引入
我們通過Flink相關論文的介紹,對于Flink已經有了初步理解,這里簡單的梳理一下Flink常見的部署方式。
Flink 的部署方式?
StandAlone模式
介紹
StandAlone模式是Flink框架自帶的分布式部署模式,不依賴其他的資源調度框架,特點:
- 分布式多臺物理主機部署
- 依賴于Java8或Java11JDk環境
- 僅支持Session模式提交Job
- 支持高可用配置
但是有以下缺點:
- 資源利用彈性不夠(資源總量是定死的;job退出后也不能立刻回收資源)
- 資源隔離度不夠(所有job共享集群的資源)
- 所有job共用一個jobmanager,負載過大
- 只能運行Flink程序,不能能運行其他的編程模型
OnYarn模式
介紹
YARN是一個通用的資源調度框架,特點是:
- 可以運行多種編程模型,例如MR、Storm、Spark、Flink等
- 性能穩定,運維經驗豐富
- 靈活的資源分配和資源隔離
- 每提交一個application都會有一個專門的ApplicationMater(JobManager)
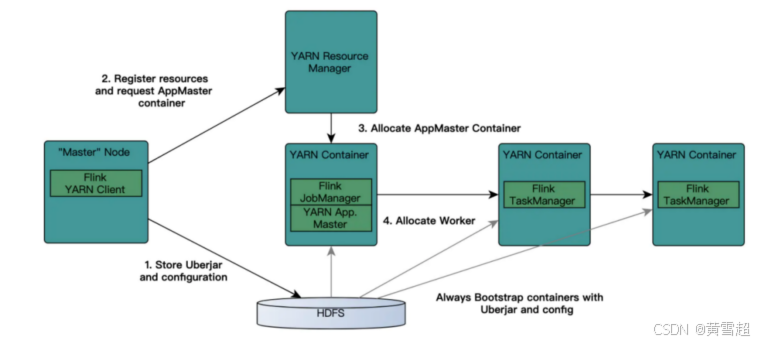
ResouManager(NM):
- 負責處理客戶端請求
- 監控NodeManager
- 啟動和監控APPlicationMaster
- 資源的分配和調度
NodeManager:
- 管理單個Worker節點上的資源
- 處理來自ResourceManager的命令
- 處理來自ApplicationMaster的命令
- 匯報資源狀態
ApplicationMaster:
- 負責數據的切分
- 為應用申請計算資源,并分配給Task
- 任務的監控與容錯
- 運行在Worker節點上?
Container:
- 資源抽象,封裝了節點上的多維度資源,如CPU,內存,網絡資源等
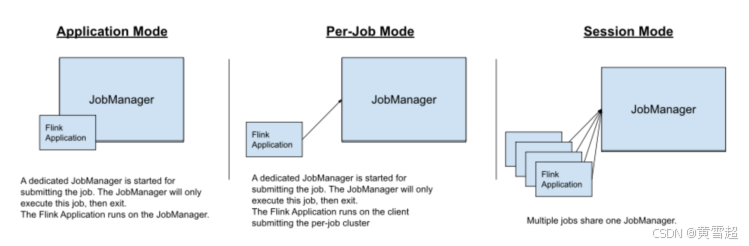
Flink On Yarn 的三種模式
Flink程序可以運行為以下3種模式:
- Application Mode【生產中建議使用的模式】:每個job獨享一個集群,job退出集群則退出,用戶類的main方法在集群上運行
- Per-Job Mode:每個job獨享一個集群,job退出集群則退出,用戶類的main方法在client端運行;(大job,運行時長很長,比較合適;因為每起一個job,都要去向yarn申請容器啟動jm,tm,比較耗時)
- Yarn Session Mode:多個job共享同一個集群<jobmanager/taskmanager>、job退出集群也不會退出,用戶類的main方法在client端運行;(需要頻繁提交大量小job的場景比較適用;因為每次提交一個新job的時候,不需要去向yarn注冊應用)
上述3種模式的區別點在:
集群的生命周期和資源的隔離保證
用戶類的main方法是運行在client端,還是在集群端
yarn application模式提交
bin/flink run-application -t yarn-application \
-yjm 1024 -yqu default -ys 2 \
-ytm 1024 -p 4 \
-c com.chaos.flink.java.KafkaSinkYarn /root/flink_test-1.0.jar
- bin/flink run-application :這是用于運行 Flink 應用程序的命令入口。
- -t yarn-application :指定在 YARN 集群上運行應用程序。
- -yjm 1024 :設置 JobManager 的內存大小為 1024 MB。
- -yqu default :指定 YARN 隊列的名稱為 default。
- -ys 2 :設置 YARN 服務,這里可能是指 YARN 的一些特定配置,比如在 YARN 上運行的實例數量。
- -ytm 1024 :設置 TaskManager 的內存大小為 1024 MB。
- -p 4 :設置 Flink 作業的并行度為 4。
- -c com.chaos.flink.java.KafkaSinkYarn :指定主類的完整類名為 com.chaos.flink.java.KafkaSinkYarn,這是應用程序的入口類。
- /root/flink_test-1.0.jar :指定要運行的 Flink 應用程序的 JAR 包路徑。?
yarn perJob模式提交
Yarn-Per-Job 模式:每個作業單獨啟動集群,隔離性好,JM(JobManager) 負載均衡,main 方法在客戶端執行。在 per-job 模式下,每個 Job 都有一個 JobManager,每個TaskManager 只有單個 Job。 ?
特點: 一個任務會對應一個 Job,每提交一個作業會根據自身的情況,都會單獨向 yarn申請資源,直到作業執行完成,一個作業的失敗與否并不會影響下一個作業的正常提交和運行。獨享 Dispatcher 和 ResourceManager,按需接受資源申請;適合規模大長時間運行的作業。
提交命令 (申請容器啟動flink集群以及提交job,是合二為一的)
bin/flink run -m yarn-cluster -yjm 1024 \
-ytm 1024 -yqu default -ys 2 ? -p 4 \
-c com.chaos.TaskDemo ?/root/flink_test-1.0.jar
- -m:master的運行模式
- -yjm:JobManager的所在Yarn容器的內存大小
- -ytm:TaskManager的所在Yarn容器額內存大小
- -yqu:Yarn任務隊列的名稱
- -ys:每個TaskManager的slot數量
- -p:并行度
- -c:main方法全類名
yarn session模式提交
Yarn-Session 模式:所有作業共享集群資源,隔離性差,JM 負載瓶頸,main 方法在客戶端執行。適合執行時間短,頻繁執行的短任務,集群中的所有作業 只有一個 JobManager,另外,Job 被隨機分配給 TaskManager ?
特點: Session-Cluster 模式需要先啟動集群,然后再提交作業,接著會向 yarn 申請一塊空間后,資源永遠保持不變。如果資源滿了,下一個作業就無法提交,只能等到 yarn 中的其中一個作業執行完成后,釋放了資源,下個作業才會正常提交。所有作業共享 Dispatcher 和 ResourceManager;共享資源;適合規模小執行時間短的作業。
- 基本操作命令
# 提交命令: bin/yarn-session.sh –help# 停止命令: yarn application -kill application_1550836652097_0002 - 具體操作步驟
- 先開辟資源啟動session模式集群
# 老版本:? bin/yarn-session.sh -n 3 -jm 1024 -tm 1024 # -n --> 指定需要啟動多少個Taskmanager# 新版本:? bin/yarn-session.sh -jm 1024 ?-tm 1024 ?-s 2 ?-m yarn-cluster -ynm hello -qu default?-jm:jobmanager memory ? -tm:taskmanager memory -m yarn-cluster:集群模式(yarn集群模式) -s:規定每個taskmanager上的taskSlot數(槽位數) -nm:自定義appliction名稱 -qu:指定要提交到的yarn隊列 - 啟動的服務進程
YarnSessionClusterEntrypoint(AppMaster,即JobManager)
注意:此刻并沒有taskmanager,也就是說,taskmanager是在后續提交job時根據資源需求動態申請容器啟動的。 - 向已運行的session模式集群提交job
bin/flink run -d -yid application_1550579025929_62420 -p 4 -c com.chaos.flink.java.TaskDemo /root/flink_test-1.0.jar
- 先開辟資源啟動session模式集群
Flink On Yarn 的優劣勢
優勢:
- 與現有大數據平臺無縫對接(Hadoop2.4+)
- 部署集群與任務提交都非常簡單
- 資源管理統一通過Yarn管理,提升整體資源利用率類
- 基于Native方式,TaskManager資源按需申請和啟動,防止資源浪費
- 容錯保證:借助于Hadoop Yarn提供的自動failover機制,能保證JobManager,TaskManager節點異常恢復
劣勢:
- 資源隔離問題,尤其是網絡資源的隔離,Yarn做的還不夠完善
- 離線和實時作業同時運行相互干擾等問題需要重視
- Kerberos認證超期問題導致Checkpoint無法持久化
On?Kubernetes模式
介紹
Flink on Kubernetes 是將 Apache Flink 部署在 Kubernetes 集群上的一種方式,使用戶能夠利用 Kubernetes 的強大功能進行資源管理、彈性伸縮和高可用性管理。
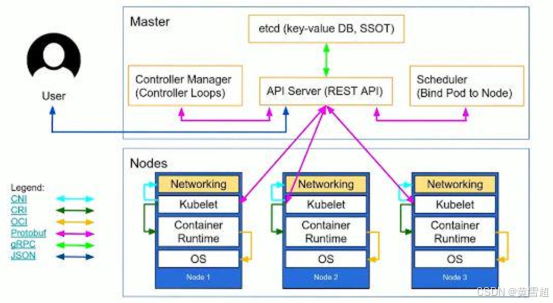
Master節點:
- 負責整個集群的管理,資源管理
- 運行APIServer,ControllerManager,Scheduler服務
- 提供Etcd高可用鍵值存儲服務,用來保存Kubernetes集群所有對象的狀態信息和網絡信息
Node:
- 集群操作的單元,Pod運行宿主機
- 運行業務負載,業務負載會以Pod的形式運行
Kubelet:
- 運行在Node節點上,維護和管理該Node上的容器
Container Runtime:
- Docker容器運行環境,負責容器的創建和管理
Pod:
- 運行在Node節點上,多個相關Container的組合
- Kubunetes創建和管理的最小單位
核心概念
- ReplicationController(RC):RC是K8s集群中最早的保證Pod高可用的API對象,通過監控運行中的Pod來保證集群中運行指定數目的Pod副本。
- Service:Service是對一組提供相同功能的Pods的抽象,并為它們提供一個統一的入口。
- PersistentVolume(PV):容器的數據都是非持久化的,在容器消亡以后數據也跟著丟失,所以Docker提供了Volume機制以便將數據持久化存儲。
- ConfigMap:ConfigMap用于保存配置數據的鍵值對,可以用來保存單個屬性,也可以用來保存配置文件。
Flink On Kubunetes的三種模式
Session 模式:啟動一個長期運行的 Flink 集群,所有作業共享該集群資源。適合多個作業需要共享資源的場景。
Application 模式:為每個作業啟動一個獨立的 Flink 集群,作業之間資源隔離,互不影響。
Native Kubernetes 模式:Flink 原生支持 Kubernetes,通過 Kubernetes API 進行資源管理和調度,能夠動態分配和釋放 TaskManager。
Flink On Kubunetes的優缺點
優點:
-
強大的資源管理與彈性伸縮:Kubernetes 可根據作業負載動態分配和釋放資源,實現 Flink 集群的彈性伸縮。這提高了資源利用率,降低了成本,尤其在業務波動時可快速調整資源以滿足需求。
-
高可用性與容錯能力:Kubernetes 能自動重啟故障 Pod 并重新調度 TaskManager,確保 Flink 作業持續運行,保障數據處理的可靠性和穩定性。
-
深度云原生集成:Flink on Kubernetes 與云原生生態系統深度融合,可與云服務(如對象存儲、消息隊列)無縫協作,便于構建完整的云原生數據處理解決方案。
-
簡化的部署與運維:通過 Flink Kubernetes Operator 提供的抽象接口,用戶可以更高效地部署和管理 Flink 集群,減少手動操作,降低運維負擔。
-
多租戶支持:Kubernetes 的命名空間功能可實現多租戶隔離,為多團隊或項目共用集群提供了便利,提高了資源的隔離性和安全性。
缺點:
-
部署復雜度增加:與在專用集群上部署 Flink 相比,Flink on Kubernetes 需要熟悉 Kubernetes 的概念和工具(如 Pod、Deployment、Service 等),增加了學習曲線和部署前的準備工作。
-
資源管理的潛在挑戰:Kubernetes 的資源調度策略可能與 Flink 的需求不完全匹配,導致資源分配效率降低。例如,在某些情況下,Kubernetes 的默認調度算法可能無法滿足 Flink 對數據本地性的要求,影響作業性能。
-
性能開銷:在 Kubernetes 上運行 Flink 會引入額外的性能開銷,包括容器的啟動時間和 Kubernetes 的調度延遲。此外,如果 Kubernetes 集群的資源緊張,可能導致 Flink 作業的性能下降。
-
網絡配置復雜性:在 Kubernetes 集群中,網絡配置可能較為復雜,需要確保 Flink 的各個組件之間能夠正確通信。
-
長期運行作業的資源管理:對于長期運行的 Flink 作業,需要持續監控和管理資源使用情況。Kubernetes 的資源配額和限制機制可以幫助控制資源使用,但需要合理配置以避免對作業的性能產生負面影響。
?



)





:從.svg 到 SVG Vue 組件的高效蛻變?)


)






