名人說:一笑出門去,千里落花風。——辛棄疾《水調歌頭·我飲不須勸》
創作者:Code_流蘇(CSDN)(一個喜歡古詩詞和編程的Coder😊)
上一篇:AI知識補全(十四):零樣本學習與少樣本學習是什么?
目錄
- 一、AI可解釋性的基本概念
- 1. 什么是AI可解釋性?
- 2. 為什么AI可解釋性如此重要?
- 3. AI可解釋性與透明度的關系
- 二、AI可解釋性的分類方法
- 1. 按時機分類:事前、事中和事后解釋
- 2. 按范圍分類:全局解釋與局部解釋
- 3. 按依賴程度分類:模型相關和模型無關方法
- 三、主要的AI可解釋性技術
- 1. LIME (Local Interpretable Model-agnostic Explanations)
- 2. SHAP (SHapley Additive exPlanations)
- 3. 特征重要性分析
- 4. 注意力機制可視化
- 5. 類激活映射技術
- 6. 對抗性樣本和反事實解釋
- 四、AI可解釋性在各行業的應用
- 1. 醫療健康領域的應用
- 2. 金融領域的應用
- 3. 自動駕駛領域的應用
- 五、AI可解釋性面臨的挑戰與未來發展
- 1. 當前面臨的主要挑戰
- 2. 未來發展趨勢
- 六、如何實現可解釋的AI系統
- 1. 設計階段的可解釋性考量
- 2. 可解釋AI系統實現的代碼示例
- 1??LIME實現示例
- 2??SHAP實現示例
- 3. 實際應用中的最佳實踐
- 七、結論與展望
- 參考資料
很高興你打開了這篇博客,更多AI知識,請關注我、訂閱專欄《AI大白話》,內容持續更新中…
一、AI可解釋性的基本概念
1. 什么是AI可解釋性?
AI可解釋性(Explainable AI,簡稱XAI)是指讓人類能夠理解和信任人工智能系統產生結果和輸出的過程和原因的能力。
隨著AI系統日益復雜化,特別是深度學習模型的"黑盒"特性,使得理解它們的決策過程變得越來越困難。可解釋性AI旨在讓人類用戶能夠理解和信任機器學習算法創建的結果和輸出。
AI可解釋性的本質是讓AI模型的決策過程變得透明、可理解和可追溯,使人類能夠:
- 了解模型為什么做出特定決策
- 確認模型是否基于正確的因素做出決策
- 驗證模型是否存在偏見或錯誤
- 建立對AI系統的信任
在醫學領域中,可解釋性尤為重要。醫療診斷系統必須是透明的、可理解的、可解釋的,以獲得醫生、監管者和病人的信任。
2. 為什么AI可解釋性如此重要?
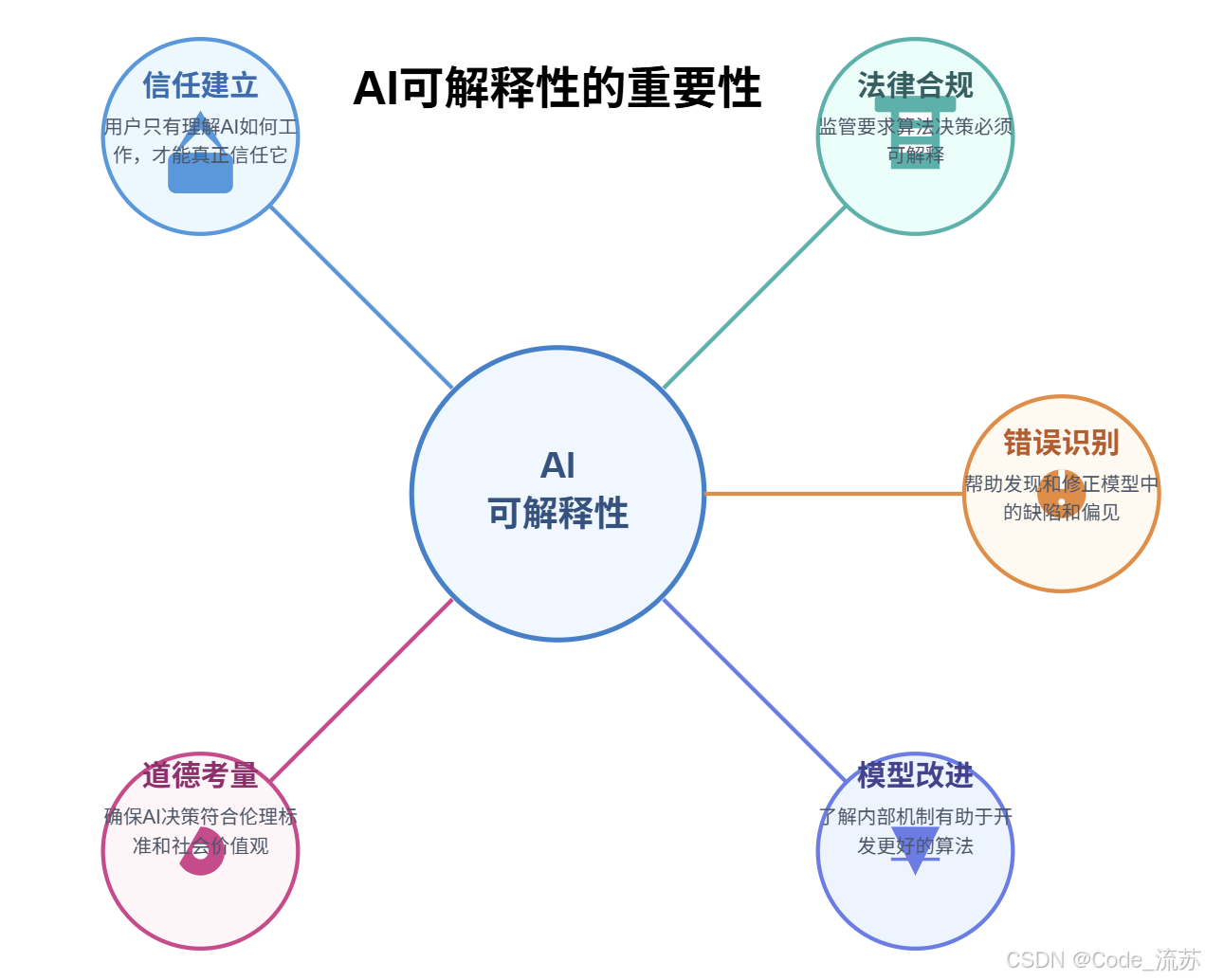
AI可解釋性的重要性體現在以下五個方面
- 信任建立:用戶只有理解AI如何工作,才能真正信任它
- 法律合規:許多領域(如金融、醫療)的監管要求算法決策必須可解釋
- 錯誤識別:幫助開發者發現和修正模型中的缺陷和偏見
- 模型改進:了解模型內部機制有助于開發更好的算法
- 道德考量:確保AI決策符合倫理標準和社會價值觀
缺乏對人工智能系統信任的一個原因是用戶無法清楚地理解人工智能的運作原理。這可能是由于模型本身的復雜性導致的,也可能是因為知識產權的封閉保護導致的,這通常被稱為"黑箱問題"。
3. AI可解釋性與透明度的關系
透明度是AI可解釋性的一個重要維度,但兩者不完全等同:
- AI透明度:關注系統設計、數據使用、模型訓練過程等方面的公開信息
- AI可解釋性:更聚焦于解釋具體的決策過程和結果
完善的AI系統應當同時具備高度的透明度和可解釋性,讓用戶既能了解系統的整體架構,又能理解具體的決策依據。
二、AI可解釋性的分類方法
1. 按時機分類:事前、事中和事后解釋
AI可解釋性方法可以按照解釋發生的時機進行分類:
- 事前解釋:在模型設計和訓練階段就考慮可解釋性,選擇天然具有可解釋性的模型結構
- 事中解釋:在模型推理過程中,實時提供決策依據和解釋
- 事后解釋:在模型做出預測后,通過額外的技術手段來解釋結果
2. 按范圍分類:全局解釋與局部解釋
SHAP提供局部和全局解釋,意味著它能夠解釋特征對所有實例和特定實例的作用,而LIME僅限于局部解釋。
1??全局解釋:
- 解釋整個模型的行為和決策模式
- 揭示不同特征在整體上的重要性
- 適用于理解模型的總體行為
2??局部解釋:
- 解釋模型對單個樣本或實例的預測
- 分析特定決策背后的具體因素
- 適用于理解具體案例的決策依據
3. 按依賴程度分類:模型相關和模型無關方法
模型特定的方法基于單個模型的參數進行解釋。而模型無關方法并不局限于特定的模型體系結構,這些方法不能直接訪問內部模型權重或結構參數,主要適用于事后分析。
- 模型相關方法:利用特定模型的內部結構和參數進行解釋
- 模型無關方法:將模型視為黑盒,通過輸入-輸出關系進行解釋,適用于任何模型
三、主要的AI可解釋性技術
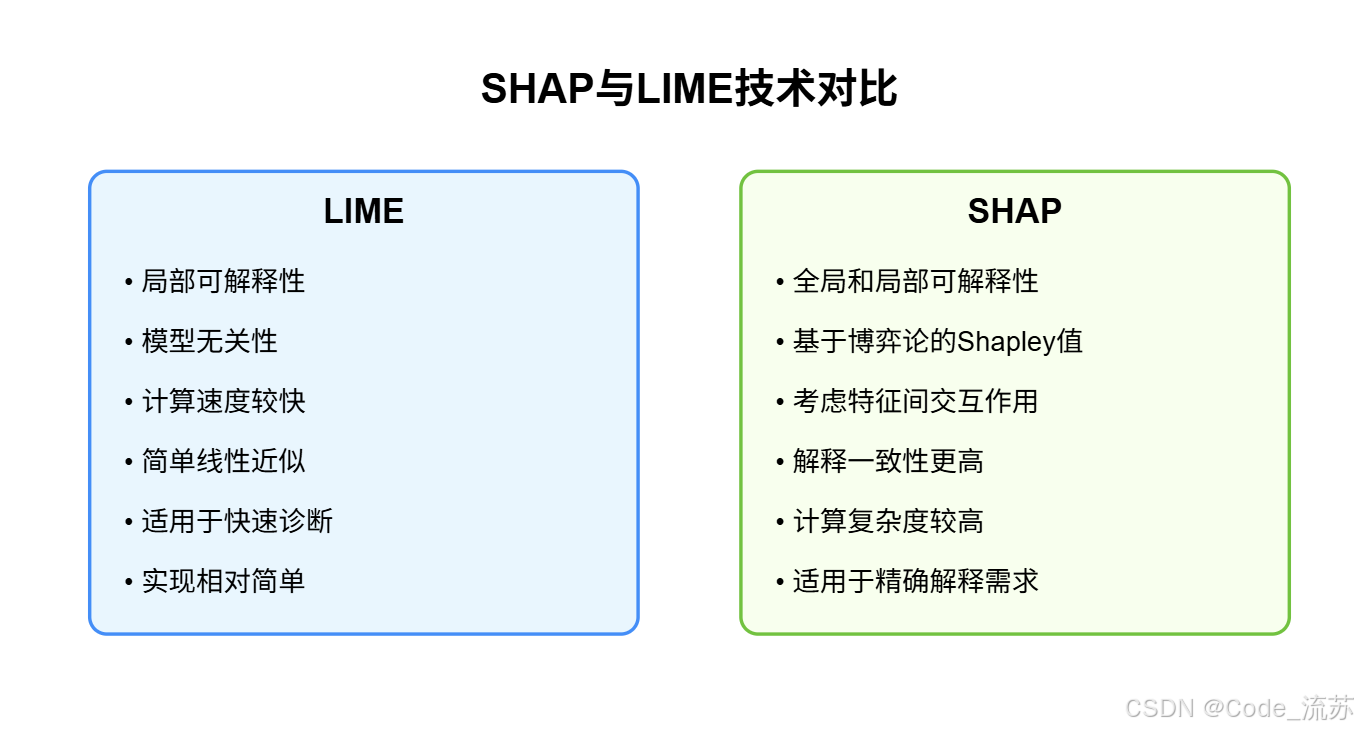
1. LIME (Local Interpretable Model-agnostic Explanations)
LIME是一種廣泛應用的局部可解釋性技術,LIME是Local Interpretable Model Agnostic Explanation的縮寫,局部(Local)意味著它可以用于解釋機器學習模型的個別預測。
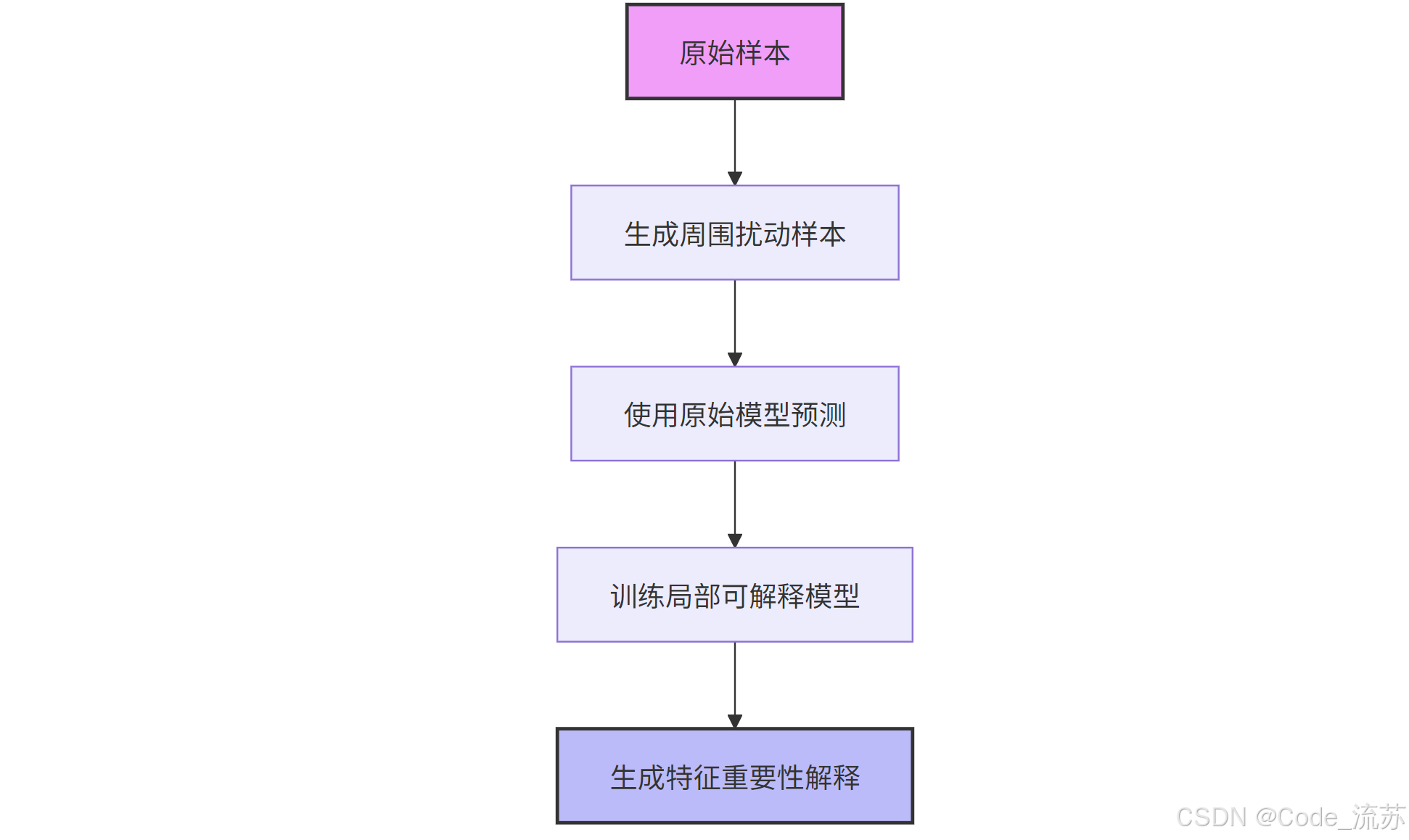
LIME的工作原理:
- 針對待解釋的樣本,在其周圍生成隨機擾動樣本
- 使用原始模型對這些樣本進行預測
- 基于預測結果,訓練一個簡單的可解釋模型(如線性回歸)
- 使用這個簡單模型解釋原始模型的局部行為
LIME在當前狀態下雖然只限于監督機器學習和深度學習模型,但它是最流行且使用廣泛的XAI方法之一。
下面是LIME的工作流程圖:
2. SHAP (SHapley Additive exPlanations)
SHAP是基于博弈論中的Shapley值概念,它是SHapley Additive exPlanations的縮寫。該方法旨在通過計算每個特征對預測的貢獻來解釋實例/觀察的預測。
SHAP的主要特點:
- 提供全局和局部解釋能力
- 保證了解釋的一致性和公平性
- 考慮了特征間的交互作用
- 計算復雜度較高,但解釋更精確
SHAP基于Shapley值,確保特征貢獻的公平分配,而LIME則近似黑盒行為,可能導致結果不太一致。
3. 特征重要性分析
特征重要性分析是一種直觀的全局可解釋性方法,通過衡量每個特征對模型預測的影響程度來解釋模型。常見的實現方式包括:
- 排列重要性:通過隨機排列某個特征的值,測量模型性能下降程度
- 平均絕對SHAP值:計算每個特征的平均絕對SHAP值
- 基于樹的特征重要性:在樹模型中,特征被用作分裂節點的頻率

4. 注意力機制可視化
在深度學習模型(特別是自然語言處理和計算機視覺)中,注意力機制(Attention Mechanism)已成為提高模型性能和可解釋性的重要工具。通過可視化注意力權重,我們可以了解模型在做決策時關注的是輸入的哪些部分。
例如,在一個情感分析模型中,通過注意力可視化,我們可以看到模型在判斷文本情感時主要關注的是哪些詞語。
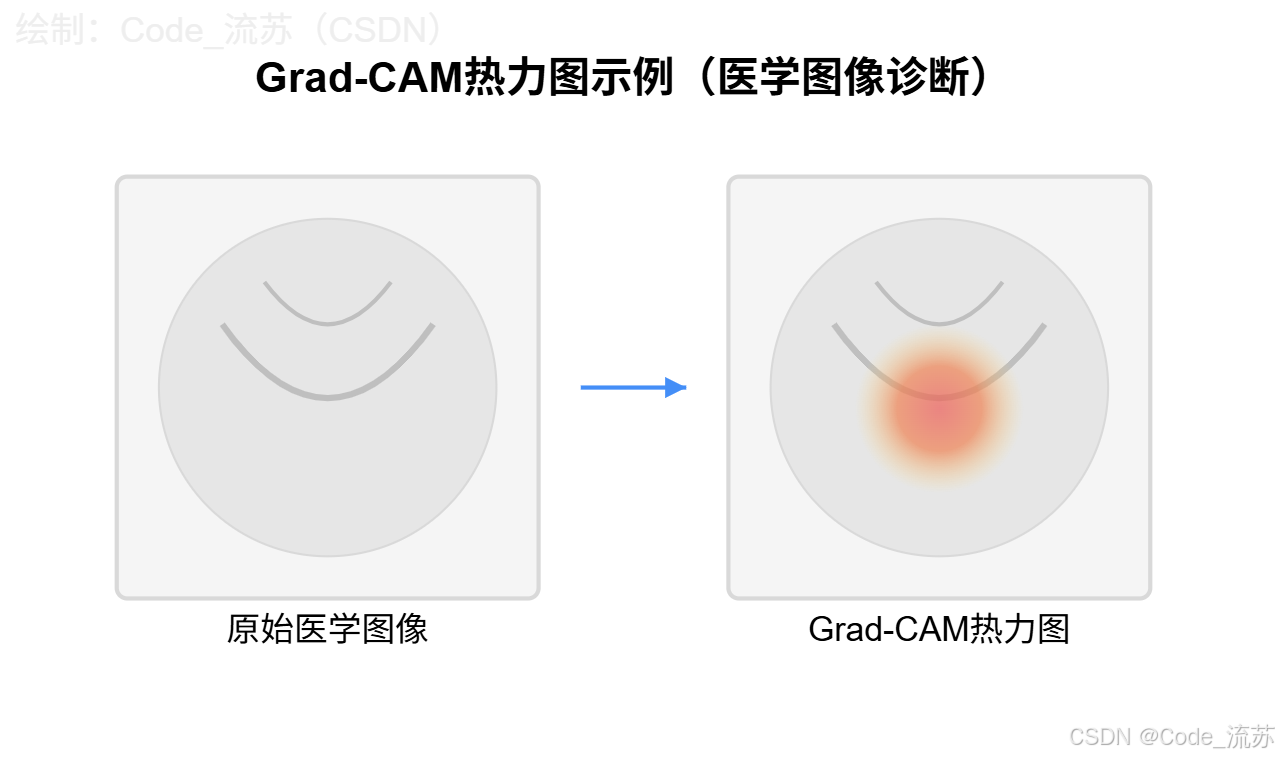
5. 類激活映射技術
類激活映射(Class Activation Mapping,CAM)和其改進版Grad-CAM是計算機視覺領域常用的可視化技術,用于顯示卷積神經網絡在圖像分類任務中關注的區域。
6. 對抗性樣本和反事實解釋
對抗性樣本是指對原始輸入進行微小修改,導致模型預測結果完全改變的樣本。分析對抗性樣本有助于理解模型的決策邊界和脆弱性。
反事實解釋(Counterfactual Explanations)回答的是"如果輸入發生什么變化,結果會不同"的問題。例如,“如果貸款申請人的年收入增加5000元,他的貸款就會被批準”。
這種解釋方式直觀且易于理解,讓用戶知道需要改變什么才能獲得不同的預測結果。
四、AI可解釋性在各行業的應用
1. 醫療健康領域的應用
在醫療領域,AI可解釋性對于建立信任和確保安全至關重要。一個醫療診斷系統必須是透明的、可理解的、可解釋的,以獲得醫生、監管者和病人的信任。
醫療AI可解釋性的主要應用包括:
- 醫學影像分析:解釋AI系統在X光片、CT或MRI掃描中識別出的異常區域
- 疾病診斷支持:說明AI系統做出特定診斷建議的依據
- 藥物研發:解釋AI在藥物發現和設計中的決策過程
- 患者風險預測:解釋預測某患者發展為重癥的風險因素
如果沒有醫學上可解釋的人工智能,并且醫生無法合理地解釋決策過程,那么患者對他們的信任就會受到侵蝕。
2. 金融領域的應用
金融行業受到嚴格監管,需要對算法決策提供清晰解釋。各方對常見AI黑盒模型的透明度、模型可解釋性的需求變得極其迫切——金融業務不僅需要AI提供準確的預測結果,更要打開"黑盒",向人類展示出其中的數據要素、神經網絡的推理邏輯和決策原因。
金融AI可解釋性的主要應用包括:
- 信貸評估:解釋貸款申請被拒絕或批準的原因
- 欺詐檢測:說明為何某交易被標記為可疑
- 投資建議:解釋AI投資顧問做出特定推薦的依據
- 風險評估:闡明企業或個人風險評分的構成因素
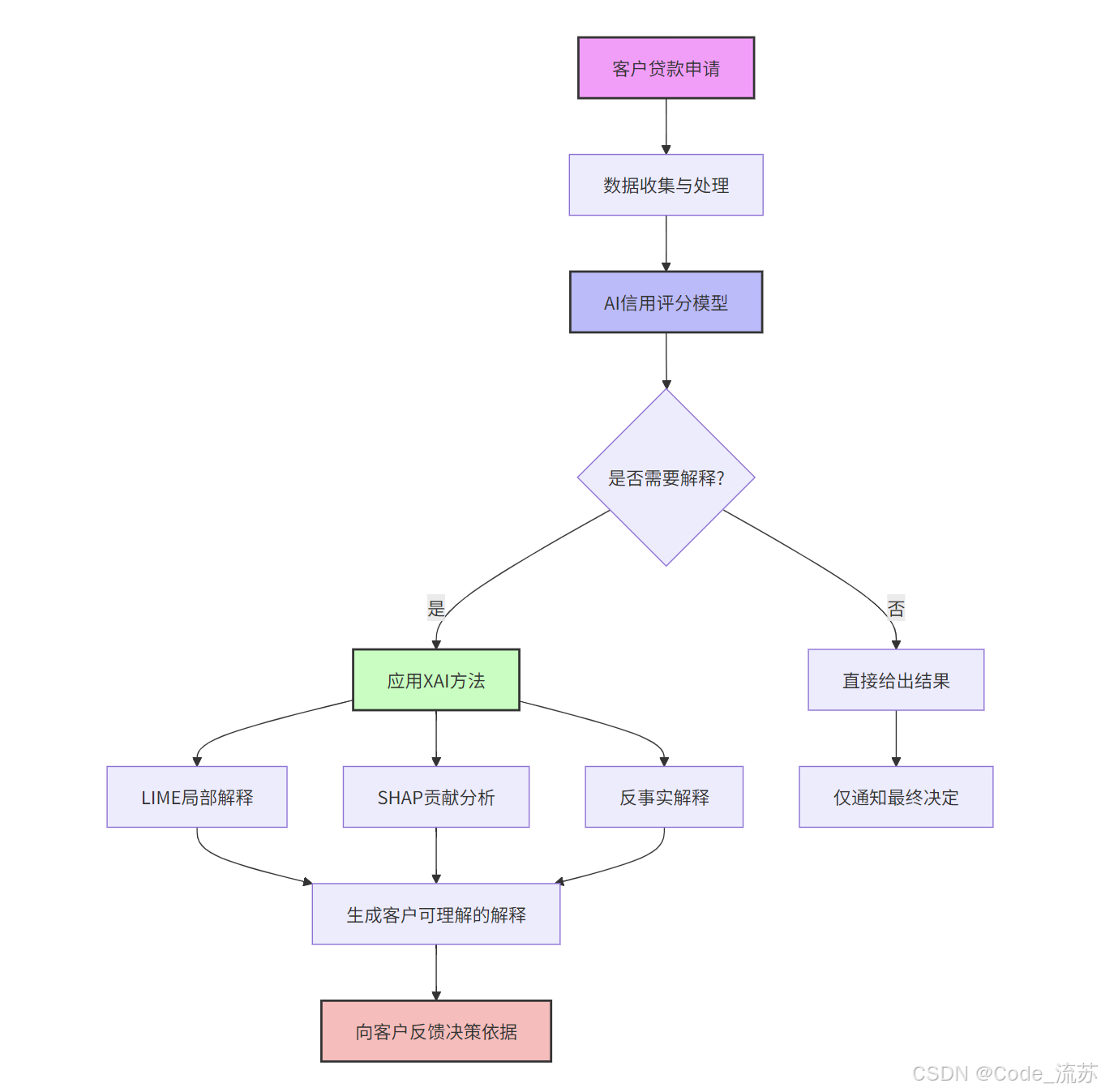
3. 自動駕駛領域的應用
自動駕駛是生命安全攸關的領域,對AI可解釋性有著極高要求。自動駕駛汽車需要能夠解釋其決策過程,以便在出現問題時能夠迅速找出原因。可解釋性AI可以幫助自動駕駛汽車提供更清晰的決策解釋,從而提高其安全性和可靠性。
自動駕駛AI可解釋性的關鍵應用:
- 感知系統解釋:解釋車輛如何識別道路標志、行人和其他車輛
- 決策邏輯透明:說明車輛為何選擇特定行動(如減速、變道)
- 安全事件分析:事故發生后,解釋系統行為的原因
- 預測行為解釋:解釋車輛如何預測其他道路使用者的行為
自動駕駛領域的可解釋性技術通常結合了可視化方法(如注意力熱圖)和決策樹等直觀模型,以幫助用戶理解系統的感知和決策過程。
五、AI可解釋性面臨的挑戰與未來發展
1. 當前面臨的主要挑戰
AI可解釋性領域面臨幾個關鍵挑戰:
- 精度與可解釋性的權衡:高精度的復雜模型通常更難解釋,而簡單易解釋的模型往往精度較低
- 解釋的評估標準:缺乏統一的標準來評估解釋的質量和有效性
- 用戶理解能力差異:不同背景的用戶對AI解釋的理解能力各不相同
- 計算復雜度:某些可解釋性方法(如SHAP)計算成本高昂
- 解釋的穩定性:解釋應在相似輸入下保持一致,但許多方法難以保證這點
盡管SHAP和LIME在不確定性估計、泛化、特征依賴性和因果推理能力等方面存在局限性,但它們在解釋和理解復雜機器學習模型方面仍具有重要價值。
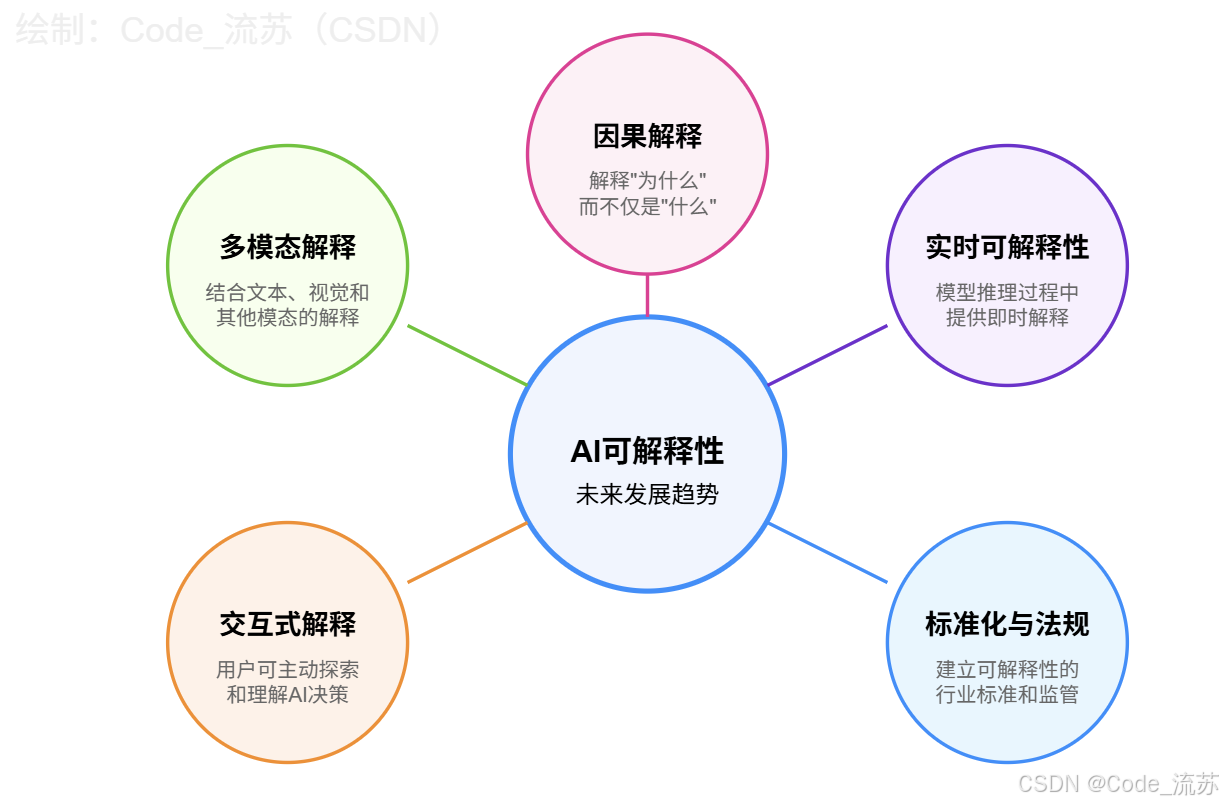
2. 未來發展趨勢
在2024年世界科技與發展論壇上,人工智能十大前沿技術趨勢包括小數據和優質數據、人機對齊、AI使用邊界和倫理監督模型、可解釋性模型等。
AI可解釋性領域的發展趨勢包括:
- 多模態解釋:結合文本、視覺和其他模態的解釋方法
- 交互式解釋:允許用戶通過交互方式探索和理解AI決策
- 實時可解釋性:在模型推理過程中提供即時解釋
- 標準化與法規:建立可解釋性的行業標準和監管框架
- 因果解釋:從相關性向因果性過渡,解釋"為什么"而不僅是"什么"
六、如何實現可解釋的AI系統
1. 設計階段的可解釋性考量
構建可解釋的AI系統應從設計階段開始考慮:
- 選擇適當的模型:在滿足性能要求的情況下,優先選擇天然可解釋的模型(如決策樹、線性模型)
- 特征工程:使用有意義且可理解的特征,避免過于復雜的特征轉換
- 模型結構簡化:在不顯著影響性能的前提下,簡化模型結構
- 可解釋性評估:將可解釋性作為模型評估的重要指標之一
2. 可解釋AI系統實現的代碼示例
下面以Python代碼示例,展示如何使用LIME和SHAP實現模型可解釋性:
1??LIME實現示例
# 導入必要的庫
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from lime import lime_tabular# 假設我們已經有了訓練好的模型和數據
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier()
model.fit(X_train, y_train)# 創建LIME解釋器
explainer = lime_tabular.LimeTabularExplainer(X_train,feature_names=feature_names,class_names=class_names,discretize_continuous=True
)# 為特定樣本生成解釋
instance = X_test[0]
explanation = explainer.explain_instance(instance, model.predict_proba,num_features=10
)# 顯示解釋結果
explanation.show_in_notebook()# 獲取特征重要性
feature_importance = explanation.as_list()
2??SHAP實現示例
# 導入必要的庫
import shap
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier# 假設我們已經有了訓練好的模型和數據
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier()
model.fit(X_train, y_train)# 創建SHAP解釋器
explainer = shap.TreeExplainer(model)# 計算SHAP值
shap_values = explainer.shap_values(X_test)# 可視化單個樣本的SHAP值
shap.force_plot(explainer.expected_value[1], shap_values[1][0,:], X_test.iloc[0,:],feature_names=feature_names
)# 可視化所有樣本的SHAP值匯總
shap.summary_plot(shap_values, X_test, feature_names=feature_names)
3. 實際應用中的最佳實踐
在實際應用中,實現AI可解釋性的最佳實踐包括:
- 多方法結合:同時使用多種可解釋性方法,獲得更全面的理解
- 層次化解釋:提供不同深度的解釋,適應不同用戶需求
- 領域專家參與:解釋過程中結合領域專家知識,提高解釋質量
- 持續驗證:定期驗證解釋的準確性和可靠性
- 反饋機制:建立用戶反饋機制,持續改進解釋質量
金融機構應設置內部治理架構,并指定高級主管或委員會負責AI技術的監督管理,針對幻覺問題,建議強調透明性和可解釋性。
七、結論與展望
AI可解釋性是人工智能發展中不可忽視的關鍵方面,它不僅關系到用戶對AI系統的信任,還影響到AI在關鍵領域的廣泛應用。隨著人工智能技術的不斷進步,可解釋性的重要性只會越來越高。
未來的AI系統將不僅僅追求高精度,還會更加注重透明度和可解釋性。通過結合多種解釋方法,利用可視化技術,以及考慮因果關系,我們能夠構建既強大又透明的AI系統,為各行各業帶來真正的價值。
如何實現黑盒模型的可解釋、從而使AI同時具備精度和可解釋性,成為金融行業能否廣泛采用AI技術的重中之重。
作為開發者和研究者,我們應當積極探索新的可解釋性方法,并將可解釋性作為AI系統設計和評估的重要維度。只有這樣,我們才能構建出真正可信、安全且符合倫理的人工智能系統。
參考資料
- IBM. “What is Explainable AI (XAI)?” IBM Think. 2025.
- 機器之心. “一文探討可解釋深度學習技術在醫療圖像診斷中的應用.” 2020.
- 安全內參. “IAPP發布《2024年人工智能治理實踐報告》.” 2024.
- Ahmed Salih et al. “A Perspective on Explainable Artificial Intelligence Methods: SHAP and LIME.” 2024.
- DataCamp. “Explainable AI, LIME & SHAP for Model Interpretability.” 2023.
- 中國醫院協會信息專業委員會. “案例分享.” 2024.
- 李春曉. “可解釋人工智能(XAI)元年——XAI在金融領域中的應用實踐.” 上海交通大學中銀科技金融學院.
- Steadforce. “Exploring Explainable AI with LIME Technology.” 2024.
- GeeksforGeeks. “Explainable AI(XAI) Using LIME.” 2023.
- Java Code Geeks. “Explainable AI in Production: SHAP and LIME for Real-Time Predictions.” 2025.
創作者:Code_流蘇(CSDN)(一個喜歡古詩詞和編程的Coder😊)

學習曲線)

















)