背景
在學習緩存雪崩的時候,了解到有二級緩存和隨機TTL兩個解決方案,但是在學習之后,個人認為二級緩存本質上還是利用兩層緩存的過期時間不一致來實現緩存過期時間隨機化,這不就是和隨機TTL一樣嗎,故有了這篇思考,如有不對,歡迎指正
緩存雪崩是什么
緩存雪崩指的是大量的緩存同時失效(過期)導致大量的請求直接到了數據庫,數據庫瞬間受到了很大的壓力,可能導致系統崩潰
或者是緩存層直接不提供服務宕機導致大量請求直接打到數據庫上,使得數據庫承受很大壓力
其中緩存雪崩解決方案有多種,其中兩種為
- 二級緩存
- 設置隨機ttl(隨機過期時間)
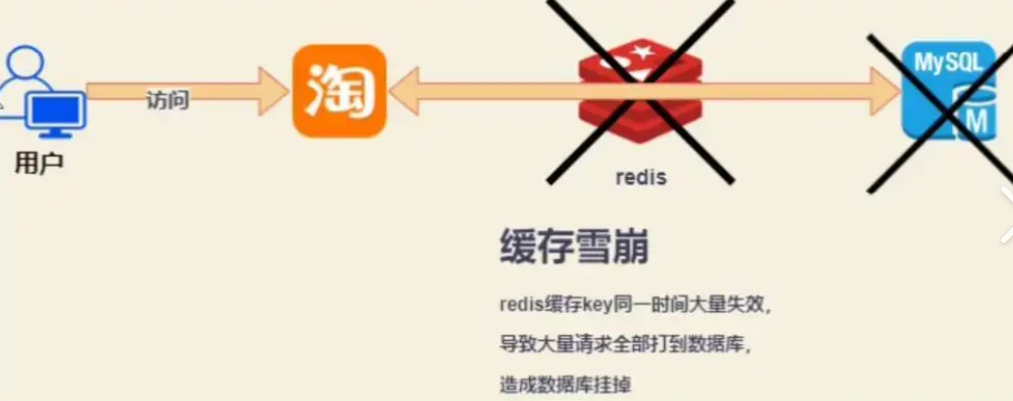
二級緩存是什么?
二級緩存指的是將兩個不同層次的緩存結合起來使用,是一種組合型分組的緩存結構,最常見的就是Redis+本地緩存(如Caffeine)。目的是通過分層設計,在內存與持久化緩存之間分擔壓力,提高系統的容錯能力與性能。(一般是采取熱點數據存儲到本地緩存,非熱點數據存儲到redis種)
常見的一個請求流程圖如下:
首先先查詢一級緩存,隨后如果讀取不到的話就讀取二級緩存,再沒有就去數據庫查詢并且將找到的數據寫入一二級緩存
代碼示例
// 根據店鋪 ID 查詢店鋪信息public String queryShopById(Long id) {String cacheKey = CACHE_SHOP_KEY + id;// 1. 首先查詢 Caffeine 本地緩存String shop = caffeineCache.getIfPresent(cacheKey);if (shop != null) {System.out.println("從Caffeine緩存中查詢到數據...");return shop;}// 2. 如果 Caffeine 本地緩存沒有,從 Redis 查詢shop = redisTemplate.opsForValue().get(cacheKey);if (shop != null) {System.out.println("從Redis緩存中查詢到數據...");// Redis 命中,放入 Caffeine 本地緩存caffeineCache.put(cacheKey, shop);return shop;}// 3. 如果 Redis 和 Caffeine 都沒有,從數據庫查詢shop = getShopFromDatabase(id);if (shop != null) {// 數據庫查詢成功,將數據放入 Redis 和 Caffeine 緩存redisTemplate.opsForValue().set(cacheKey, shop, 10, TimeUnit.MINUTES); // 設置 Redis 緩存有效期caffeineCache.put(cacheKey, shop); // 將數據放入 Caffeine 本地緩存return shop;}return "店鋪不存在";}二級緩存如何解決緩存雪崩的問題
(1) 緩存過期時間不一致,避免大規模并發請求(核心)
- 為了避免緩存雪崩問題,Redis 緩存和 Caffeine 緩存的過期時間可以設置不同,而且本地緩存 Caffeine 還支持自動清除過期的緩存。這種不同的過期策略可以避免大量緩存同時過期。
- 避免全量緩存同時失效:通過設計合理的過期時間,避免 Redis 和 Caffeine 緩存同時在同一時刻過期。比如,Redis 緩存設置為較長的過期時間(例如 10 分鐘),而 Caffeine 的過期時間較短(例如 1 分鐘)。這樣即使 Redis 緩存失效,本地緩存仍然能繼續工作,避免了緩存雪崩的發生。(caffeine可以通過設置expireAfter:基于個性化定制的邏輯來實現過期處理,靈活設置過期時間)
(2) Redis 緩存失效時,Caffeine 能接管
- Redis 緩存失效時,由于本地緩存(Caffeine)的存在,查詢操作首先會嘗試從 Caffeine 獲取數據,這樣能夠在 Redis 緩存失效期間保證一定的服務可用性,并避免所有請求都落到數據庫上。
(3) Caffeine 本地緩存減少對 Redis 的壓力
- Caffeine 作為本地緩存,存儲的是每個節點本地的數據,能夠極大地減少對 Redis 的訪問。
- 即使 Redis 緩存失效(比如 Redis 發生故障或緩存過期),本地緩存 Caffeine 仍然可以繼續提供服務,避免了緩存失效后直接查詢數據庫的壓力。
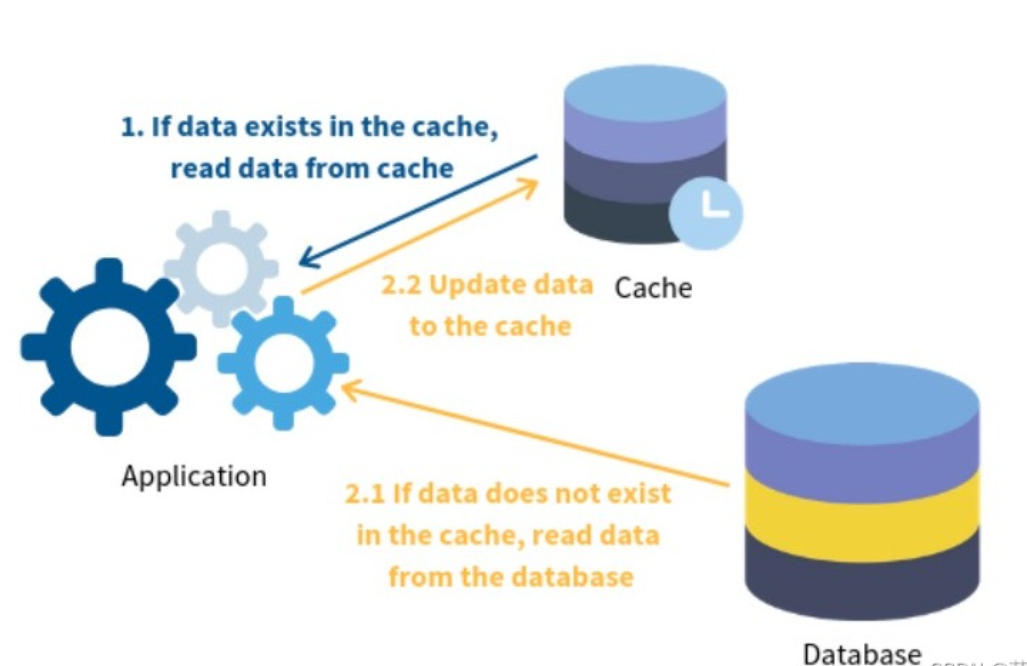
隨機ttl是什么?
隨機 TTL(Time to Live)是設置緩存過期時間的一種策略,它通過給每個緩存設置一個 隨機的過期時間,來避免緩存過期時間集中在同一時刻。從而避免了大量緩存同時過期,避免了大量請求同時擊中數據庫的緩存雪崩問題。
一種常用的方案就是在集體的過期時間上各個添加一個隨機的時長從而實現隨機ttl
隨機ttl如何解決的緩存雪崩?
即時多個原本的緩存項的原本的過期時間相同,經過隨機化后,它們的實際過期時間就不同了,減少了集中過期概率
當緩存項過期,新的請求觸發從數據庫加載數據并更新緩存,避免了大規模同時從數據庫加載數據
示例代碼
public class CacheExample {private static final String CACHE_KEY = "shop_info:";private static final int MIN_TTL = 5; // 最小 TTL 時間(秒)private static final int MAX_TTL = 20; // 最大 TTL 時間(秒)private static Jedis jedis = new Jedis("localhost", 6379); // Redis 連接// 模擬查詢數據庫獲取數據private static String queryDatabase(Long id) {return "Shop Info for ID: " + id;}// 獲取緩存數據public static String getShopInfo(Long id) {String cacheKey = CACHE_KEY + id;// 嘗試從 Redis 獲取緩存數據String cachedData = jedis.get(cacheKey);if (cachedData != null) {System.out.println("從緩存獲取數據: " + cachedData);return cachedData;}// 如果緩存不存在,查詢數據庫String data = queryDatabase(id);// 設置緩存時,使用隨機的 TTL(過期時間)int ttl = new Random().nextInt(MAX_TTL - MIN_TTL + 1) + MIN_TTL;jedis.setex(cacheKey, ttl, data);System.out.println("從數據庫獲取數據并緩存: " + data);return data;}// 模擬調用緩存查詢public static void main(String[] args) {// 查詢 shop 1System.out.println(getShopInfo(1L));// 查詢 shop 2System.out.println(getShopInfo(2L));}
}
但是,經過看過兩種實現,其實仔細一看好像似乎隨機TTL和二級緩存的本質都是避免緩存同時過期來解決緩存雪崩的問題,保證緩存不會大量同一時刻失效,從而減少數據庫的訪問壓力,但是二者并非一致?
隨機TTL VS 二級緩存
1. 隨機 TTL 優勢:
- 簡單實現:相比于二級緩存方案,隨機 TTL 不需要引入額外的緩存系統,只需調整緩存的過期策略即可,配置和實現較為簡單。
- 降低緩存過期集中性:通過隨機化每個緩存項的過期時間,解決了大量緩存同時過期的問題,減少了對數據庫的壓力。
2. 二級緩存優勢:
- 更高的可用性:二級緩存引入了本地緩存(如 Caffeine)和分布式緩存(如 Redis),即使 Redis 出現故障,本地緩存 Caffeine 仍然能繼續提供數據服務,確保系統高可用。
- 更高的性能:本地緩存 Caffeine 可以極大降低 Redis 的訪問壓力,提升系統響應速度。
- 數據一致性和實時更新:二級緩存可以通過合理的緩存更新機制和緩存失效策略,保持數據的一致性和及時更新,避免緩存和數據庫的不同步問題。
二者的核心區別:
緩存的可靠性和冗余
- 隨機ttl只是通過在緩存失效時間引入隨機性避免緩存雪崩問題,但是這種方法只依賴單一緩存層,如果緩存層出現問題,整個緩存機制失效,所有請求直接訪問數據庫
- 二級緩存而是通過兩層緩存系統提高緩存可靠性和容錯能力,即時一級緩存失效,應用依然能夠依賴另外一層緩存提供數據,避免了對數據庫的直接訪問,意味著即使分布式緩存(如 Redis)失效,應用也可以通過本地緩存繼續提供數據,保證系統的高可用性。
性能的優化:
本地緩存的延遲比redis更短,而且內存訪問速度極快,本地緩存是 非常有效的性能優化手段
總結
雖然 隨機 TTL 和 二級緩存 都是解決 緩存雪崩 的有效手段,但它們的設計目標和適用場景有所不同。隨機 TTL 簡單有效,適用于單一緩存層的情況,尤其是 Redis。二級緩存通過結合 Redis 和本地緩存來增強系統的 容錯性、高可用性、性能優化 ,適用于更復雜和高并發的場景。






三端)




——邊緣檢測)


:強化 AI 智能體的知識 “武裝”)



)
