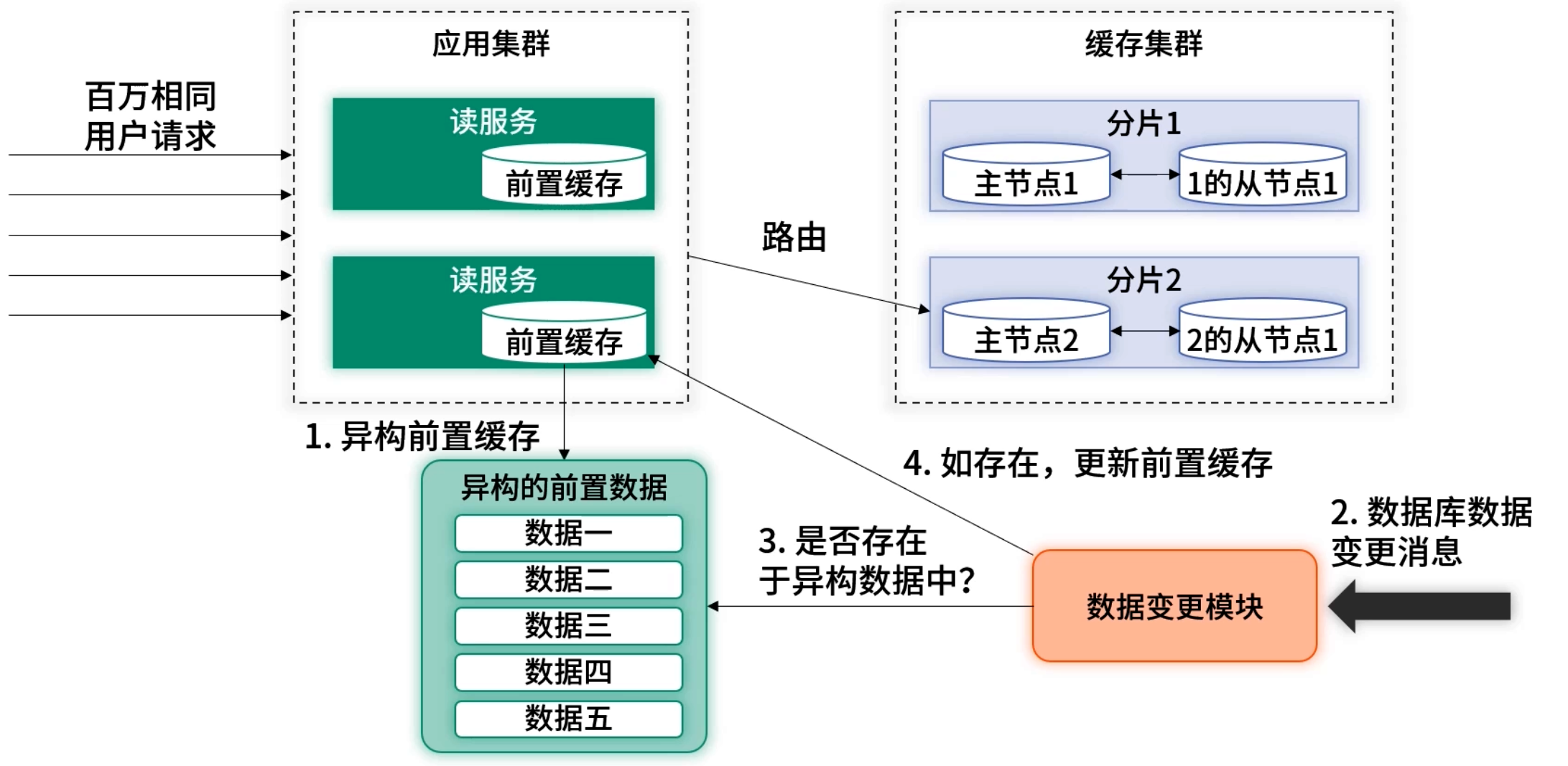
4.3 逃逸流量控制
再者要把控好瞬間的逃逸流量
應用初始化時,前置緩存是空的。假設在初始化時,瞬間出現熱點查詢,所有的熱點請求都會逃逸到后端緩存里。可能這個瞬間熱點就會把后端緩存打掛。
其次,如果前置緩存采用定期過期,在過期時若將數據清理掉,那么所有的請求都會逃逸至后端加載最新的緩存,也有可能把后端緩存打掛。這兩種情況對應的流程圖如下圖所示:
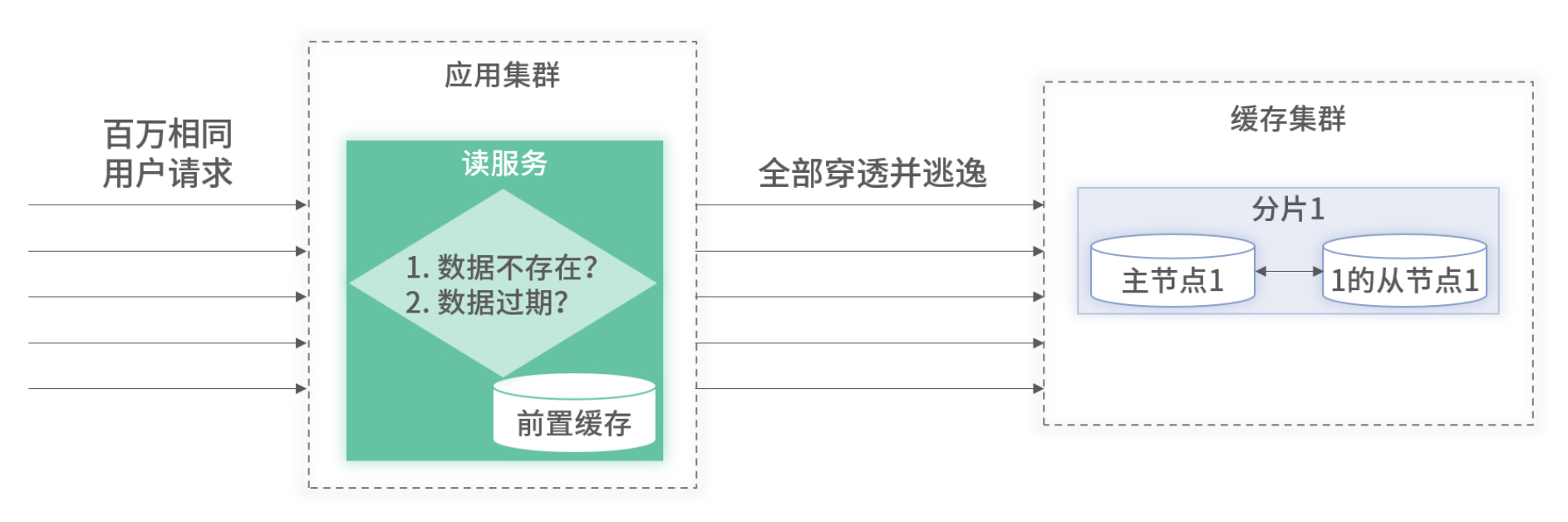
對于這兩種情況,可以對逃逸流量進行前置等待或使用歷史數據的方案。不管是初始化還是數據過期,在從后端加載數據時,只允許一個請求逃逸。這樣最大的逃逸流量為部署的應用總數,量級可控。架構如下圖 所示

- 初始化或過期瞬間,只允許 1 個 請求穿透后端加載并更新本地緩存;
- 其他并發請求 等待(帶超時)或 返回歷史臟數據,防止短時洪峰打掛后端。
4.4 熱點發現:被動 vs. 主動
除了需要應對熱點緩存,另外一個重點就是如何發現熱點緩存。對于發現熱點有兩個方式,一種是被動發現,另外一種是主動發現。
-
被動:憑借本地緩存容量和 LRU 策略,自然淘汰非熱點,熱點常駐;
被動發現是借助前置緩存有容量上限實現的。在被動發現的方案里,讀服務接受到的所有請求都會默認從前置緩存中獲取數據,如不存在,則從緩存服務器進行加載。因為前置緩存的容量淘汰策略是 LRU,如果數據是熱點,它的訪問次數一定非常高,因此它一定會在前置緩存中。借助前置緩存的容量上限和淘汰策略,即實現了熱點發現。
但此方式也存在一個問題——所有的請求都優先從前置緩存獲取數據,并在未查詢到時加載服務端數據到本地的前置緩存里,此方式也會把非熱點數據存儲至前置緩存里,導致非熱點數據產生非必要的延遲性。
-
主動:在緩存層或接入層統計訪問頻次,超過閾值后 推送 到本地緩存,避免誤入冷數據。
主動發現則需要借助一些外部計數工具來實現熱點的發現。外部計數工具的思路大體比較類似,都是在一個集中的位置對于請求進行計數,并根據配置的閾值判斷某請求是否會命中數據。對于判定為熱點的數據,主動的推送至應用內的前置緩存即可。
下圖為在緩存服務器進行計數的架構方案:
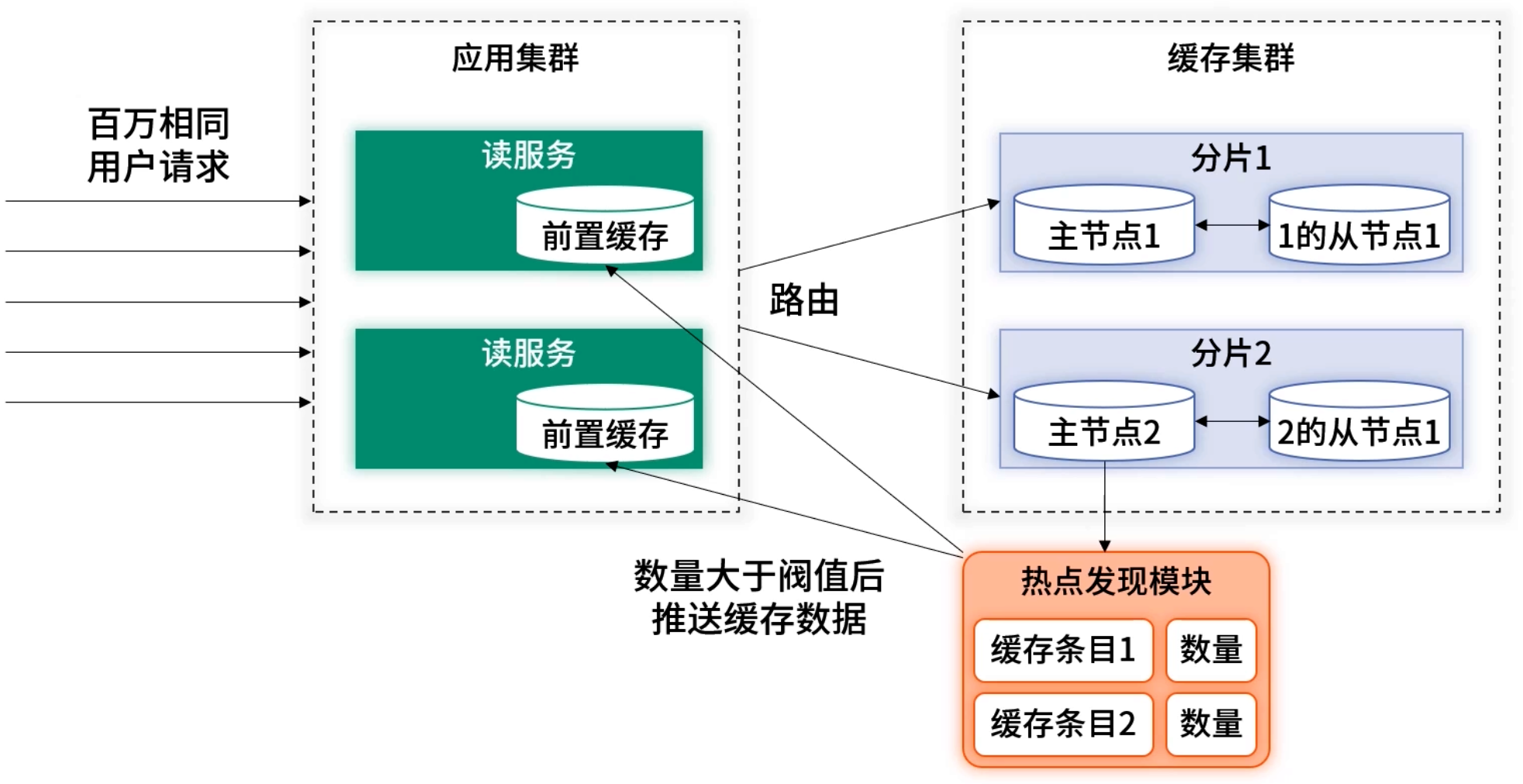
采用主動發現的架構后,讀服務接受到請求后仍然會默認的從前置緩存獲取數據,如獲取到即直接返回。如未獲取到,會穿透去查詢后端緩存的數據并直接返回。但穿透獲取到的數據并不會寫入本地前置緩存。數據是否為熱點且是否要寫入前置緩存,均由計數工具來決定。此方案很好地解決了因誤判斷帶來的延遲問題。
五、降級與限流兜底
在采用了前置緩存并解決了上述四大類問題之后,當再次遇到百萬級并發時,基本沒什么疑難問題了。但這里還存在一個前置條件,即當熱點查詢發生時,你所部署的容器數量所能支撐的 QPS 要大于熱點查詢的 QPS。
但實際情況并非如此,所部署的機器能夠支持的 QPS 未必都能夠大于當次的熱點查詢。對于可能出現的超預期流量,可以使用前置限流的策略進行應對。在系統上線前,對于開啟了前置緩存的應用進行壓測,得到單機最大的 QPS。根據壓測值設置單機的限流閾值,閾值可以設置為壓測值的一半或者更低。設置為壓測閾值的一半或更低,是因為壓測時應用 CPU 基本已達到 100%,為了保證線上應用能夠正常運轉,是不能讓 CPU 達到 100% 的
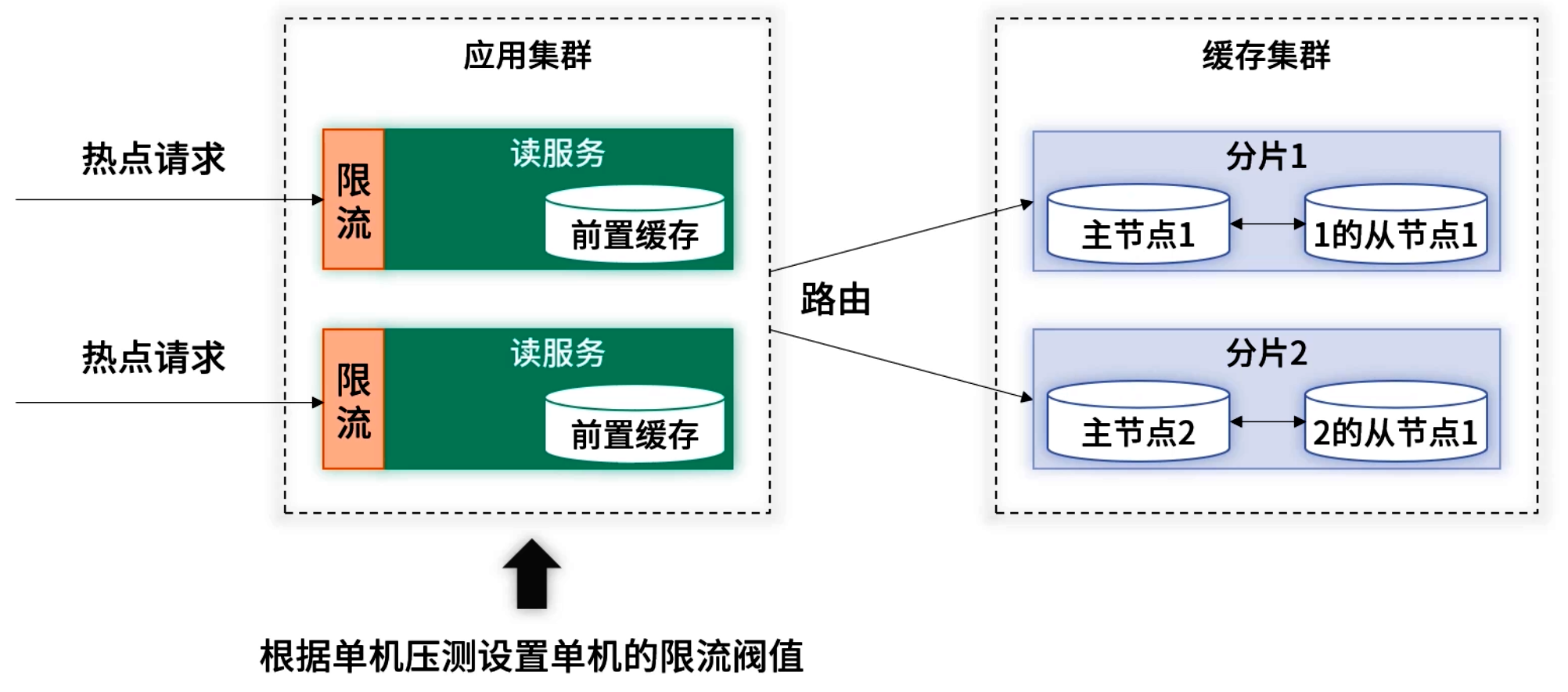
即便前置緩存和后端擴展俱全,也難保偶發超預期洪峰不至于打滿資源。
- 前置限流:根據單機壓測 QPS 設定閾值(如 50% 負載),超過即返回降級策略或失敗;
- 降級內容:可返回緩存的歷史值、靜態頁面或友好提示。
六、前端/接入層其他應對
在網絡邊界亦可做熱點緩解:
- Nginx/接入層緩存:對熱點 Key 做短時緩存;
- CDN/邊緣緩存:將熱點內容推至離用戶更近節點;
- 瀏覽器緩存:HTTP Cache-Control 頭設置合理 TTL。
七、模擬壓測Code
import com.github.benmanes.caffeine.cache.LoadingCache;
import com.github.benmanes.caffeine.cache.Caffeine;import java.util.concurrent.TimeUnit;/*** FrontCacheBenchmark.java* 示例:基于 Java + Caffeine 實現前置緩存的性能對比*/
public class FrontCacheBenchmark {// 模擬后端數據源加載private static String loadFromBackend(String key) {try {// 模擬網絡/數據庫延遲TimeUnit.MILLISECONDS.sleep(10);} catch (InterruptedException e) {Thread.currentThread().interrupt();}return "Value-for-" + key;}public static void main(String[] args) {final int WARM_UP = 1_000;final int TEST_OPS = 100_000;final String HOT_KEY = "hot-item";// 1. 構建 Caffeine LoadingCache,自動加載邏輯LoadingCache<String, String> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(5, TimeUnit.MINUTES).build(FrontCacheBenchmark::loadFromBackend);// 2. 預熱緩存for (int i = 0; i < WARM_UP; i++) {cache.get(HOT_KEY);}// 3. 測試緩存命中性能long startHits = System.nanoTime();for (int i = 0; i < TEST_OPS; i++) {cache.get(HOT_KEY);}long endHits = System.nanoTime();// 4. 測試直接后端加載性能long startMisses = System.nanoTime();for (int i = 0; i < TEST_OPS; i++) {loadFromBackend(HOT_KEY);}long endMisses = System.nanoTime();double avgHitLatencyMs = (endHits - startHits) / 1e6 / TEST_OPS;double avgMissLatencyMs = (endMisses - startMisses) / 1e6 / TEST_OPS;double throughputWithCache = TEST_OPS / ((endHits - startHits) / 1e9);double throughputWithout = TEST_OPS / ((endMisses - startMisses) / 1e9);System.out.println("=== Performance Comparison ===");System.out.printf("Operation | Avg Latency (ms) | Throughput (ops/sec)%n");System.out.printf("----------------+------------------+--------------------%n");System.out.printf("Cache Hit | %8.6f | %10.0f%n", avgHitLatencyMs, throughputWithCache);System.out.printf("Backend Direct | %8.6f | %10.0f%n", avgMissLatencyMs, throughputWithout);}
}八、總結
- 單一用戶百萬 QPS 需額外考慮熱點路由壓力;
- 主從復制 簡單易行但資源浪費;
- 應用內前置緩存 從四大維度(容量、刷新、逃逸、發現)精細打磨;
- 限流降級 是最后的安全閥;
- 前端與接入層也可層層加固。



)
)
)
)
)

概述 QT 的元對象系統里的類的調用與聯系,及訪問接口)




)
 這里串口的2/0 和 3/0分別都是什么?)


算法)

完整講解與實戰應用)