在網絡上找了很多關于深度學習的資料,也總結了一點小心得,于是就有了下面這篇文章。這里內容較為簡單,適合初學者查看,所以大佬看到這里就可以走了。
話不多說,上圖
從上圖可以看出,傳統神經網絡算是另外兩個神經網絡的母體,所以這三者之間真要比較也一般都是拿CNN與RNN進行比較,很少看到拿三者一起比較的,很多初學者在這里就有所誤解,以為三個神經網絡是同時期的不同網絡架構。
為了讓大家更容易理解,這里整理了一組思維導圖,解析三者神經網絡的區別:
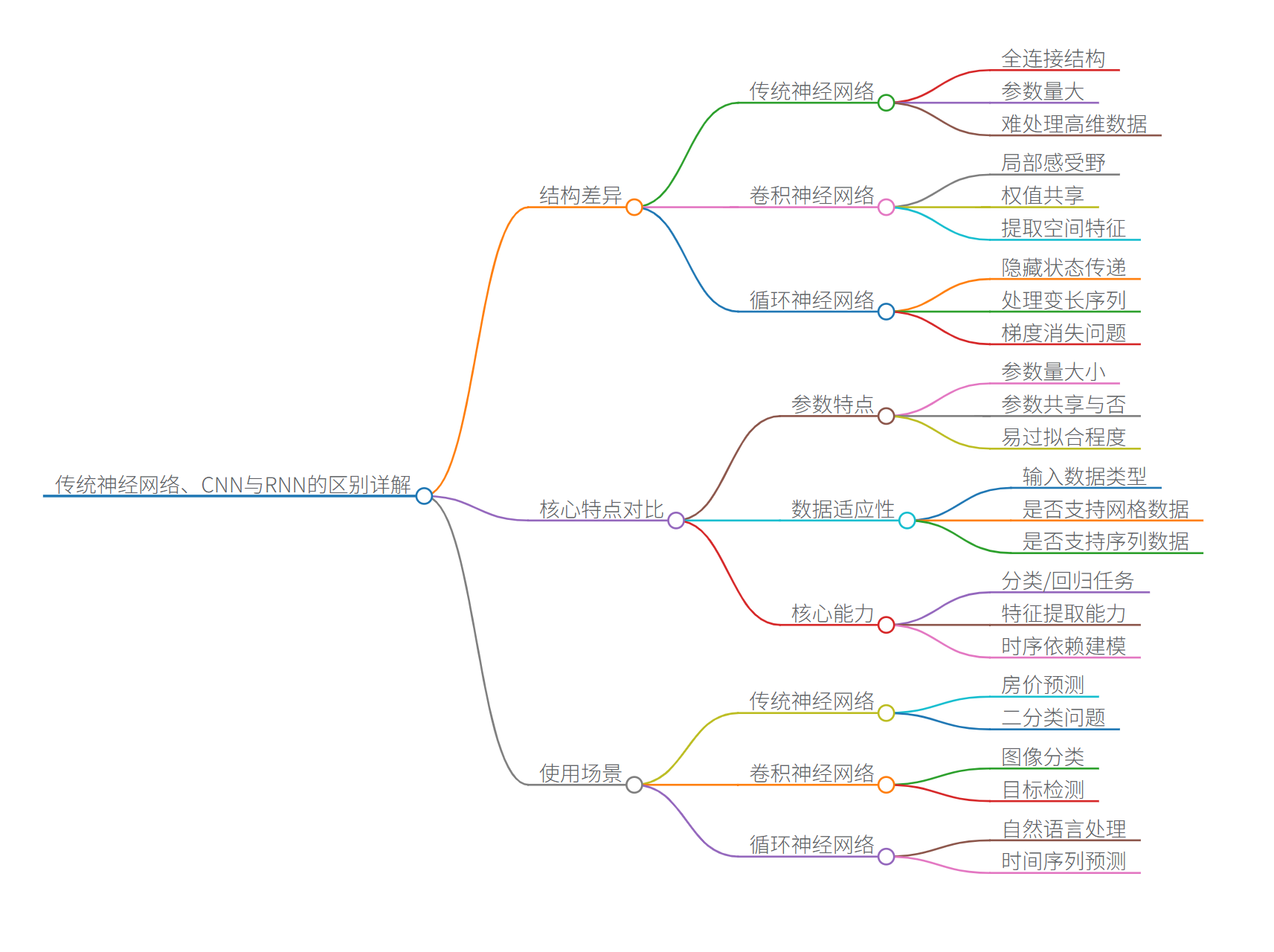
一、傳統神經網絡
傳統神經網絡(Traditional Neural Network)是指沒有采用現代深度學習技術(如殘差連接、批歸一化、注意力機制等)的早期人工神經網絡。它們通常由簡單的全連接層或卷積層堆疊而成,其結構和訓練方法相對基礎。以下是傳統神經網絡的詳細解釋:
傳統神經網絡是一種基于生物學神經元模型的計算模型,通過多層非線性變換處理輸入數據。其核心思想是通過“逐層傳遞”的方式將輸入數據映射到輸出結果,每一層的神經元通過權重和激活函數進行計算。
1.1 典型結構
傳統神經網絡的結構通常包括以下部分:
(1) 輸入層
- 功能:接收原始數據(如像素值、文本特征)。
- 示例:MNIST 手寫數字識別的輸入層是 784 維向量(28×28 像素)。
(2) 隱藏層
- 全連接層(Dense Layer):
- 每個神經元與前一層的所有神經元相連。
- 計算公式: z = W ? x + b , a = σ ( z ) z=W\cdot x+b, a=\sigma (z) z=W?x+b,a=σ(z),( σ \sigma σ為激活函數)。
- 激活函數:
- Sigmoid:將輸出壓縮到 [0,1],但存在梯度消失問題。
- Tanh:輸出范圍 [-1,1],緩解梯度消失但未徹底解決。
- ReLU:早期傳統網絡較少使用,因其可能導致神經元死亡。
(3) 輸出層
- 多分類任務:使用 Softmax 激活函數,輸出類別概率。
- 回歸任務:使用線性激活函數(無激活函數)。
1.2 典型網絡
傳統神經網絡算是人工智能領域的奠基性模型,典型結構包含輸入層、隱藏層和輸出層,通過非線性激活函數和權重連接實現特征映射。根據連接方式,可分為三大類:
-
前饋神經網絡
- 結構:單向傳遞信息,無反饋連接(如感知機、BP神經網絡)。
- 應用:簡單分類、回歸問題(如手寫數字識別)。
- 局限性:無法捕捉數據中的時序依賴或空間相關性。
-
反饋神經網絡
- 結構:包含循環連接(如Hopfield網絡、Elman網絡)。
- 應用:聯想記憶、動態系統建模。
- 局限性:梯度消失/爆炸問題顯著,難以處理長序列。
-
自組織神經網絡
- 結構:無監督學習,自動聚類輸入數據(如Kohonen網絡)。
- 應用:數據降維、模式發現。
代碼示例:
from keras.models import Sequential
from keras.layers import Dense# MNIST手寫數字識別示例
dnn_model = Sequential([Dense(512, activation='relu', input_shape=(784,)),Dense(256, activation='relu'),Dense(10, activation='softmax')
])
dnn_model.compile(optimizer='adam', loss='categorical_crossentropy')
1.3 訓練問題
傳統神經網絡在訓練中面臨以下挑戰:
(1) 梯度消失/爆炸
- 原因:鏈式求導導致梯度在反向傳播中指數級衰減(消失)或增長(爆炸)。
- 影響:深層網絡無法有效更新權重,訓練停滯。
(2) 過擬合
- 原因:網絡容量過大,記憶噪聲數據。
- 解決方案:
- 正則化(如 L2 正則化)。
- Dropout(早期傳統網絡較少使用)。
(3) 優化困難
- 問題:梯度方向不準確,陷入局部最優。
- 改進:使用更優的優化器(如 Adam),但傳統網絡通常依賴 SGD。
1.4 局限性
雖然對當時的來說傳統神經網絡以及很優秀,但是我們現在來看,傳統神經網絡還是有很大的缺點,其中最為限制其性能的就是以下三點:
- 深度限制:難以訓練超過 20 層的網絡。
- 特征提取能力:依賴手工特征(如 SIFT、HOG),而非端到端學習。
- 計算效率:全連接層參數量巨大,如 1000 層的網絡可能包含數億參數。
1.5 典型應用
在了解了上面的這些之后我們再來了解一下它的發展歷史,傳統神經網絡的應用總共有以下在節點:
- 圖像識別:LeNet-5(1998 年,手寫數字識別)。
- 語音識別:深度信念網絡(DBNs)。
- 自然語言處理:循環神經網絡(RNNs)的早期應用。
1.6 與現代網絡的對比
將傳統神經網絡拿到現在來對比,可以看出傳統神經網絡架構還是較為單一:
| 特性 | 傳統神經網絡 | 現代神經網絡(如 ResNet) |
|---|---|---|
| 殘差連接 | 無 | 有(解決梯度消失) |
| 激活函數 | Sigmoid/Tanh 為主 | ReLU/Swish/GELU 為主 |
| 歸一化 | 無 | 批歸一化(BatchNorm) |
| 深度 | 淺(通常 <20 層) | 深(如 ResNet-152 有 152 層) |
| 特征學習 | 依賴手工特征 | 端到端學習 |
總結:從上述的介紹我們可以看出,傳統神經網絡是深度學習的基礎,但受限于梯度消失、過擬合和計算效率等問題,難以構建更深層、更復雜的模型。現代網絡(如 ResNet、Transformer)通過引入殘差連接、批歸一化、注意力機制等創新,突破了這些限制,推動了 AI 技術的革命性發展。
二、卷積神經網絡(CNN):空間特征的提取專家
卷積神經網絡(Convolutional Neural Network, CNN)是一種專門設計用于處理網格狀數據(如圖像、音頻、視頻)的深度學習模型。它通過卷積層、池化層和全連接層的組合,能夠自動提取數據的層次化特征,在計算機視覺領域取得了革命性突破。其核心優勢在于局部連接和權重共享,大幅減少參數數量并提升平移不變性。
2.1 CNN的核心思想
- 局部連接:每個神經元僅連接輸入的局部區域(如圖像的一個小窗口),而非全部像素。
- 參數共享:同一卷積核的參數在整個輸入中共享,大幅減少參數量。
- 層級特征提取:淺層學習邊緣、紋理等低級特征,深層學習形狀、物體部件等高級特征。
2.2 典型結構
CNN的結構通常包含以下模塊:
(1) 輸入層
- 圖像輸入:形狀為
(高度, 寬度, 通道數),如RGB圖像為(224, 224, 3)。 - 預處理:歸一化(如像素值縮放到 [0,1])和標準化(均值為0,方差為1)。
(2) 卷積層(Convolutional Layer)
- 功能:通過滑動窗口(卷積核)提取局部特征。
- 關鍵參數:
- 核大小:如
3x3、5x5,決定感受野大小。 - 步長(Stride):窗口滑動的步幅,步長為2時特征圖尺寸減半。
- 填充(Padding):在輸入邊緣填充0,保持特征圖尺寸。
- 核大小:如
- 輸出形狀:
輸出尺寸 = 輸入尺寸 ? 核大小 + 2 × 填充 步長 + 1 \text{輸出尺寸} = \frac{\text{輸入尺寸} - \text{核大小} + 2 \times \text{填充}}{\text{步長}} + 1 輸出尺寸=步長輸入尺寸?核大小+2×填充?+1
(3) 激活函數
- ReLU:最常用激活函數,公式為 ( f(x) = \max(0, x) ),解決梯度消失問題。
- Swish/GELU:更平滑的激活函數,提升深層網絡性能。
(4) 池化層(Pooling Layer)
- 功能:降低特征圖尺寸,減少計算量,增強平移不變性。
- 類型:
- 最大池化(Max Pooling):取窗口內最大值。
- 平均池化(Average Pooling):取窗口內平均值。
- 示例:
MaxPool2D(pool_size=(2,2))將特征圖尺寸減半。
(5) 全連接層(Fully Connected Layer)
- 功能:將提取的特征映射到最終分類結果。
- 結構:每個神經元與前一層所有神經元相連。
- 輸出層:
- 多分類任務:使用 Softmax 激活函數,輸出類別概率。
- 回歸任務:使用線性激活函數。
(6) 正則化技術
- 批量歸一化(BatchNorm):標準化特征分布,加速訓練。
- Dropout:隨機丟棄神經元,防止過擬合。
2.3 CNN的優勢
| 特性 | 傳統神經網絡 | CNN |
|---|---|---|
| 局部連接 | 全連接,參數量爆炸 | 局部連接,參數大幅減少 |
| 平移不變性 | 需手動設計特征 | 自動學習平移不變特征 |
| 層級特征 | 依賴手工特征 | 端到端學習層次化特征 |
| 計算效率 | 高(全連接層參數量大) | 低(卷積層參數共享) |
2.4 經典CNN模型
| 模型 | 特點 | 應用場景 |
|---|---|---|
| LeNet-5 | 首個成功的CNN(1998),用于手寫數字識別 | MNIST、OCR |
| AlexNet | 現代CNN的奠基模型(2012),引入ReLU和Dropout | ImageNet分類 |
| VGGNet | 加深網絡(16-19層),驗證深度重要性 | 圖像分類、特征提取 |
| ResNet | 引入殘差連接,解決梯度消失問題 | 圖像分類、目標檢測 |
| YOLO | 實時目標檢測模型,融合CNN與回歸 | 自動駕駛、安防監控 |
2.5 工作流程示例(MNIST識別)
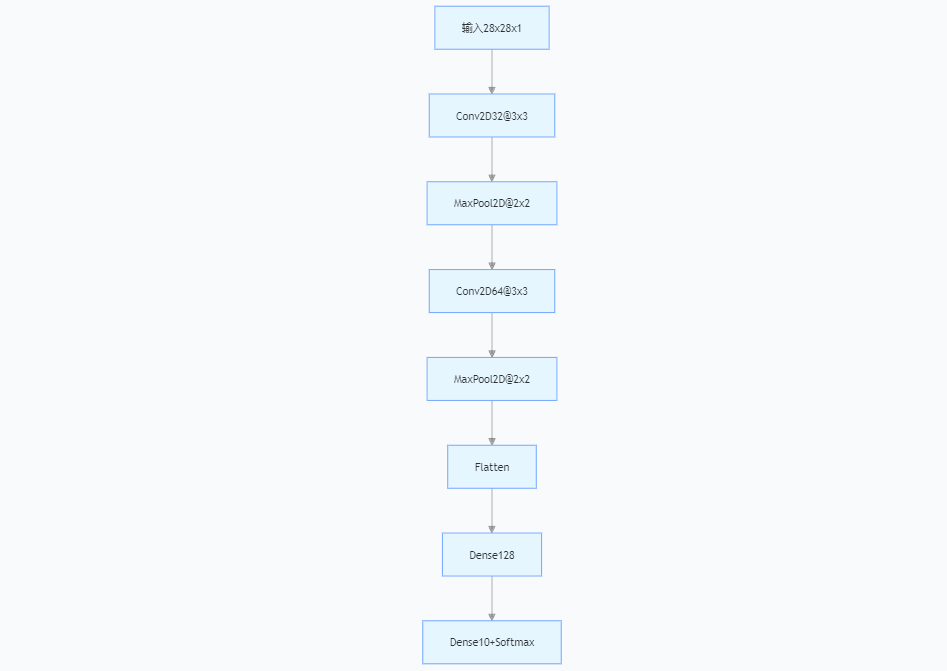
- 卷積層:提取邊緣、曲線等低級特征。
- 池化層:降低特征圖尺寸,保留關鍵信息。
- 全連接層:整合全局特征,輸出數字概率。
代碼示例:
from keras.layers import Conv2D, MaxPooling2D, Flatten# CIFAR-10圖像分類
cnn_model = Sequential([Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)),MaxPooling2D((2,2)),Conv2D(64, (3,3), activation='relu'),MaxPooling2D((2,2)),Flatten(),Dense(128, activation='relu'),Dense(10, activation='softmax')
])
6. 應用領域
- 圖像分類:識別物體類別(如ImageNet挑戰賽)。
- 目標檢測:定位并分類圖像中的多個物體(如COCO數據集)。
- 語義分割:像素級分類(如醫學影像分析)。
- 視頻分析:動作識別、異常檢測(如UCF101數據集)。
- 自然語言處理:文本分類、情感分析(如TextCNN)。
總結: CNN通過局部連接、參數共享和層級特征提取,成為處理圖像和視頻數據的首選模型。其成功推動了計算機視覺的革命,并為后續模型(如Transformer)奠定了基礎。理解CNN的結構和原理是深入學習深度學習的關鍵一步。
三、循環神經網絡(RNN)
RNN(循環神經網絡,Recurrent Neural Network)是一種專門處理序列數據(如文本、語音、時間序列等)的神經網絡架構。與傳統前饋神經網絡(如CNN)不同,RNN通過循環連接(Recurrent Connection)引入了時間維度上的記憶能力,允許信息在網絡中傳遞和保留。
其通過隱藏狀態傳遞機制捕捉長期依賴。經典公式如下:
h t = tanh ? ( W x h x t + W h h h t ? 1 + b h ) h_t = \tanh(W_{xh}x_t + W_{hh}h_{t-1} + b_h) ht?=tanh(Wxh?xt?+Whh?ht?1?+bh?)
y t = softmax ( W h y h t + b y ) y_t = \text{softmax}(W_{hy}h_t + b_y) yt?=softmax(Why?ht?+by?)
3.1 核心特點
-
循環結構
RNN的隱藏層不僅接收當前輸入,還接收上一時刻的隱藏狀態,形成“循環”信息流。公式表示為:
h t = σ ( W x h x t + W h h h t ? 1 + b h ) h_t = \sigma(W_{xh}x_t + W_{hh}h_{t-1} + b_h) ht?=σ(Wxh?xt?+Whh?ht?1?+bh?)
其中, h t h_t ht?是當前時刻的隱藏狀態, x t x_t xt?是輸入, σ \sigma σ是激活函數(如tanh)。 -
時間依賴性
能夠捕捉序列中的長期依賴關系(如句子中的上下文關聯),但傳統RNN存在梯度消失/爆炸問題,導致難以學習長期依賴。 -
變體改進
- LSTM(長短期記憶網絡):通過門控機制(輸入門、遺忘門、輸出門)解決長期依賴問題。
- GRU(門控循環單元):簡化版LSTM,參數更少,訓練效率更高。
核心挑戰:梯度消失/爆炸
- 解決方案:
- 使用ReLU激活函數
-引入門控機制(LSTM、GRU)
-梯度裁剪
- 使用ReLU激活函數
LSTM結構解析:
- 遺忘門:決定保留多少歷史信息
- 輸入門:控制新信息的流入
- 輸出門:調節隱藏狀態的輸出
3.2 與CNN的對比
| 特性 | CNN | RNN |
|---|---|---|
| 結構 | 前饋,空間局部連接 | 循環,時間序列連接 |
| 適用數據 | 圖像、網格數據 | 文本、語音、時間序列 |
| 記憶能力 | 無 | 有(短期依賴為主) |
| 典型應用 | 圖像分類、目標檢測 | 語言模型、語音識別 |
3.3 應用領域
- 自然語言處理(NLP)
- 語言模型(如GPT系列)
- 機器翻譯、情感分析、文本生成
- 時間序列預測
- 股票走勢預測、天氣預測
- 語音處理
- 語音識別、說話人識別
- 視頻分析
- 動作識別、視頻描述生成
優缺點
- 優點:
- 擅長處理序列數據中的時間依賴關系。
- 結構靈活,可根據任務調整層數和單元類型(LSTM/GRU)。
- 缺點:
- 傳統RNN存在梯度消失問題,難以捕捉長期依賴。
- 并行計算能力差,訓練速度較慢(LSTM/GRU有所改善)。
代碼示例(文本生成):
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Densemodel = Sequential([LSTM(128, input_shape=(seq_length, vocab_size)),Dense(vocab_size, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy')
總結:RNN是處理序列數據的核心模型,其循環結構賦予了對時間信息的建模能力。盡管存在一些局限性,但其變體(如LSTM、GRU)在實際任務中表現出色,是自然語言處理和時間序列分析的基石。
四、三者對比
4. 1 特征提取方式對比
# 可視化中間層輸出
from keras.models import Model# CNN特征可視化
conv_layer = Model(inputs=cnn_model.input, outputs=cnn_model.layers[2].output)
feature_maps = conv_layer.predict(img_array)# RNN隱藏狀態可視化
lstm_layer = Model(inputs=rnn_model.input,outputs=rnn_model.layers[2].output)
hidden_states = lstm_layer.predict(text_sequence)
4.2 各自特點對比
| 特征 | 傳統神經網絡(DNN) | 卷積神經網絡(CNN) | 循環神經網絡(RNN) |
|---|---|---|---|
| 連接方式 | 全連接 | 局部連接+參數共享 | 時序遞歸連接 |
| 核心優勢 | 簡單快速 | 空間特征提取 | 時序依賴捕捉 |
| 參數數量 | O(n2)級增長 | O(k2×c)級增長(k為卷積核尺寸) | O(n×h)級增長(h為隱藏單元) |
| 特征提取 | 全局特征 | 空間局部特征 | 時序特征 |
| 典型應用 | 簡單分類/回歸 | 圖像處理 | 自然語言處理 |
| 并行計算能力 | 高 | 極高 | 低 |
| 記憶能力 | 無 | 無 | 有時序記憶 |
| 處理序列能力 | 需展開為向量 | 需轉換為圖像格式 | 原生支持 |
| 訓練難度 | 容易過擬合 | 中等 | 梯度消失/爆炸問題嚴重 |
4.3 計算效率提升方案
| 網絡類型 | 優化策略 | 效果提升幅度 |
|---|---|---|
| DNN | 參數剪枝+量化 | 50-70% |
| CNN | 深度可分離卷積 | 3-5倍加速 |
| RNN | 使用GRU代替LSTM | 30%提速 |
| 混合架構 | 層間融合+知識蒸餾 | 2-3倍加速 |
4.4 內存優化代碼示例
# 混合精度訓練
from keras.mixed_precision import set_global_policy
set_global_policy('mixed_float16')# 梯度累積
optimizer = Adam(learning_rate=1e-4, gradient_accumulation_steps=4)# 內存映射數據集
dataset = tf.data.Dataset.from_generator(data_gen, output_types=(tf.float32, tf.int32))
4.5 參數共享機制對比
- DNN:無共享機制
- CNN:卷積核滑動共享
- RNN:時間步參數共享
# 參數數量計算示例
def print_params(model):trainable_params = np.sum([K.count_params(w) for w in model.trainable_weights])print(f"可訓練參數數量: {trainable_params:,}")print_params(dnn_model) # 約 669,706 參數
print_params(cnn_model) # 約 121,866 參數
print_params(rnn_model) # 約 1,313,793 參數
五、組合應用:CNN+RNN的協同效應
- 圖像描述生成
- CNN提取圖像特征 → RNN生成自然語言描述
- 視頻分類
- CNN處理空間信息 → RNN分析時間序列動態
- 對話系統
- CNN編碼視覺輸入 → RNN生成回復
示例架構:
# CNN特征提取
image_input = Input(shape=(224,224,3))
cnn_features = VGG16(weights='imagenet', include_top=False)(image_input)
cnn_features = GlobalAveragePooling2D()(cnn_features)# RNN文本生成
text_input = Input(shape=(max_length,))
embedding = Embedding(vocab_size, 128)(text_input)
lstm_output = LSTM(256)(embedding)# 合并輸出
concat = Concatenate()([cnn_features, lstm_output])
output = Dense(1000, activation='softmax')(concat)
model = Model(inputs=[image_input, text_input], outputs=output)
六、寫在最后(小結一下)
6.1 行業應用風向標
- 傳統DNN:適合小規模、結構化數據,已逐步被CNN/RNN替代
- CNN:計算機視覺領域的絕對主力,向輕量化(MobileNet)和3D擴展
- RNN:LSTM/GRU仍是序列建模的主流,但Transformer架構在長距離依賴上表現更優
6.2 行業應用風向標
相信讀完這篇文章,你對與三大網絡架構有了一個大體的了解,掌握三大神經網絡的本質差異,猶如獲得打開深度學習世界的三把鑰匙。無論是處理空間信息、時序序列還是簡單結構化數據,選擇合適的網絡架構往往能事半功倍。如果有任何問題歡迎留言,也期待各位的批評指正!



)
方面全新升級)
——Windows窗體應用概念)




![[從零開始學習JAVA ] 了解線程池](http://pic.xiahunao.cn/[從零開始學習JAVA ] 了解線程池)






)
)
