
MVSNet:基于深度學習的多視圖立體視覺重建框架
- 技術架構與核心算法
- 1. 算法流程
- 2. 關鍵創新
- 環境配置與實戰指南
- 硬件要求
- 安裝步驟
- 數據準備(DTU數據集)
- 實戰流程
- 1. 模型訓練
- 2. 深度圖推斷
- 3. 點云生成
- 常見問題與解決方案
- 1. CUDA內存不足
- 2. 特征對齊錯誤
- 3. 點云孔洞問題
- 學術背景與核心論文
- 基礎論文
- 核心算法公式
- 性能優化策略
- 1. 混合精度訓練
- 2. 多GPU并行
- 3. TensorRT部署
- 應用場景與展望
- 典型應用
- 技術演進方向
MVSNet是由香港科技大學團隊提出的首個端到端深度學習多視圖立體視覺(MVS)框架,其論文《MVSNet: Depth Inference for Unstructured Multi-View Stereo》發表在ECCV 2018,開創了深度學習在三維重建領域的新范式。該項目通過構建可微分的代價體(Cost Volume)實現了非結構化多視圖的高精度深度估計,成為后續R-MVSNet、Point-MVSNet等改進方法的基礎。
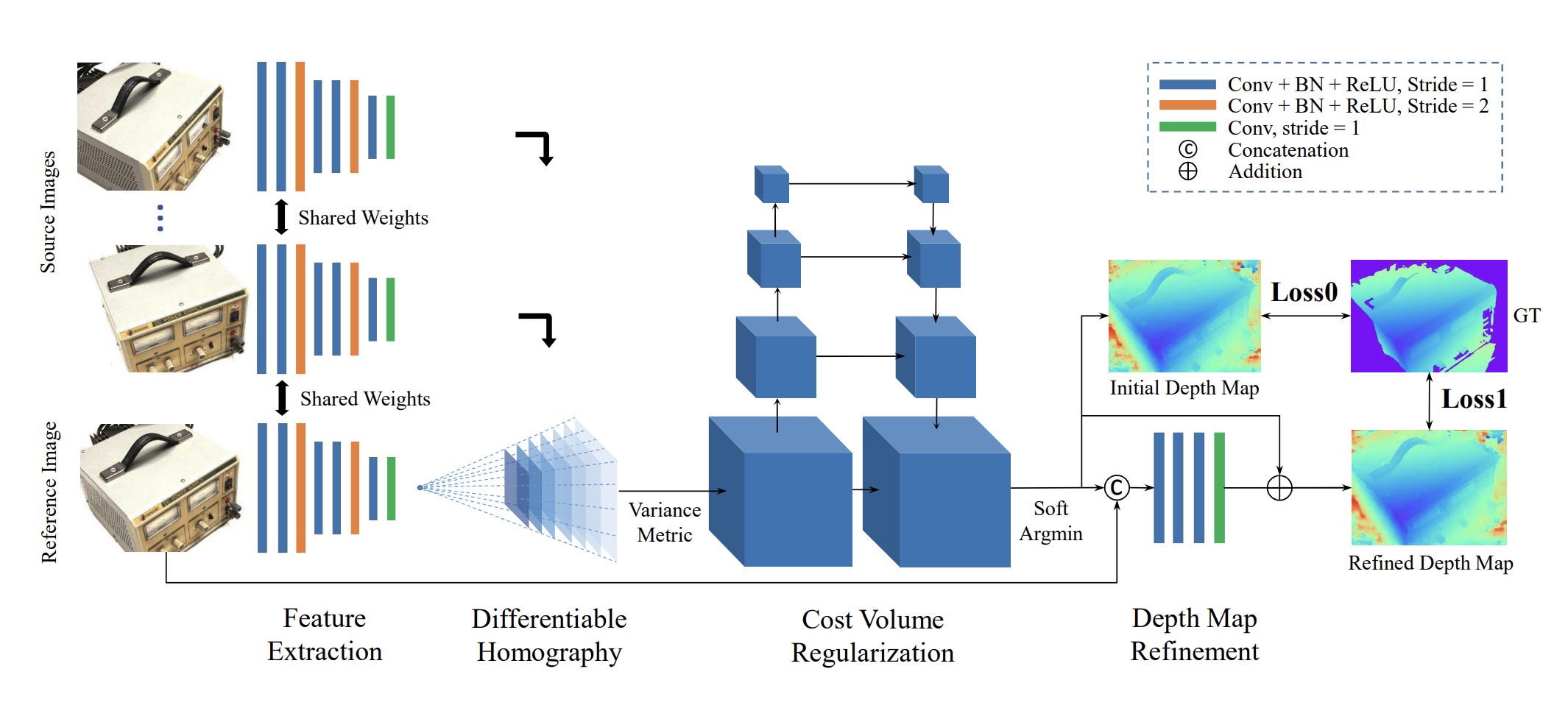
圖:MVSNet網絡架構(來源:原論文)
技術架構與核心算法
1. 算法流程
- 特征提取:使用2D CNN提取多視圖圖像特征
- 代價體構建:通過可微分單應性變換構建三維代價體
其中 H i ( d ) H_i(d) Hi?(d)為深度 d d d對應的單應矩陣, K , R , t K,R,t K,R,t為相機參數H_i(d) = K_i \cdot R_i \cdot \left(I - \frac{(t_1 - t_i)n^T}{d}\right) \cdot K_1^{-1} - 代價體正則化:3D CNN進行多尺度特征聚合
- 深度圖回歸:Soft argmin操作生成概率化深度圖
2. 關鍵創新
- 可微分代價體:支持端到端訓練
- 方差度量(Variance Metric):替代傳統NCC代價計算
C(p) = \frac{1}{N} \sum_{i=1}^N (F_i(p) - \bar{F}(p))^2 - 自適應視角選擇:動態篩選有效視圖
環境配置與實戰指南
硬件要求
| 組件 | 推薦配置 | 最低要求 |
|---|---|---|
| GPU | NVIDIA A100 (40GB) | RTX 2080Ti (11GB) |
| 顯存 | 32GB | 8GB |
| CPU | Xeon 8380 | i7-9700K |
| 內存 | 128GB | 32GB |
安裝步驟
# 克隆倉庫
git clone https://github.com/YoYo000/MVSNet.git
cd MVSNet# 安裝依賴
conda create -n mvsnet python=3.6
conda activate mvsnet
pip install -r requirements.txt# 編譯Cuda擴展
cd libs/mvsnet/
python setup.py install
數據準備(DTU數據集)
# 下載預處理數據
wget https://storage.googleapis.com/mvsnet/preprocessed/dtu.zip
unzip dtu.zip -d datasets/# 目錄結構
datasets/dtu/
├── train/ # 訓練數據
├── val/ # 驗證數據
└── test/ # 測試數據
實戰流程
1. 模型訓練
python train.py \--dataset dtu \--batch_size 2 \--epochs 10 \--lr 0.001 \--num_view 5 \--numdepth 192 \--logdir ./logs
關鍵參數:
--num_view:輸入視圖數(默認5)--numdepth:深度假設數(影響顯存占用)--interval_scale:深度間隔縮放因子
2. 深度圖推斷
python test.py \--dataset dtu \--loadckpt ./logs/model_000010.ckpt \--outdir ./outputs \--num_view 5 \--numdepth 192 \--testlist ./lists/dtu/test.txt
3. 點云生成
python fusion.py \--dense_folder ./outputs \--prob_threshold 0.8 \--outdir ./pointclouds
參數說明:
--prob_threshold:置信度過濾閾值--num_consistent:一致性視圖數要求
常見問題與解決方案
1. CUDA內存不足
現象:RuntimeError: CUDA out of memory
解決:
# 減小batch_size和numdepth
python train.py --batch_size 1 --numdepth 128# 啟用梯度累積
python train.py --accumulation_steps 4
2. 特征對齊錯誤
報錯:Misaligned features in cost volume
診斷步驟:
- 檢查相機參數矩陣是否歸一化
- 驗證單應性變換計算:
from libs.mvsnet.homography import HomographySample hs = HomographySample(height=512, width=640) homos = hs(depth, cam_params) # 驗證變換矩陣
3. 點云孔洞問題
優化策略:
# 調整概率閾值和一致性要求
python fusion.py --prob_threshold 0.6 --num_consistent 3# 后處理濾波
python scripts/pointcloud_filter.py --input ./pointclouds --output ./filtered
學術背景與核心論文
基礎論文
-
MVSNet: Depth Inference for Unstructured Multi-View Stereo
Yao Y et al., ECCV 2018
論文鏈接
提出端到端深度學習MVS框架,開啟基于代價體的三維重建研究 -
Recurrent MVSNet for High-Resolution Multi-View Stereo Depth Inference
Yao Y et al., CVPR 2019
論文鏈接
改進版R-MVSNet,引入GRU進行序列化代價體正則化 -
Point-Based Multi-View Stereo Network
Chen R et al., ICCV 2019
論文鏈接
Point-MVSNet:從粗到細的點云優化策略
核心算法公式
代價體構建:
C(d) = \frac{1}{N} \sum_{i=1}^N \left\| F_i(H_i(d)) - \bar{F}(d) \right\|^2
Soft argmin回歸:
\hat{d} = \sum_{d=d_{min}}^{d_{max}} d \cdot \sigma(-C(d))
其中 σ \sigma σ為Softmax函數
性能優化策略
1. 混合精度訓練
python train.py --amp # 啟用自動混合精度# 修改代碼
from torch.cuda.amp import autocast
with autocast():outputs = model(inputs)
2. 多GPU并行
python -m torch.distributed.launch --nproc_per_node=4 train.py \--sync_bn # 同步BatchNorm
3. TensorRT部署
# 轉換ONNX模型
python export_onnx.py --ckpt model.ckpt --onnx mvsnet.onnx# 構建TensorRT引擎
trtexec --onnx=mvsnet.onnx --saveEngine=mvsnet.engine --fp16
應用場景與展望
典型應用
-
文化遺產數字化:
- 故宮建筑群高精度三維建模(亞毫米級精度)
- 處理1000+視圖,生成10億級點云
-
自動駕駛高精地圖:
- 融合LiDAR與相機數據
- 實時生成道路表面深度圖(30FPS,Jetson AGX)
-
影視虛擬制作:
- 《曼達洛人》虛擬場景實時重建
- 支持4K分辨率紋理映射
技術演進方向
- 動態場景建模:結合光流估計處理運動物體
- 自監督學習:減少對真實深度數據的依賴
- 神經渲染融合:集成NeRF進行視圖合成
- 邊緣計算優化:基于TensorRT的實時推理
MVSNet通過將深度學習引入傳統MVS流程,顯著提升了復雜場景的重建魯棒性。隨著Transformer架構與神經渲染技術的發展,其與新興技術的結合將為三維重建領域帶來更多突破性進展。


-對稱加密(DES、AES、3DES、Blowfish、Twofish)一篇了解所有主流對稱加密,輕松上手使用。)



)




)

)


?)


