1.DML data manage language數據庫管理語言
外鍵:外鍵是什么?就是對其進行表與表之間的聯系,就是使用的鍵進行關聯!
方法一:我們在數據庫里面就對其進行表與表之間的連接【這種是不建議的,我不太喜歡就是將數據里面弄得很復雜,數據庫就是對其存儲數據就行,這種物理外鍵不建議,我們可以執行使用軟件程序方面對其進行操作就行,本質上面就是一個篩選的過程!
可以參考一下這個文章,解釋了為什么不能用外鍵】
create table if not exists grade (id int not null auto_increment comment '學生id',name varchar(10) not null default '匿名' comment '學生名字',primary key (id)
);
alter table student addconstraint fk_student_grade foreign key (id) references grade (id);
-- alter table 表 add constraint 外鍵名 foreign key (字段名) references 主表名(主鍵字段名);方法二:軟件層面(后面我才開始介紹!應用層面的時候會進行介紹!)
下面就開始介紹數據庫的操作!
增:(為了加上記憶,就是你要添加(insert into),你先需要先說明你哪個表(student),表里面的哪個字段(字段1,字段2....),然后在對字段進行添加(值1,值2...))
-- insert into 表(字段1,字段2...) values (值1,值2...);
-- 主鍵是自增的不需要對其進行定義
-- 字段需要和后面的值一一對應
insert into student (name, password, sex, birthday, address, email)
values ('張三', '123456', '男', '1999-01-01', '北京', 'zhangsan@qq.com');
insert into student (name, password, sex, birthday, address, email)
values ('李四', '15951', '男', '1999-01-01', '四川', 'lisi@qq.com');刪:(首先我們需要對其進行要進行刪除,要找到對應的表(delete? from student),當然你不能不加條件對其刪除,那最終導致的結果就會全部進行刪除(where id = 3))
-- delete from 表名 where 條件;
delete from student where id = 3;改(你要對其進行修改,首先你需要設置條件然后對其進行尋找(where id= 2),然后選擇表對其進行修改 (update student),選擇字段進行修改 set 字段 = ‘修改 ’ )
-- update 表名 set 字段1 = 值1,字段2 = 值2... where 條件;
update student set name = '李化' where id = 2;
update student set password = '123', sex = '女' where id = 3;
update student set name = '李化', password = '123' where id = 3 and sex = '女';
update student set name = '李化化', password = '123' where id = 3 or sex = '男'; -- 這里表示就是男或者id為3,都需要對其進行修改!!!這里面稍微需要注意一點就是where里面是進行條件的,換句話說就是一些操作符
大于小于等于不等于(不說了噻!)
between..and..(范圍)
and,or
2.DQL data quire language數據庫查詢語言
(查詢毋庸置疑是最重要的,因為大部分我們的數據庫是進行查詢的)
2.1.最簡單就是查詢表里面的所有內容,對于數據庫表達式列的處理!
-- 語法:select 字段 from 表名;
select * from student;
-- 可以起別名,便于好看
select sex as '性別' from student as s;
-- 使用函數
select concat('性別:', sex) as '性別' from student;
-- 進行去重
select distinct sex from student;2.2where條件查詢
2.2.1與或非
select name as '名字' from student where address = '北京'and sex = '男';2.2.2模糊查詢
還有什么 is null 或者is not null
| 運算符 | 語法 | 描述 |
| like | a like b | 就相當于就是 ‘小紅’ like ‘小紅。。。。’ |
| in | a in (b1,b2.。) | 就相當于就是‘a’ i在這里面 |
-- where條件進行查詢
select name as '名字' from student where address = '北京'and sex = '男';
-- 模糊查詢
-- like
-- %表示任意字符,_表示一個字符
-- 查看張姓的人
select name as '名字' from student where name like '張%';-- 查看張姓的第二個人
select name as '名字' from student where name like '張_';-- 查看中間一個字為‘佳’
select name as '名字' from student where name like '%佳%';-- in
-- 查詢地址子在北京和上海的人
select name as '名字' from student where address in ('北京', '上海');2.3.聯表查詢(join連接)
聯表查詢主要分為三個:
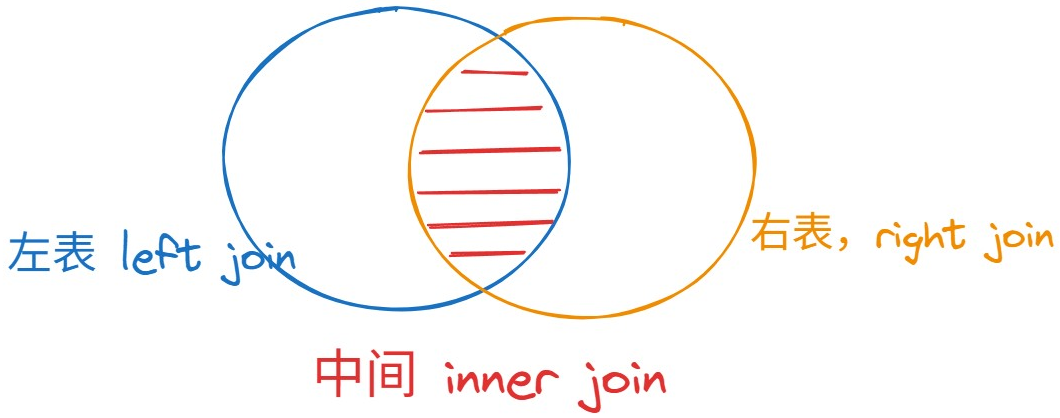
inner join:只要滿足要求就進行匹配
select name,s.address,st.des
from student as s
inner join status as st
where s.address = st.address ;right join:(其實就是必須包含右邊的東西,然后再進行篩選)
select name,s.address,st.des
from student as s
right join status as st
on s.address = st.address ;left join:(其實就是必須包含左邊的東西,然后再進行篩選)
select name,s.address,st.des
from student as s
left join status as st
on s.address = st.address ;小結一下:(我們做一個綜合的案例)
首先我們創建四個表,學生,老師,課程,成績,并對其進行數據填寫!
-- ==================學生=========================
create table if not exists student
(s_no varchar(21) not null primary key comment '學號',s_name varchar(12) not null comment '學生姓名',s_age tinyint unsigned not null comment '學生年齡',s_sex enum ('1','0') default '1' comment '學生性別',s_birthday datetime comment '學生生日',class varchar(10) not null comment '學生班級'
);insert into student(s_no, s_name, s_age, s_sex, s_birthday, class)
values (1, '李洋', 18, '1', 19980422, '1'),(2, '溫俊林', 19, '0', 19970422, '1'),(3, '周恒華', 20, '1', 19950422, '1'),(4, '張松濤', 22, '1', 19940422, '2'),(5, '李暉', 20, '0', 19960622, '2'),(6, '包政', 23, '1', 19930422, '2');-- ==================課程=========================
create table if not exists course
(cno varchar(21) not null primary key comment '課程號',cname varchar(10) not null comment '課程名稱',tno varchar(10) not null comment '教師編號'
);insert into course(cno, cname, tno)
values ('1', 'linux', '001'),('2', 'linux', '002'),('3', 'python', '003');-- ==================分數=========================
create table if not exists score
(sno varchar(21) not null primary key comment '學號',cno varchar(21) not null comment '課程號',mark float(4, 1) not null comment '成績'
);insert into score(sno, cno, mark)
values ('1', '1', '99.5'),('2', '1', '80.5'),('3', '1', '85.5'),('4', '1', '84.5'),('5', '1', '89.5'),('6', '1', '89.5');-- ==================老師=========================
create table if not exists teacher
(t_no varchar(21) not null primary key comment '教師編號',t_name varchar(10) not null comment '教師姓名',t_age tinyint unsigned not null comment '教師年齡',t_sex enum ('0','1') not null default '1' comment '教師性別',prof varchar(10) comment '教師職稱',depart varchar(15) not null comment '教師部門'
);insert into teacher(t_no, t_name, t_age, t_sex, prof, depart)
values ('001', '曾導', 18, 1, '校長', 'linux'),('002', '徐導', 19, 1, '教學總監', 'linux'),('003', '李導', 20, 1, '講師', 'python');select的練習題:(注意我使用的不是那個一層一層進行篩選)
-- 查詢student表中的所有記錄的s_name、s_sex和class列
select student.s_name,student.s_sex,student.class from student;
-- 查詢教師所有的單位即不重復的depart列
select distinct teacher.depart from teacher;
-- 查詢score表中成績在80到90之間的所有記錄
select * from score where mark between 80 and 90;
-- 查詢score表中成績為85.5,89.5或80.5的記錄
select * from score where mark in (85.5,89.5,80.5);
-- 查詢student表中1班或性別為“女”的同學記錄
select * from student where class='1' or s_sex='女';
-- 以cno升序、mark降序查詢Score表的所有記錄
select * from score order by cno asc,mark desc;
-- 查詢”曾導“教師任課的學生成績
select teacher.t_name,course.cname,student.s_name,score.mark
from teacher,course,student,score
where teacher.t_name='曾導' andteacher.t_no=course.tno andcourse.cno=score.cno andscore.sno=student.s_no;
-- 查詢linux課程所有男生的成績并且查出對應課程的教師名,職稱,及所在部門。
-- 96ms運行時間
select teacher.t_name,teacher.prof,teacher.depart,score.mark
from teacher,course,student,score
where course.cname='linux' andstudent.s_sex='1' andteacher.t_no=course.tno andcourse.cno=score.cno andscore.sno=student.s_no;/*我要進行一層一層的查詢1. 先查詢linux課程的所有成績2. 再查詢linux課程的所有男生3. 最后查詢linux課程的所有男生對應的成績4. 最后查詢linux課程的所有男生對應的成績對應的教師名,職稱,及所在部門*/-- 40ms運行時間select teacher.t_name,teacher.prof,teacher.depart,mark,s_namefrom teacherinner join course
on teacher.t_no = course.tno and depart = 'linux'
inner join scoreon score.cno = course.cnoinner join studenton student.s_no = score.sno and student.s_sex = '1';【值得注意一點就是,我們在使用的時候一層一層要不直接進行判斷要節約一半的時間!!!】
2.4自連接(換句話說就是自己對自己的這個表進行拆分成兩個一模一樣的表,然后通過拆成的兩個進行比較!)
我們還是舉一個例子:
創建shop表格,添加數據進行對比!
create table if not exists shop (id int not null auto_increment comment '商品id',name varchar(10) not null default '匿名' comment '商品名字',price float(10,2) not null default 0.00 comment '商品價格',primary key (id)
);
insert into shop (name,price) values ('華為手機',6999.00);
insert into shop (name,price) values ('小米手機',5000.00);
insert into shop (name,price) values ('榮耀手機',5999.00);
insert into shop (name,price) values ('華為平板',4999.00);
insert into shop (name,price) values ('小米平板',3999.00);
insert into shop (name,price) values ('榮耀平板',8999.00);然后我想對其價格估算,我想知道比華為平板高的商品有哪些?
方法1:就是進行分步查詢
select price from shop where name = '華為平板'; -- 先進行查詢
select * from shop where price > 4999;方法2.自連接
select a.*
from shop as a,shop as b
where b.name = '華為平板'and a.price > b.price;3.排序和分頁
排序:升序ASC,降序DESC
select a.*
from shop as a,shop as b
where b.name = '華為平板'and a.price > b.price
order by a.price desc;分頁: 1.環節數據庫壓力 2.還有就是美觀!
select a.*
from shop as a,shop as b
where b.name = '華為平板'and a.price > b.price
order by a.price desc
limit 0, 2; -- 起始值,頁面大小
-- limit規律就是limit (當前頁-1)*頁面大小,頁面大小4.MySQ函數(畢竟是一門語言,就有自己的api,自己的函數)
4.1常用函數(常見但是也不是很常用)
就是什么絕對值,向上取整,向下取整,產生隨機數等等!
需要就進行查詢一下!
4.2聚合函數(就是比如有時候需要對其表格里面的數據進行處理)
聚合函數的查詢
| 函數名稱 | 描述 |
| count() | 計數 |
| sum() | 求和 |
| avg() | 平均值 |
| max() | 最大值 |
| min() | 最小值 |
-- =============count()===============
select count(shop.name)
from shop; -- 會忽略null值select count(*)
from shop; -- 不會忽略nullselect count(1)
from shop; -- 不會忽略null-- ====================sum()==============select sum(shop.price)
from shop;-- ====================avg()==============
select avg(shop.price)
from shop;-- ====================max()==============
select max(shop.price)
from shop;-- ====================min()==============
select min(shop.price)
from shop;下面我們通過分組來進行查詢
select shop.name,sum(shop.price) as sum_price,avg(shop.price) as avg_price,max(shop.price) as max_price,min(shop.price) as min_price
from shop
group by shop.name;【小的知識點補充一下就是md5:messenge digest 信息摘要算法,是不可逆的一種加密算法,我們可以對于數據庫里面的數據進行加密】
【但是就是我們網上不是有那種在線破解碼,那些都是把一些常見的密碼已經存好了,存放在一個字典里面,你去查詢就可以看到了!】
insert into shop (name, price)
values (md5('華為汽車'), 699);總結
select完整的語句:
-- select的查詢語法完整語句
select 去重的列
要查詢的字段
*** join 關聯表名 on 關聯條件
from 表名
where 指定結果需滿足的條件,或者子查詢
group by 指定結果按照哪幾個字段進行分組
having 指定分組后,分組結果需滿足的條件
order by 指定結果按照哪一個字段進行排序
limit 指定結果返回的條數)






)


![LeetCode[232]用棧實現隊列](http://pic.xiahunao.cn/LeetCode[232]用棧實現隊列)



)




