前言:
????????在前兩期內容中,我們深入探討了內存管理機制中在?ThreadCache?和?CentralCache兩個層級進行內存申請的具體實現。這兩層緩存作為高效的內存分配策略,能夠快速響應線程的內存需求,減少鎖競爭,提升程序性能。
????????本期文章將繼續沿著這一脈絡,聚焦于PageCache層級的內存申請邏輯。作為內存分配體系的更高層級,PageCache承擔著從操作系統獲取大塊內存,并對其進行管理和再分配的重要職責。通過對PageCache內存申請流程的剖析,我們將完整地勾勒出整個內存分配體系的工作流程。這不僅有助于我們理解內存分配的底層機制,也為后續深入探討內存釋放策略奠定了基礎。
????????接下來,讓我們一同走進PageCache的內存世界。
目錄
一、PageCache的概述
二、PageCache結構
三、內存申請的核心流程
四、PageCache類的設計
五、代碼實現
1.GetOneSpan的實現
2.NewSpan的實現
3.加鎖保護
六、源碼
一、PageCache的概述
? ? ? ? ?緩存是在central cache緩存上?的?層緩存,存儲的內存是以?為單位存儲及分配的。當central cache沒有內存對象時,從page cache分配出?定數量的page,并切割成定???的?塊內存,分配給central cache。當?個span的?個跨度?的對象都回收以后,page cache會回收central cache滿?條件的span對象,并且合并相鄰的?,組成更?的?,緩解內存碎?的問題。
二、PageCache結構
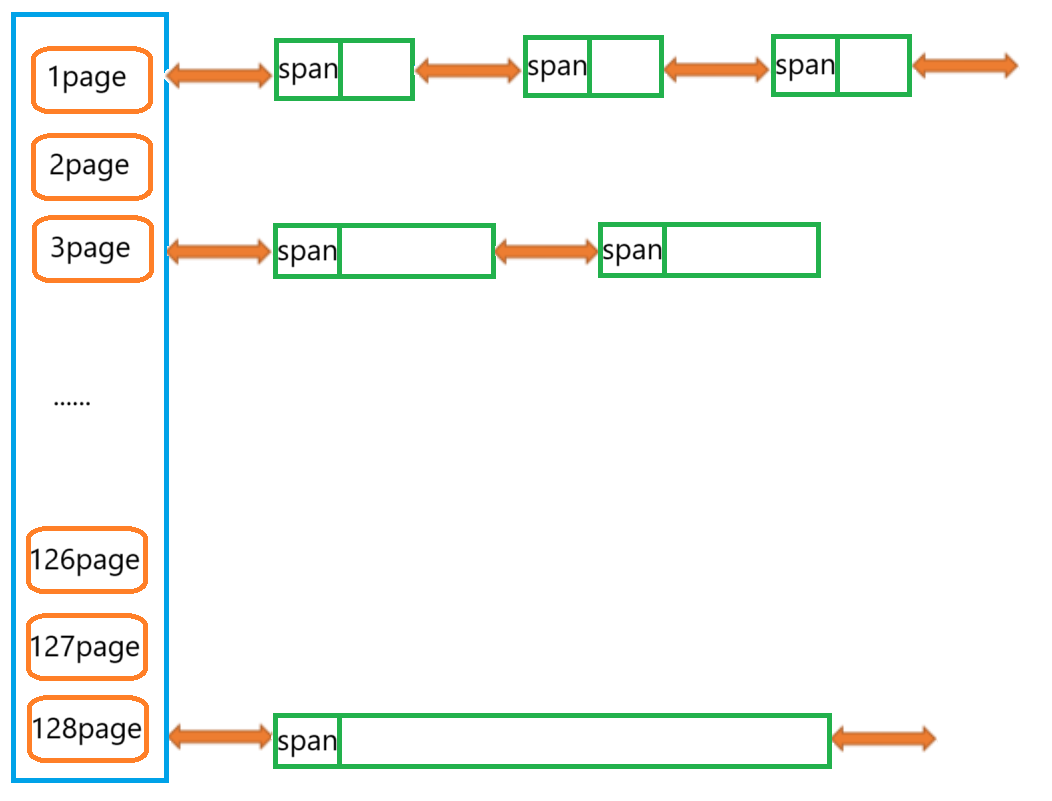
????????PageCache的結構是一個哈希表,如上圖所示,也就是一個儲存span雙鏈表的數組,這一點和CentralCache的結構完全類似,區別在于這里的Span是大塊的頁(1頁~128頁)沒有進行分割,而CentralCache中的Span是分割好的小塊內存(自由鏈表),這樣做的好處是方便頁與頁之間的分割與合并,有效的緩解內存外碎片,在下文會詳細講解。
????????PageCache結構的哈希映射方法是直接定址法,下標為n的位置儲存的Span雙鏈表中每個節點有n個頁。
? ? ? ? 這個哈希表也是所有線程共用一個,屬于臨界資源需要加鎖,但不是桶鎖,而是一整個大鎖,為什么呢?同樣在下文細講。
注:通常以4KB或8KB為一頁,這里我們以8KB為一頁。
三、內存申請的核心流程
- ThreadCache
?CentralCache?
????????當ThreadCache的自由鏈表內沒有內存時,會向CentralCache中的一個Span申請,如果沒有可用的Span,就向PageCache申請一個Span大塊頁,如果沒有Span大塊頁了,最后才會向系統申請。
那么CentralCache具體是如何向PageCache申請內存的呢?
? ? ? ? 同樣的PageCache一次只給一個Span,然后把這個Span切割成小塊連接到CentralCache的哈希桶中,要給幾頁的Span呢?,這需要根據要將它切割成多大為單位的小塊內存來進行具體分配,如果要切較小的內存塊,頁數就給小一些,如果要切大內存塊,頁數就給多一些。這里我們就先記為n頁的Span。
? ? ? ? 因為PageCache中的哈希映射是直接定址法,所以直接找到n下標位置的Span鏈,如果有Span則取出并切成小塊連接到CentralCache的哈希桶中。
????????如果沒有n頁的Span并不是直接去系統申請,而是到更大的頁單位去找Span。比如找到有(n+k)頁的Span,k>0,n+k<=128,那么把(n+k)拆開為n頁與k頁,并連接到相應位置。這樣就有了n頁的Span,把它切割和連接就行。
? ? ? ? 如果直到找到128頁也沒有找到可用的Span那么就向系統申請128頁的內存,即128*8*1024字節,然后再執行上面邏輯。這就是整個在PageCache申請內存的邏輯。
處理臨界資源互斥問題
如上,PageCache的哈希桶中各個桶是互相聯動的,主要體現在這三方面:
- 當前桶沒Span要往后找。
- 后面的桶切割Span后要連接到前面的桶。
- 在內存回收時又需要前面桶的Span合并成大頁的Span連接到后面的桶。
????????所以這里不像CentralCache結構的桶相互獨立,如果用桶鎖會造成頻繁的鎖申請和釋放,效率反而變得很低。用一個大鎖來管理整個哈希桶更為合理。
四、PageCache類的設計
????????把這個類的設計放在頭文件PageCache.h里,它核心就兩個成員變量:鎖和哈希桶,然后再聲明一個用來申請Span的成員函數,如下:
class PageCache
{
public:Span* NewSpan(size_t k);std::mutex _pageMtx;
private:SpanList _spanLists[NPAGES];
};- Span* NewSpan(size_t k):申請一個k頁的Span
- mutex _pageMtx:鎖,因為它要在外部使用,所以設為public。
- SpanList _spanLists[NPAGES]:哈希桶,其中NPAGES是一個靜態全局變量為129,在Common.h中定義。設為129是因為哈希表中存1頁~128頁的Span,要通過頁數直接定址的方式找到Span鏈表,就需要開辟129大小的數組。
????????PageCache類和CentralCache類一樣所有線程共用一份,所以把它創建為單例模式,它分為以下幾步:
- 把構造函數設為私有。
- 把拷貝構造禁用。
- 聲明靜態的PageCache對象,并在PageCache.cpp中定義。
- 提供一個獲取PageCache對象的靜態成員函數,并設為public。
代碼示例:
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}Span* NewSpan(size_t k);std::mutex _pageMtx;
private:PageCache() {}PageCache(const PageCache&) = delete;SpanList _spanLists[NPAGES];static PageCache _sInst;
};五、代碼實現
1.GetOneSpan的實現
????????回顧上一期我們只是假設通過GetOneSpan從CentralCache中取到了Span,然后繼續做后面的處理。接下來我們一起來實現GetOneSpan函數。
????????因為要在Span鏈表中取一個有用的Span節點,所以需要遍歷Span鏈表,那么可以模擬一個迭代器。我們在SpanList類中封裝這兩個函數:
Span* Begin()
{return _head->_next;
}
Span* End()
{return _head;
}注:SpanList是一個帶頭雙向環形鏈表。?
接下來遍歷鏈表找到可用的Span并返回,如果沒有則到PageCache中申請。
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}it = it->_next;}//走到這里說明沒有可用的Span了,向PageCache中申請。//......
}- SpanList& list:指定的一個哈希桶,即一個Span鏈表的頭結點。
- size_t size:進行內存對齊后實際需要申請的字節大小。
????????注意在PageCache中申請的是大塊的Span頁,還需要把它切割,然后連接到CentralCache的桶中并返回。
????????在PageCache類中我們準備實現的函數NewSpan就是用來實現這個功能,現在需要考慮的是要傳入的參數是多少,即要申請多少頁的Span。
這里我們是以8KB為一頁,即 1頁=8*1024字節(2^13字節)為方便后面做位運算,我們在Common.h文件定義一個這樣一個變量:
????????????????static int const PAGE_SHIFT = 13;
當然了這里也可以做成宏定義。
????????接下來在SizeClass類里封裝一個函數NumMovePage用來計算一個size需要申請幾頁的Span,如下:
//用來計算ThreadCache向CentralCache申請幾個小內存塊
static inline size_t NumMoveSize(size_t size)
{int ret = MAX_BYTES / size;if (ret < 2) ret = 2;if (ret > 512) ret = 512;return ret;
}
//用來計算CentralCache向PageCache申請幾個頁的Span
static inline size_t NumMovePage(size_t size)
{int num = NumMoveSize(size);int npage = num * size;npage >>= PAGE_SHIFT; //除以8KBif (npage < 1) npage = 1;return npage;
}????????在此,大家無需過度糾結于該設計背后的原理。這或許是相關領域的資深專家在歷經大量測試與實踐后,所總結提煉出的有效策略,我們繼續走下面的邏輯。
//申請Span
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
//切割Span
//......????????NewSpan函數我們待會再設計,現在假設已經申請到一個Span的大塊頁,接下來就是進行切割。?
????????首先我們需要得到的是這個頁的起始地址與終止地址,在這個范圍內以size的跨度切割。
? ? ? ? 用char*的指針變量start,end分別來儲存起始地址和終止地址,用char*類型是因為char*類型指針變量加多少,就移動多少字節,方便后面做切割運算。
起始頁地址的獲取:
取到Span的頁號,用頁號乘以8KB(2^13字節)就能得到頁的起始地址,即:
????????????????char* start = (char*)(span->_pageId << PAGE_SHIFT);
終止頁地址的獲取:
取到Span的頁數,用頁數乘以8KB再加上起始頁地址就能得到終止頁地址,即:
????????????????int bytes = span->_n << PAGE_SHIFT;
? ? ? ? ? ? ? ? char* end = start + bytes;
注:頁號是通過申請到的內存的虛擬地址除以8KB得到的。
????????接下來把start連接到Span的自由鏈表中,然后使用循環把[start,end]這塊內存以size為跨度進行切割,如下:
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}it = it->_next;}//申請SpanSpan* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));//切割Spanchar* start = (char*)(span->_pageId << PAGE_SHIFT);int bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;span->_freeList = start;while (start < end){Nextobj(start) = start + size;start = (char*)Nextobj(start);}Nextobj(end) = nullptr;//連接到CentralCache中list.PushFront(span);return span;
}????????這里直接以尾插的方式切,好處在于用戶在使用內存時是連在一塊的,相關的數據會被一并載入寄存器中,可以增加高速緩存命中率,提高效率。
最后實現一個類方法PushFront,用來把Span連接到哈希桶里。
void PushFront(Span* node)
{//在Begin()前插入node,即頭插Insert(Begin(), node);
}2.NewSpan的實現
NewSpan我們放在源文件PageCache.cpp中實現。
查找當前桶
????????首先可以用assert斷言頁數的有效性,然后直接定址找到Span鏈,如果不為空返回一個Span節點,如果為空到后面的大頁去找,如下:
Span* PageCache::NewSpan(size_t k)
{//判斷頁數的有效性assert(k > 0 && k < NPAGES);if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}//到后面更大塊的Span頁切割//......//向系統申請內存//......
}到大頁切割
????????當k號桶沒有Span后,從k+1號桶開始往后找,比如找到i號桶不為空,則把Span節點取出來,記為nSpan,然后切割為k頁和i-k頁,切割的本質就是改變頁數_n和頁號_pageId。
????????new一個Span空間,用kSpan變量指向,然后把nSpan頭k個頁切出來儲存到一個kSpan中,即:
- kSpan->_pageId = nSpan->_pageId:更新kSpan的頁號。
- kSpan->_n = k:更新kSpan的頁數。
- nSpan->_pageId += k:原nSpan的頁起始頁號后移k位。
- nSpan->_n -= k:原nSpan的頁數減少k。
????????這樣就相當于把原來大塊的nSpan切割成了兩塊,最后把割剩下的nSpan插入到對應的哈希桶中,把kSpan返回。
for (int i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}向系統申請?
????????當k號桶往后的桶都是空的,那么我們就需要向系統申請內存了,直接申請一個128的頁,放在128號桶,再執行上面的邏輯。?
????????對于內存申請,在windows下我們使用VirtualAlloc函數,與malloc相比VirtualAlloc直接與操作系統交互,無額外開銷,效率高,通常用來申請超大塊內存。
VirtualAlloc的聲明
LPVOID VirtualAlloc(LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect );
- LPVOID ?lpAddress:期望的起始地址(通常設為0由系統決定)
- SIZE_T ?dwSize:分配的內存大小(字節)
- DWORD ? flAllocationType:?分配的類型(如保留或提交)
- DWORD ? flProtect:內存保護選項(如讀寫權限)
返回值:LPVOID ,本質是void*,需強制類型轉換后使用。
flAllocationType
MEM_COMMIT:提交內存,使其可用。
MEM_RESERVE:保留地址空間,暫不分配物理內存。二者可組合使用(
MEM_RESERVE | MEM_COMMIT),同時保留并提交。flProtect
控制內存訪問權限,常用選項:
PAGE_READWRITE:可讀/寫。
PAGE_NOACCESS:禁止訪問(觸發訪問違規)。
PAGE_EXECUTE_READ:可執行/讀。
????????因為還要考慮其他系統的需求,我們在Common.h內封裝一個向系統申請內存的函數,并使用條件編譯來選擇不同的函數調用,如下:
#ifdef _WIN32#include <windows.h>
#else//Linux...
#endifinline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();//拋異常return ptr;
}????????接下來繼續NewSpan的執行邏輯,向系統申請內存后,new一個Span儲存相關的頁信息,即計算頁號(地址/8KB),填寫頁數,然后把Span連接到128號哈希桶,最后需要做的就是把它切割為k頁的Span和(128-k)頁的Span和前面的邏輯一模一樣,為提高代碼復用率以遞歸的方式返回。如下:
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}for (int i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}//向系統申請內存Span* span = new Span;void* ptr = SystemAlloc(NPAGES - 1);span->_pageId = (PANGE_ID)ptr>>PAGE_SHIFT;span->_n = NPAGES - 1;_spanLists[span->_n].PushFront(span);return NewSpan(k);
}3.加鎖保護
????????PageCache哈希桶是臨界資源,需要對它進行加鎖保護。上文已經講過只用加一個大鎖,而不是用桶鎖。
? ? ? ? 因為NewSpan函數涉及遞歸,需要使用遞歸鎖,這樣比較高效。但這里也可以把鎖加到NewSpan外面,也就是GetOneSpan函數里,如下:

? ? ? ? 其次有一個優化的點:線程進入PageCache這一層之前是先進入了CentralCache的,并在這一層加了桶鎖,那么此時CentralCache的哈希桶它暫時不用,但可能其他線程要用,可以先把鎖釋放掉,等從PageCache申請完內存后再去申請鎖。
? ? ? ? 雖然說線程走到PageCache這一層說明CentralCache的哈希桶已經沒有內存了,其他線程來了也申請不到內存,但別忘了還有內存的釋放呢。把桶鎖釋放了,其他線程釋放內存對象回來,就不會阻塞。如下:

六、源碼
代碼量比較大,就不放在這里了,需要的小伙伴到我的gitee上取:
PageCache/PageCache · 敲上癮/ConcurrentMemoryPool - 碼云 - 開源中國




)
)
![【01BFS】# P4667 [BalticOI 2011] Switch the Lamp On 電路維修 (Day1)|普及+](http://pic.xiahunao.cn/【01BFS】# P4667 [BalticOI 2011] Switch the Lamp On 電路維修 (Day1)|普及+)



)




)


,SAM上計數))
:AXI GPIO)