深度強化學習 pdf
百度云
hea4
pdf
主頁
概念
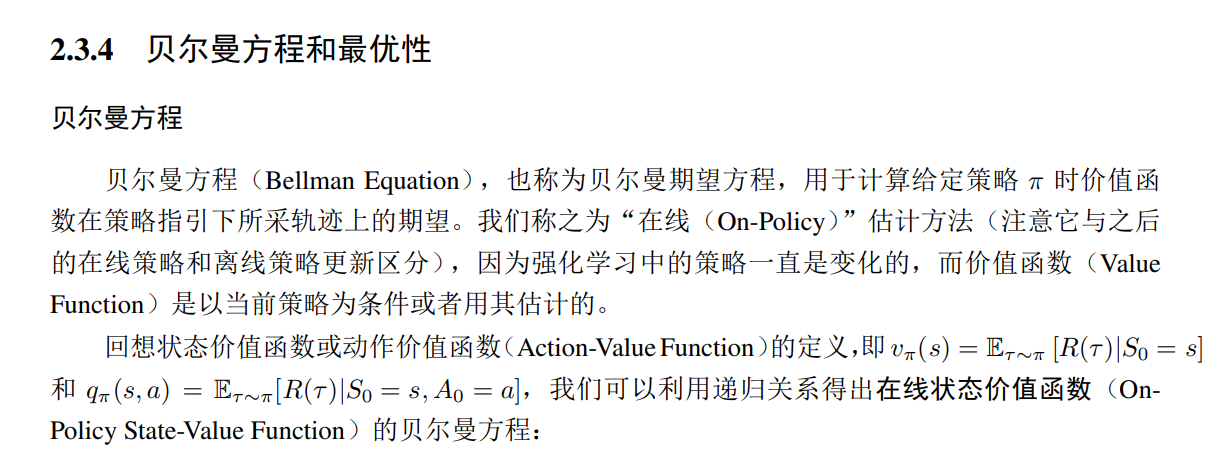
- 馬爾可夫獎勵過程和價值函數估計的結合產生了在絕大多數強化學習方法中應用的核心結果——貝爾曼
(Bellman)方程。 - 最優價值函數和最優策略可以通過求解貝爾曼方程得到,還將介紹三種貝爾曼
方程的主要求解方式:- 動態規劃(Dynamic Programming)
- 蒙特卡羅(Monte-Carlo)方法
- 時間差分(Temporal Difference)方法。
我們進一步介紹深度強化學習策略優化中對 策略 和 價值 的擬合。
策略優化的內容將會被分為兩大類:
- 基于價值的優化
- 基于策略的優化。
在基于價值的優化中,我們介紹基于梯度的方法,如使用深度神經網絡的深度 Q 網絡(Deep Q-Networks);
在基于策略的優化中,我們詳細介紹確定性策略梯度(Deterministic Policy Gradient)和隨機性策略梯度(Stochastic Policy Gradient),并提供充分的數學證明。
結合基于價值和基于策略的優化方法產生了著名的 Actor-Critic 結構
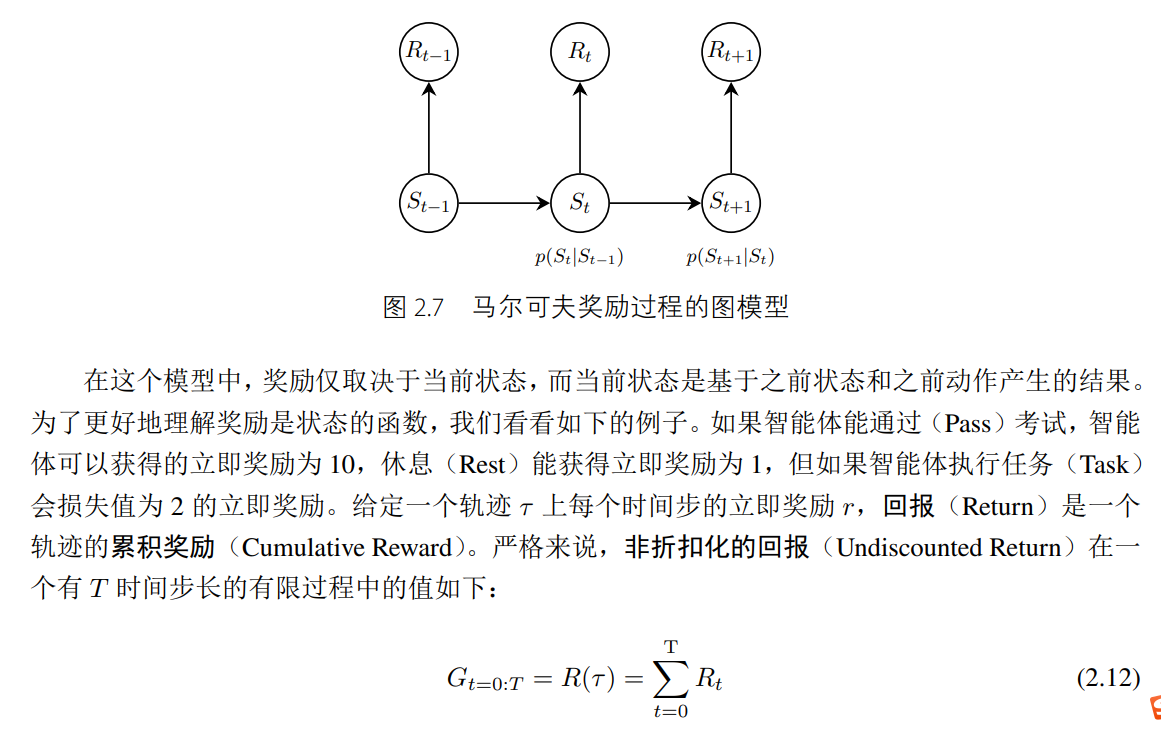
在線預測(Online Prediction)問題是一類智能體需要為未來做出預測的問題。假如你在夏威夷度假一周,需要預測這一周是否會下雨;或者根據一天上午的石油價格漲幅來預測下午石油的價格。在線預測問題需要在線解決。在線學習和傳統的統計學習有以下幾方面的不同:
- 樣本是以一種有序的(Ordered)方式呈現的,而非無序的批(Batch)的方式。
- 我們更多需要考慮最差情況而不是平均情況,因為我們需要保證在學習過程中隨時都對事
情有所掌控。 - 學習的目標也是不同的,在線學習企圖最小化后悔值(Regret),而統計學習需要減少經驗
風險。我們會稍后對后悔值進行介紹。
對于展示探索-利用的權衡問題,MAB 可以作為一個很好的例子。當我們已經對一些狀態的q 值進行估計之后,如果一個智能體一直選擇有最大 Q 值的動作的話,那么這個智能體就是貪心的(Greedy),因為它一直在利用已經估計過的 q 值。如果一個智能體總是根據最大化 Q 值來選取動作,那么我們認為這樣的智能體是有一定探索(Exploration)性的。只做探索或者只對已有估計值進行利用(Exploitation),在大多數情況下都不能很好地改善策略。
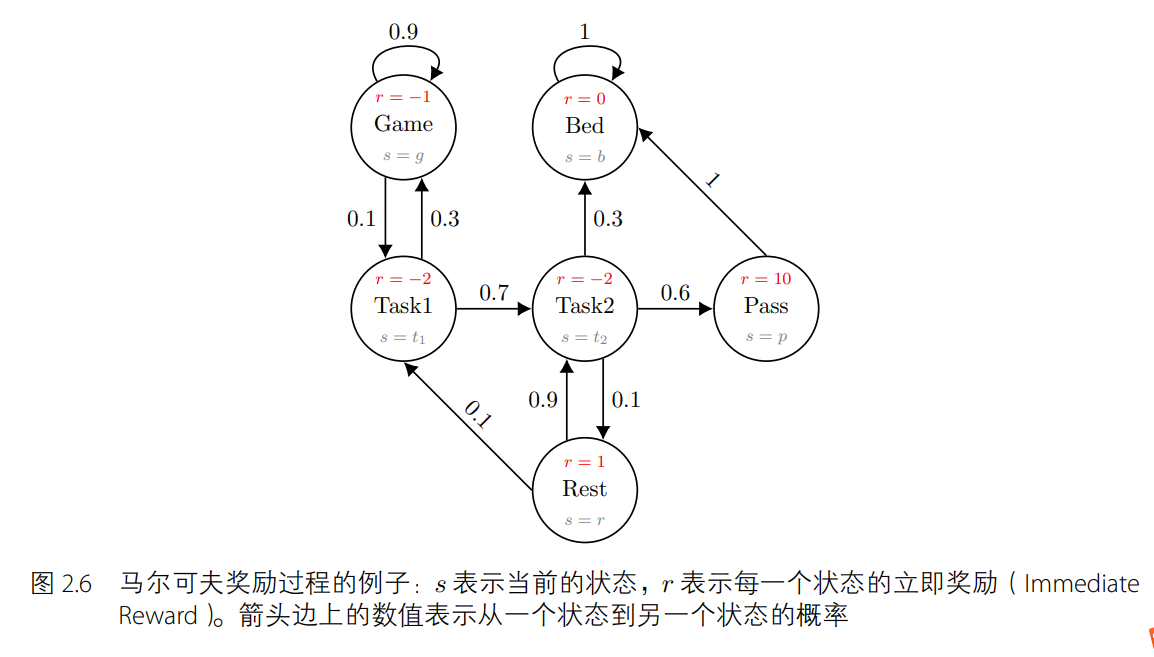
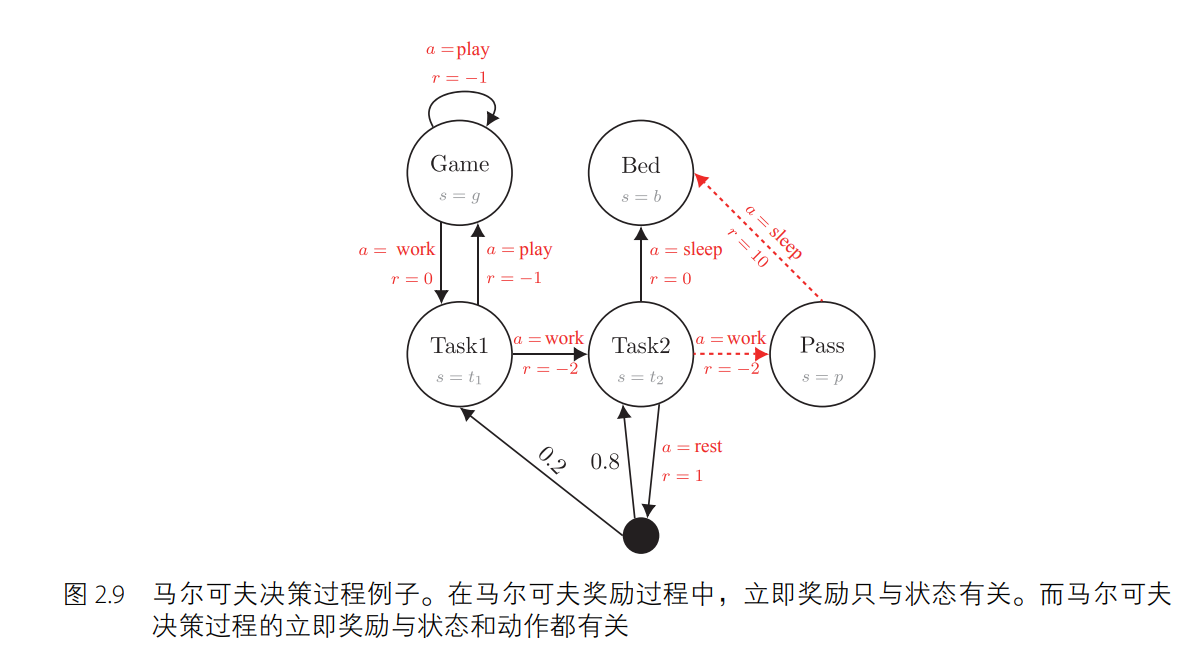
在模擬序列決策過程的問題上,馬爾可夫決策過程比馬爾可夫過程和馬爾可夫獎勵過程要好用。如圖 2.9 所示,和馬爾可夫獎勵過程不同的地方在于,馬爾可夫獎勵過程的立即獎勵只取決于狀態(獎勵值在節點上),而馬爾可夫決策過程的立即獎勵與狀態和動作都有關(獎勵值在邊上)。同樣地,給定一個狀態下的一個動作,馬爾可夫決策過程的下一個狀態不一定是固定唯一的。舉例來說,如圖 2.10 所示,當智能體在狀態 s = t2 時執行休息(rest)動作后,下一時刻的狀態有 0.8 的概率保留在狀態 s = t2 下,有 0.2 的概率變為 s = t1。
馬爾科夫性質,馬爾科夫過程,馬爾科夫獎勵過程,馬爾科夫決策過程


馬爾可夫過程是一個具備馬爾可夫性質
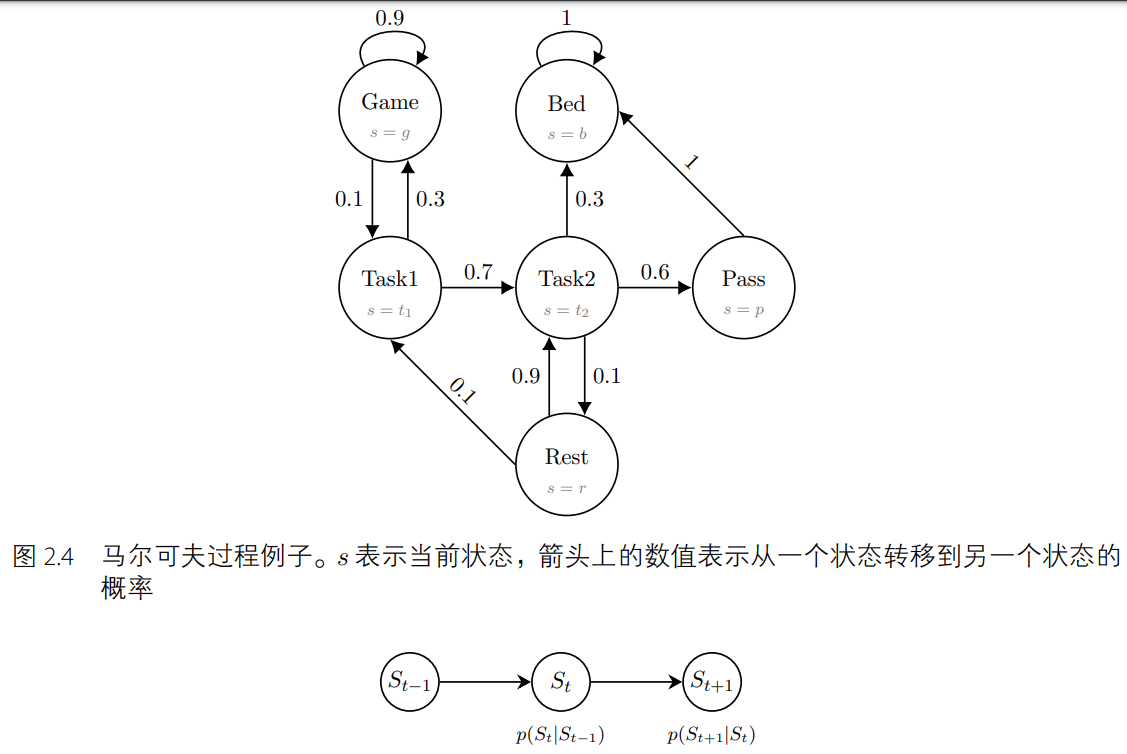
馬爾可夫過程(Markov Process,MP)是一個具備馬爾可夫性質(Markov Property)的離散隨機過程(Discrete Stochastic Process)。圖 2.4 展示了一個馬爾可夫過程的例子。每個圓圈表示一個狀態,每個邊(箭頭)表示一個狀態轉移(State Transition)。這個圖模擬了一個人做兩種不同的任務(Tasks),以及最后去床上睡覺的這樣一個例子。為了更好地理解這個圖,我們假設這個人當前的狀態是在做“Task1”,他有 0.7 的概率會轉到做“Task2”的狀態;如果他進一步從“Task2”以 0.6 的概率跳轉到“Pass”狀態,則這個人就完成了所有任務可以去睡覺了,因為“Pass”到“Bed”的概率是 1。


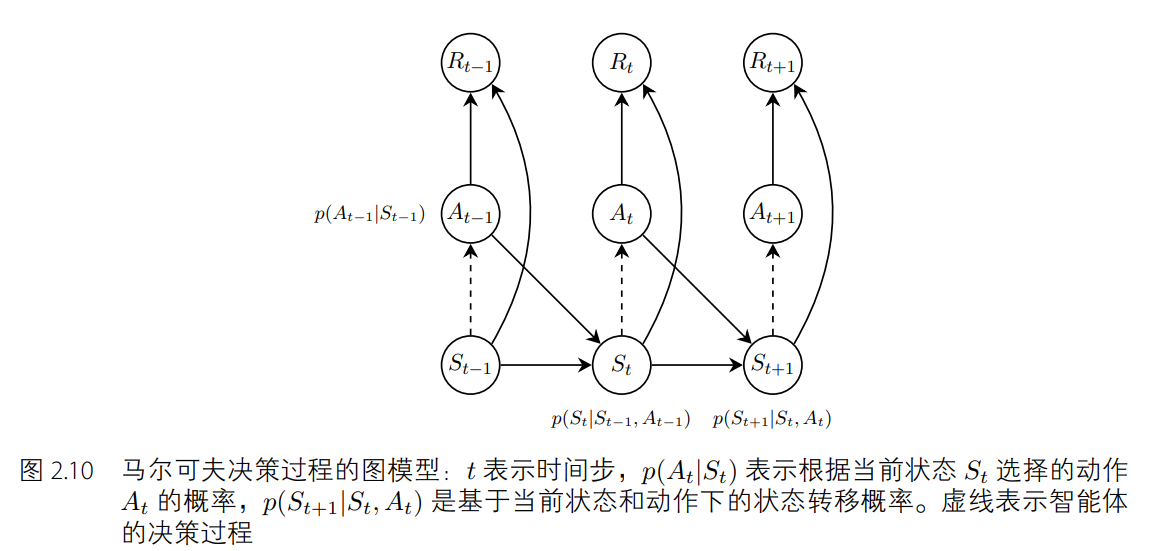


我們知道馬爾可夫決策過程是基于馬爾可夫性質的,滿足p(Xt+1| Xt, · · · , X1) = p(Xt+1|Xt),其中 Xt 是 t 時刻的隨機變量,這意味著隨機變量 Xt 的時間相關性只取決于上一個時刻的隨機變量 Xt?1。而 O-U 噪聲就是一個具有時間相關性的隨機變量,這一點與馬爾可夫決策過程的性質相符,因此很自然地被運用到隨機噪聲的添加中。然而,實踐表明,時間不相關的零均值高斯噪聲也能取得很好的效果。




)

:實戰篇——OSSClient泄漏引發的FullGC風暴)










:數據庫)
)



