????????隨著人工智能技術的快速發展,檢索增強生成(RAG)作為一種結合檢索與生成的創新技術,正在重新定義信息檢索的方式,RAG 的核心原理及其在實際應用中的挑戰與解決方案,通用大模型在知識局限性、幻覺問題和數據安全性等方面的不足,隨后詳細介紹了 RAG 通過 “檢索 + 生成” 模式如何有效解決這些問題,RAG 利用向量數據庫高效存儲與檢索目標知識,并結合大模型生成合理答案,RAG 的關鍵技術進行了全面解析,包括文本清洗、文本切塊、向量嵌入、召回優化及提示詞工程等環節,針對 RAG 系統的召回效果與模型回答質量,本文提出了多種評估方法,為實際開發提供了重要參考
一、人工智能術語或書籍
LLM,chatGPT,RAG,Agent 等等的術語,AI:Artificial Intelligence 的縮寫,指 “人工智能”,AIGC:AI Generated Content 的縮寫,意指由人工智能生成的內容。在算法和數碼內容制作領域,AIGC 涉及使用人工智能技術生成各種形式的內容,比如文字、圖像、視頻、音樂,
Transformer:一種用于自然語言處理(NLP)任務的深度學習模型
BERT:Bidirectional Encoder Representations from Transformers 的縮寫,是一種自然語言處理(NLP)的預訓練模型
PEFT:Parameter-Efficient Fine-Tuning 的縮寫,中文高效參數微調
LoRA:Low-Rank Adaptation 的縮寫,一種用于微調大規模語言模型的一種技術
LLM:Large Language Model 的縮寫,指 “大語言模型”
RAG:Retrieval-Augmented Generation 的縮寫,指 “檢索增強生成”,這是一個跨越檢索和生成任務的框架,通過先從數據庫或文檔集合中檢索到相關信息
Agent:中文叫智能體,一個能獨立執行任務和做出決策的實體,在人工智能中
GPT:Generative Pre-trained Transformer 的縮寫,指 “生成式預訓練變換器”
LLaMA:Large Language Model Meta AI 的縮寫,是由 Meta 開發的一系列大型自然語言處理模型
chatGPT:由 OpenAI 開發的一種基于 GPT(生成預訓練變換模型)架構的人工智能聊天機器人
Prompt:指的是提供給模型的一段初始文本,用于引導模型生成后續的內容
Embedding:中文叫嵌入,是一種將高維數據映射到低維空間的技術,但仍盡可能保留原數據的特征和結構。嵌入技術通常用于處理和表示復雜的數據如文本、圖像、音樂以及其他高維度的數據類型
二、向量數據庫
非結構化數據呈現出高速增長的趨勢。圖片、音頻、視頻等非結構化數據的存儲和檢索需求也變得越來越多
IDC DataSphere 數據顯示?IDC FutureScape:2024年中國數據和分析市場十大預測
????????為了更有效地管理非結構化數據,常見的做法是將其轉換為向量表示,并存儲在向量數據庫中。這種轉換過程通常被稱為向量化或嵌入(Embedding)。通過將文本、圖像或其他非結構化數據映射到高維向量空間,我們可以捕捉數據的語義特征和潛在關系。向量數據庫通過在「向量表示」上構建索引,實現快速的相似性搜索。
????????向量數據庫是用于存儲和查詢高維向量數據的數據庫,通常在搜索、推薦系統、圖像識別、自然語言處理等領域中廣泛使用。
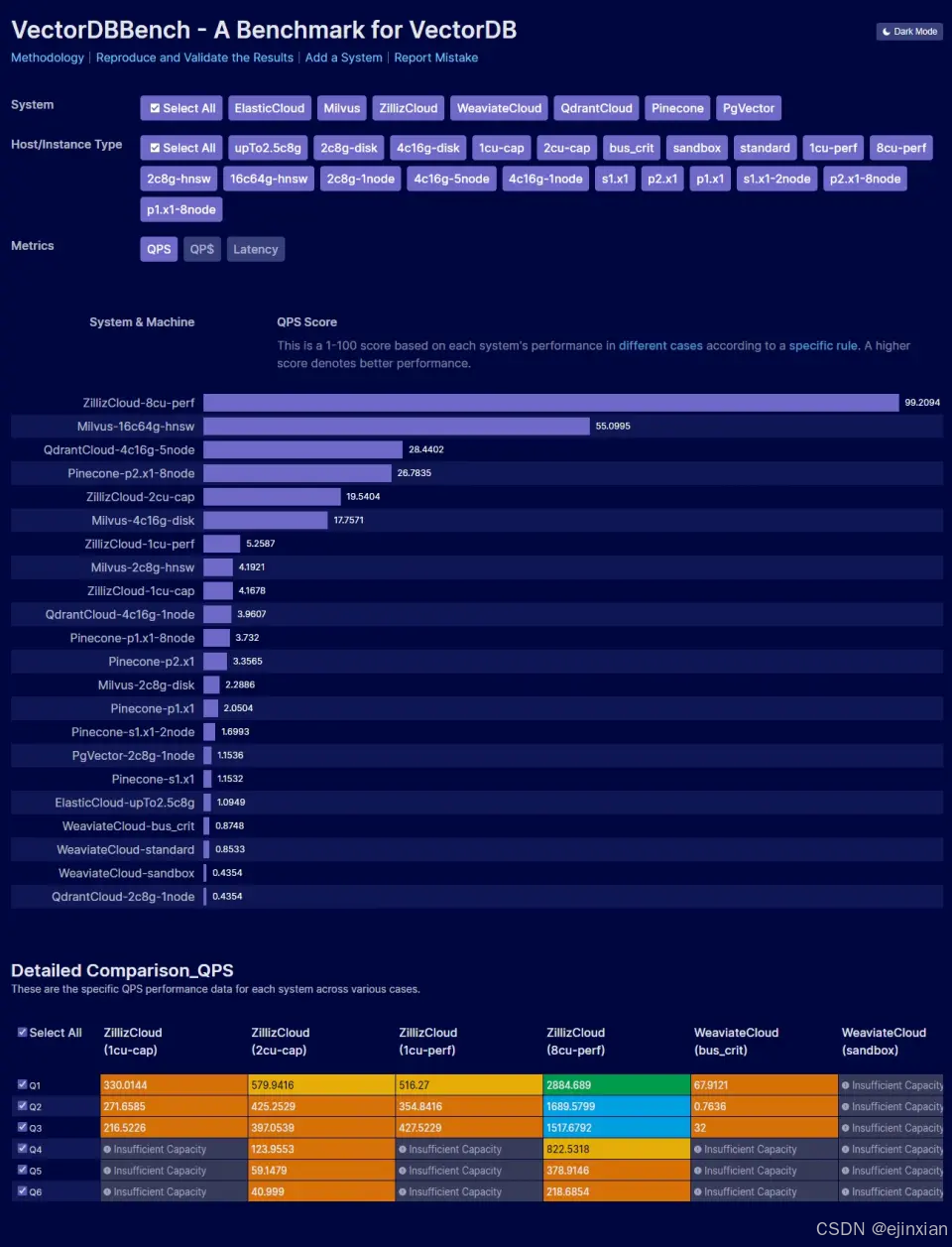
常用的向量數據庫
1. Faiss (Facebook AI Similarity Search):
-
開發者:Facebook AI Research
-
特點:高效的相似性搜索和密集向量聚類,支持 CPU 和 GPU 加速。
-
適用場景:圖像相似性搜索、大規模推薦系統等。
2. Annoy (Approximate Nearest Neighbors Oh Yeah):
-
開發者:Spotify
-
特點:基于內存的高效最近鄰搜索,使用構建的可持久化樹數據結構。
-
適用場景:音樂推薦、快速搜索等。
3. HNSW (Hierarchical Navigable Small World):
-
開發者:Yury Malkov(和其他社區貢獻者)
-
特點:小世界圖算法,高效的近似最近鄰搜索,支持動態插入和刪除。
-
適用場景:實時搜索和推薦系統。
4. Elasticsearch with k-NN Plugin:
-
開發者:Elastic
-
特點:在 Elasticsearch 之上添加 k-NN 搜索功能,結合全文搜索和向量搜索。
-
適用場景:綜合搜索引擎,需要同時支持文本和向量查詢的場景。
5. Milvus:
-
開發者:ZILLIZ
-
特點:分布式、高性能向量數據庫,支持大規模數據管理和檢索。
-
適用場景:圖像、視頻、文本等大規模向量數據的存儲和檢索。
6. Pinecone:
-
開發者:Pinecone
-
特點:專用于機器學習應用程序的向量數據庫,易于集成和擴展。
-
適用場景:個性化推薦、語義搜索、實時機器學習應用等。
7. Weaviate:
-
開發者:SeMI Technologies
-
特點:開源的向量搜索引擎,支持上下文感知的語義搜索,擴展性強。
-
適用場景:知識圖譜構建、語義搜索、推薦系統。
8. Vectara:
-
開發者:Vectara, Inc.
-
特點:基于向量的全托管搜索服務,專注于語義搜索和相關性。
-
適用場景:搜索引擎優化、自然語言處理應用。
????????在向量數據的存儲成本、召回率等方面都面臨較大的挑戰。隨著非結構化數據的進一步增長,成本和召回率的挑戰會變得困難
1. 存儲和索引優化
-
量化技術:使用向量量化(Vector Quantization, VQ)技術,例如產品量化(Product Quantization, PQ)或乘積量化(Additive Quantization, AQ),可以在保證精度的同時大幅度減少存儲和計算資源。
-
壓縮向量:采用哈希方法如局部敏感哈希(Locality-Sensitive Hashing, LSH)來減少存儲消耗,并加速相似性搜索。
-
分布式存儲:使用分布式文件系統和數據庫(如 Apache Hadoop、Cassandra)可以優化存儲和查詢的大規模向量數據。
-
存儲器級別調整:利用固態硬盤(SSD)甚至是新興的持久化內存(Persistent Memory, PMEM)來在內存和磁盤之間找到平衡,優化存儲成本。
2. 召回率優化
-
混合搜索技術:結合粗粒度和細粒度的索引,例如先使用粗濾技術快速縮小搜索范圍,然后進行精確查找。
-
近似最近鄰查找(ANN)算法:如 HNSW(Hierarchical Navigable Small World)圖、FAISS 中使用的 ANN 算法可以在保證高召回率的基礎上優化搜索速度。
-
多層次檢索:分層結構的檢索方法,從粗到細進行,逐步提高召回率和精度。
4. 專用硬件加速
-
GPU 和 TPU:使用專門的硬件加速器,如 GPU(圖形處理單元)或 TPU(張量處理單元),以加速向量計算和相似性搜索。
-
FPGA:使用可編程門陣列(FPGA)為特定向量計算任務定制硬件加速,以提高效率和降低延遲。
5. 持續優化和更新模型
-
動態索引更新:隨著非結構化數據的增長和變化,保持索引和向量表示的及時性,使用在線或增量更新的方法管理索引。
-
自適應模型:利用機器學習和深度學習模型不斷優化向量表示的嵌入質量,使得向量檢索更加精準有效
6. 先進的嵌入技術
-
預訓練模型:使用當前的預訓練語言模型(如 BERT、GPT-3)進行上下文嵌入,捕捉復雜的語義信息。
-
多模態嵌入:對于不同類型的數據(如文本、圖像、視頻),使用多模態嵌入模型來統一表示和處理,提升檢索性能。
-
AutoGen 框架
AutoGen 是一個能讓多個 Agent 進行溝通協作的 Python 開源框架。核心解決兩個問題:
第一個問題:如何設計用戶可定制、可重用的、能夠互相協作的 Agent。AutoGen 是要設計為一個通用的能夠適用多種場景的框架,在 AutoGen 的官網 Examples 中給出了在多種場景下能夠解決問題的例子,此外在 git 倉庫中的 notbook 目錄中有 50 + 例子。有解決數學問題場景、有通過開發代碼進行分析的場景(比如上一章節的列子)、還有通過五六個 Agent 討論分析開放問題的場景。所以 Agent 的擴展能力是需要重要考慮問題,AutoGen 中通過支持多種外部工具、不同 LLM、支持 human in the loop 的方式,Agent 之間能夠通信的方式來解決擴展問題。
第二個問題:如何讓 Agent 能靈活支持不同模式的會話方式。不同的場景,根據復雜度、問題的類型需要不同的 Agent 會話模式。這里的 “模式” 包括了單輪對話 or 多輪對話、自動選擇每輪的 speaker or 通過規則選擇、通過自然語言控制邏輯 or 通過代碼控制,此外設計需要考慮多個 Agent 之間如何靈活 “組網”,比如三人一組,每組一個 leader,組內互相通信,leader 能夠通信的方式。
為了解決這兩個問題,AutoGen 抽象了一些基礎概念。
Conversable Agents
旨在用于在復雜任務中進行多輪交互。這些智能體能夠理解和處理用戶輸入,維護上下文,并生成合適的響應。Conversable Agents 通常集成了自然語言處理技術,包括自然語言理解(NLU)和自然語言生成(NLG),以提高對話的流暢性和智能性
Conversation Programming
旨在通過自然語言與人工智能系統進行交互,來實現編程和任務自動化。這個概念試圖簡化編程過程,使得用戶無需深厚的編程背景也能使用自然語言描述需求,進而生成可執行的代碼或自動化腳本。
MetaGPT 的主要工作流程和特點包括:
-
角色定義(Role Definitions):MetaGPT 通過定義不同的角色(如產品經理、架構師、項目經理等)來封裝每個角色的特定技能和業務流程。這些角色類繼承自一個基礎角色類,具有名稱、簡介、目標、約束和描述等關鍵屬性。角色定義幫助 LLM 生成符合特定角色要求的行為。
-
任務分解(Task Decomposition):MetaGPT 將復雜的軟件開發任務分解成更小、更易于管理的部分,然后將這些子任務分配給合適的智能體執行。
-
流程標準化(Process Standardization):MetaGPT 定義了一系列標準化操作,每個操作都具有前綴、LLM 代理、標準化輸出模式、執行內容、重試機制等屬性。這些標準化操作確保了智能體之間的協作是一致的,輸出的結果也是結構化的。
-
知識共享(Knowledge Sharing):MetaGPT 通過環境日志復制消息,智能體可以根據自己的角色訂閱感興趣的消息類型。這種方式使智能體可以主動獲取相關信息,而不是被動地通過對話獲取。
-
端到端開發(End-to-End Development):從產品需求到技術設計,再到具體編碼,MetaGPT 通過多智能體的協作可以完成整個軟件開發生命周期。
RAG 的工作流程涉及 3 個主要階段:數據準備、數據召回和答案生成。數據準備階段包括識別數據源、從數據源提取數據、清洗數據并將其存儲在數據庫中。數據召回階段包括根據用戶輸入的查詢條件從數據庫中檢索相關數據。答案生成階段則是利用檢索到的數據和用戶輸入的查詢條件生成輸出結果。輸出質量的高低取決于數據質量和檢索策略。

-
數據準備
根據 LLM 需要處理的任務類型,數據準備通常包括識別數據源、從數據源中提取數據、清洗數據并將其存儲在數據庫中等環節。用于存儲數據的數據庫類型和準備數據的步驟可能會因應用場景和檢索方法的不同而有所變化。例如,如果使用像 Faiss 這樣的向量存儲庫,需要為數據創建嵌入并將其存儲在向量存儲庫中;如果使用像 Elasticsearch 這樣的搜索引擎,需要將數據索引到搜索引擎中;如果使用像 Neo4j 這樣的圖數據庫,需要為數據創建節點和邊,并將它們存儲到圖數據庫中
RAG 的優點。
高質量的答案生成,降低答案生成的幻覺
RAG 的一個優點是它能夠生成高質量的回答。因為在生成過程中,檢索器可以從大量文檔中檢索問題相關的信息,然后基于這些信息生成回答。這使得整個系統能夠充分利用現有知識生成更準確、更具深度的回答,也意味著模型出現幻覺答案的概率更小。
五、大模型框架
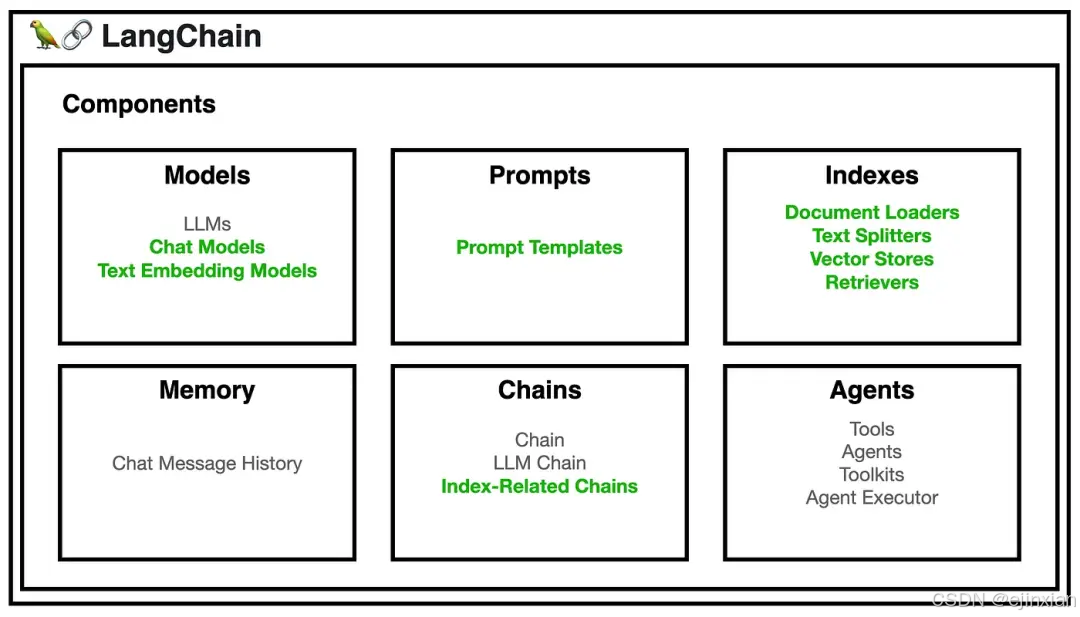
LangChain 是一個開源的應用開發框架,目前支持 Python 和 TypeScript 兩種編程語言。它賦予 LLM 兩大核心能力:數據感知,將語言模型與其他數據源相連接;代理能力,允許語言模型與其環境互動。
來源
-
《大模型 RAG 實戰:RAG 原理、應用與系統構建》:https://m.douban.com/book/subject/37104428/
-
《從 AIGC 典型客戶實踐揭秘云原生向量數據庫內核設計與智能創新》:?https://www.infoq.cn/article/5frz8imatl9yevqjofct
-
AutoGen Blog 官網:?https://microsoft.github.io/autogen/0.2/blog/
-
《AI Agent【項目實戰】:MetaGPT 遇上元編程,重塑復雜多智能體協作的邊界》:?https://xie.infoq.cn/article/a9977d01e3131bf951ba28e72
?













)




【附代碼文檔】)
![[dp5_多狀態dp] 按摩師 | 打家劫舍 II | 刪除并獲得點數 | 粉刷房子](http://pic.xiahunao.cn/[dp5_多狀態dp] 按摩師 | 打家劫舍 II | 刪除并獲得點數 | 粉刷房子)