有了之前的經驗(【神經網絡】python實現神經網絡(二)——正向推理的模擬演練),我們繼續來介紹如何正向訓練神經網絡中的超參(包含權重以及偏置),本章大致的流程圖如下:

一.損失函數
神經網絡以某個指標為基準尋求最優權重參數,而這個指標即可稱之為 “損失函數” 。(例如:在使用神經網絡進行識別手寫數字時,在學習階段找出最佳參數中,最常用的方法是通過梯度下降法找出最優參數,使得通過損失函數計算的值降到最低),在之前寫過的一篇文章:【機器學習】幾個簡單的損失函數 已經大致介紹了幾種常用的損失函數,不再贅述,本章將使用交叉熵誤差作為本次的損失函數。
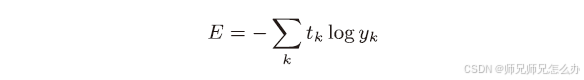
與之前不同的是,前面介紹的損失函數的例子中考慮的都是針對單個數據的損失函數。如果要求計算所有訓練數據的損失函數的總和,那么公式應該更新成這樣:
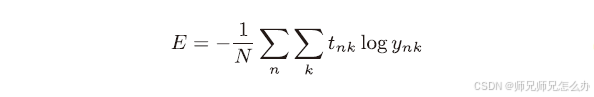
這里, 假設數據有N個,tnk 表示第n個數據的第k 個元素的值(ynk 是神經網絡的輸出,tnk 是監督數據),通過除以N,可以求單個數據的“平均損失函數”。通過這樣的平均化,可以獲得和訓練數據的數量無關的統一指標。這里其實和普通的交叉熵誤差沒有什么太大區別&#x


 1-0 等級保護制度公安部前期發文總結)











 --- 中的多協議與漏洞利用技術(雜項知識點 重點) 持續更新)




