隨著人工智能的快速發展,RAG(Retrieval-Augmented Generation,檢索增強生成)技術日益受到關注。向量數據庫作為 RAG 系統的核心基礎設施,堪稱 RAG 的“記憶中樞”,其性能直接關系到大模型生成內容的精準度與實用價值。
FastGPT 作為開源 AI Agent 開發框架,集成了即開即用的數據處理和模型調用能力,用戶可通過 Flow 可視化界面靈活配置工作流,輕松實現復雜場景的快速部署。
然而,隨著應用規模的不斷擴大、數據量的持續增長,以及更高維度的向量模型(如上千維的 Embedding)和更復雜的檢索邏輯(如先按類別篩選再找相似內容)的出現,傳統數據庫在向量處理方面的局限性逐漸顯現。
為了滿足日益增長的高性能、高擴展性和高易用性需求,FastGPT 宣布正式上線 OceanBase!
OceanBase 作為一款高性能的分布式數據庫,在向量功能方面展現出了顯著優勢,是 FastGPT 向量 Embedding 存儲的更優選擇。
向量數據處理之困:傳統數據庫在 RAG 中的瓶頸
在向量數據這種 “新物種” 面前,FastGPT 原本使用的某傳統數據庫在實際應用中暴露出三大核心問題,具體表現如下:
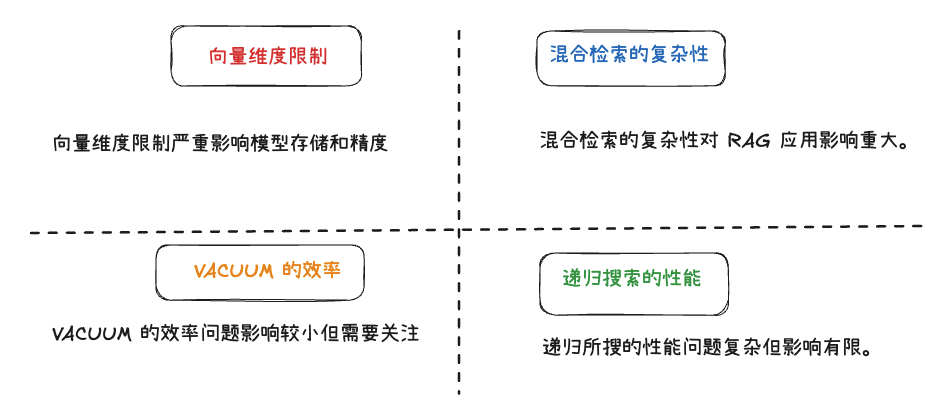
1、向量維度限制:“高維模型放不下”
當訓練完成的高性能 Embedding 模型維度達到 2048 維或更高時,傳統數據庫的 HNSW 索引僅支持最高 2000 維的全精度存儲。開發者若想使用高維模型,要么進行降維處理,而這將導致模型精度損失;要么面臨無法存儲的困境,限制模型優化空間。
2、混合檢索的 “坑”:“我想精準找,怎么這么難?”
在實際業務場景中,RAG 系統需要在特定條件下進行向量檢索。比如,僅在“技術文檔” 類別中查找與“數據庫優化” 相關的內容,這種 “先過濾、再搜索” 的需求,就是混合檢索。
然而,某傳統數據庫的 HNSW 索引缺乏原生混合過濾能力,需要先通過 HNSW 召回大量向量,再于應用層或數據庫層面進行二次過濾。這種處理方式不僅效率不佳,在數據刪改頻繁的情況下,舊數據 (死元組) 可能干擾 HNSW 的召回過程,導致過濾后關鍵數據丟失。
即便引入遞歸搜索進行優化,在實際測試中,仍存在查詢性能下降、索引失效的情況,增加 SQL 編寫復雜度,整體使用體驗不佳。
3、VACUUM?的 “痛”:“空間回收跟不上”
某傳統數據庫依賴 VACUUM 機制回收數據刪除或更新后產生的空余資源,適用于文本、數字等數據。但向量數據體量較大,單個向量可達到數 KB 以上。在大規模數據刪改更新的場景下,某傳統數據庫的 VACUUM 處理效率跟不上數據更新的速度,導致數據庫文件持續膨脹。開發者需要手動、頻繁地執行 VACUUM FULL 操作,該過程會造成鎖表,或者被迫給 Autovacuum 分配更多的系統資源,顯著增加運維成本。
?OceanBase 為 RAG 定制向量存儲方案
面對上述挑戰,OceanBase 憑借其分布式架構與創新技術,為 RAG 應用的向量數據庫提供了更具競爭力的向量存儲方案,在 FastGPT 項目升級中展現出顯著優勢:
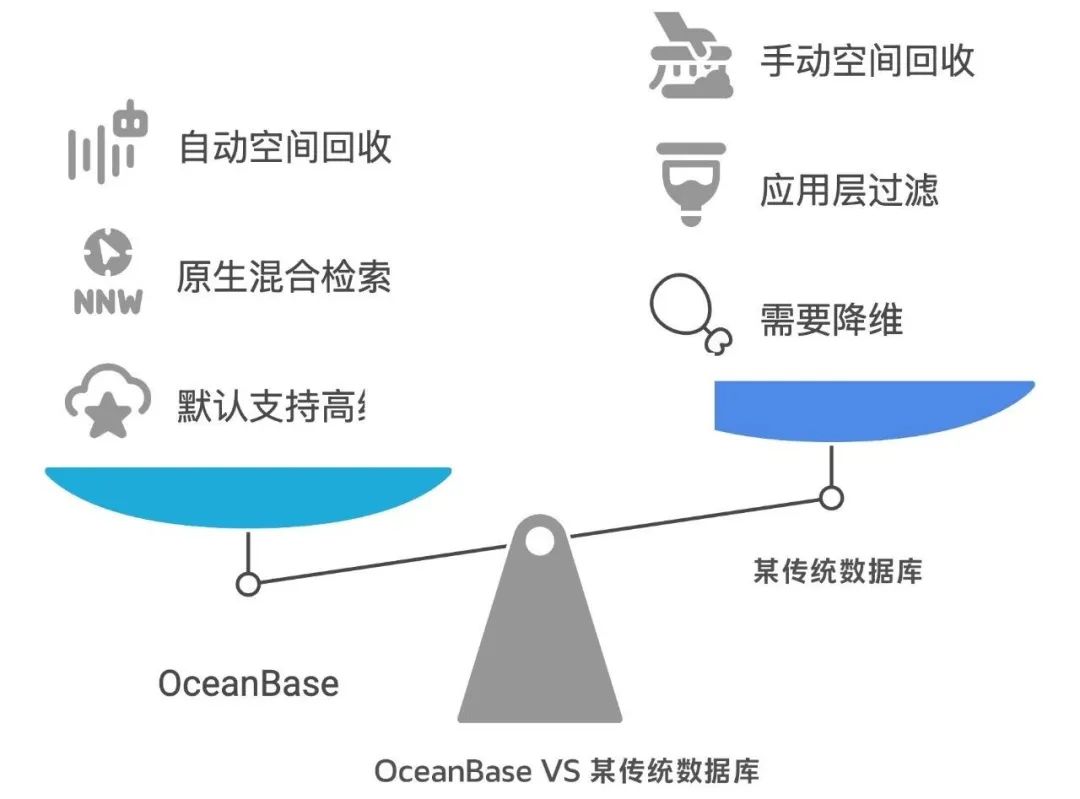
1、輕松駕馭 4096 維,還能更高!
OceanBase 的向量索引默認支持高達 4096 維的向量存儲,且該維度的上限可以通過配置靈活擴展,最高支持 16000 維的 Float 類型的稠密向量。開發者可以放心地選用更高維度的模型來追求更好的效果,不用因為數據庫限制而犧牲模型精度。
2、原生混合檢索:精準、高效,一步到位!
OceanBase 的向量索引原生支持混合檢索,可以直接在查詢時就告訴它:“嘿,幫我在 ‘這個分類’ 并且 ‘那個標簽’ 下,找和 ‘這個描述’ 最相似的向量”。OceanBase 可以在索引層面一邊進行精確的標量過濾,一邊進行高效的向量相似度搜索。這種優勢顯而易見:
👉?精準:?先框定范圍再搜索,提高查詢效率,避免數據丟失。
👉 高效:?索引層直接搜索,避免應用層二次過濾的開銷,提升查詢速度,避免索引失效,降低 SQL 開發難度。
3、空間回收更 “智能”:自動管理,省心省力!
OceanBase 基于與某傳統數據庫不同的 LSM-Tree 架構,擁有更完善、更自動化的空間回收機制,能高效處理向量數據的增刪改操作,對于向量這種體積大、更新頻繁的數據類型更加友好。
簡單來說,開發者無需再為 VACUUM 維護投入大量精力,OceanBase 會在后臺更平穩、高效地處理空間回收,減少了數據庫膨脹的煩惱,也大大減輕了運維負擔,讓開發者能更專注于業務邏輯。
OceanBase 還有一些加分項:
單表多列索引支持:OceanBase 支持在單表中對多個不同的向量列 (比如標題向量、內容向量) 建立索引,滿足復雜業務場景需求。
分布式彈性擴展:?OceanBase 作為原生分布式數據庫,在高并發、大數據量的場景下具備水平擴展能力與高可用性。雖然?FastGPT 暫時規模不大,但 OceanBase 可適應業務規模動態增長。
國產適配能力:?OceanBase 可為有國產適配需求的項目提供專業可靠的技術支撐。
綜上所述,選擇 OceanBase 作為 RAG 應用的向量數據庫,能讓開發者擁抱更高維模型、實現精準高效混合檢索、擺脫繁瑣的 VACUUM 維護,顯著提升 RAG 應用的性能、功能和易用性。
?實戰部署:基于 OceanBase 快速構建 FastGPT
準備工作:
📜 注冊并獲取 Sealos Cloud 賬號權限。
📜 熟悉 OceanBase 的基本部署概念,確認目標 OceanBase Docker 鏡像版本。官方文檔地址:
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002013494?
步驟一:在 Sealos Cloud 控制臺創建應用
登錄 Sealos Cloud (sealos.run),進入 Sealos Cloud 控制臺后,導航至?“應用管理” 或 “應用啟動臺”?功能模塊,點擊?“新建應用” 或 “創建無狀態服務”?按鈕,開始配置新的應用部署。
步驟二:配置應用基本信息與網絡
參考如圖所示界面,進行如下配置:
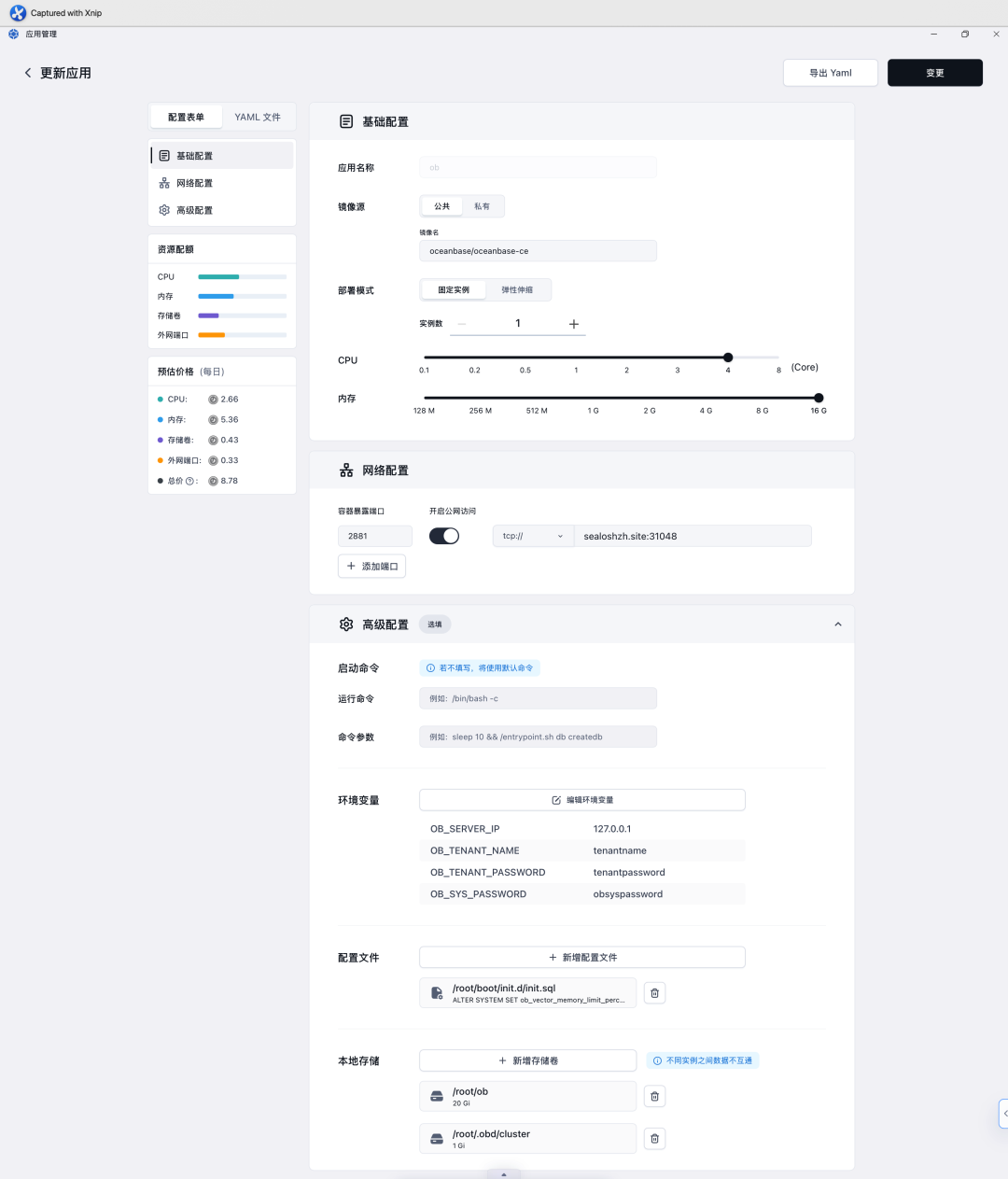
🔎?容器鏡像 (Image Name):輸入 OceanBase 數據庫 Docker 鏡像名稱。請確保鏡像是官方或可靠來源提供的,并注明版本(例如 oceanbase/oceanbase-ce)。
🔎?應用名稱 (App Name):為 OceanBase 部署設置一個易于識別的名稱。
🔎?計算資源 (CPU/內存):根據 OceanBase 的資源需求和使用場景,配置合適的 CPU 和內存資源。
🔎?網絡配置 (Network Configuration):開啟 TCP 協議端口暴露。點擊 “添加端口”,容器端口 (Container Port)?設置為 OceanBase 數據庫默認監聽的服務端口,通常是 2881。設置對應的服務端口 (Service Port)?并選擇適當的?暴露方式 (Exposure Method)(例如選擇公網暴露,以便外部客戶端連接到您的數據庫)。
步驟三:配置環境變量
在?“高級設置” 或 “環境變量”?區域,根據 OceanBase Docker 鏡像的官方文檔,添加啟動和配置 OceanBase 實例所需的環境變量。例如:
💡 OB_SERVER_IP: OceanBase 節點的服務 IP 地址。
💡 OB_TENANT_NAME: 要創建或連接的租戶名稱。
💡 OB_TENANT_PASSWORD: 租戶的密碼。
💡 OB_SYS_PASSWORD: SYS 租戶的密碼(用于管理)。
步驟四:配置持久化存儲
🔑 數據庫的數據、日志等核心文件需要持久化存儲,以防止容器重啟或刪除導致數據丟失。
🔑 在?“本地存儲” 或 “持久化存儲”?區域,參考下圖所示的掛載配置,為 OceanBase 容器掛載持久化存儲卷。
🔑 點擊?“添加存儲卷”,選擇或創建一個存儲卷,并將其掛載到 OceanBase 容器內部存放數據、日志和配置文件的關鍵路徑。請務必查閱 OceanBase 鏡像的官方文檔,確認需要掛載哪些具體的路徑。
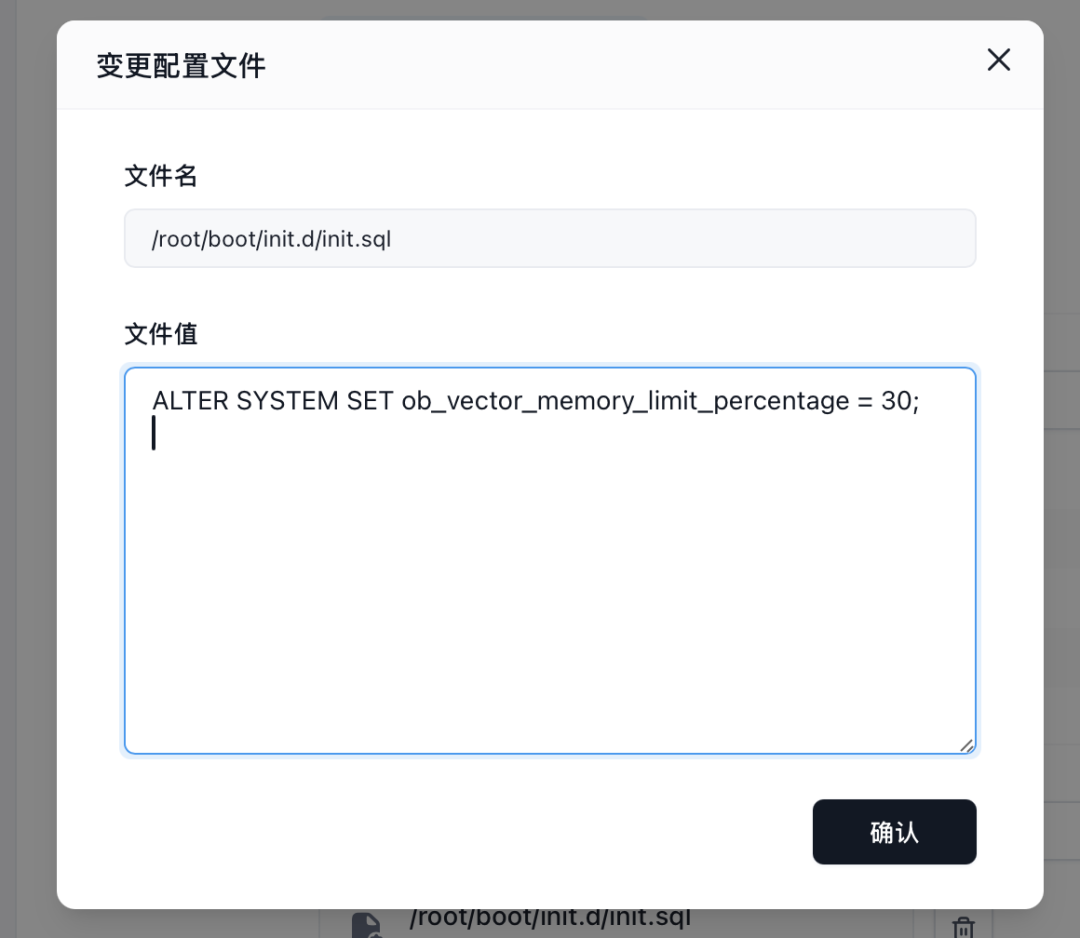
步驟五:仔細檢查所有配置項
包括鏡像名、資源、端口、環境變量和存儲掛載路徑,確保信息準確無誤。
🔧 點擊頁面底部的?“部署” 或 “啟動”?按鈕。
🔧 Sealos 將開始拉取 OceanBase 鏡像,并根據配置創建并啟動容器。數據庫啟動和初始化過程可能需要一些時間。
步驟六:驗證部署并連接數據庫
🔔 部署成功后,在 Sealos 控制臺的應用詳情頁面查看 OceanBase 應用實例的狀態。
🔔 查看日志輸出,確認 OceanBase 數據庫已成功啟動并完成初始化。
🔔 獲取 Sealos 分配的對外訪問地址(URL)和端口。
🔔 使用 OceanBase 客戶端工具(如 ODC - OceanBase Developer Center 或命令行客戶端 obclient)連接到該地址和端口,并使用在環境變量中設置的用戶名和密碼來訪問和管理 OceanBase 數據庫。
將 FastGPT 連接到此 OceanBase 實例
按照上述步驟成功部署并驗證了 OceanBase 數據庫后,接下來可以在 Sealos Cloud 上部署 FastGPT 應用,并將其配置為使用此 OceanBase 實例作為數據存儲。
重要參考文檔:
📕 FastGPT 官方文檔:?
https://doc.fastgpt.cn/docs/
📕 FastGPT GitHub Docker 示例 (OceanBase):
https://github.com/labring/FastGPT/tree/main/deploy/docker/docker-compose-oceanbase
技術融合:OceanBase 與 FastGPT 共探 AI 時代
OceanBase 與 FastGPT 的深度融合,標志著 RAG 應用在向量存儲領域進入全新發展階段。通過 OceanBase 的技術賦能,開發者可以突破傳統架構限制,實現更高維度的模型應用、更精準高效的檢索能力,以及更智能的運維管理。
這種技術創新不僅為 AI 應用開發者提供了更優的解決方案,也為金融、政務、醫療等行業的智能化升級注入新動能。未來,雙方將持續深化技術合作,共同探索向量數據庫在更多復雜場景下的創新應用,推動 RAG 技術生態的繁榮發展。


)


)




——電子制造行業趨勢分析案例)
merge 操作有多種方法)


接入華為云iotDA平臺的路徑元素有哪些不同?)

-Redis 基本知識及五大數據類型)

