第一課時
一、導入
前面的課程我們搭建了hadoop集群,并成功啟動了它,接下來我們看看如何去使用集群。
測試的內容包括:1.上傳文件,2.下載文件,3.運行程序
二、授新
(一)配置運行任務的歷史服務器
為了查看程序的歷史運行情況,需要配置一下歷史服務器。這個歷史服務器需要消耗的資源比較小,你可以選擇把它配置在集群中的任意一臺節點上。但是,請注意,在哪一臺上配置了,就應該在哪一臺上去啟動。
我們這把它配置在nn節點(hadoop100)上。具體配置步驟如下:
1.配置mapred-site.xml
在hadoop的安裝目錄下,打開mapred-site.xml,并在該文件里面增加如下兩條配置。
<!-- 歷史服務器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop100:10020</value>
</property><!-- 歷史服務器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop100:19888</value>
</property>2.分發配置
把這個配置同步到其他的節點中。這里直接使用我們之前封裝好的命令xsync來同步。具體如下:
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
3.啟動歷史服務器
請注意,你在配置的時候指定哪個節點是歷史服務器,就在哪里啟動,請不要搞錯了。
對應的命令是:?mapred --daemon start?historyserver
4.檢查歷史服務器是否啟動
通過jps命令來查看歷史服務器是否已經成功啟動了。
[root@hadoop100?hadoop]$ jps
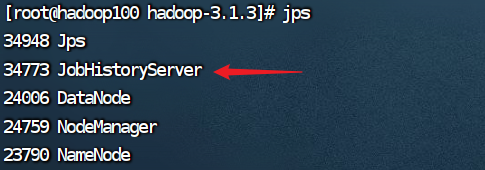
5.查看JobHistory
方式1:直接去看所有的歷史記錄 href="http://hadoop100:19888/jobhistory" http://hadoop100:19888/jobhistory
方式2:重新啟動yarn服務。再從具體的history鏈接進行跳轉。
(二)配置運行任務的日志
與歷史命令相配套的還有對應的執行的日志。

它的入口在上面的位置。點擊之后,我們去查看:

發現看不了。接下來我們就去配置一下,讓它能夠訪問。
這個操作叫日志聚集。由于任務是在具體的節點上運行的,所以運行日志也是產生在具體的節點上,但是我們希望應用完成以后,將程序運行日志信息上傳到HDFS系統上,這樣就可以方便的查看到程序運行詳情,方便開發調試。
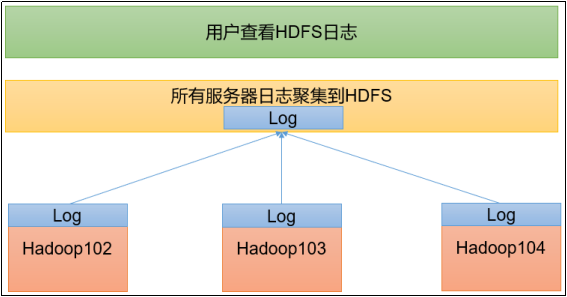
注意:開啟日志聚集功能,需要重新啟動NodeManager 、ResourceManager和HistoryServer。
開啟日志聚集功能具體步驟如下:
(1)配置yarn-site.xml
打開yarn-site.xml文件,我們添加如下的配置。在該文件里面增加如下配置。
<!-- 開啟日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 設置日志聚集服務器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 設置日志保留時間為7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>(2)分發配置
和之前的配置一樣,我們需要把這個更新之后的yarn-site.xml文件同步到其他的機器。這里還是使用腳本xsync。具體如下:
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
(3)重啟ResourceManager和HistoryServer
進入到我們安裝yarn的主機,通過命令來關閉掉yarn和historyServer,然后再重啟。
[root@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[root@hadoop103 hadoop-3.1.3]$?mapred --daemon?stop historyserver
啟動ResourceManage和HistoryServer
start-yarn.sh
mapred --daemon?start historyserver
(三)測試運行任務的日志
前面我們已經完成了任務日記的聚集,下面我們來看看是不是配置正確了。我們需要重新運行wordcount應用,然后再去看看是不是正確生成了日志。
- 重新執行WordCount程序
命令如下:
[root@hadoop100?hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
- 查看日志
如果一切正常,我們打開歷史服務器地址http://hadoop101:19888/jobhistory?可以看到歷史任務列表,如下:
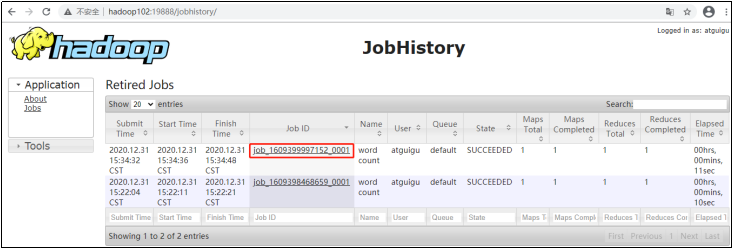
點擊對應的JobID,就可以進一步查看任務運行日志
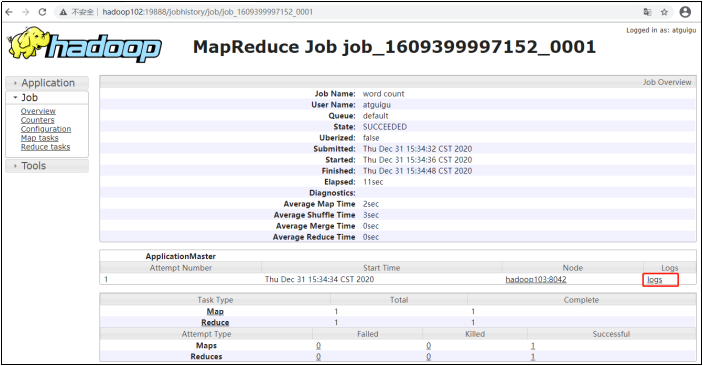
然后在點擊logs,就可以查看運行日志的詳情了。

第二課時
我們基本上完成了hadoop集群的所有配置了,涉及到的服務也非常多。下面我們看看在啟動和關閉集群和相關的服務的細節。
(四)集群啟動/停止方式命令小結
我們配置了多臺服務器,并且每臺服務器上運行的任務都不太相同,我們可以使用jps命令來查看每臺設備上的運行任務。

具體說明如下:
- DataNode,它是hdfs的模塊之一,每臺服務器都有。
- NameNode, hdfs的核心服務,只有一個。
- SecondaryNameNode,hdfs的核心服務,是NameNode的備份。
- RourceManager, Yarn的核心服務,只有一個。
- NodeManager,Yarn的核心模塊,每臺服務器都有。
我們可以通過這些關鍵進程的名稱來判斷當前集群是否正常運轉。
1.各個模塊分開啟動/停止
(1) 整體啟動/停止HDFS: start-dfs.sh/stop-dfs.sh
(2) 整體啟動/停止YARN: start-yarn.sh/stop-yarn.sh
2.各個服務組件逐一啟動/停止
(1)分別啟動/停止HDFS組件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)啟動/停止YARN組件
yarn --daemon start/stop ?resourcemanager/nodemanager/historyserver
(五)編寫Hadoop集群啟停腳本
啟動的命令(HDFS,Yarn,Historyserver)比較多,在啟動的時候,還要分別進入不同的服務器寫不同的命令,比較麻煩。我們可以準備一個自定義的shell腳本,更加方便地完成整體啟動和停止。
具體操作有四步:
- 建立新文件,編寫腳本程序
- 分配執行權限
- 分發腳本
- 測試執行
下面分別介紹。
1.我們在hadoop100中操作,在/root/bin下新建文件:myhadoop,輸入如下內容:
#!/bin/bash
if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
fi
case $1 in
"start")echo " =================== 啟動 hadoop集群 ==================="echo " --------------- 啟動 hdfs ---------------"ssh hadoop100 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 啟動 yarn ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 啟動 historyserver ---------------"ssh hadoop100 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 關閉 hadoop集群 ==================="echo " --------------- 關閉 historyserver ---------------"ssh hadoop100 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 關閉 yarn ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 關閉 hdfs ---------------"ssh hadoop100 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac2.保存后退出,然后賦予腳本執行權限
chmod +x myhadoop
3.分發/home/root/bin目錄,保證自定義腳本在三臺機器上都可以使用。使用的命令如下
[root@hadoop100?~]$ cd
4.測試執行
我們在hadoop100中,運行 myhadoop start 啟動集群
在hadoop102中,運行myhadoop stop 停止集群
(六)查看三臺服務器Java進程腳本:jpsall
同理,我們去/root/bin下創建一個新的腳本文件:jpsall,輸入如下內容
#!/bin/bash
for host in hadoop100 hadoop101 hadoop102
doecho =============== $host ===============ssh $host jps
done保存后退出,然后賦予腳本執行權限
[root@hadoop100?bin]$ chmod +x jpsall
3)分發/home/root/bin目錄,保證自定義腳本在三臺機器上都可以使用
[root@hadoop100?~]$ xsync /home/root/bin/
(七)常用端口號說明
最后,補充總結一點關于我們用到的端口號的內容:
- 8020/9000/9820: NameNode內部通信端口
- 9870:NameNode HTTP UI
- 8088: MapReduce查看執行任務端口
- 19888:歷史服務器通信端口
三、課堂小結
通過本堂課的學習,我們學習了配置歷史任務的功能和查看運行日志的功能,并且編寫了一個用來啟動和停止集群的腳本。至此,所有的配置相關的內容全部結束。


)


![[學術][人工智能] 001_什么是神經網絡?](http://pic.xiahunao.cn/[學術][人工智能] 001_什么是神經網絡?)


)
)
)



失敗 錯誤代碼:0×80240438)


之中醫知識問答數據存儲、功能結構、用戶界面初步設計)

