主要參考學習資料:
《動手學深度學習》阿斯頓·張 等 著
【動手學深度學習 PyTorch版】嗶哩嗶哩@跟李牧學AI
概述
- 硬件性能和大數據的發展為深度卷積神經網絡(AlexNet)的實現提供了條件。
- VGG首次將塊的思想用于搭建網絡。
- NiN將多層感知機應用在每個像素上以取代最終的全連接層。
- GoogLeNet將不同卷積核大小的卷積層并行連接。
- 批量規范化可加速深層網絡的收斂。
- ResNet用函數參數化思想緩解了深層網絡的退化問題。
- DenseNet是ResNet在函數展開上的邏輯擴展。
目錄
- 7.1 深度卷積神經網絡(AlexNet)
- 7.1.1 學習表征
- 1. 數據
- 2. 硬件
- 7.1.2 AlexNet
- 7.1.3 讀取數據集
- 7.1.4 訓練AlexNet
- 7.2 使用塊的網絡(VGG)
- 7.2.1 VGG塊
- 7.2.2 VGG網絡
- 7.2.3 訓練模型
- 7.3 網絡中的網絡(NiN)
- 7.3.1 NiN塊
- 7.3.2 NiN模型
- 7.3.3 訓練模型
- 7.4 含并行連接的網絡(GoogLeNet)
- 7.4.1 Inception塊
- 7.4.2 GoogLeNet模型
- 7.4.3 訓練模型
- 7.5 批量規范化
- 7.5.1 訓練深層網絡
- 7.5.2 批量規范化層
- 1.全連接層
- 2.卷積層
- 3.預測
- 7.5.3 從零實現
- 7.5.4 使用批量規范化層的LeNet
- 7.5.5 簡明實現
- 7.6 殘差網絡(ResNet)
- 7.6.1 函數類
- 7.6.2 殘差塊
- 7.6.3 ResNet模型
- 7.6.4 訓練模型
- 7.7 稠密連接網絡(DenseNet)
- 7.7.1 從ResNet到DenseNet
- 7.7.2 稠密塊體
- 7.7.3 過渡層
- 7.7.4 DenseNet模型
- 7.7.5 訓練模型
7.1 深度卷積神經網絡(AlexNet)
提出LeNet后的一段時間里,出于以下幾點原因,神經網絡未能超越機器學習主導圖像分類領域:
- 硬件不足以開發出有大量參數的深層多通道多層卷積神經網絡。
- 數據集相對較小。
- 訓練神經網絡的一些關鍵技巧仍然確實。
和神經網絡訓練端到端的系統不同,經典機器學習的過程如下:
- ①獲取一個有趣的數據集。
- ②根據光學、幾何學、其他知識以及偶然的發現,手動對特征數據集進行預處理。
- ③通過標準的特征提取算法或其他手動調整的流水線來輸入數據。
- ④將提取的特征送入最喜歡的分類器中以訓練分類器。
7.1.1 學習表征
另一個影響圖像分類領域發展的重要因素是圖像特征的提取方法。
在2012年前,圖像特征是機械地計算出來的,設計一套新的特征函數、改進結果并撰寫論文是盛極一時的潮流。
另一批研究人員認為特征本身應該被學習,并在合理的復雜性前提下,應該由多個共同學習的神經網絡層組成,基于此提出的AlexNet在2012年ImageNet挑戰賽中取得了轟動一時的成績。
在AlexNet的底層,模型學習到了一些類似傳統濾波器的特征提取器,而較高層建立在這些底層表示的基礎上以表示更大的特征,更高的層可以檢測整個物體,最終的隱藏神經元可以學習圖像的綜合表示。這一突破可歸因于以下兩個關鍵因素:
1. 數據
包含許多特征的深度模型需要大量有標簽數據才能顯著優于基于凸優化的傳統方法,然而限于早期計算機有限的存儲資源和研究預算,大部分研究只基于小的公開數據集。隨著大數據的發展,直至2009年,擁有涵蓋一千個類別的一百萬多個樣本的ImageNet數據集發布,以此為基礎發起的挑戰賽推動了計算機視覺和機器學習研究的發展。
2. 硬件
深度學習對計算資源要求很高,訓練可能需要數百輪,每次迭代需要通過代價高昂的許多線性代數層傳遞數據,因此早期優化凸目標的簡單算法是研究人員的首選。GPU訓練神經網絡改變了這一格局。
圖形處理器(GPU)早期用來加速圖形處理以服務于電腦游戲。GPU可優化高吞吐量的 4 × 4 4\times4 4×4矩陣和向量乘法,這些數學運算與卷積層的計算驚人地相似。
GPU相對于CPU的優勢如下:
- CPU的核時鐘頻率高,性能高,但制造成本也高,需要大量芯片面積、復雜支持結構,且單任務性能相對較差,總體性價比不高。
- GPU由成百上千個小處理單元組成,通常被分成更大的組。單個核時鐘頻率低,性能較弱,但龐大的核數量使GPU比CPU快幾個數量級。其原因在于功耗隨時鐘頻率呈平方級增長,且GPU簡單的內核更節能,最后GPU滿足了深度學習需要的高內存帶寬。
7.1.2 AlexNet
AlexNet與LeNet架構對比
卷積層(更多的層數和輸出通道):
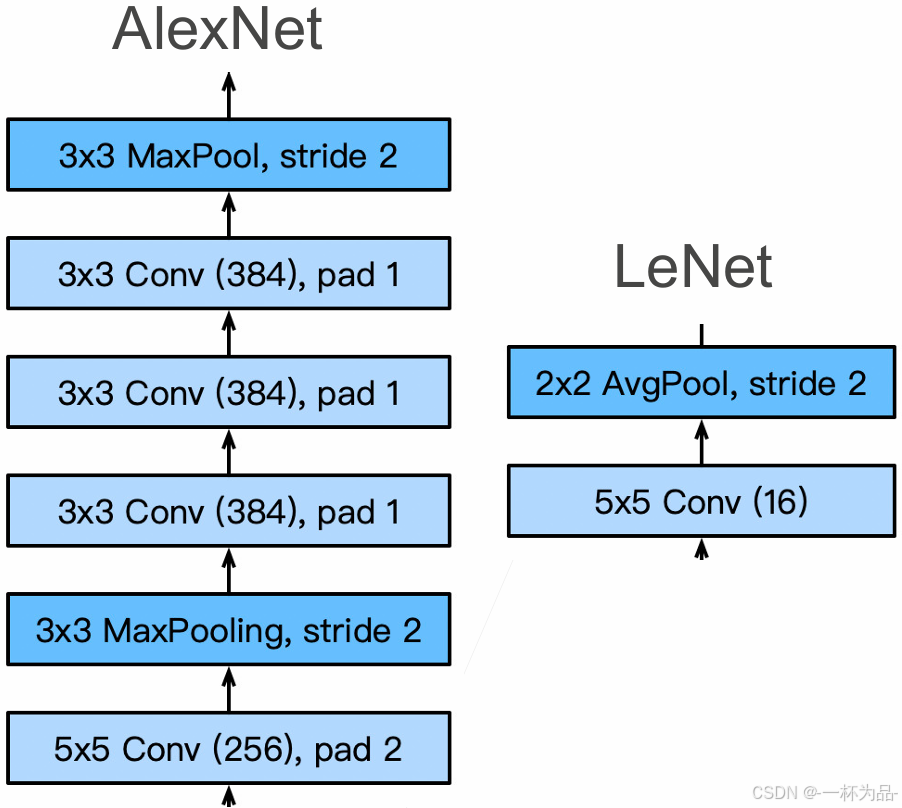
全連接層(更多的輸出):
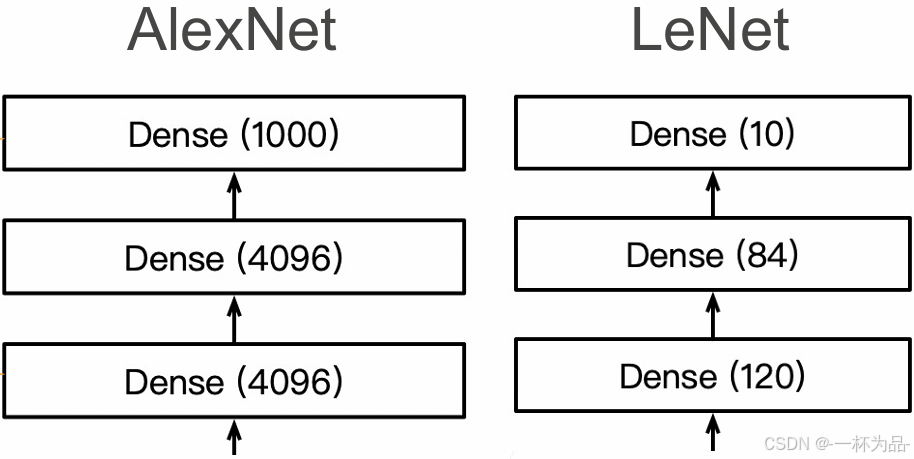
除此之外,AlexNet還采用了早期沒有的ReLU激活函數和暫退法。
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as pltnet = nn.Sequential( nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(), nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 10)
)
7.1.3 讀取數據集
訓練ImageNet模型可能需要數小時乃至數天,因此我們仍使用Fashion-MNIST數據集,但為了使用AlexNet架構需要將其分辨率提高到 224 × 224 224\times224 224×224像素。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
7.1.4 訓練AlexNet
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
訓練結果:
loss 0.326, train acc 0.880, test acc 0.880
407.4 examples/sec on cuda:0

7.2 使用塊的網絡(VGG)
使用塊的想法首先出現在VGG網絡中。
7.2.1 VGG塊
一個VGG塊由一系列卷積層組成,再加上用于空間降采樣的最大匯聚層。

import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt#參數分別為卷積層數量、輸入通道數量、輸出通道數量
def vgg_block(num_convs, in_channel, out_channel): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1)) layers.append(nn.ReLU()) in_channel = out_channel layers.append(nn.MaxPool2d(kernel_size=2, stride=2)) return nn.Sequential(*layers)
7.2.2 VGG網絡
VGG網絡由數個VGG塊構成的卷積層和全連接層組成,每個VGG塊由超參數conv_arch指定卷積層個數和每個卷積層的輸出通道數。
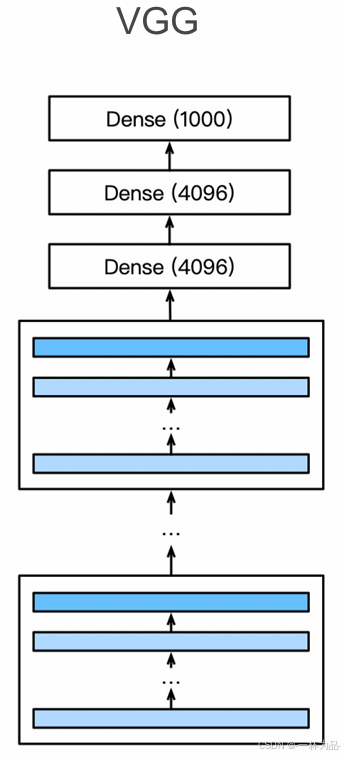
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) def vgg(conv_arch): conv_blks = [] in_channels = 1 for (num_convs, out_channels) in conv_arch: conv_blks.append(vgg_block(num_convs, in_channels, out_channels)) in_channels = out_channels return nn.Sequential( *conv_blks, nn.Flatten(), nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 10)) net = vgg(conv_arch)
7.2.3 訓練模型
由于VGG-11比AlexNet計算量更大,我們構建一個通道數較少的網絡,足夠用于訓練Fashion-MNIST數據集。
#將每層的輸出通道數除以4
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch) lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
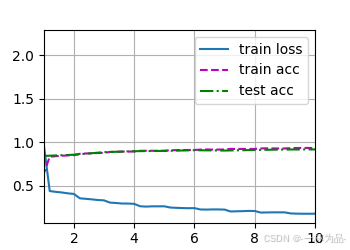
訓練結果:
loss 0.179, train acc 0.933, test acc 0.917
333.2 examples/sec on cuda:0
7.3 網絡中的網絡(NiN)
LeNet、AlexNet和VGG最終都使用全連接層對特征進行表征處理,然而全連接層可能會完全放棄表征的空間結構。NiN的解決方案是在每個像素的通道上分別使用多層感知機( 1 × 1 1\times1 1×1卷積層)。
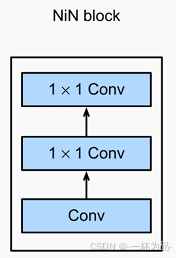
7.3.1 NiN塊
NiN塊以一個普通卷積層開始,后面是兩個 1 × 1 1\times1 1×1卷積層,它們充當帶有ReLU激活函數的逐像素全連接層。
import torch
from torch import nn
from d2l import torch as d2l def nin_block(in_channels, out_channels, kernel_size, strides, padding): return nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
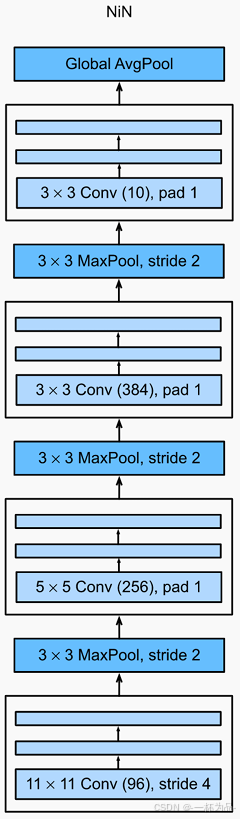
7.3.2 NiN模型
NiN使用卷積核大小分別為 11 × 11 11\times11 11×11、 5 × 5 5\times5 5×5、 3 × 3 3\times3 3×3的卷積層,輸出通道數與AlexNet相同。每個NiN塊后有一個最大匯聚層,匯聚窗口形狀為 3 × 3 3\times3 3×3,步幅為 2 2 2。NiN完全取消了全連接層,而是使用一個輸出通道數等于標簽類別數的NiN塊和一個全局平均匯聚層來生成對數幾率。
net = nn.Sequential( nin_block(1, 96, kernel_size=11, strides=4, padding=0), nn.MaxPool2d(kernel_size=3, stride=2), nin_block(96, 256, kernel_size=5, strides=1, padding=2), nn.MaxPool2d(kernel_size=3, stride=2), nin_block(256, 384, kernel_size=3, strides=1, padding=1), nn.MaxPool2d(kernel_size=3, stride=2), nin_block(384, 10, kernel_size=3, strides=1, padding=1), nn.AdaptiveAvgPool2d(1), nn.Flatten())
7.3.3 訓練模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
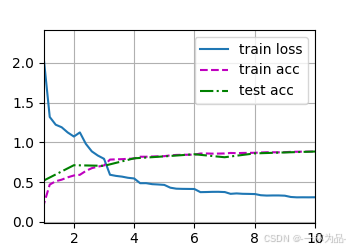
訓練結果:
loss 0.310, train acc 0.885, test acc 0.885
385.2 examples/sec on cuda:0
7.4 含并行連接的網絡(GoogLeNet)
GoogLeNet在2014年的ImageNet挑戰賽大放異彩,它吸收并改進了NiN中串聯網絡的思想,還提出了使用不同大小的卷積核組合是有利的以解決多大的卷積核最合適的問題。
7.4.1 Inception塊
Inception塊由 4 4 4條并行路徑組成。前 3 3 3條路徑使用卷積核大小為 1 × 1 1\times1 1×1、 3 × 3 3\times3 3×3、 5 × 5 5\times5 5×5的卷積層,從不同的空間大小提取信息。中間的 2 2 2條路徑在輸入上執行 1 × 1 1\times1 1×1卷積以減少通道數從而降低模型復雜度。第 4 4 4條路徑使用 3 × 3 3\times3 3×3最大匯聚層,然后使用 1 × 1 1\times1 1×1卷積層改變通道數。所有路徑都使用合適的填充使輸入和輸出的高度和寬度一致,最后每條路徑的輸出在通道維度上合并構成Inception塊的輸出。Inception塊的超參數是每層輸出通道數。

import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
from matplotlib import pyplot as pltclass Inception(nn.Module): def __init__(self, in_channels, c1, c2, c3, c4, **kwargs): super(Inception, self).__init__(**kwargs) #編號代表第幾條路徑的第幾層self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1) self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1) self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1) self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1) self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2) self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) self.p4_2 = nn.Conv2d(in_channels, c4[0], kernel_size=1) def forward(self, x): p1 = F.relu(self.p1_1(x)) p2 = F.relu(self.p2_2(F.relu(self.p2_1(x)))) p3 = F.relu(self.p3_2(F.relu(self.p3_1(x)))) p4 = F.relu(self.p4_2(self.p4_1(x))) return torch.cat([p1, p2, p3, p4], dim=1)
7.4.2 GoogLeNet模型
GoogLeNet使用 9 9 9個Inception塊和全局平均匯聚層的堆疊來生成其估計值,Inception塊之間的最大匯聚層可降低維度。
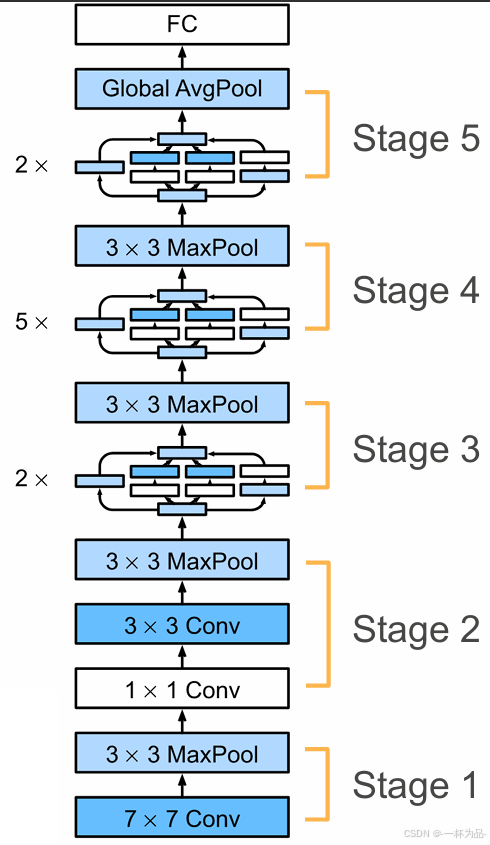
模塊一
- 64 64 64通道 7 × 7 7\times7 7×7卷積層
- 3 × 3 3\times3 3×3最大匯聚層
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
模塊二
- 64 64 64通道 1 × 1 1\times1 1×1卷積層
- 192 192 192通道 3 × 3 3\times3 3×3卷積層
- 3 × 3 3\times3 3×3最大匯聚層
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(), nn.Conv2d(64, 192, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
模塊三
- 256 ( 64 + 128 + 32 + 32 ) 256(64+128+32+32) 256(64+128+32+32)通道Inception塊
- 480 ( 128 + 192 + 96 + 64 ) 480(128+192+96+64) 480(128+192+96+64)通道Inception塊
- 3 × 3 3\times3 3×3最大匯聚層
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32), Inception(256, 128, (128, 192), (32, 96), 64), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
模塊四
- 512 ( 192 + 208 + 48 + 64 ) 512(192+208+48+64) 512(192+208+48+64)通道Inception塊
- 512 ( 160 + 224 + 64 + 64 ) 512(160+224+64+64) 512(160+224+64+64)通道Inception塊
- 512 ( 128 + 256 + 64 + 64 ) 512(128+256+64+64) 512(128+256+64+64)通道Inception塊
- 528 ( 112 + 288 + 64 + 64 ) 528(112+288+64+64) 528(112+288+64+64)通道Inception塊
- 832 ( 256 + 320 + 128 + 128 ) 832(256+320+128+128) 832(256+320+128+128)通道Inception塊
- 3 × 3 3\times3 3×3最大匯聚層
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64), Inception(512, 160, (112, 224), (24, 64), 64), Inception(512, 128, (128, 256), (24, 64), 64), Inception(512, 112, (144, 288), (32, 64), 64), Inception(528, 256, (160, 320), (32, 128), 128), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
模塊五
- 832 ( 256 + 320 + 128 + 128 ) 832(256+320+128+128) 832(256+320+128+128)通道Inception塊
- 1024 ( 384 + 384 + 128 + 128 ) 1024(384+384+128+128) 1024(384+384+128+128)通道Inception塊
- 全局平均匯聚層
- 展平層
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128), Inception(832, 384, (192, 384), (48, 128), 128), nn.AdaptiveAvgPool2d(1), nn.Flatten()) #再連接一個輸出個數為標簽類別數的全連接層
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
7.4.3 訓練模型
GoogLeNet模型計算復雜,而且不如VGG便于修改通道數,為縮短訓練過程我們將輸入的高度和寬度從 224 224 224降為 96 96 96。
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
訓練結果:
loss 0.248, train acc 0.904, test acc 0.864
601.7 examples/sec on cuda:0
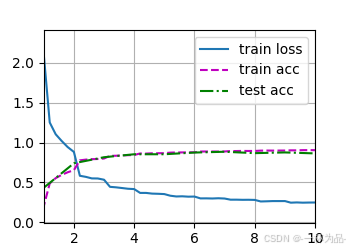
7.5 批量規范化
訓練深層神經網絡十分困難,特別是想要在較短的時間內使它們收斂。批量規范化可持續加速深層網絡的收斂。
7.5.1 訓練深層網絡
神經網絡需要批量規范化層的原因如下:
- 數據預處理的方式通常會對最終結果產生巨大影響。
- 中間層中的變量可能具有更廣的變化范圍,批量規范化的發明者非正式地假設變量分布中的這種偏移可能會阻礙網絡的收斂。
- 更深層的網絡更復雜,也更容易過擬合,意味著正則化變得更加重要。
另一種說法是,由于深層網絡得到的梯度比淺層大,參數更新也會更快,因而當輸入數據的分布發生變化時,深層網絡的參數會受到更大的影響而極不穩定。
批量規范化的原理是在每次訓練迭代中首先規范化輸入,即減去其均值并除以其標準差,使其均值為 0 0 0,標準差為 1 1 1,再應用比例系數和比例偏移。只有使用足夠大的小批量,批量規范化才是有效且穩定的。對于來自小批量 B B B的輸入 x \boldsymbol x x:
B N ( x ) = γ ⊙ x ? μ ^ B σ ^ B + β \mathrm{BN}(\boldsymbol x)=\gamma\odot\displaystyle\frac{\boldsymbol x-\hat{\boldsymbol\mu}_B}{\hat{\boldsymbol\sigma}_B}+\beta BN(x)=γ⊙σ^B?x?μ^?B??+β
由于標準化處理是一個主觀選擇,因此引入模型學習的與 x \boldsymbol x x形狀相同的拉伸參數 γ \gamma γ和偏移參數 β \beta β。小批量 B B B的樣本均值和標準差如下計算:
μ ^ B = 1 ∣ B ∣ ∑ x ∈ B x \hat{\boldsymbol\mu}_B=\displaystyle\frac1{|B|}\sum_{\boldsymbol x\in B}\boldsymbol x μ^?B?=∣B∣1?x∈B∑?x
σ ^ B 2 = 1 ∣ B ∣ ∑ x ∈ B ( x ? μ ^ B ) 2 + ? \hat{\boldsymbol\sigma}^2_B=\displaystyle\frac1{|B|}\sum_{\boldsymbol x\in B}(\boldsymbol x-\hat{\boldsymbol\mu}_B)^2+\epsilon σ^B2?=∣B∣1?x∈B∑?(x?μ^?B?)2+?
小常量 ? > 0 \epsilon>0 ?>0確保分母不為零。
均值和方差的噪聲估計抵消了縮放效應。事實證明,這些優化中的各種噪聲源通常會實現更快的訓練和較少的過擬合,但尚未在理論上明確證明。
7.5.2 批量規范化層
1.全連接層
通常我們將批量規范化層置于全連接層中的仿射變換與激活函數之間:
h = ? ( B N ( W x + b ) ) \boldsymbol h=\phi(\mathrm{BN}(\boldsymbol{Wx}+b)) h=?(BN(Wx+b))
2.卷積層
卷積層可以在卷積層之后和非線性激活函數之前應用批量規范化。在多輸出通道情況下,每個通道有自己的拉伸參數和偏移參數以對各自的輸出執行批量規范化。假設小批量包含 m m m個樣本,且對于每個通道卷積的輸出高度為 p p p、寬度為 q q q,則我們在每個輸出通道上的 m ? p ? q m\cdot p\cdot q m?p?q個元素進行批量規范化。
3.預測
批量規范化在訓練和預測時的行為通常不同,我們不再需要樣本噪聲,也可能需要對單個樣本進行預測。一種常用的方法是使用訓練集移動平均所得的樣本均值和方差來得到確定的輸出。移動平均是在不知道全局數據的情況下對均值和方差進行動態估計的方法,其將過去樣本的移動平均估計值與新樣本的統計值加權相加。
7.5.3 從零實現
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as pltdef batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum): #判斷是預測模式還是訓練模式 if not torch.is_grad_enabled(): #預測模式傳入移動平均所得均值和方差X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) else: #限定X來自全連接層或卷積層assert len(X.shape) in (2, 4) if len(X.shape) == 2: #全連接層計算特征維上的均值和方差mean = X.mean(dim=0) var = X.var(dim=0) else: #卷積層計算通道上(axis=1)的均值和方差#保持X的形狀以便廣播mean = X.mean(dim=(0, 2, 3), keepdim=True) var = X.var(dim=(0, 2, 3), keepdim=True) #訓練模式用當前均值和方差做標準化X_hat = (X - mean) / torch.sqrt(var + eps) #更新移動平均的均值和方差moving_mean = momentum * moving_mean + (1 - momentum) * mean moving_var = momentum * moving_var + (1 - momentum) * var #縮放和移位Y = gamma * X_hat + beta return Y, moving_mean.detach(), moving_var.detach()#批量規范化層
class BatchNorm(nn.Module): #num_features:全連接層的輸出數量或卷積層的輸出通道數#num_dims:2表示全連接層,4表示卷積層def __init__(self, num_features, num_dims): super().__init__() if num_dims == 2: shape = (1, num_features) else: shape = (1, num_features, 1, 1) #初始化參與梯度的拉伸參數、偏移參數self.gamma = nn.Parameter(torch.ones(shape)) self.beta = nn.Parameter(torch.zeros(shape)) #初始化非模型參數移動均值和移動方差 self.moving_mean = torch.zeros(shape) self.moving_var = torch.ones(shape) def forward(self, X): #同一設備計算if self.moving_mean.device != X.device: self.moving_mean = self.moving_mean.to(X.device) self.moving_var = self.moving_var.to(X.device) Y, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta, self.moving_mean, self.moving_var, eps=1e-5, momentum=0.9) return Y
7.5.4 使用批量規范化層的LeNet
#將批量規范化層應用在卷積層和全連接層之后、激活函數之前
net = nn.Sequential( nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16 * 4 * 4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(), nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(), nn.Linear(84, 10)) #訓練與6.6相同,但學習率大得多
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
訓練效果:
loss 0.267, train acc 0.902, test acc 0.842
21184.6 examples/sec on cuda:0
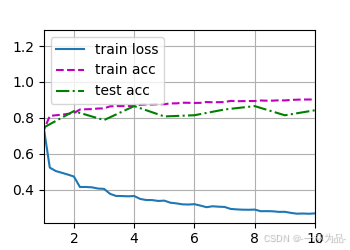
7.5.5 簡明實現
pytorch框架定義了批量規范化層,其中BatchNorm1d應用于全連接層,BatchNorm2d應用于卷積層。
net = nn.Sequential( nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16 * 4 * 4, 120), nn.BatchNorm1d(120, num_dims=2), nn.Sigmoid(), nn.Linear(120, 84), nn.BatchNorm1d(84, num_dims=2), nn.Sigmoid(), nn.Linear(84, 10))
7.6 殘差網絡(ResNet)
殘差網絡基于網絡退化問題而提出,當時的研究者發現,模型的深度越大,其訓練效果未必會提升,反而可能下降。
7.6.1 函數類
假設有一類特定的神經網絡架構 F F F(函數類)可以學習到的函數為 f ∈ F f\in F f∈F,而我們真正需要的函數是 f ? f^* f?。通常 f ? ? F f^*\notin F f?∈/F,因此我們只能在 F F F中尋找最接近 f ? f^* f?的函數 f F ? f^*_F fF??,而我們尋找的方法即是對給定的 X \boldsymbol X X特征和 y \boldsymbol y y標簽的數據集解決如下優化問題:
f F ? : = a r g m i n f L ( X , y , f ) , f ∈ F f^*_F:=\underset f{\mathrm{argmin}}L(\boldsymbol X,\boldsymbol y,f),f\in F fF??:=fargmin?L(X,y,f),f∈F
要得到更接近 f ? f^* f?的函數只有設計更強大的架構 F ′ F' F′,使 f F ′ ? f^*_{F'} fF′??比 f F ? f^*_F fF??更接近 f ? f^* f?。然而如果 F ? F ′ F\nsubseteq F' F?F′(非嵌套函數類),更復雜的函數類并不意味著向 f ? f^* f?靠攏,但嵌套函數類則可以保證這一點:
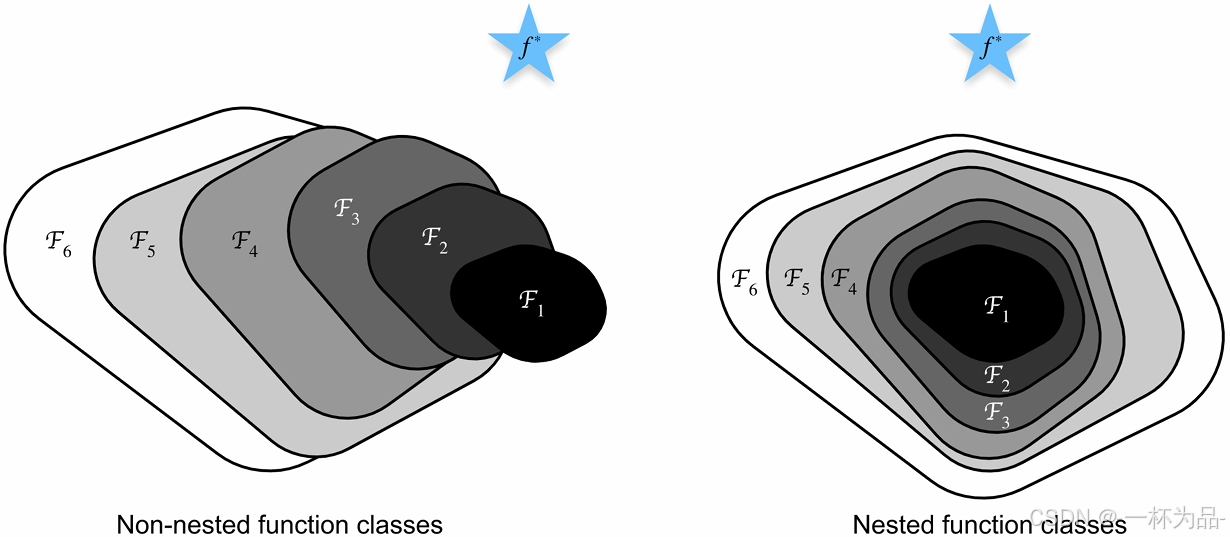
由此,如果新添加的層可以被訓練為恒等函數 f ( x ) = x f(\boldsymbol x)=\boldsymbol x f(x)=x,那么它既可以保證和原模型一樣的效果,也可能得出更優解。
7.6.2 殘差塊
殘差塊在正常塊的基礎上引出一條路徑讓輸入與輸出直接相加,這樣即是新的塊沒有從訓練中得到任何東西,新模型也能保證和原模型有一樣的效果(權重和偏置參數設置成 0 0 0)。此外,輸入在殘差塊中還可以通過跨層數據更快地向前傳播。殘差塊的引入只會讓原模型朝著接近目標函數的方向發展。

ResNet殘差塊的細節設計基于VGG塊,額外路徑中可選的 1 × 1 1\times1 1×1卷積層負責處理輸入以匹配原有塊輸出通道融合的情況:
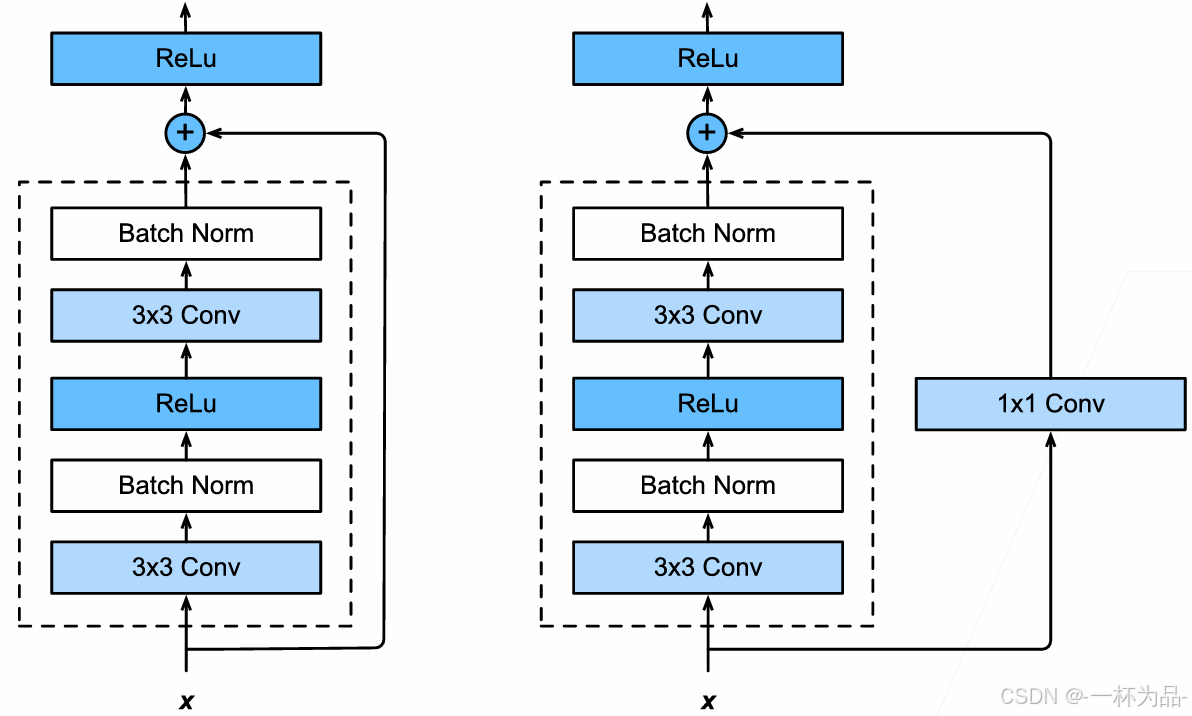
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
from matplotlib import pyplot as pltclass Residual(nn.Module): def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1): super().__init__() self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, stride=strides, padding=1) self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) if use_1x1conv: self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides) else: self.conv3 = None self.bn1 = nn.BatchNorm2d(num_channels) self.bn2 = nn.BatchNorm2d(num_channels) def forward(self, X): Y = F.relu(self.bn1(self.conv1(X))) Y = self.bn2(self.conv2(Y)) if self.conv3: X = self.conv3(X) Y += X return F.relu(Y)
7.6.3 ResNet模型
ResNet前兩層與GoogLeNet一樣,但在卷積層后增加了批量規范化層。后面ResNet使用 4 4 4個由殘差塊組成的模塊,每個模塊使用若干輸出通道數相同的殘差塊,其中后 3 3 3個模塊包含 1 × 1 1\times1 1×1卷積處理。最后與GoogLeNet一樣使用全局平均匯聚層和全連接層輸出:
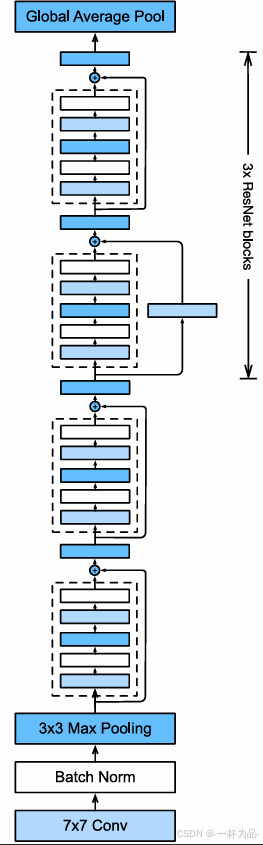
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) #殘差模塊
def resnet_block(input_channels, num_channels, num_residuals, firstblock=False): blk = [] for i in range(num_residuals): #除了第一個模塊,每個模塊的第一個塊做1×1卷積if i == 0 and not firstblock: blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2)) else: blk.append(Residual(num_channels, num_channels)) return blk b2 = nn.Sequential(*resnet_block(64, 64, 2, firstblock=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2)) net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d(1), nn.Flatten(), nn.Linear(512, 10))
7.6.4 訓練模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
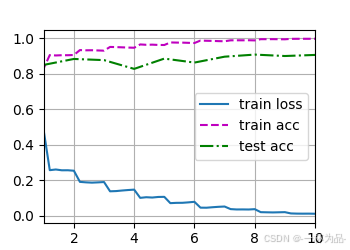
訓練結果:
loss 0.010, train acc 0.998, test acc 0.906
828.8 examples/sec on cuda:0
7.7 稠密連接網絡(DenseNet)
ResNet極大地改變了如何參數化深度網絡中函數的觀點,稠密連接網絡在某種程度上時ResNet的邏輯擴展。
7.7.1 從ResNet到DenseNet
泰勒展開將函數分解成越來越高階的項:
f ( x ) = f ( 0 ) + f ′ ( 0 ) x + f ′ ′ ( 0 ) 2 ! x 2 + f ′ ′ ′ 3 ! x 3 + ? f(x)=f(0)+f'(0)x+\displaystyle\frac{f^{''}(0)}{2!}x^2+\frac{f^{'''}}{3!}x^3+\cdots f(x)=f(0)+f′(0)x+2!f′′(0)?x2+3!f′′′?x3+?
而ResNet將函數展開為:
f ( x ) = x + g ( x ) f(\boldsymbol x)=\boldsymbol x+g(\boldsymbol x) f(x)=x+g(x)
ResNet將 f f f分解為一個簡單的線性項和一個復雜的非線性項,而DenseNet提出了一種將 f f f拓展成超過兩部分的方案。關鍵區別在于DenseNet輸出是連接(用 [ , ] [,] [,]表示)而不是ResNet的簡單相加:
x → [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) , f 3 ( [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) ] ) , ? ] \boldsymbol x\rightarrow[\boldsymbol x,f_1(\boldsymbol x),f_2([\boldsymbol x,f_1(\boldsymbol x)]),f_3([\boldsymbol x,f_1(\boldsymbol x),f_2([\boldsymbol x,f_1(\boldsymbol x)])]),\cdots] x→[x,f1?(x),f2?([x,f1?(x)]),f3?([x,f1?(x),f2?([x,f1?(x)])]),?]
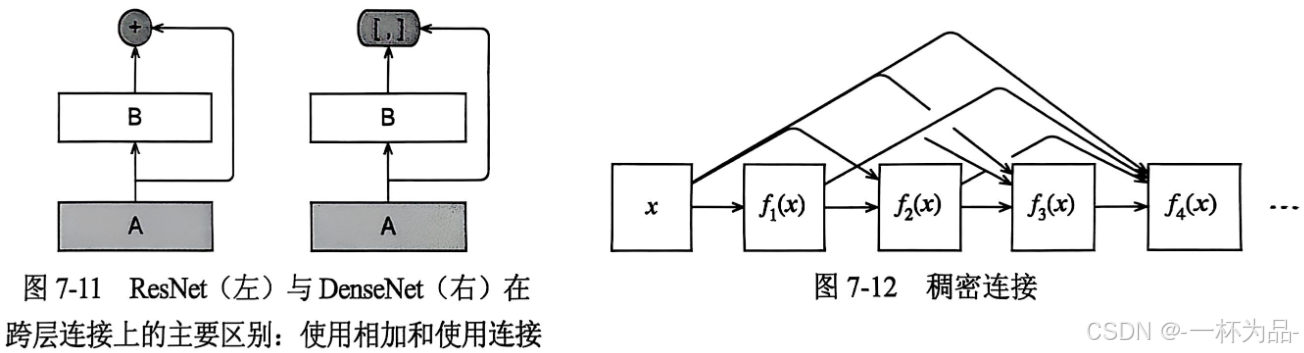
稠密網絡由稠密塊和過渡層組成,前者定義如何連接輸入和輸出,后者控制通道數使其不會太復雜。
7.7.2 稠密塊體
DenseNet使用了ResNet改良版的“批量規范化層+激活層+卷積層”架構,一個稠密塊由多個這樣的卷積塊組成,每個卷積塊使用相同數量的輸出通道,但最終每個卷積塊的輸入和輸出會在通道維度上連接,即每次都會使輸出通道數增加一個卷積塊的通道數。卷積塊的通道數控制了輸出通道數相對于輸入通道數的增長率。
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt #卷積塊
def conv_block(input_channels, num_channels): return nn.Sequential( nn.BatchNorm2d(input_channels), nn.ReLU(), nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1)) #稠密塊
class DenseBlock(nn.Module): def __init__(self, num_convs, input_channels, num_channels): super().__init__() layer = [] for i in range(num_convs): layer.append(conv_block(num_channels * i + input_channels, num_channels)) self.net = nn.Sequential(*layer) def forward(self, X): for blk in self.net: Y = blk(X) X = torch.cat((X, Y), 1) return X
7.7.3 過渡層
為了應對卷積塊帶來的通道增長,過渡層通過 1 × 1 1\times1 1×1卷積層減小通道數,并使用平均匯聚層減半高度和寬度,從而降低模型復雜度。
def transition_block(input_channels, num_channels): return nn.Sequential( nn.BatchNorm2d(input_channels), nn.ReLU(), nn.Conv2d(input_channels, num_channels, kernel_size=1), nn.AvgPool2d(kernel_size=2, stride=2))
7.7.4 DenseNet模型
b1 = nn.Sequential( nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) #當前輸出通道數和增長率(卷積塊通道數)
num_channels, growth_rate = 64, 32
#每個稠密塊的卷積塊個數
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks): blks.append(DenseBlock(num_convs, num_channels, growth_rate)) #更新輸出通道數num_channels += num_convs * growth_rate if i != len(num_convs_in_dense_blocks) - 1: #過渡層將輸出通道數減半blks.append(transition_block(num_channels, num_channels // 2)) num_channels //= 2 net = nn.Sequential( b1, *blks, nn.BatchNorm2d(num_channels), nn.ReLU(), nn.AdaptiveAvgPool2d(1), nn.Flatten(), nn.Linear(num_channels, 10))
7.7.5 訓練模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
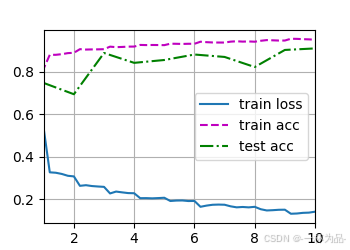
訓練結果:
loss 0.140, train acc 0.950, test acc 0.909
820.2 examples/sec on cuda:0
)
)







![[物聯網iot]對比WIFI、MQTT、TCP、UDP通信協議](http://pic.xiahunao.cn/[物聯網iot]對比WIFI、MQTT、TCP、UDP通信協議)

)



)



