前提:
①:本博客是對哈希表(開散列)進行封裝,因為閉散列不優秀(與庫保持一致)
②:哈希表封裝出unordered_set/_map和紅黑樹封裝出ste/map是大同小異的,可以先看下:用紅黑樹封裝出set和map -CSDN博客
③:本博客基于手撕哈希表-CSDN博客的基礎上講解,所以哈希表的起始代碼如下:
#pragma once
#include<iostream>
#include<vector>
using namespace std;template<class K>
//仿函數 用于得到kv對應的哈希值
//默認的是能直接轉換成整形值的 比如int 地址 指針 這種
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
//string比較通用,所以特化
//采取DKBR
//使用循環遍歷字符串中的每個字符e。
//將字符的ASCII值加到hash上,然后乘以一個常數131。
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};//開散列(哈希桶)的實現
namespace hash_bucket
{//這里叫HashNode 因為值存在鏈表中哦~template<class K, class V>struct HashNode{HashNode<K, V>* _next;//只想下一個節點的指針pair<K, V> _kv;//存儲的鍵值對//節點的構造HashNode(const pair<K, V>& kv):_next(nullptr)//next默認為空, _kv(kv){}};//哈希表類 依舊是一個仿函數用于得到kv對應的哈希值template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public://哈希表的構造 默認開存儲10個空指針的vector//相比于閉散列的構造 多了置nullptr這一步HashTable(){_tables.resize(10, nullptr);_n = 0;}//析構 用于釋放vector下面掛著的鏈表 //外層for循環->遍歷vector//內層while循環->遍歷每一個桶中的節點~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}//插入bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//仿函數實例化Hash hs;// 負載因子到1就擴容if (_n == _tables.size()){//不再是開一個新哈希表對象了,而是一個新的2倍大小的vector//這樣效率更高vector<Node*> newTables(_tables.size() * 2, nullptr);//依舊是外層for循環->遍歷原來的vector//內層while循環->遍歷每個桶內的節點for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算桶的位置掛到新表桶中Node* cur = _tables[i];while (cur){//保存下一個節點Node* next = cur->_next;// 頭插到新表//計算新位置size_t hashi = hs(cur->_kv.first) % newTables.size();//讓當前節點的 next 指向新表的桶頭cur->_next = newTables[hashi];//把當前節點設為新表的桶頭。newTables[hashi] = cur;cur = next;}//清空舊表的桶_tables[i] = nullptr;}//交換兩個vector_tables.swap(newTables);}//走到這里代表已經擴容完畢 或者不需要擴容//直接仿函數對象得到哈希值hashisize_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//然后頭插即可 切記vector里面放的是節點指針 指向一個桶的首節點newnode->_next = _tables[hashi];_tables[hashi] = newnode;//插入n記得++++_n;return true;}//查找函數//找到返回該節點的指針 反之nullptrNode* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}//刪除函數//不能像閉散列那樣find+delete 因為我們單向鏈表刪除后還要鏈接刪除節點的前后節點//易錯:得看前驅是否為空 即需要以防刪除的就是首節點bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){// 情況1:刪除的是中間或尾節點if (prev)//前驅不為空 {prev->_next = cur->_next;// 前驅節點直接跳過當前節點}//情況2:刪除的是頭節點else//前驅為空{_tables[hashi] = cur->_next;// 讓桶頭指向下一個節點}//釋放delete cur;//n-1--_n;return true;}//沒找到則繼續遍歷prev = cur;cur = cur->_next;}//遍歷結束仍未找到 return false;}//測試我們寫的哈希桶 測試內容如下/*負載因子(load factor)總桶數量(all bucketSize)非空桶數量(bucketSize)最長鏈表長度(maxBucketLen)平均鏈表長度(averageBucketLen)*/void Some(){size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;printf("load factor:%lf\n", (double)_n / _tables.size());printf("all bucketSize:%d\n", _tables.size());printf("bucketSize:%d\n", bucketSize);printf("maxBucketLen:%d\n", maxBucketLen);printf("averageBucketLen:%lf\n\n", averageBucketLen);}private://與閉散列不同的是 vector里面存儲的是節點指針了vector<Node*> _tables; // 指針數組size_t _n;};
}引入:想要完成封裝,我們的哈希表有什么不足?
①:哈希表結構的優化
我們哈希表目前只能存儲kv模型;所以結構需要優化,以便既能夠成為K模型,又要能成為KV模型
以及我們要做到不論是k模型還是kv模型,都要取得到k值
②:兩個仿函數的嵌套適用
我們要先通過仿函數得到k模型或者kv模型中的k值,然后再通過仿函數(哈希函數)得到k值對應的一個整形值;這是和紅黑樹封裝的不同,紅黑樹只需要得到k值即可。
③:迭代器的實現
④:unordered_map的[ ]的實現
一:優化哈希表的結構
A:要想即能創建出k模型的unordered_set和kv模型的unordered_map:
和紅黑樹類似,哈希表也是從第二個模板參數進行操作,就能達到效果
B:要想無論是k模型還是kv模型,都要取得到k值
從仿函數入手即可
相關細節不再贅述,紅黑樹封裝博客里面有類似的詳細講解:用紅黑樹封裝出set和map -CSDN博客
直接看代碼:
unordered_set代碼:
#include"HashTable.h"template<class K, class Hash = HashFunc<K>>//外界調用所需參數class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:private://創建一個哈希表對象hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;};unordered_map代碼:
#include"HashTable.h"template<class K, class V, class Hash = HashFunc<K>>//外界調用所需參數class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};private://創建一個哈希表對象hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};解釋:對哈希表的第四個參數的解釋
? ? ? ?①:?創建哈希表中的第四個參數Hash,是實現在HashTable.h中的,且unordered_set和unordered_map文件中在包含了HashTable.h后,都是在模版中的Hash給上缺省值的,所以我們HashTable.h中,哈希表的模版中的Hash參數不需要再給缺省值
? ? ? ? ②:為什么在unordered_set/map中處理這個參數??因為,使用者不可能直接用哈希表而是用unordered_set或unordered_map,所以一般是不需要對unordered_set/map參數中的哈希函數進行傳參的,只有k值是特殊類型的時候,才需要自己實現哈希函數進行手動傳參
所以哈希表的起始狀態如下:
//哈希函數 以及模版參數為string的特化處理
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};namespace hash_bucket
{// T -> K// T -> pair<K, V>//哈希節點類 哈希桶中都是節點 所以叫節點類template<class T>struct HashNode{HashNode<T>* _next;T _data;HashNode(const T& data):_next(nullptr), _data(data){}};//哈希表類template<class K, class T, class KeyOfT, class Hash>//Hash不需要缺省值class HashTable{//節點類的縮寫 typedef HashNode<T> Node;public:private:vector<Node*> _tables; // 指針數組size_t _n;};
}????????到這里,我們的哈希表既能創建出k模型的unordered_set和kv模型的unordered_map;也能無論是k模型還是kv模型,都要取得到k值;通過兩個仿函數就可以辦到~
二:兩個仿函數的嵌套使用
????????我們的函數,也要進行改變,不再是之前的寫死了對pair類型進行操作,現在獲取到的是T類型的data值,我們要先對data進行取出其中的k,然后再用仿函數讓k得到一個整形
所以插入 查找 刪除函數改動如下:
//插入函數pair<iterator, bool> Insert(const T& data){KeyOfT kot;iterator it = Find(kot(data));if (it != end())return make_pair(it, false);//仿函數對象的實例化Hash hs;// 負載因子到1就擴容if (_n == _tables.size()){vector<Node*> newTables(GetNextPrime(_tables.size()), nullptr);for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算掛到新表桶中Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 頭插到新表size_t hashi = hs(kot(cur->_data)) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = hs(kot(data)) % _tables.size();Node* newnode = new Node(data);// 頭插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}//查找函數iterator Find(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return iterator(nullptr, this);}//刪除函數bool Erase(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){// 刪除if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}解釋:
①:仿函數的實例化
//取出data里面的k值
KeyOfT kot; //將k值轉換為一個整形值
Hash hs;
②:仿函數嵌套適用:
hs(kot(data))這就叫仿函數的嵌套使用,先拿出data里面的k值,然后得到k值對應的整形值?
③:insert函數的返回值,和紅黑樹一樣,是為了unordered_map的[ ]所準備的
④:擴容中用到了一個GetNextPrime函數,先別管,后面會講
三:迭代器的實現
哈希表的迭代器的實現是一個重點,和以往的任何的迭代器實現都不同,以前的實現,要么是直接復用的指針(如底層連續的vector),要么就是對一個節點指針進行封裝,去重載++ * != 等操作符;
哈希表的迭代器的問題:
Q:你對一個節點指針進行了封裝,雖然可以* ++ !=....重載,但是一個桶走完了,怎么找到下一個桶?
A:所以哈希表的迭代器不再只對節點指針封裝,且還要對哈希表指針封裝,也就是有兩個成員變量
注意:迭代器博主只實現了正向非const迭代器,其余的大同小異,不再贅述
1:迭代器代碼:
//哈希桶的迭代器類template<class K, class T, class KeyOfT, class Hash>struct __HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef __HTIterator<K, T, KeyOfT, Hash> Self;//兩個成員變量Node* _node;HT* _ht;//迭代器的構造__HTIterator(Node* node, HT* ht):_node(node), _ht(ht){}//*重載T& operator*(){return _node->_data;}//->的重載T* operator->(){return &_node->_data;}//++的重載Self& operator++(){if (_node->_next){// 當前桶還是節點_node = _node->_next;}else{// 當前桶走完了,找下一個桶KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();// 找下一個桶hashi++;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}hashi++;}// 后面沒有桶了if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}//!=的重載bool operator!=(const Self& s){return _node != s._node;}};2:迭代器代碼解釋:
①:成員變量
Node* _node; // 當前指向的哈希節點
HT* _ht; // 指向所屬的哈希表②:關鍵類型定義
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef __HTIterator<K, T, KeyOfT, Hash> Self;Self:迭代器自身的類型,簡化返回值類型聲明(如 operator++ 返回 Self&)。?
③:迭代器的核心操作
a:解引用操作?operator*
T* operator->()
{return &_node->_data; // 返回節點數據的指針
}b:成員訪問操作?operator->
T* operator->()
{return &_node->_data; // 返回節點數據的指針
}c:?不等比較?operator!=
bool operator!=(const Self& s)
{return _node != s._node; // 比較兩個迭代器是否指向同一節點
}d:最關鍵的?operator++(跨桶遍歷)
Self& operator++()
{//情況1:當前桶還有下一個節點if (_node->_next) {_node = _node->_next;} //來到這里 代表是情況2//情況2:當前桶已遍歷完,需跳轉到下一個非空桶else {//所以需要先計算當前節點所在的桶索引 hashi!KeyOfT kot;Hash hs;//hashi即當前節點所在的桶索引size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();hashi++; // 從下一個桶開始找//hashi得一直++,直到找到一個不為空的桶(為空代表vector此槽位是nullptr)while (hashi < _ht->_tables.size()) {if (_ht->_tables[hashi]) // 找到非空桶{_node = _ht->_tables[hashi]; // 指向該桶的首節點break;}hashi++;}//hashi一直++ 直到vector遍歷完了 都沒發現非空桶 //則將迭代器置為end()(因為end()就是nullptr)if (hashi == _ht->_tables.size()) {_node = nullptr;}}return *this;
}?解釋:代碼邏輯轉換為圖片如下

四:map的[ ]的實現?
在unordered_map中進行以下實現即可,和紅黑樹類似,不再贅述:
//[ ]函數V& operator[](const K& key){pair<iterator, bool> ret = insert(make_pair(key, V()));return ret.first->second;}?
五:總代碼
①:HashTable.h
#pragma once
#include<iostream>
#include<vector>
#include<unordered_set>
#include<unordered_map>
#include<set>
using namespace std;//哈希函數 以及模版參數為string的特化處理
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};//開散列的域
//開散列 也叫哈希桶
namespace hash_bucket
{// T -> K// T -> pair<K, V>//哈希節點類 哈希桶中都是節點 所以叫節點類template<class T>struct HashNode{HashNode<T>* _next;T _data;HashNode(const T& data):_next(nullptr), _data(data){}};// 前置聲明 template<class K, class T, class KeyOfT, class Hash >class HashTable;//哈希桶的迭代器類template<class K, class T, class KeyOfT, class Hash>struct __HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef __HTIterator<K, T, KeyOfT, Hash> Self;//兩個成員變量Node* _node;HT* _ht;//迭代器的構造__HTIterator(Node* node, HT* ht):_node(node), _ht(ht){}//*重載T& operator*(){return _node->_data;}//->的重載T* operator->(){return &_node->_data;}//++的重載Self& operator++(){if (_node->_next){// 當前桶還剩節點_node = _node->_next;}else{// 當前桶走完了,找下一個桶KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();// 找下一個桶hashi++;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}hashi++;}// 后面沒有桶了if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}//!=的重載bool operator!=(const Self& s){return _node != s._node;}};//哈希表類template<class K, class T, class KeyOfT, class Hash>// KeyOfT用于取出T中的k值 Hash則是得到這個取出的k值對應的整形class HashTable{template<class K, class T, class KeyOfT, class Hash>friend struct __HTIterator;//節點類的縮寫 typedef HashNode<T> Node;public:typedef __HTIterator<K, T, KeyOfT, Hash> iterator;//迭代器的兩個函數//begin()函數iterator begin(){for (size_t i = 0; i < _tables.size(); i++){// 找到第一個桶的第一個節點if (_tables[i]){return iterator(_tables[i], this);}}return end();}//end()函數iterator end(){return iterator(nullptr, this);}//構造函數HashTable(){_tables.resize(10, nullptr);_n = 0;}//析構函數~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}//獲取本次增容后哈希表的大小 空間呈素數增長size_t GetNextPrime(size_t prime){const int PRIMECOUNT = 28;//素數序列const size_t primeList[PRIMECOUNT] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (i = 0; i < PRIMECOUNT; i++){if (primeList[i] > prime)return primeList[i];}return primeList[i];//邏輯返回}//插入函數pair<iterator, bool> Insert(const T& data){KeyOfT kot;iterator it = Find(kot(data));if (it != end())return make_pair(it, false);//仿函數對象的實例化Hash hs;// 負載因子到1就擴容if (_n == _tables.size()){vector<Node*> newTables(GetNextPrime(_tables.size()), nullptr);for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算掛到新表桶中Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 頭插到新表size_t hashi = hs(kot(cur->_data)) % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = hs(kot(data)) % _tables.size();Node* newnode = new Node(data);// 頭插newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}//查找函數iterator Find(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return iterator(nullptr, this);}//刪除函數bool Erase(const K& key){KeyOfT kot;Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){// 刪除if (prev){prev->_next = cur->_next;}else{_tables[hashi] = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables; // 指針數組size_t _n;};
}②:My_unordered_set
#pragma once
#include"HashTable.h"namespace bit
{template<class K, class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public://復用哈希表類的迭代器typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::iterator iterator;//復用哈希表的begin函數iterator begin(){return _ht.begin();}//復用哈希表的end函數iterator end(){return _ht.end();}//復用哈希表的插入函數pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}//復用哈希表的查找函數iterator Find(const K& key){return _ht.Find(key);}//復用哈希表的刪除函數bool erase(const K& key){return _ht.Eease(key);}private://創建一個哈希表對象hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;};//測試set 體現迭代器遍歷出來是無序的 且set的k值不能被修改void test_set1(){unordered_set<int> us;us.insert(3);us.insert(1);us.insert(5);us.insert(15);us.insert(45);us.insert(7);unordered_set<int>::iterator it = us.begin();while (it != us.end()){//*it += 100;cout << *it << " ";++it;}cout << endl;for (auto e : us){cout << e << " ";}cout << endl;}}
③:My_unordered_map
#pragma once
#include"HashTable.h"namespace bit
{template<class K, class V, class Hash = HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::iterator iterator;//復用哈希表的begin()函數iterator begin(){return _ht.begin();}//復用哈希表的end()函數iterator end(){return _ht.end();}//復用哈希表的插入函數pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}//復用哈希表的查找函數iterator Find(const K& key){return _ht.Find(key);}//復用哈希表的刪除函數bool erase(const K& key){return _ht.Eease(key);}//[ ]函數V& operator[](const K& key){pair<iterator, bool> ret = insert(make_pair(key, V()));return ret.first->second;}private://創建一個哈希表對象hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};//測試map 體現迭代器遍歷出來是無序的 且map的k值不能被修改 v值可以修改void test_map1(){unordered_map<string, string> dict;dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("left", "左面"));dict.insert(make_pair("right", "右面"));for (auto& kv : dict){//kv.first += 'x';kv.second += 'y';cout << kv.first << ":" << kv.second << endl;}}//測試map的[]void test_map2(){string arr[] = { "蘋果", "西瓜", "蘋果", "西瓜", "蘋果", "蘋果", "西瓜","蘋果", "香蕉", "蘋果", "西瓜", "香蕉", "草莓" };unordered_map<string, int> countMap;for (auto& e : arr){countMap[e]++;}for (auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}cout << endl;}}④:test.cpp?
#define _CRT_SECURE_NO_WARNINGS 1#include"MyOrderedMap.h"
#include"MyOrderedSet.h"int main()
{//測試封裝后的OrderedSet和OrderedMap 體現無序性bit::test_set1();bit::test_map1();//測試OrderedMap的[]bit::test_map2();return 0;
}⑤:代碼整合
當多份獨立可運行的代碼合并到一個項目中時,需要解決一些問題:
a:創建哈希表時候的第二個參數的寫法
//My_unordered_set中:
const K//My_unordered_map中:
pair<const K, V>解釋:這樣寫,對于My_unordered_set,k不能改;對于My_unordered_map?,k不能改,v可以改
和庫保持一致,符合這種數據結構的特性
b:在迭代器之前要前置聲明一下哈希表類,注意寫法:
// 前置聲明 template<class K, class T, class KeyOfT, class Hash >class HashTable;
解釋:
Q:為什么在?迭代器之前要前置聲明哈希表類?
A:因為迭代器類中又需要用到?HashTable?的類型(如?typedef HashTable<K, T, KeyOfT, Hash> HT;);這樣迭代器類才能安全地引用?HashTable,而不會報錯“未定義的類型”。
c:哈希表類中要聲明迭代器類為友元:
template<class K, class T, class KeyOfT, class Hash>friend struct __HTIterator;Q: 為什么要在哈希表類中要聲明迭代器類為友元?
A:因為迭代器需要訪問?HashTable?的?私有成員(如?_tables?和?_n),但默認情況下,外部類(包括迭代器)無法訪問私有成員;
例如,operator++?中需要計算哈希桶位置:
size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size(); // 訪問 _tables?如果?_tables?是?private,且迭代器不是友元,這段代碼會編譯失敗。
Q:為什么不能直接把?_tables?改成?public?
A:
-
破壞封裝性,外部任何代碼都可以隨意修改哈希表內部結構,不安全。
-
友元是一種?受控的暴露,只允許特定的類(如迭代器)訪問私有成員
d:GetNextPrime函數的作用
GetNextPrime?是哈希表擴容時用于?計算新容量?的函數,其核心目的是?返回一個比當前容量大的素數,作為哈希表的新桶數組大小。這是為了解決哈希表擴容時的效率問題,并減少哈希沖突。
因為,經過前輩研究,素數擴容是最好的,會有效的減少哈希沖突!
六:測試代碼
①:測試My_unordered_set
void test_set1(){unordered_set<int> us;us.insert(3);us.insert(1);us.insert(5);us.insert(15);us.insert(45);us.insert(7);unordered_set<int>::iterator it = us.begin();while (it != us.end()){//*it += 100;cout << *it << " ";++it;}cout << endl;for (auto e : us){cout << e << " ";}cout << endl;}運行結果:

解釋:迭代器和范圍for均正常,且符合無序的預期
②:測試My_unordered_map
void test_map1(){unordered_map<string, string> dict;dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("left", "左面"));dict.insert(make_pair("right", "右面"));for (auto& kv : dict){//kv.first += 'x';kv.second += 'y';cout << kv.first << ":" << kv.second << endl;}}
運行結果:
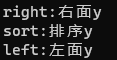
解釋:符合無序的預期,且k值不能改變,但可以對v值進行了改變,正確
void test_map2(){string arr[] = { "蘋果", "西瓜", "蘋果", "西瓜", "蘋果", "蘋果", "西瓜","蘋果", "香蕉", "蘋果", "西瓜", "香蕉", "草莓" };unordered_map<string, int> countMap;for (auto& e : arr){countMap[e]++;}for (auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}cout << endl;}運行結果:
 ?
?
解釋:符合預期

:深度圖優化)
)

)



-加載、控制)
:淺析ATAM 在軟件技術架構評估中的應用)






)


