目錄
1?主要內容
風光出力場景生成方法
2?部分程序
3?程序結果
4 下載鏈接
1?主要內容
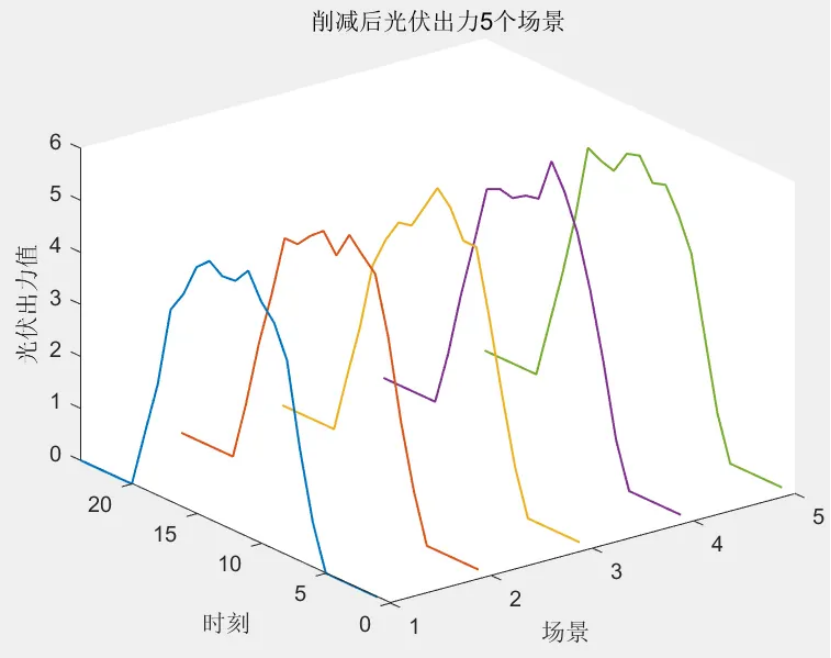
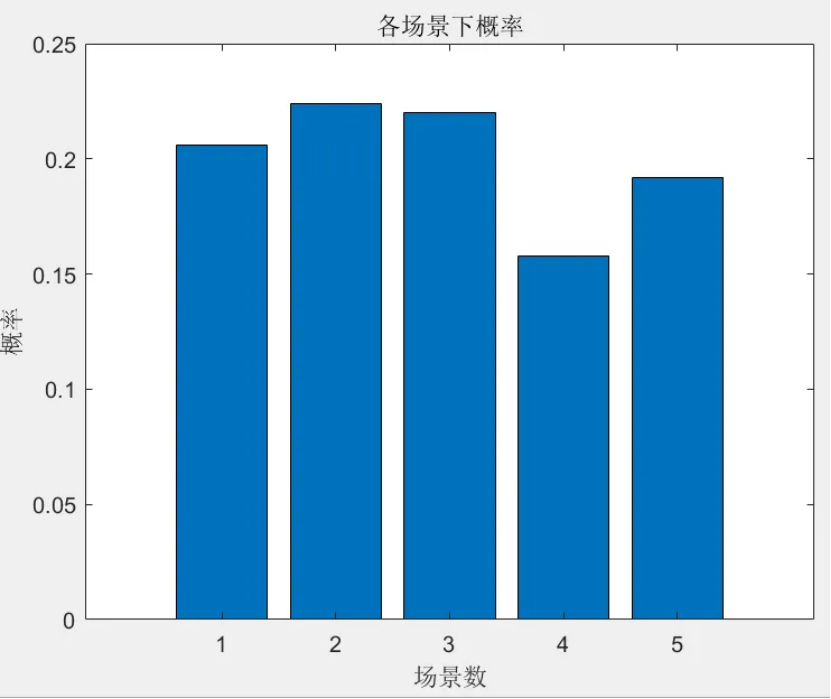
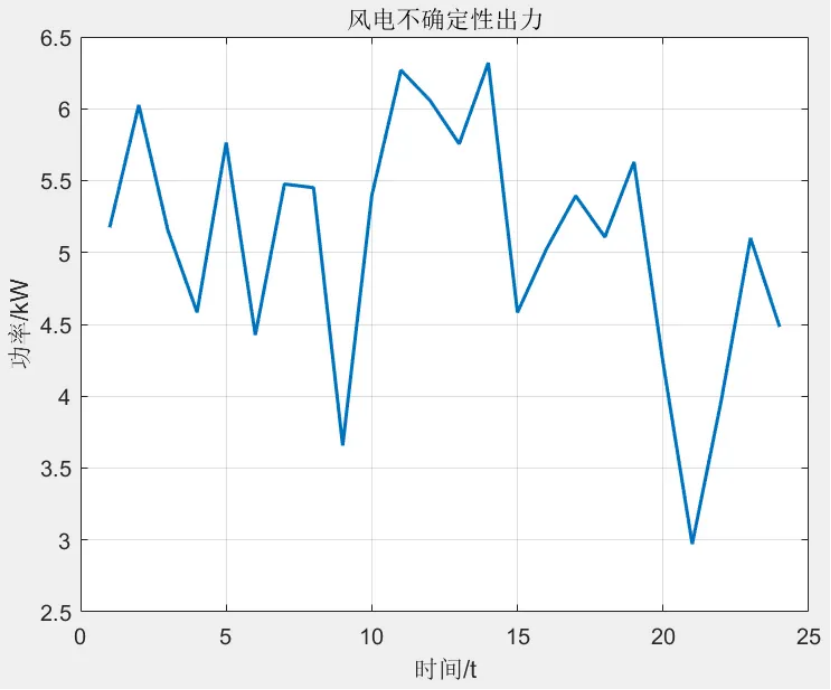
該程序方法復現《融合風光出力場景生成的多能互補微網系統優化配置》風光出力場景生成部分,目前大多數研究的是不計風光出力之間的相關性影響,但是地理位置相近的風電機組和光伏機組具有極大的相關性。因此,采用 Copula 函數作為風電、光伏聯合概率分布,生成風、光考慮空間相關性聯合出力場景,在此基礎上,基于Kmeans算法,分別對風光場景進行聚類,從而實現大規模場景的削減,削減到5個場景,最后得出每個場景的概率與每個對應場景相乘求和得到不確定性出力。

-
風光出力場景生成方法
以歷史風光出力數據(每小時一個點)為基礎(圖中x?和y?分別表示單位風機和光伏出力),首先基于核密度估計法選取常用的高斯核函數生成24h內每個時段的風、光出力概率密度函數。然后考慮風光相關性,基于?Copula理論建立每個時段的風光出力聯合概率分布函數;對于?Copula函數的選取,由于二元阿基米德?Copula函數中,Gumbel和ClaytonCopula函數只能描述變量間的非負關系,FrankCopula可兼顧變量的非負和負相關關系,而風光常有負相關互補關系,因此本文選取?FrankCopula函數描述風光相關性。最后,對每個時段的聯合概率分布函數進行采樣,并根據采樣結果和風光的聯合概率分布函數反變換得到每個時段的采樣風機和光伏出力,從而最終生成考慮風光相關性和隨機性的典型日曲線。
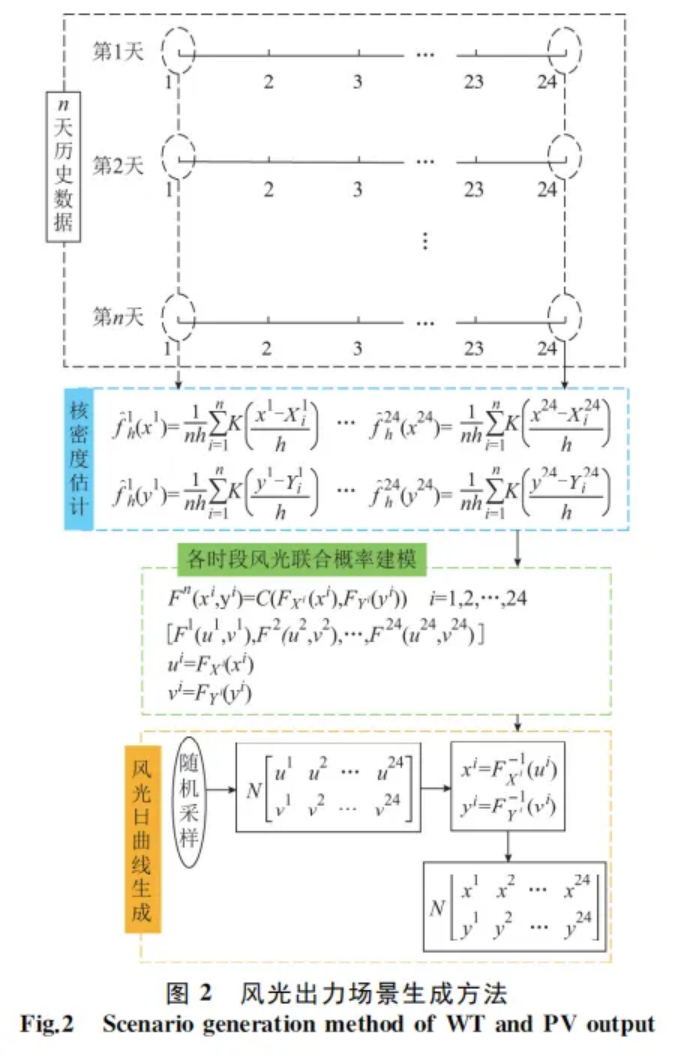
2?部分程序
% 基于Copula函數的風光功率聯合場景生成
% 關鍵詞:Copula;場景生成;風光出力相關性
clear; clc; close all;
%% 導入數據與預處理
solardata = xlsread('數據-光伏.xlsx');
winddata = xlsread('數據-風功率.xlsx');
winddata = winddata(2:end, :);
solardata = solardata(2:end, :);scenarionum = 500; % 初始場景數目,可修改
num_cluster = 5; % 要削減到的場景數目,可修改
ntime = 24; % 24小時% X和Y分別存儲風和光的24個時刻歷史觀測數據
X = []; Y = [];
for t = 1 : ntimeX{t} = winddata(:, t);Y{t} = solardata(:, t);
end%% Copula擬合
% Frank-Copula 函數可以同時考慮變量的非負與負相關的關系
% 故采用 Frank-Copula 函數分別對24個時刻進行擬合for i = 1 : ntimeU = ksdensity(X{i}, 'function', 'cdf'); % 核密度估計V = ksdensity(Y{i}, 'function', 'cdf');alpha = copulafit('frank', [U(:) V(:)]); % 擬合出的參數copulaparams.alpha = alpha;copulaparams.numParams = 1;copModels(i) = copulaparams;
end
%% 繪制二元Frank-Copula的密度函數和分布函數圖
[Udata, Vdata] = meshgrid(linspace(0,1,31)); % 為繪圖需要,產生新的網格數據
Ccdf_Frank = copulacdf('Frank', [Udata(:), Vdata(:)], copModels(12).alpha);3?程序結果
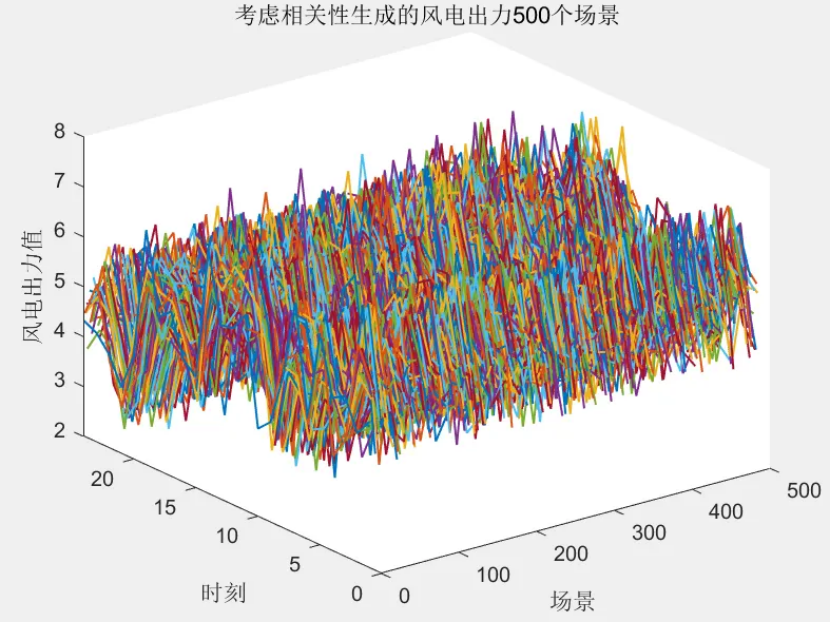
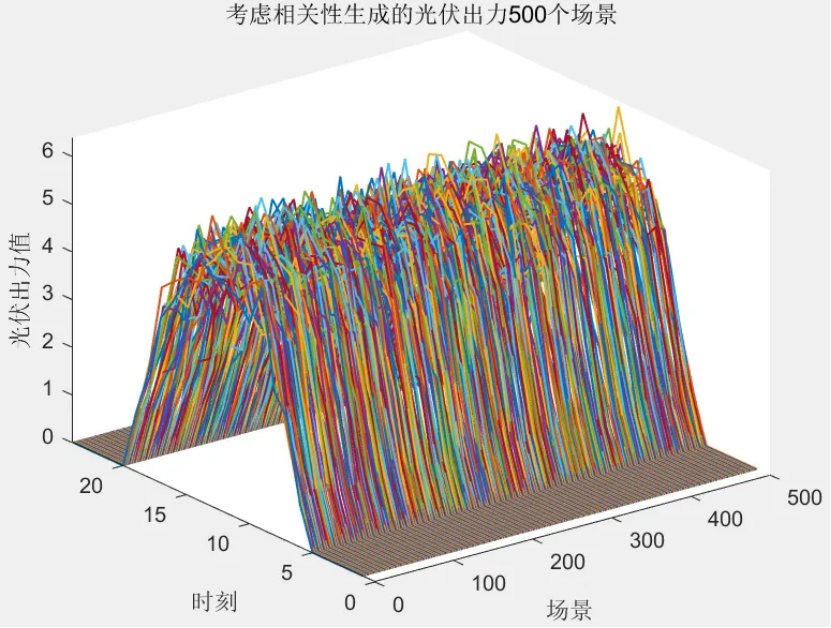
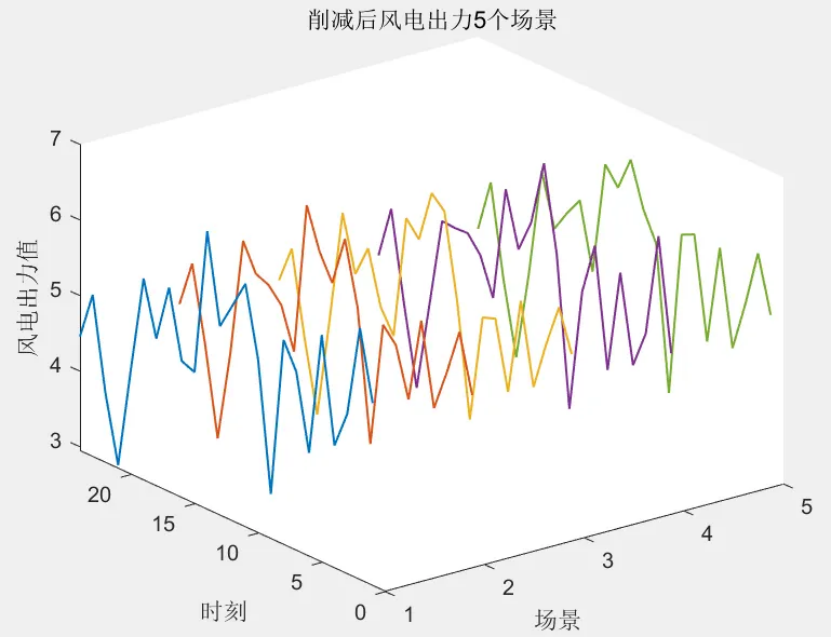










的深度解析及高級用法)
——05.線性代數)
)






:LLM如何解決模型可解釋性)
