大語言模型(LLMs)的推理能力是當下研究熱點,強化學習在其復雜推理任務微調中廣泛應用。這篇論文深入剖析了相關算法,發現簡單的拒絕采樣基線方法表現驚人,還提出了新算法。快來一探究竟,看看這些發現如何顛覆你對LLMs訓練的認知!
論文標題
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
來源
arXiv:2504.11343v1 [cs.LG] 15 Apr 2025
https://arxiv.org/abs/2504.11343
文章核心
研究背景
在大語言模型(LLMs)的后訓練階段,近端策略優化(PPO)是常用方法,但它存在計算開銷大、算法復雜等問題。同時,一些簡單有效的強化學習(RL)算法逐漸受到關注,如GRPO在訓練模型(如DeepSeek - R1)上取得成功,但對其有效性來源了解不足。
研究問題
- RL算法中不同方法處理負樣本的方式差異較大,負樣本在LLMs訓練中的作用和影響尚不明確,例如簡單地基于最終答案正確性定義負樣本可能過于粗糙。
- GRPO算法細節缺乏充分文檔記錄,其性能優勢是源于自身固有優點,還是與之前研究方法的延續性,有待探究。
- 在基于獎勵的LLMs后訓練中,算法設計和樣本選擇的重要性尚不清晰,難以確定哪種因素對模型性能提升更關鍵。
主要貢獻
- 重新評估簡單基線方法:發現僅使用正樣本訓練的簡單拒絕采樣基線方法RAFT,性能與最先進的RL方法GRPO差距極小,在早期訓練階段收斂更快,挑戰了傳統認為RL方法因利用負反饋而更強大的觀點。
- 剖析GRPO優勢來源:通過消融實驗揭示,GRPO的主要優勢并非獎勵歸一化,而是丟棄了完全錯誤響應的提示,為理解和改進基于策略梯度的RL算法提供了關鍵依據。
- 提出新算法Reinforce - Rej:基于研究成果提出Reinforce - Rej算法,它選擇性過濾完全正確和完全錯誤的樣本,提高了KL效率和穩定性,為獎勵基策略優化提供了一個簡單且有競爭力的基線。
- 明確樣本選擇重要性:強調在基于獎勵的LLMs后訓練中,樣本選擇比算法設計更重要,未來研究應聚焦于更合理地選擇和利用樣本,而不是盲目依賴負樣本。
方法論精要
- 核心算法/框架:研究涉及RAFT、Policy Gradient(包括Reinforce)、GRPO、Iterative DPO、RAFT++等算法。其中,RAFT通過拒絕采樣選擇正樣本微調模型;Policy Gradient旨在優化策略網絡以最大化期望獎勵;GRPO改進了Policy Gradient,采用優勢函數并進行獎勵歸一化;Iterative DPO基于成對比較數據集優化對比損失;RAFT++則是對RAFT應用重要性采樣和裁剪技術的擴展算法。
- 關鍵參數設計原理:在實驗中,使用AdamW優化器,學習率為$ 1×10^{-6} 。每次迭代采樣 1024 個提示, R A F T 和 G R P O 每個提示生成 。每次迭代采樣1024個提示,RAFT和GRPO每個提示生成 。每次迭代采樣1024個提示,RAFT和GRPO每個提示生成 n = 4 $個響應,訓練小批量大小設置為512,模型訓練時最多生成4096個令牌。這些參數設置基于verl框架推薦,以平衡模型訓練的效率和效果。
- 創新性技術組合:RAFT++結合了重要性采樣和裁剪技術,在采樣過程中糾正分布偏移,同時通過裁剪防止更新過大導致訓練不穩定,有效提升了模型性能。Reinforce - Rej算法則創新性地同時過濾完全正確和完全錯誤的樣本,避免不良樣本對訓練的干擾,提高模型訓練的穩定性和效率。
- 實驗驗證方式:選擇數學推理任務進行實驗,使用Numina - Math數據集,該數據集包含約860k數學問題及答案,來源廣泛。模型選擇Qwen2.5 - Math - 7B - base和LLaMA - 3.2 - 3B - instruct。基線方法包括Base模型(未經過特定RL算法微調)、Iterative DPO、Reinforce、GRPO、PPO等。通過對比不同算法在多個基準測試(Math500、Minerva Math、Olympiad Bench)上的平均@16準確率來評估模型性能。
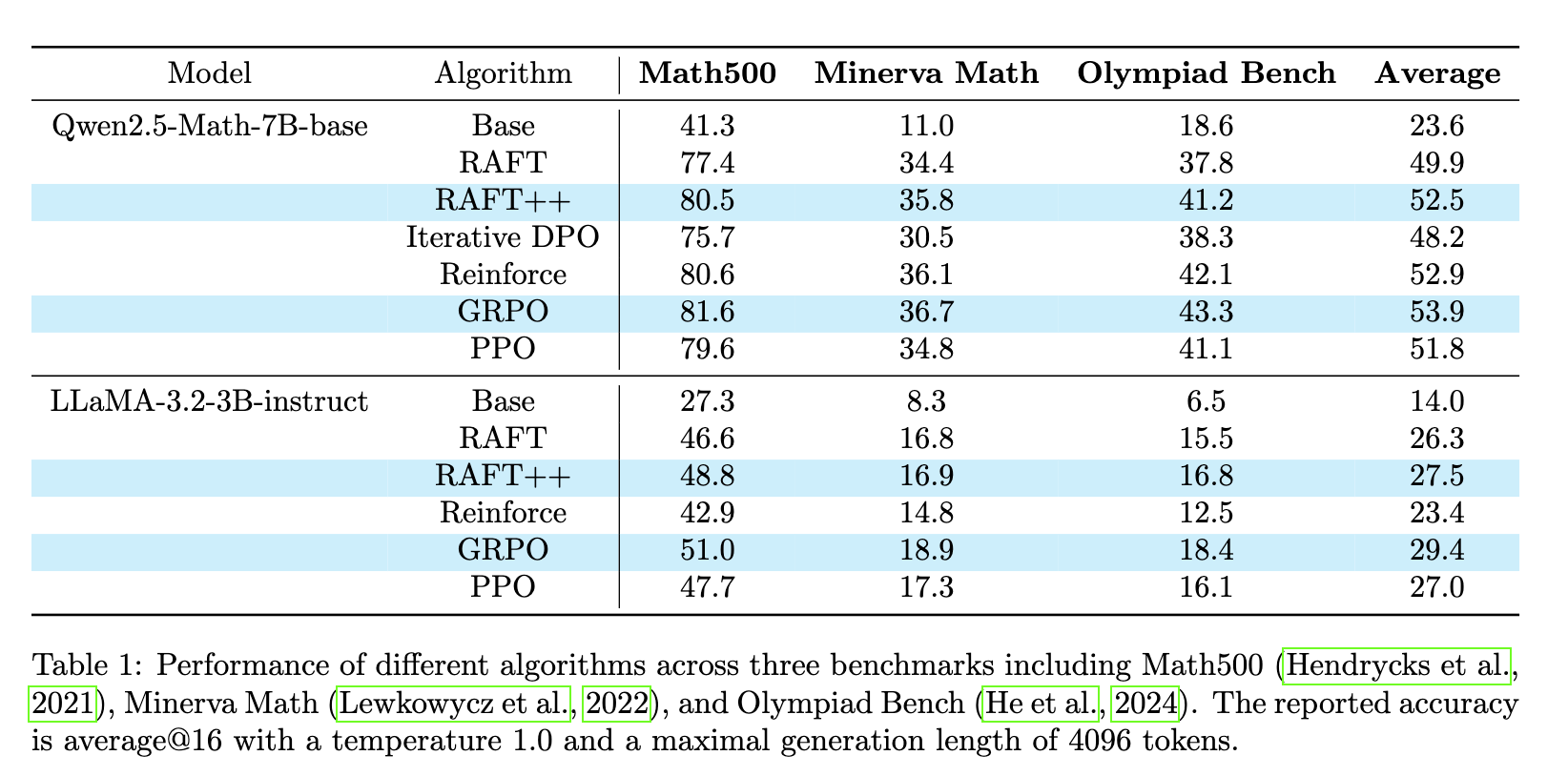
實驗洞察
- 性能優勢:在Qwen2.5 - Math - 7B - base模型上,RAFT平均準確率達49.9%,超過Iterative DPO(48.2%),接近PPO(51.8%);RAFT++進一步提升至52.5%,與GRPO的53.9%非常接近。在LLaMA - 3.2 - 3B - instruct模型上,RAFT平均準確率為26.3%,RAFT++為27.5%,均優于Reinforce(23.4%)。
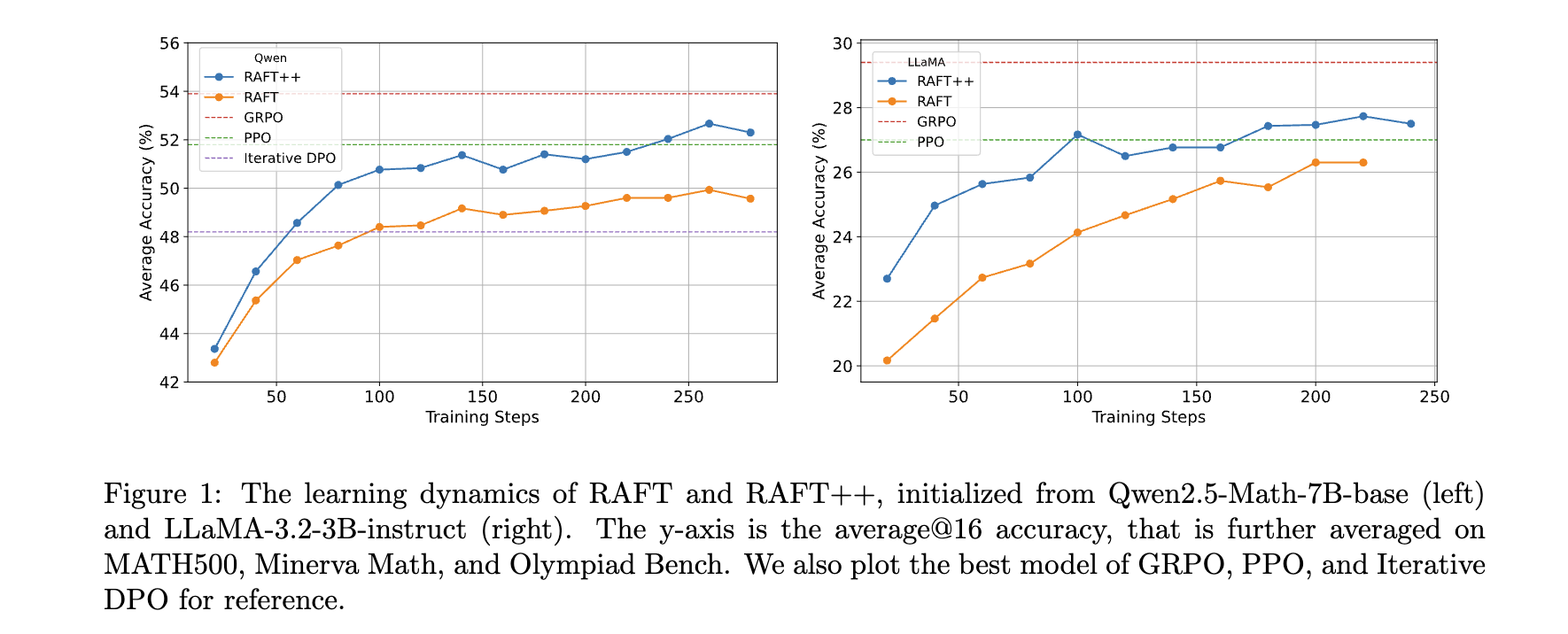
- 效率突破:RAFT++在早期訓練階段收斂速度比GRPO更快,其在訓練前期準確率提升迅速。這得益于其僅使用正樣本訓練,能快速聚焦有效信息,使模型在早期訓練中快速學習和提升性能。
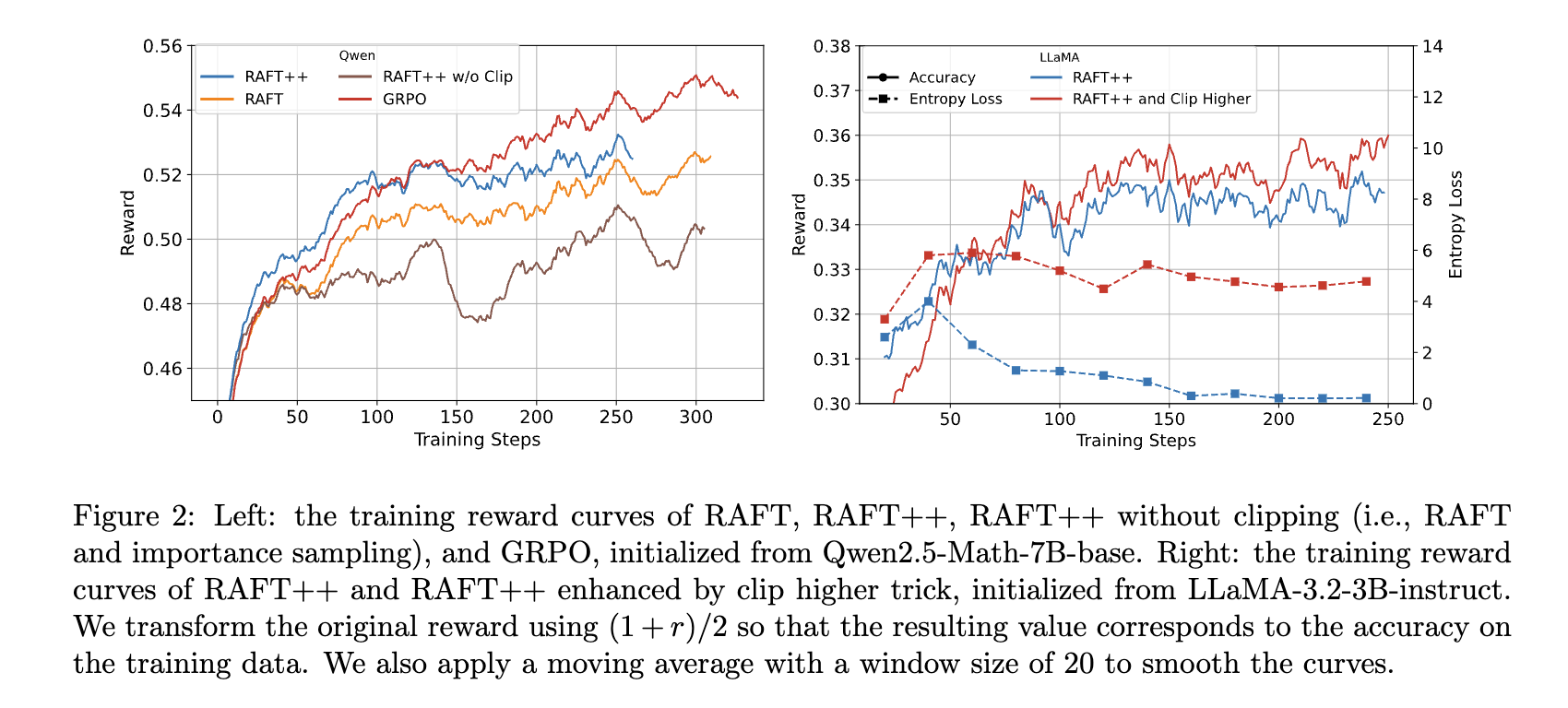
- 消融研究:研究發現從RAFT++到GRPO,RAFT++早期收斂快但后期被超越,原因是僅從正樣本學習導致策略熵快速下降,限制了探索能力。從Reinforce到GRPO的關鍵優勢在于丟棄完全錯誤的樣本,如“Reinforce + Remove all wrong”變體比Vanilla Reinforce性能提升顯著,而獎勵歸一化對性能提升貢獻較小。








)



,源碼可白嫖!)





![53.[前端開發-JS實戰框架應用]Day04-Bootstrap入門到項目實戰](http://pic.xiahunao.cn/53.[前端開發-JS實戰框架應用]Day04-Bootstrap入門到項目實戰)
