思維導圖:
Redis最主要的用途,三個方面:
1.存儲數據(內存數據庫)
2.緩存(redis最常用的場景)
3.消息隊列
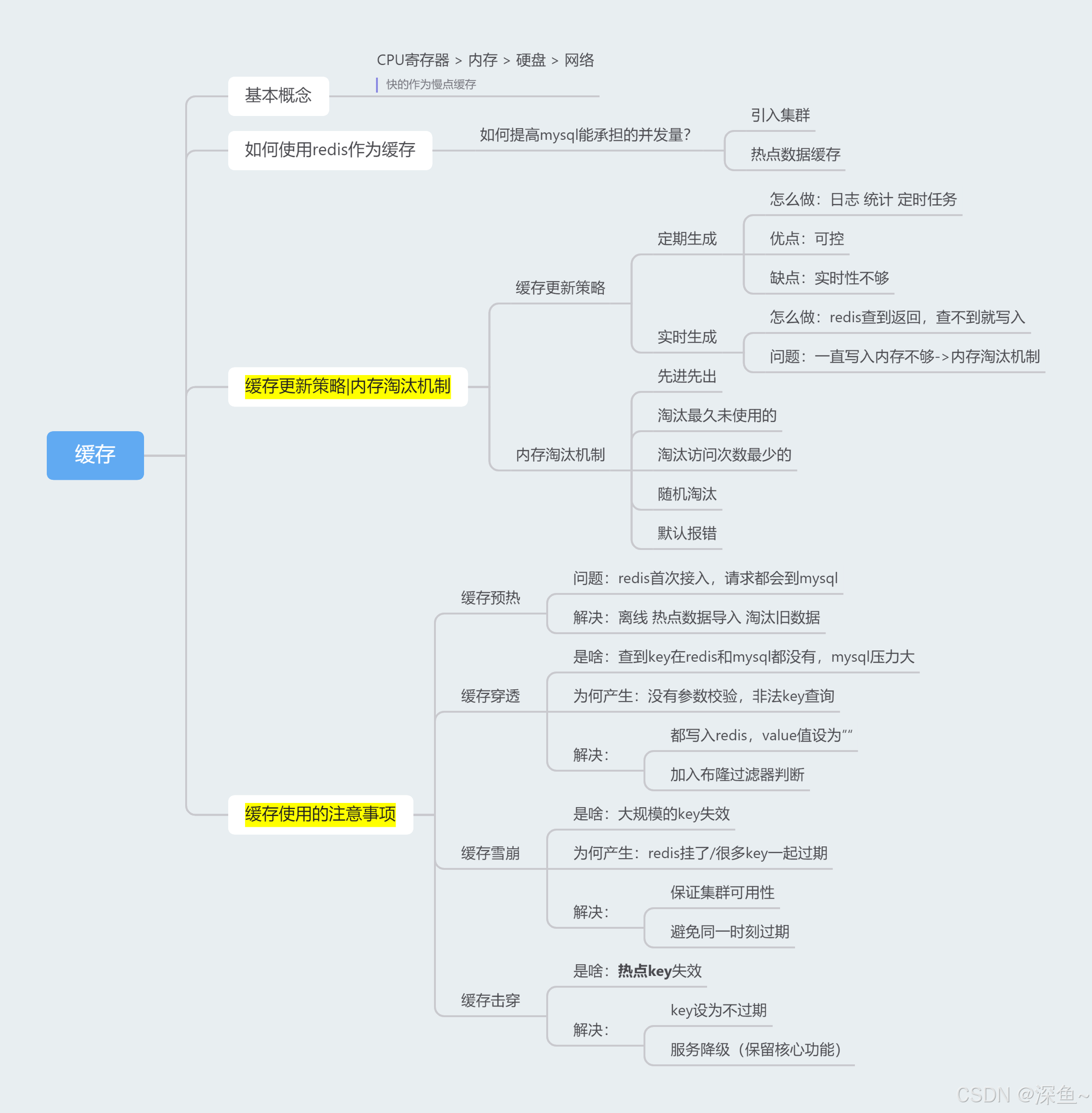
一、什么是緩存
我們知道對于硬件的訪問速度來說,通常情況下:
CPU寄存器 > 內存 > 硬盤?> 網絡
速度快點設備,可以作為速度慢的設備的緩存??
最常見的就是使用 內存 作為 硬盤 的緩存(redis定位)
同樣硬盤也可作為網絡的緩存,比如瀏覽器的緩存,瀏覽器通過http/https從服務器上(網絡)獲取到數據(html,css,圖片,視頻,音頻...)并進行展示,像圖片這種比較大,又不太改變的數據,就可以保存到瀏覽器本地(瀏覽器所在的主機硬盤上),后續打開這個頁面,就不必重新從網絡獲取上述數據了
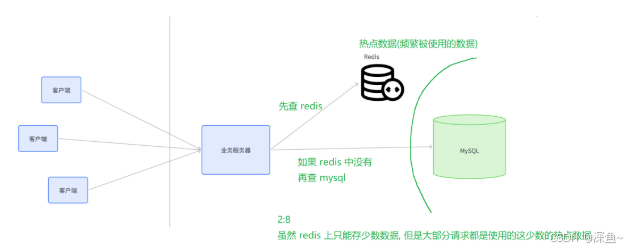
🍞二八定律
20%的數據,可以應對80%的請求
因此只需要把這少量的熱點數據緩存起來,就可以應對?多數場景,從?在整體上有明顯的性能提升
二、使用Redis作為緩存
通常是使用redis作為數據庫的緩存(mysql),因為數據庫是非常重要的組件,并且mysql的速度又比較慢,所以可以使用redis作為mysql的緩存
🍞為什么關系型數據庫性能不高?
(1)數據存儲在硬盤上,硬盤IO速度很慢,尤其是隨機訪問
(2)如果查詢不能命中索引,就需要全表變量
(3)對SQL執行會做一系列的解析,校驗,優化工作
(4)如果是復雜查詢,需要進行笛卡爾積操作,效率更低
1和2屬于硬件,3和4屬于軟件,因為mysql等數據庫,效率比較低,所以承擔的并發量有限,一旦請求多了,數據庫壓力就很大,甚至就容易宕機了(服務器每次處理應一個請求,一定都要消耗一些硬件資源CPU,內存,硬盤這些,任意一種資源的消耗超出了機器能提供的上限,機器就很容易出現故障
如何提高mysql能承擔的并發量?
(1)開源:引入更多的機器,構成數據庫集群
(2)節流:引入緩存,把一些頻繁讀取的熱點數據,保存到緩存上,后續在查詢數據的時候,如果緩存中已經存在,就不用訪問mysql了
三、📚緩存的更新策略
引入:如何知道redis中應該存哪些數據呢/如何知道哪些數據是熱點數據呢
📚緩存的更新策略:
1.定期生成
怎么做:把訪問的數據,以日志的形式記錄下來,此處的數據,就可以根據當前這里統計的維度,來定期更新(比如按照天級別統計,就每天更新一次),寫一套離線的流程(往往使用shell,python寫腳本),可以通過定時任務來觸發
eg:搜索引擎為例子
a)完成統計熱詞的過程
b)根據熱詞,找到搜索結果的數據(廣告數據)
c)把得到的緩存數據同步到緩存服務器上
d)控制這些緩存服務器自動重啟
優點:可控(緩存中有啥比較固定),方便排查問題
缺點:實時性不夠,如果出現突發熱點事件(比如:”春節晚會“這幾天才會搜索),有一些本來不是熱詞的內容,變為了熱詞,新的熱詞就可能給后面的數據庫帶來較大的壓力
2.實時生成
怎么做:
(1)如果在Redis查到了,就直接返回
(2)如果Redis中不存在,就數據庫中查,把查到的結果同時也寫入redis
存在的問題:經過一段時間的動態平衡,redis中的key就逐漸都成了熱點數據,這樣不同的寫redis,就會使redis的內存占用越來越多,逐漸達到內存上限(這個上限可以配置的maxmemory參數設定),此時如果繼續往里面插入數據,就會觸發問題
解決:
📚內存淘汰策略
(1)FIFO(First In First Out)先進先出:把緩存中存在時間最久的(也就是先來的數據)淘汰掉
(2)LRU(Least Recently Used)淘汰最久未使用的:記錄每個key都最近訪問時間,把最近訪問時間最老的key淘汰掉
(3)LFU(Least Frequently Used)淘汰訪問次數最少的:記錄每個key最近一段時間的訪問次數,把訪問次數最少的淘汰掉
(4)Random 隨機淘汰:從所有的 key 中抽取幸運?被隨機淘汰掉
redis中有個配置,就可以設置redis采取上述哪種策略淘汰內存數據,具體采用哪種,結合實際場景來具體問題具體分析
其實還可以細分:針對設置了過期時間的key(設置了過期時間都算,包括過期時間還沒到的)淘汰/在所有key中淘汰【FIFO沒有針對所有key,因為可能對于一些沒有設置過期時間的key,是沒有保存設置時間的】

四、緩存預熱、緩存穿透、緩存雪崩和緩存擊穿
1.緩存預熱(Cache preheating)
問題:緩存中的數據,是定期生成/實時生成的,對于定期生成這種情況是不涉及”預熱“的,而對于實時生成,redis服務器首次接入之后,服務器里面是沒有數據的。此時所有的請求都會打到mysql上
解決:緩存預熱就是來解決上述問題的,把定期生成 和 實時生成結合一下,先通過離線的方式,通過一些統計的途徑,先把熱點數據找到一批,導入到redis中,此時導入的這批熱點數據,就能幫助mysql承擔很大的壓力了,隨著時間的推移,逐漸就使用新的熱點數據淘汰舊的數據
2.📚緩存穿透(Cache penetration)
是啥:
查詢的某個key,在redis中沒有,mysql也沒有,這次查詢沒有,下次查也沒有,如果這樣的數據,存在很多,并且還反復查詢,一樣也會給mysql帶來很大的壓力
為何產生:
(1)業務設計不合理,比如缺少必要的參數校驗環節,導致非法的key也被查詢了【典型】
(2)開發/運維誤操作,不小心把部分數據從數據庫上誤刪了
(3)黑客惡意攻擊
解決:
(1)如果發現這個key,在redis和mysql都不存在,仍然寫入redis,value值設為非法值(比如”“)
(2)引入布隆過濾器,每次查詢redis/mysql之前都先判定一下key是否在布隆過濾器存在(把所有的key都插入到布隆過濾器中)
(3)通過改進業務/加強監控報警
3.📚緩存雪崩(Cache avalanche)
是啥:
由于在短時間內,redis上大規模的key失效,導致緩存命中陡然下降,并且mysql的壓力迅速上升,甚至直接宕機
為何產生:
(1)redis直接掛了(redis宕機/redis集群環境下大量節點宕機)
(2)redis好著,但是可能之前短時間內設置了很多key給redis,并且設置的過期時間是相同的
解決:
(1)加強監控報警,加強redis集群可用性的保證
(2)不給key設置過期時間/設置過期時間的時候添加隨機的因子(避免同一時刻過期)
4.📚緩存擊穿(Cache breakdown)
是啥:相當于緩存血崩的特殊情況,針對熱點key,突然過期了,導致大量的請求直接訪問到數據庫上,甚至引起數據庫宕機【熱點key訪問頻率高,影響更大】
解決:
(1)基于統計的方式發現熱點key,并設置永不過期
(2)服務降級(適當關閉一些不重要的功能,只保留核心功能),比如訪問數據庫的時候使?分布式鎖,限制數據庫的訪問頻率
?








)



:深入掌握 Common Clock Framework 架構與實戰開發)



)
 是衡量排序質量的指標,常用于搜索引擎或推薦系統)

一面)