傳統 OLAP 系統的局限
在大數據實時分析領域,數據模型設計直接決定了系統的查詢性能、存儲效率與業務適配性。Apache Doris作為新一代MPP分析型數據庫,通過獨創的多模型融合架構,在業內率先實現了"一份數據支持多種分析范式"的能力。本文將深入解析Doris的三大核心數據模型及其背后的設計哲學。
在 Doris 出現之前,傳統的 OLAP 系統通常面臨以下的局限性:
- 預聚合模型,犧牲靈活性換取性能,無法支持明細查詢;
- 全量明細模型,保留原始數據但查詢效率低下;
- Lambda 混合架構,又會導致架構復雜,而且會有數據一致性風險。
Doris 數據模型技術實現
Doris 通過數據模型來定義數據存儲和管理方式,當前提供了明細模型、聚合模型以及主鍵模型三種表模型,不同的模型具有相應的數據去重、聚合和更新機制,滿足不同應用場景需求。
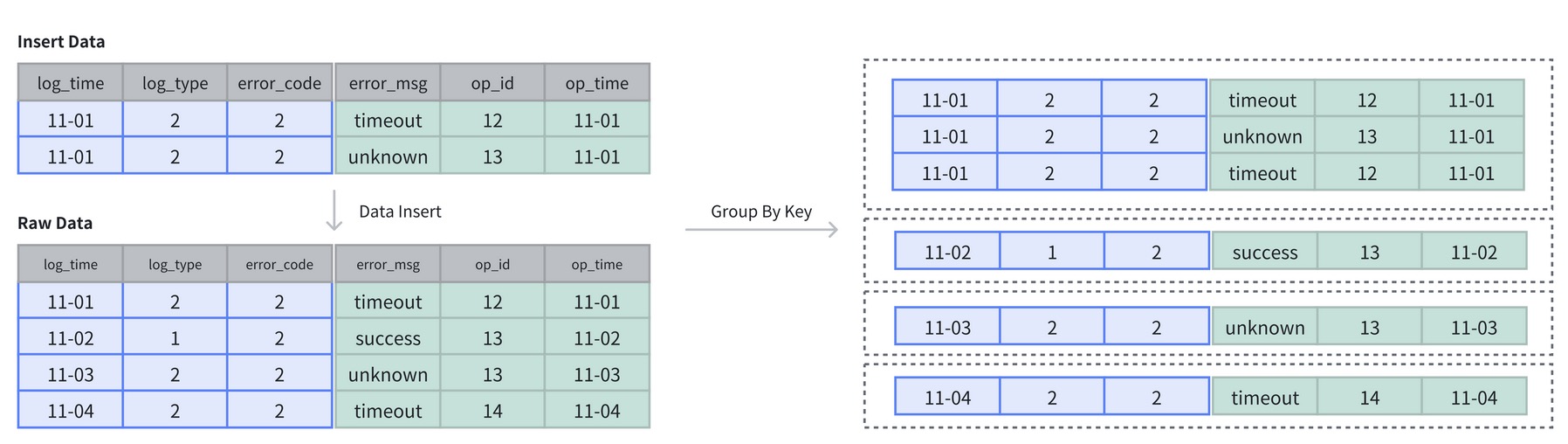
明細模型 (Duplicate Key Model)
明細模型下的數據存儲類似于傳統數據庫,允許指定的 Key 列重復,一般數據只進行追加,現有數據不更新或少量更新。 Doris 存儲層保留所有寫入的數據,既不去重也不聚合。
雖然無法利用預聚合特性,但是不受聚合模型的約束,可以發揮列存模型的優勢。適合任意維度的 Ad-hoc 查詢,典型的應用場景如日志存儲、交易數據和用戶行為數據查詢等。
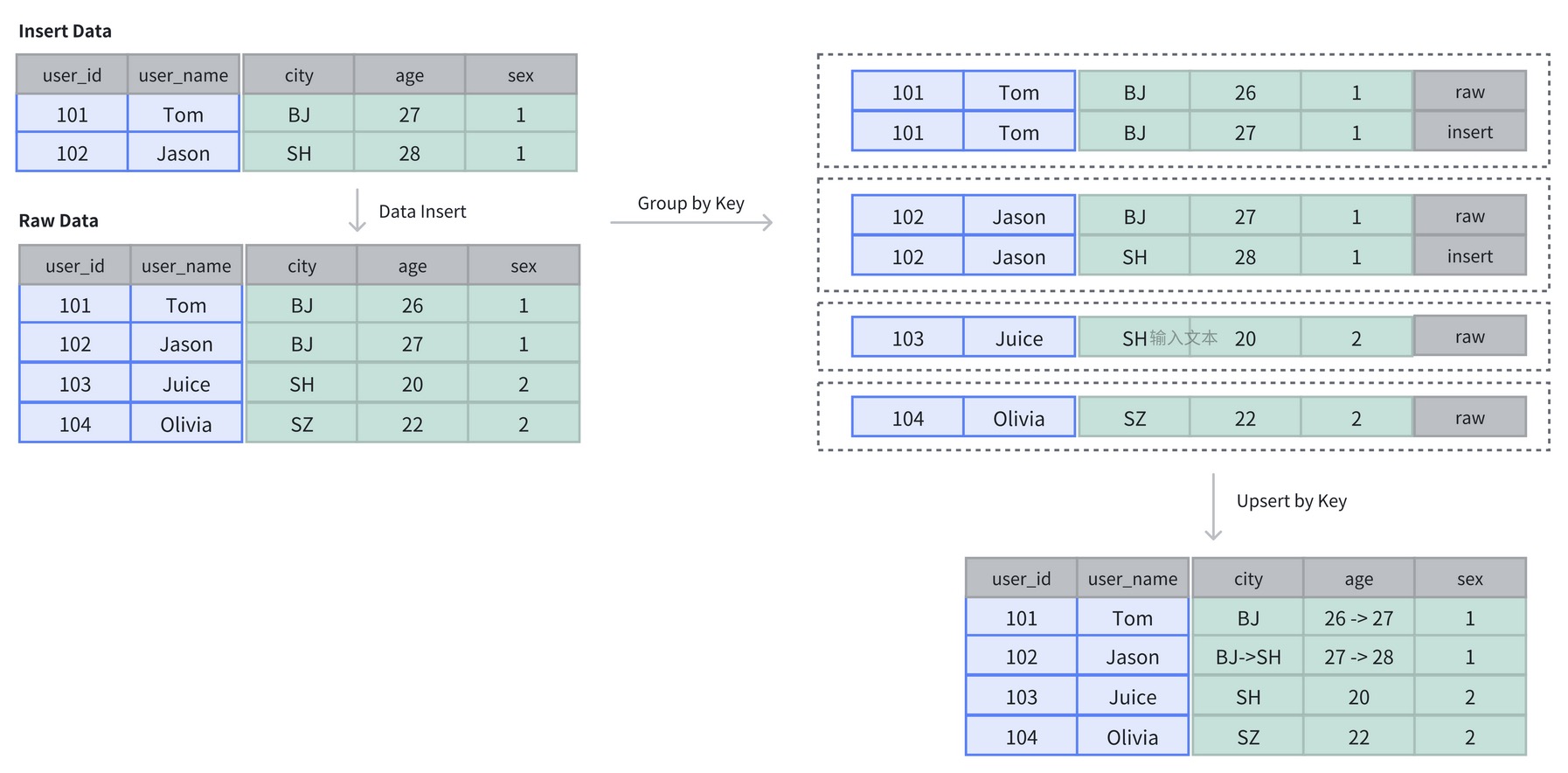
主鍵模型 (Unique Key Model)
每行 Key 值唯一,確保給定的 Key 列不會存在重復行,基于主鍵進行 UPSERT 更新,Doris 存儲層對每個 Key 只保留最新寫入的數據。
Doris 中的主鍵模型有兩種實現方式:
- 寫時合并:數據在寫入時立即合并相同 Key 的記錄,確保存儲的始終是最新數據。寫時合并兼顧查詢和寫入性能,避免多個版本的數據合并,并支持謂詞下推到存儲層。大多數場景推薦使用此模式;
- 讀時合并:數據在寫入時并不進行合并,以增量的方式被追加存儲,在 Doris 內保留多個版本。查詢或 Compaction 時,會對數據進行相同 Key 的版本合并。讀時合并適合寫多讀少的場景,在查詢是需要進行多個版本合并,謂詞無法下推,可能會影響到查詢速度。
主鍵模型默認為整行更新,即使用戶使用 Insert Into 指定部分列進行寫入,Doris 也會在 Planner 中將未提供的列使用 NULL 值或者默認值進行填充。如果希望更新部分字段,需要使用寫時合并實現,并通過特定的參數來開啟部分列更新的支持。
針對需要唯一主鍵約束的場景,可以保證主鍵唯一性約束,但無法利用 ROLLUP 等預聚合帶來的查詢優勢。適用于需要數據更新的情況,典型的場景如用戶畫像和實時風控等。
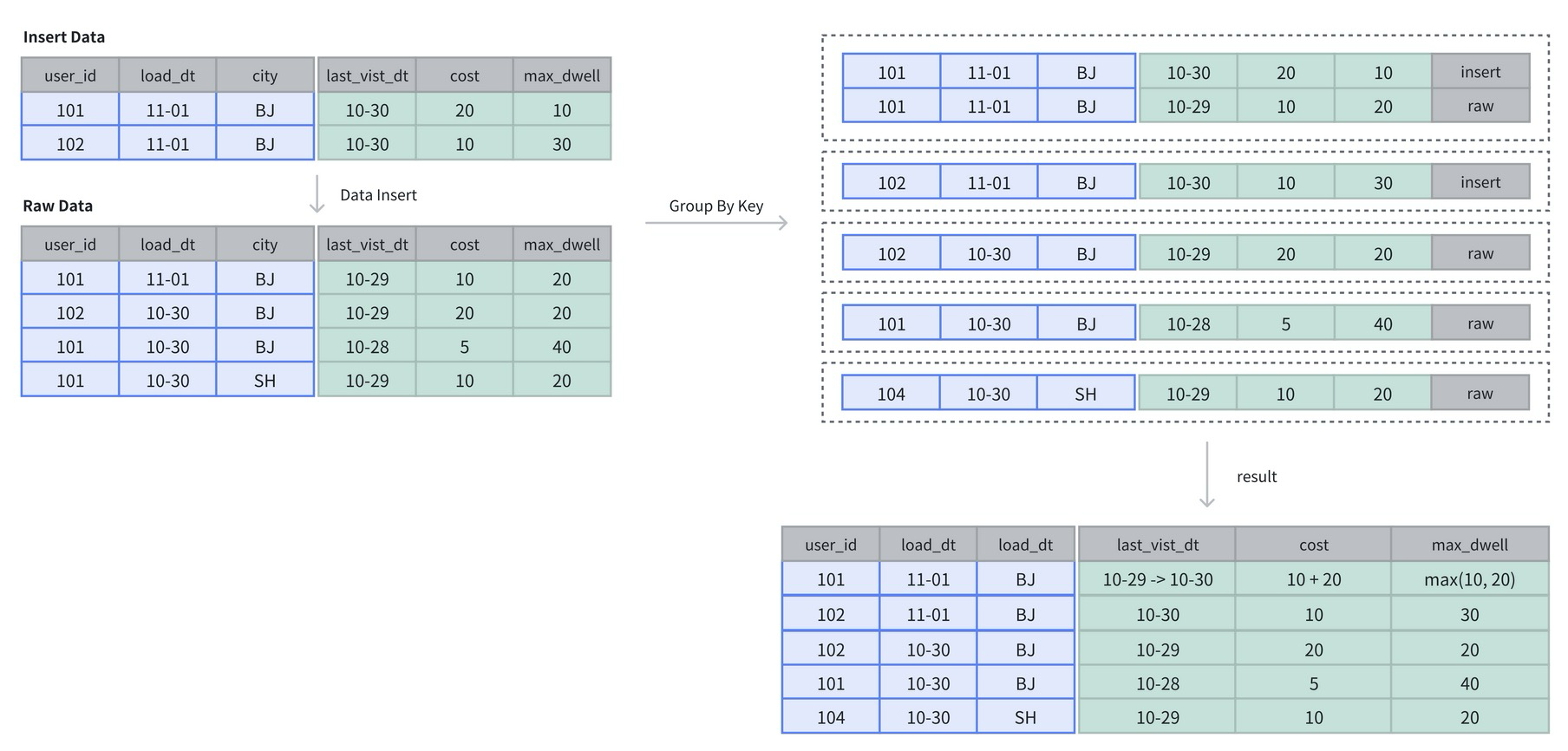
聚合模型 (Aggregate Key Model)
聚合模型專為高效處理大規模數據查詢中的聚合操作設計,根據 Key 列聚合數據,在數據寫入時自動維護 SUM/MAX/MIN 等聚合狀態, Doris 存儲層保留聚合后的數據,從而減少存儲空間,極大的降低聚合查詢時所需要掃描的數據量和查詢計算量,非常適合有固定模式的報表類查詢和指標看板等場景。
當然聚合模型的使用也存在一定的局限性:
- 模型對外展現的是最終聚合后的數據,任何還未聚合的數據(比如說兩個不同導入批次的數據),必須通過某種方式,以保證對外展示的一致性。因此,在進行其他類型的聚合查詢時,需要考慮語意正確性;
- 模型對 count(*) 查詢很不友好,為了得到正確的結果,必須掃描所有的聚合列,并進行聚合后才能得到語意正確的結果,查詢成本非常高。
模型特征總結
| 模型類型 | 數據特征 | 典型場景 | 性能優勢 |
|---|---|---|---|
| 明細模型 | 原始數據、高基數維度 | 日志分析、Ad-hoc查詢 | 靈活查詢 |
| 聚合模型 | 固定維度、數值型指標 | 日報表、監控看板 | 查詢速度提升100倍 |
| 主鍵模型 | 頻繁更新、點查為主 | 用戶畫像、實時庫存 | 支持高并發點查 |
寫在最后
實時分析場景是 Doris 的立足之本,致力于打造速度最快且最具成本效益的分析型數據庫,而數據模型是實現這一目標的基礎。傳統 OLTP 數據庫大多數使用明細模對數據進行直接的存儲,而不做額外的處理和加工,好處是插入性能好,滿足高響應低延時的業務系統需求;而 OLAP 類的業務通常有較多的分析計算,通過聚合模型將數據按需求提前進行計算,在查詢時直接提取計算后的結果,因而大大降低了分析計算的時間,但是又會損失一些插入的時間。
數據庫的設計中總是充滿了各種權衡,就像 Doris 的聚合模型,當你在分析計算過程中得到了好處,則可能在數據插入時損失一些性能。當然好的產品或者好的架構師,就是結合自身的業務需求,將適當的技術和產品放在最合理的位置,從而發揮出最大的價值!
帶論文文檔1萬字以上,文末可獲取,系統界面在最后面。)


——建模學習記錄)

)

——基礎)



)







