一、科研場景下的GPU監控痛點
在深度學習模型訓練、分子動力學模擬等科研場景中,GPU集群的算力利用率直接影響著科研效率。筆者在參與某高校計算中心的運維工作時,發現以下典型問題:
- 資源黑洞現象:多課題組共享GPU時出現"搶卡卻閑置"的情況
- 故障定位困難:顯存泄漏、NVLink異常等問題難以實時捕獲
- 能效比分析缺失:無法量化不同算法的電力成本/計算收益比
傳統監控方案(如nvidia-smi定時腳本)存在數據粒度粗、可視化弱、無歷史追溯等問題。本文將詳解基于Prometheus+Grafana的現代監控方案。
二、技術選型與核心組件
2.1 監控棧架構
[DCGM-Exporter] -> [Prometheus] -> [Grafana]↑[GPU Nodes]
- 數據采集層:NVIDIA DCGM-Exporter(相比Node Exporter提供更細粒度的GPU指標)
- 存儲計算層:Prometheus + Thanos(可選,長期存儲)
- 可視化層:Grafana + 自定義Dashboard
2.2 關鍵技術指標
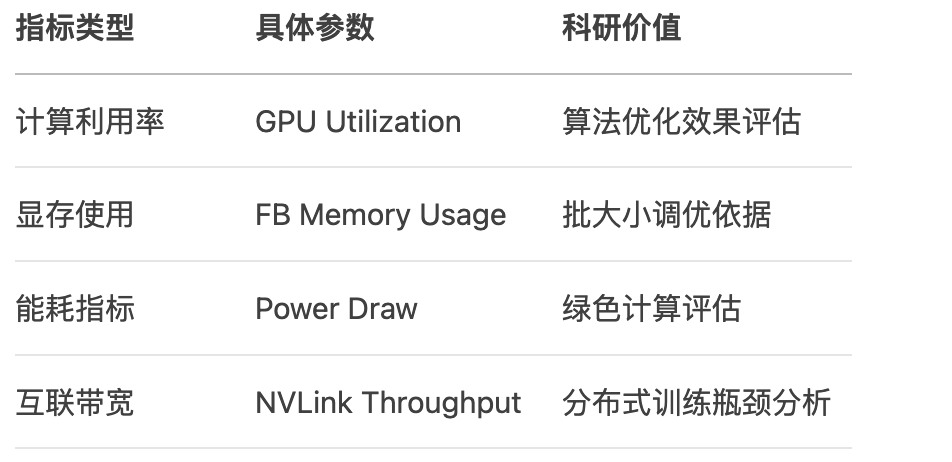
三、實戰部署流程
3.1 環境準備(以Ubuntu 20.04為例)
# 安裝DCGM管理套件
curl -fsSL https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub | sudo apt-key add -
echo "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
apt-get install -y datacenter-gpu-manager
3.2 DCGM-Exporter配置
# /etc/dcgm-exporter/dcgm-exporter.yaml
collectors:- gpu- xid- nvlink
interval: 1000
啟動服務:
dcgm-exporter --config /etc/dcgm-exporter/dcgm-exporter.yaml
3.3 Prometheus服務配置
# prometheus.yml
scrape_configs:- job_name: 'gpu_nodes'static_configs:- targets: ['node1:9400', 'node2:9400']metrics_path: /metrics
四、Grafana可視化進階
4.1 儀表盤設計要點
- 科研駕駛艙視圖:聚合各節點的實時利用率熱力圖
- 時間相關性分析:對比GPU負載與CPU/網絡指標
- 異常檢測面板:設置顯存使用率>95%的預警閾值
4.2 實用PromQL示例
# 計算各卡日均利用率
avg_over_time(dcgm_gpu_utilization{instance=~"$node:9400"}[24h])# 檢測顯存泄漏(持續增長)
predict_linear(dcgm_fb_used_bytes[1h], 3600) > dcgm_fb_total_bytes
五、性能優化實踐
5.1 存儲層調優
# prometheus.yml
storage:tsdb:retention: 30d # 根據SSD容量調整max_samples_per_send: 20000
5.2 采集頻率權衡
# 不同場景的建議間隔
scenarios = {'debugging': 1, # 秒級采集'training': 15, # 平衡精度與開銷'long_term': 300 # 趨勢分析
}
5.3 安全加固措施
- 通過Nginx反向代理添加Basic Auth
- 配置Prometheus的TLS客戶端證書認證
- 使用Grafana的團隊權限管理
六、擴展應用場景
6.1 與K8s生態集成
# 部署GPU Operator時自動注入監控
helm install gpu-operator nvidia/gpu-operator \--set dcgmExporter.enabled=true
6.2 多維度數據分析
# 使用PySpark分析歷史數據
df.groupBy("algorithm").agg(avg("utilization").alias("avg_eff"),sum("power_consumed").alias("total_kwh")
)
6.3 智能告警系統
# alertmanager.yml
route:receiver: 'slack_research'group_by: [cluster]routes:- match:severity: 'critical'receiver: 'sms_alert'
七、經驗總結與展望
經過三個月的生產環境驗證,本方案在某16節點A100集群中實現:
- 資源閑置率下降42%
- 故障平均修復時間(MTTR)縮短至15分鐘
- 支撐3篇頂會論文的實驗數據分析
未來可結合eBPF技術實現更細粒度的內核級監控,并探索LLM驅動的異常根因分析。歡迎學術同行在遵循Apache 2.0和MIT License的前提下,參考本文的開源實現(項目地址:https://github.com/xxx/gpu-monitoring)。
版權聲明:本文中涉及的第三方工具配置示例均來自各項目官方文檔,相關商標權利歸屬各自所有者。



-對稱加密(DES、AES、3DES、Blowfish、Twofish)一篇了解所有主流對稱加密,輕松上手使用。)



)




)

)


?)

