- Paper: https://arxiv.org/abs/2107.04034
- Project: https://ashish-kmr.github.io/rma-legged-robots/
- Code: https://github.com/antonilo/rl_locomotion
- 訓練環境:Raisim
1.方法
RMA(Rapid Motor Adaptation)算法通過兩階段訓練實現四足機器人在復雜環境中的快速適應。
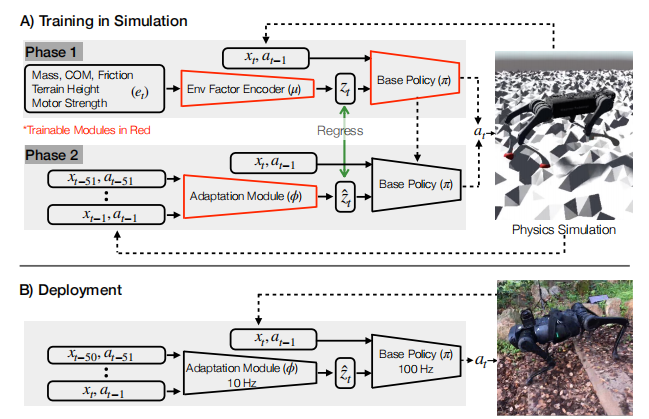
1.1.第一階段:基礎策略訓練
在第一階段,算法引入了一個17維的特權觀測向量( e t e_t et?),該向量包含了以下信息:
- 3維的質量和質心位置:描述機器人整體的質量分布。
- 12維的電機強度:表示每個關節電機的最大輸出能力。
- 1維的摩擦系數:描述機器人與地面之間的摩擦特性。
- 1維的相對地面高度:表示機器人當前所處地形的相對高度。
這些特權觀測信息雖然對訓練過程非常有幫助,但在實際部署中無法直接獲取。這些信息首先通過一個環境因素編碼器( μ \mu μ) 被壓縮為一個8維的潛在空間向量 ( z t z_t zt?)。壓縮的好處包括:
- 降低維度:減少計算復雜度,提高訓練效率。
- 提取關鍵特征:提取對適應性最有幫助的特征,減少噪聲和冗余信息。
- 增強泛化能力:通過壓縮,潛在空間向量更能捕捉到環境變化的關鍵特征,從而在不同環境中具有更好的泛化能力。
策略網絡 ( π \pi π) 的輸入包括:
- 30維的本體觀測:包含機器人的關節位置、速度、姿態等信息。
- 12維的歷史動作:包含前一時刻的動作信息。
- 8維的潛在空間向量 ( z t z_t zt?):由環境因素編碼器生成。
策略網絡的輸出為12維的關節期望位置指令 a = q ^ ∈ R 12 a=\hat q \in \mathbb R^{12} a=q^?∈R12,這些指令通過PD控制器被轉換為關節力矩 ( τ \tau τ),驅動機器人運動。
τ = K p ( q ^ ? q ) + K d ( 0 ? q ˙ ) \tau = K_p(\hat q - q) + K_d (0-\dot q) τ=Kp?(q^??q)+Kd?(0?q˙?)
第一階段的訓練目標是最大化策略網絡在模擬環境中的累積獎勵。通過強化學習(PPO算法),策略網絡和環境因素編碼器被聯合訓練,以適應各種模擬環境中的復雜地形和動態條件。
1.2.第二階段:自適應模塊訓練
第一階段訓練得到的策略網絡無法直接部署到實際機器人上,因為實際機器人無法獲取17維的特權觀測信息( e t e_t et?),也無法獲取由環境因素編碼器生成的8維潛在空間向量 ( z t z_t zt?)。為了解決這個問題,RMA算法引入了一個自適應模塊網絡 ( ? \phi ?),用于在運行時估計特權信息。
自適應模塊網絡的輸入是機器人最近50組歷史狀態和動作,這些信息被用來估計特權觀測經過壓縮后的8維潛在空間向量 ( z ^ t \hat{z}_t z^t?)。自適應模塊網絡由一個1維卷積神經網絡(CNN)和一個多層感知機(MLP)組成,通過監督學習進行訓練。具體來說,自適應模塊網絡的訓練目標是最小化估計的潛在空間向量 ( z ^ t \hat{z}_t z^t?) 與真實潛在空間向量 ( z t z_t zt?) 之間的均方誤差(MSE)。
第二階段訓練得到的自適應模塊網絡可以與基礎策略網絡一起部署到實際機器人上。在實際運行中,自適應模塊網絡以10Hz的頻率更新潛在空間向量 ( z ^ t \hat{z}_t z^t?) ,而基礎策略網絡則以100Hz的頻率根據當前狀態、歷史動作和最新的潛在空間向量生成關節期望位置指令。
2.關鍵創新點
- 異步執行設計:基礎策略網絡和自適應模塊網絡以不同的頻率運行(100Hz和10Hz),并且異步執行。這種設計使得算法能夠在計算資源有限的機器人上高效運行,同時保證了實時性和適應性。
- 無需微調:RMA算法完全在模擬環境中訓練,無需在現實世界中進行任何微調或數據收集,即可直接部署。
- 快速適應:通過自適應模塊網絡在運行時快速估計特權信息,RMA算法能夠在幾秒鐘內適應新的環境條件,如不同的地形、負載和摩擦系數。
3.實驗驗證
RMA算法在多種復雜地形上進行了實驗驗證,包括沙地、泥土、草地、混凝土、鵝卵石、樓梯等。實驗結果表明,RMA算法在這些復雜環境中的成功率和適應性優于基線方法,展示了其在實際應用中的潛力。
4.總結
RMA算法通過兩階段訓練,第一階段在模擬環境中訓練基礎策略,第二階段訓練自適應模塊以估計特權信息。通過將17維特權觀測壓縮為8維潛在空間,算法能夠更高效地提取關鍵特征,減少計算復雜度,增強泛化能力。這種設計使得算法能夠在實際機器人上快速適應新環境,無需額外的微調或數據收集。


】家政平臺蛻變記:性能優化與代碼重構揭秘)

)





)

】解鎖家政平臺測試秘籍:計劃與策略全解析)



)


