簡介:預測酶動力學參數是酶發現和酶工程中的一項重要任務。在此,研究人員基于蛋白質語言模型、小分子語言模型和分子指紋,提出了一種名為 CataPro 的新酶動力學參數預測算法。該研究從 BRENDA 和 SABIO-RK 數據庫中收集了最新的轉化率(kcat)、邁克爾常數(Km)和催化效率(kcat/Km)數據。根據 0.4 的蛋白質序列相似性對這些數據進行聚類,我們得到了相應的 10 倍交叉驗證數據集。CataPro 在這些無偏 10 倍交叉驗證數據集上進行了訓練,在預測 kcat、Km 和 kcat/Km 方面的性能優于之前的預測器。
安裝教程:
1、創建并激活虛擬環境
conda create -n catapro python=3.10
conda activate catapro?2、按照環境的需求安裝以下必要的軟件包
? ? pytorch >= 1.13.0
? ? transformers
? ? numpy
? ? pandas
? ? RDKit
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=11.8 -c pytorch -c nvidia # 安裝GPU版本的torchconda install -c conda-forge rdkit -y # 安裝化學信息處理的開源工具包rdkitpip install transformers pandaspip install "numpy<2" # 因為PyTorch 版本的兼容問題,所以要安裝numpy<2pip install sentencepiece # 加載 ProtT5_model 和 MolT5_model 時需要用到 HuggingFace 的 T5Tokenizer,而 T5Tokenizer 依賴于 SentencePiece 庫3、安裝并初始化 Git LFS
conda install -c conda-forge git-lfs -y # HuggingFace 模型倉庫使用了 Git LFS (Large File Storage),專門用來處理大型文件的版本控制(比如模型權重)
git lfs install # 初始化 Git LFS
4、下載所需的預訓練模型:?prot_t5_xl_uniref50?and?molt5-base-smiles2caption
# 步驟1:先只克隆元數據,不自動下載 LFS
# 這條命令告訴 git:只克隆倉庫結構,不要拉取 LFS 文件。執行后你可以 cd prot_t5_xl_uniref50 看一下文件結構,此時 .bin 文件的大小可能是幾十字節(是一個指針文件)。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Rostlab/prot_t5_xl_uniref50# 步驟2:手動拉取權重文件,這一步才會真正開始下載 .bin 文件(模型權重),你會看到下載進度條。
cd prot_t5_xl_uniref50
git lfs pull
# molt5-base-smiles2caption的安裝與上面相同
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/laituan245/molt5-base-smiles2captioncd molt5-base-smiles2caption
git lfs pull
# 安裝openpyxl,是pandas 用于寫入 Excel 文件的依賴
pip install openpyxl5、測試運行
# 使用以下命令運行CataPro來推斷酶促反應的動力學參數python predict.py \-inp_fpath samples/sample_inp.csv \-model_dpath models \-batch_size 64 \-device cuda:0 \-out_fpath catapro_prediction.csv輸出結果如下:
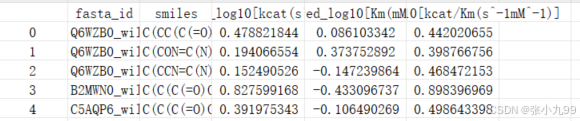
參考鏈接:zchwang/CataPro: A generalized enzyme kinetics parameter prediction model.
參考文獻:Robust enzyme discovery and engineering with deep learning using CataPro | Nature Communications






![[物聯網iot]對比WIFI、MQTT、TCP、UDP通信協議](http://pic.xiahunao.cn/[物聯網iot]對比WIFI、MQTT、TCP、UDP通信協議)

)



)






