講師:鄧澎波
Spring面試專題
1.Spring應該很熟悉吧?來介紹下你的Spring的理解
1.1 Spring的發展歷程
先介紹Spring是怎么來的,發展中有哪些核心的節點,當前的最新版本是什么等

通過上圖可以比較清晰的看到Spring的各個時間版本對應的時間節點了。也就是Spring從之前單純的xml的配置方式,到現在的完全基于注解的編程方式發展。
1.2 Spring的組成
??Spring是一個輕量級的IoC和AOP容器框架。是為Java應用程序提供基礎性服務的一套框架,目的是用于簡化企業應用程序的開發,它使得開發者只需要關心業務需求。常見的配置方式有三種:基于XML的配置、基于注解的配置、基于Java的配置.
主要由以下幾個模塊組成:
- Spring Core:核心類庫,提供IOC服務;
- Spring Context:提供框架式的Bean訪問方式,以及企業級功能(JNDI、定時任務等);
- Spring AOP:AOP服務;
- Spring DAO:對JDBC的抽象,簡化了數據訪問異常的處理;
- Spring ORM:對現有的ORM框架的支持;
- Spring Web:提供了基本的面向Web的綜合特性,例如多方文件上傳;
- Spring MVC:提供面向Web應用的Model-View-Controller實現。
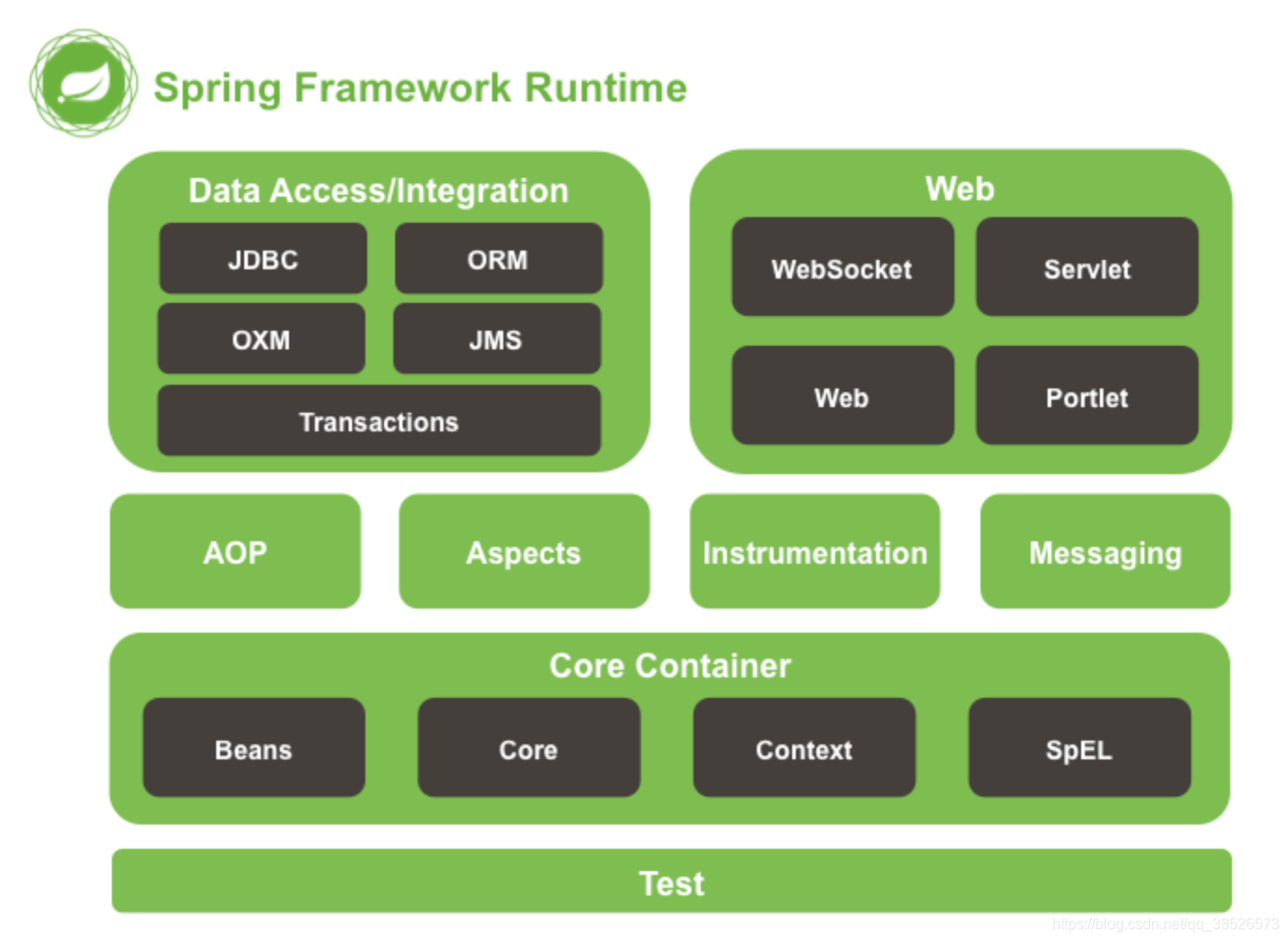
1.3 Spring的好處
| 序號 | 好處 | 說明 |
|---|---|---|
| 1 | 輕量 | Spring 是輕量的,基本的版本大約2MB。 |
| 2 | 控制反轉 | Spring通過控制反轉實現了松散耦合,對象們給出它們的依賴,<br>而不是創建或查找依賴的對象們。 |
| 3 | 面向切面編程(AOP) | Spring支持面向切面的編程,并且把應用業務邏輯和系統服務分開。 |
| 4 | 容器 | Spring 包含并管理應用中對象的生命周期和配置。 |
| 5 | MVC框架 | Spring的WEB框架是個精心設計的框架,是Web框架的一個很好的替代品。 |
| 6 | 事務管理 | Spring 提供一個持續的事務管理接口,<br>可以擴展到上至本地事務下至全局事務(JTA)。 |
| 7 | 異常處理 | Spring 提供方便的API把具體技術相關的異常 <br>(比如由JDBC,Hibernate or JDO拋出的)轉化為一致的unchecked 異常。 |
| 8 | 最重要的 | 用的人多!!! |
2.Spring框架中用到了哪些設計模式
2.1 單例模式
??單例模式應該是大家印象最深的一種設計模式了。在Spring中最明顯的使用場景是在配置文件中配置注冊bean對象的時候設置scope的值為singleton 。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><bean class="com.dpb.pojo.User" id="user" scope="singleton"><property name="name" value="波波烤鴨"></property></bean>
</beans>2.2 原型模式
??原型模式也叫克隆模式,Spring中該模式使用的很明顯,和單例一樣在bean標簽中設置scope的屬性prototype即表示該bean以克隆的方式生成
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><bean class="com.dpb.pojo.User" id="user" scope="prototype"><property name="name" value="波波烤鴨"></property></bean>
</beans>2.3 模板模式
??模板模式的核心是父類定義好流程,然后將流程中需要子類實現的方法就抽象話留給子類實現,Spring中的JdbcTemplate就是這樣的實現。我們知道jdbc的步驟是固定
- 加載驅動,
- 獲取連接通道,
- 構建sql語句.
- 執行sql語句,
- 關閉資源
在這些步驟中第3步和第四步是不確定的,所以就留給客戶實現,而我們實際使用JdbcTemplate的時候也確實是只需要構建SQL就可以了.這就是典型的模板模式。我們以query方法為例來看下JdbcTemplate中的代碼.

2.4 觀察者模式
??觀察者模式定義的是對象間的一種一對多的依賴關系,當一個對象的狀態發生改變時,所有依賴于它的對象都得到通知并被自動更新。使用比較場景是在監聽器中而spring中Observer模式常用的地方也是listener的實現。如ApplicationListener.

2.5 工廠模式
簡單工廠模式:
??簡單工廠模式就是通過工廠根據傳遞進來的參數決定產生哪個對象。Spring中我們通過getBean方法獲取對象的時候根據id或者name獲取就是簡單工廠模式了。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd"><context:annotation-config/><bean class="com.dpb.pojo.User" id="user" ><property name="name" value="波波烤鴨"></property></bean>
</beans>工廠方法模式:
??在Spring中我們一般是將Bean的實例化直接交給容器去管理的,實現了使用和創建的分離,這時容器直接管理對象,還有種情況是,bean的創建過程我們交給一個工廠去實現,而Spring容器管理這個工廠。這個就是我們講的工廠模式,在Spring中有兩種實現一種是靜態工廠方法模式,一種是動態工廠方法模式。以靜態工廠來演示
/*** User 工廠類* @author dpb[波波烤鴨]**/
public class UserFactory {/*** 必須是static方法* @return*/public static UserBean getInstance(){return new UserBean();}
}application.xml文件中注冊
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><!-- 靜態工廠方式配置 配置靜態工廠及方法 --><bean class="com.dpb.factory.UserFactory" factory-method="getInstance" id="user2"/>
</beans>2.6 適配器模式
??將一個類的接口轉換成客戶希望的另外一個接口。使得原本由于接口不兼容而不能一起工作的那些類可以在一起工作。這就是適配器模式。在Spring中在AOP實現中的Advice和interceptor之間的轉換就是通過適配器模式實現的。
class MethodBeforeAdviceAdapter implements AdvisorAdapter, Serializable {@Overridepublic boolean supportsAdvice(Advice advice) {return (advice instanceof MethodBeforeAdvice);}@Overridepublic MethodInterceptor getInterceptor(Advisor advisor) {MethodBeforeAdvice advice = (MethodBeforeAdvice) advisor.getAdvice();// 通知類型匹配對應的攔截器return new MethodBeforeAdviceInterceptor(advice);}
}2.7 裝飾者模式
??裝飾者模式又稱為包裝模式(Wrapper),作用是用來動態的為一個對象增加新的功能。裝飾模式是一種用于代替繼承的技術,無須通過繼承增加子類就能擴展對象的新功能。使用對象的關聯關系代替繼承關系,更加靈活,同時避免類型體系的快速膨脹。
??spring中用到的包裝器模式在類名上有兩種表現:一種是類名中含有Wrapper,另一種是類名中含有Decorator。基本上都是動態地給一個對象添加一些額外的職責。
??具體的使用在Spring session框架中的SessionRepositoryRequestWrapper使用包裝模式對原生的request的功能進行增強,可以將session中的數據和分布式數據庫進行同步,這樣即使當前tomcat崩潰,session中的數據也不會丟失。
<dependency><groupId>org.springframework.session</groupId><artifactId>spring-session</artifactId><version>1.3.1.RELEASE</version>
</dependency>2.8 代理模式
??代理模式應該是大家非常熟悉的設計模式了,在Spring中AOP的實現中代理模式使用的很徹底.
2.9 策略模式
??策略模式對應于解決某一個問題的一個算法族,允許用戶從該算法族中任選一個算法解決某一問題,同時可以方便的更換算法或者增加新的算法。并且由客戶端決定調用哪個算法,spring中在實例化對象的時候用到Strategy模式。XmlBeanDefinitionReader,PropertiesBeanDefinitionReader
2.10 責任鏈默認
AOP中的攔截器鏈
2.11 委托者模式
DelegatingFilterProxy,整合Shiro,SpringSecurity的時候都有用到。
…
3.Autowired和Resource關鍵字的區別?
??這是一個相對比較簡單的問題,@Resource和@Autowired都是做bean的注入時使用,其實@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要導入,但是Spring支持該注解的注入。
3.1 共同點
??兩者都可以寫在字段和setter方法上。兩者如果都寫在字段上,那么就不需要再寫setter方法.
3.2 不同點
@Autowired
??@Autowired為Spring提供的注解,需要導入org.springframework.beans.factory.annotation.Autowired;只按照byType注入。
public class TestServiceImpl {// 下面兩種@Autowired只要使用一種即可@Autowiredprivate UserDao userDao; // 用于字段上@Autowiredpublic void setUserDao(UserDao userDao) { // 用于屬性的方法上this.userDao = userDao;}
}
@Autowired注解是按照類型(byType)裝配依賴對象,默認情況下它要求依賴對象必須存在,如果允許null值,可以設置它的required屬性為false。如果我們想使用按照名稱(byName)來裝配,可以結合@Qualififier注解一起使用。如下:
public class TestServiceImpl {@Autowired@Qualifier("userDao")private UserDao userDao; }
@Resource
??@Resource默認按照ByName自動注入,由J2EE提供,需要導入包javax.annotation.Resource。@Resource有兩個重要的屬性:name和type,而Spring將@Resource注解的name屬性解析為bean的名字,而type屬性則解析為bean的類型。所以,如果使用name屬性,則使用byName的自動注入策略,而使用type屬性時則使用byType自動注入策略。如果既不制定name也不制定type屬性,這時將通過反射機制使用byName自動注入策略.
public class TestServiceImpl {// 下面兩種@Resource只要使用一種即可@Resource(name="userDao")private UserDao userDao; // 用于字段上@Resource(name="userDao")public void setUserDao(UserDao userDao) { // 用于屬性的setter方法上this.userDao = userDao;}
}
@Resource裝配順序:
- 如果同時指定了name和type,則從Spring上下文中找到唯一匹配的bean進行裝配,找不到則拋出異常。
- 如果指定了name,則從上下文中查找名稱(id)匹配的bean進行裝配,找不到則拋出異常。
- 如果指定了type,則從上下文中找到類似匹配的唯一bean進行裝配,找不到或是找到多個,都會拋出異常。
- 如果既沒有指定name,又沒有指定type,則自動按照byName方式進行裝配;如果沒有匹配,則回退為一個原始類型進行匹配,如果匹配則自動裝配。
@Resource的作用相當于@Autowired,只不過@Autowired按照byType自動注入。
4.Spring中常用的注解有哪些,重點介紹幾個
@Controller @Service @RestController @RequestBody,@Indexd @Import等
@Indexd提升 @ComponentScan的效率
@Import注解是import標簽的替換,在SpringBoot的自動裝配中非常重要,也是EnableXXX的前置基礎。
5.循環依賴
面試的重點,大廠必問之一:
5.1 什么是循環依賴
看下圖

??上圖是循環依賴的三種情況,雖然方式有點不一樣,但是循環依賴的本質是一樣的,就你的完整創建要依賴與我,我的完整創建也依賴于你。相互依賴從而沒法完整創建造成失敗。
5.2 代碼演示
??我們再通過代碼的方式來演示下循環依賴的效果
public class CircularTest {public static void main(String[] args) {new CircularTest1();}
}
class CircularTest1{private CircularTest2 circularTest2 = new CircularTest2();
}class CircularTest2{private CircularTest1 circularTest1 = new CircularTest1();
}
執行后出現了 StackOverflowError 錯誤

??上面的就是最基本的循環依賴的場景,你需要我,我需要你,然后就報錯了。而且上面的這種設計情況我們是沒有辦法解決的。那么針對這種場景我們應該要怎么設計呢?這個是關鍵!
5.3 分析問題
??首先我們要明確一點就是如果這個對象A還沒創建成功,在創建的過程中要依賴另一個對象B,而另一個對象B也是在創建中要依賴對象A,這種肯定是無解的,這時我們就要轉換思路,我們先把A創建出來,但是還沒有完成初始化操作,也就是這是一個半成品的對象,然后在賦值的時候先把A暴露出來,然后創建B,讓B創建完成后找到暴露的A完成整體的實例化,這時再把B交給A完成A的后續操作,從而揭開了循環依賴的密碼。也就是如下圖:

5.4 自己解決
??明白了上面的本質后,我們可以自己來嘗試解決下:
先來把上面的案例改為set/get來依賴關聯
public class CircularTest {public static void main(String[] args) throws Exception{System.out.println(getBean(CircularTest1.class).getCircularTest2());System.out.println(getBean(CircularTest2.class).getCircularTest1());}private static <T> T getBean(Class<T> beanClass) throws Exception{// 1.獲取 實例對象Object obj = beanClass.newInstance();// 2.完成屬性填充Field[] declaredFields = obj.getClass().getDeclaredFields();// 遍歷處理for (Field field : declaredFields) {field.setAccessible(true); // 針對private修飾// 獲取成員變量 對應的類對象Class<?> fieldClass = field.getType();// 獲取對應的 beanNameString fieldBeanName = fieldClass.getSimpleName().toLowerCase();// 給成員變量賦值 如果 singletonObjects 中有半成品就獲取,否則創建對象field.set(obj,getBean(fieldClass));}return (T) obj;}
}class CircularTest1{private CircularTest2 circularTest2;public CircularTest2 getCircularTest2() {return circularTest2;}public void setCircularTest2(CircularTest2 circularTest2) {this.circularTest2 = circularTest2;}
}class CircularTest2{private CircularTest1 circularTest1;public CircularTest1 getCircularTest1() {return circularTest1;}public void setCircularTest1(CircularTest1 circularTest1) {this.circularTest1 = circularTest1;}
}
然后我們再通過把對象實例化和成員變量賦值拆解開來處理。從而解決循環依賴的問題
public class CircularTest {// 保存提前暴露的對象,也就是半成品的對象private final static Map<String,Object> singletonObjects = new ConcurrentHashMap<>();public static void main(String[] args) throws Exception{System.out.println(getBean(CircularTest1.class).getCircularTest2());System.out.println(getBean(CircularTest2.class).getCircularTest1());}private static <T> T getBean(Class<T> beanClass) throws Exception{//1.獲取類對象對應的名稱String beanName = beanClass.getSimpleName().toLowerCase();// 2.根據名稱去 singletonObjects 中查看是否有半成品的對象if(singletonObjects.containsKey(beanName)){return (T) singletonObjects.get(beanName);}// 3. singletonObjects 沒有半成品的對象,那么就反射實例化對象Object obj = beanClass.newInstance();// 還沒有完整的創建完這個對象就把這個對象存儲在了 singletonObjects中singletonObjects.put(beanName,obj);// 屬性填充來補全對象Field[] declaredFields = obj.getClass().getDeclaredFields();// 遍歷處理for (Field field : declaredFields) {field.setAccessible(true); // 針對private修飾// 獲取成員變量 對應的類對象Class<?> fieldClass = field.getType();// 獲取對應的 beanNameString fieldBeanName = fieldClass.getSimpleName().toLowerCase();// 給成員變量賦值 如果 singletonObjects 中有半成品就獲取,否則創建對象field.set(obj,singletonObjects.containsKey(fieldBeanName)?singletonObjects.get(fieldBeanName):getBean(fieldClass));}return (T) obj;}
}class CircularTest1{private CircularTest2 circularTest2;public CircularTest2 getCircularTest2() {return circularTest2;}public void setCircularTest2(CircularTest2 circularTest2) {this.circularTest2 = circularTest2;}
}class CircularTest2{private CircularTest1 circularTest1;public CircularTest1 getCircularTest1() {return circularTest1;}public void setCircularTest1(CircularTest1 circularTest1) {this.circularTest1 = circularTest1;}
}
運行程序你會發現問題完美的解決了

??在上面的方法中的核心是getBean方法,Test1 創建后填充屬性時依賴Test2,那么就去創建 Test2,在創建 Test2 開始填充時發現依賴于 Test1,但此時 Test1 這個半成品對象已經存放在緩存到 singletonObjects 中了,所以Test2可以正常創建,在通過遞歸把 Test1 也創建完整了。

最后總結下該案例解決的本質:

5.5 Spring循環依賴
針對Spring中Bean對象的各種場景。支持的方案不一樣:

??然后我們再來看看Spring中是如何解決循環依賴問題的呢?剛剛上面的案例中的對象的生命周期的核心就兩個

??而Spring創建Bean的生命周期中涉及到的方法就很多了。下面是簡單列舉了對應的方法

??基于前面案例的了解,我們知道肯定需要在調用構造方法方法創建完成后再暴露對象,在Spring中提供了三級緩存來處理這個事情,對應的處理節點如下圖:

對應到源碼中具體處理循環依賴的流程如下:

??上面就是在Spring的生命周期方法中和循環依賴出現相關的流程了。那么源碼中的具體處理是怎么樣的呢?我們繼續往下面看。
首先在調用構造方法的后會放入到三級緩存中

下面就是放入三級緩存的邏輯
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");// 使用singletonObjects進行加鎖,保證線程安全synchronized (this.singletonObjects) {// 如果單例對象的高速緩存【beam名稱-bean實例】沒有beanName的對象if (!this.singletonObjects.containsKey(beanName)) {// 將beanName,singletonFactory放到單例工廠的緩存【bean名稱 - ObjectFactory】this.singletonFactories.put(beanName, singletonFactory);// 從早期單例對象的高速緩存【bean名稱-bean實例】 移除beanName的相關緩存對象this.earlySingletonObjects.remove(beanName);// 將beanName添加已注冊的單例集中this.registeredSingletons.add(beanName);}}}
然后在填充屬性的時候會存入二級緩存中
earlySingletonObjects.put(beanName,bean);
registeredSingletons.add(beanName);
最后把創建的對象保存在了一級緩存中
protected void addSingleton(String beanName, Object singletonObject) {synchronized (this.singletonObjects) {// 將映射關系添加到單例對象的高速緩存中this.singletonObjects.put(beanName, singletonObject);// 移除beanName在單例工廠緩存中的數據this.singletonFactories.remove(beanName);// 移除beanName在早期單例對象的高速緩存的數據this.earlySingletonObjects.remove(beanName);// 將beanName添加到已注冊的單例集中this.registeredSingletons.add(beanName);}}
5.6 疑問點
這些疑問點也是面試官喜歡問的問題點
為什么需要三級緩存
三級緩存主要處理的是AOP的代理對象,存儲的是一個ObjectFactory
三級緩存考慮的是帶你對象,而二級緩存考慮的是性能-從三級緩存的工廠里創建出對象,再扔到二級緩存(這樣就不用每次都要從工廠里拿)
沒有三級環境能解決嗎?
沒有三級緩存是可以解決循環依賴問題的
三級緩存分別什么作用
一級緩存:正式對象
二級緩存:半成品對象
三級緩存:工廠

6.Spring的生命周期

結合圖,把Bean對象在Spring中的關鍵節點介紹一遍
7.Spring中支持幾種作用域
Spring容器中的bean可以分為5個范圍:
- prototype:為每一個bean請求提供一個實例。
- singleton:默認,每個容器中只有一個bean的實例,單例的模式由BeanFactory自身來維護。
- request:為每一個網絡請求創建一個實例,在請求完成以后,bean會失效并被垃圾回收器回收。
- session:與request范圍類似,確保每個session中有一個bean的實例,在session過期后,bean會隨之失效。
- global-session:全局作用域,global-session和Portlet應用相關。當你的應用部署在Portlet容器中工作時,它包含很多portlet。如果你想要聲明讓所有的portlet共用全局的存儲變量的話,那么這全局變量需要存儲在global-session中。全局作用域與Servlet中的session作用域效果相同。
8.說說事務的隔離級別
??事務隔離級別指的是一個事務對數據的修改與另一個并行的事務的隔離程度,當多個事務同時訪問相同數據時,如果沒有采取必要的隔離機制,就可能發生以下問題:
| 問題 | 描述 |
|---|---|
| 臟讀 | 一個事務讀到另一個事務未提交的更新數據,所謂臟讀,就是指事務A讀到了事務B還沒有提交的數據,比如銀行取錢,事務A開啟事務,此時切換到事務B,事務B開啟事務–>取走100元,此時切換回事務A,事務A讀取的肯定是數據庫里面的原始數據,因為事務B取走了100塊錢,并沒有提交,數據庫里面的賬務余額肯定還是原始余額,這就是臟讀 |
| 幻讀 | 是指當事務不是獨立執行時發生的一種現象,例如第一個事務對一個表中的數據進行了修改,這種修改涉及到表中的全部數據行。 同時,第二個事務也修改這個表中的數據,這種修改是向表中插入一行新數據。那么,以后就會發生操作第一個事務的用戶發現表中還有沒有修改的數據行,就好象 發生了幻覺一樣。 |
| 不可重復讀 | 在一個事務里面的操作中發現了未被操作的數據 比方說在同一個事務中先后執行兩條一模一樣的select語句,期間在此次事務中沒有執行過任何DDL語句,但先后得到的結果不一致,這就是不可重復讀 |
Spring支持的隔離級別
| 隔離級別 | 描述 |
|---|---|
| DEFAULT | 使用數據庫本身使用的隔離級別 <br> ORACLE(讀已提交) MySQL(可重復讀) |
| READ_UNCOMITTED | 讀未提交(臟讀)最低的隔離級別,一切皆有可能。 |
| READ_COMMITED | 讀已提交,ORACLE默認隔離級別,有幻讀以及不可重復讀風險。 |
| REPEATABLE_READ | 可重復讀,解決不可重復讀的隔離級別,但還是有幻讀風險。 |
| SERLALIZABLE | 串行化,最高的事務隔離級別,不管多少事務,挨個運行完一個事務的所有子事務之后才可以執行另外一個事務里面的所有子事務,這樣就解決了臟讀、不可重復讀和幻讀的問題了 |
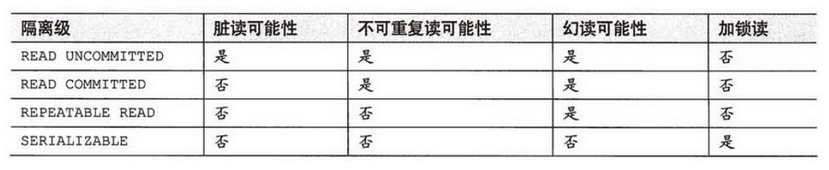
??再必須強調一遍,不是事務隔離級別設置得越高越好,事務隔離級別設置得越高,意味著勢必要花手段去加鎖用以保證事務的正確性,那么效率就要降低,因此實際開發中往往要在效率和并發正確性之間做一個取舍,一般情況下會設置為READ_COMMITED,此時避免了臟讀,并發性也還不錯,之后再通過一些別的手段去解決不可重復讀和幻讀的問題就好了。
9.事務的傳播行為
保證事務:ACID
事務的傳播行為針對的是嵌套的關系
Spring中的7個事務傳播行為:
| 事務行為 | 說明 |
|---|---|
| PROPAGATION_REQUIRED | 支持當前事務,假設當前沒有事務。就新建一個事務 |
| PROPAGATION_SUPPORTS | 支持當前事務,假設當前沒有事務,就以非事務方式運行 |
| PROPAGATION_MANDATORY | 支持當前事務,假設當前沒有事務,就拋出異常 |
| PROPAGATION_REQUIRES_NEW | 新建事務,假設當前存在事務。把當前事務掛起 |
| PROPAGATION_NOT_SUPPORTED | 以非事務方式運行操作。假設當前存在事務,就把當前事務掛起 |
| PROPAGATION_NEVER | 以非事務方式運行,假設當前存在事務,則拋出異常 |
| PROPAGATION_NESTED | 如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則執行與PROPAGATION_REQUIRED類似的操作。 |
舉例說明
案例代碼
ServiceA
ServiceA { void methodA() {ServiceB.methodB();}
}
ServiceB
ServiceB { void methodB() {}
}
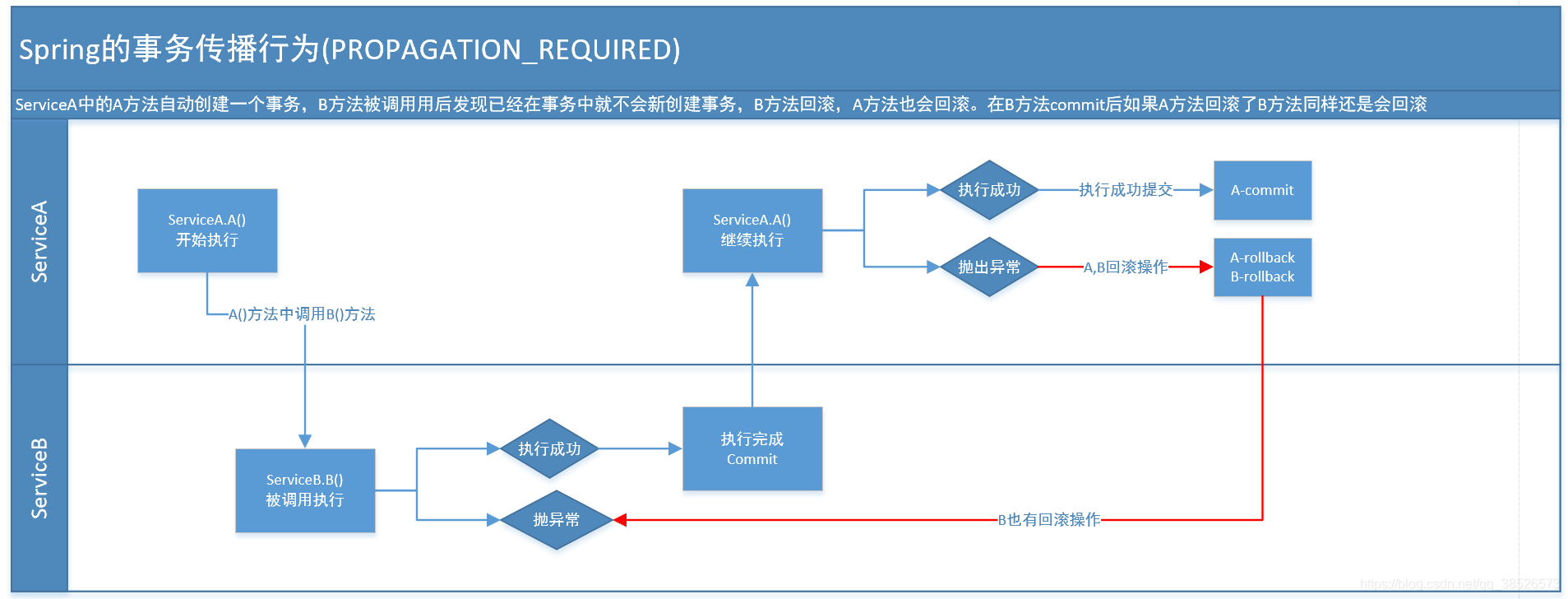
1.PROPAGATION_REQUIRED
??假如當前正要運行的事務不在另外一個事務里,那么就起一個新的事務 比方說,ServiceB.methodB的事務級別定義PROPAGATION_REQUIRED, 那么因為執行ServiceA.methodA的時候,ServiceA.methodA已經起了事務。這時調用ServiceB.methodB,ServiceB.methodB看到自己已經執行在ServiceA.methodA的事務內部。就不再起新的事務。而假如ServiceA.methodA執行的時候發現自己沒有在事務中,他就會為自己分配一個事務。這樣,在ServiceA.methodA或者在ServiceB.methodB內的不論什么地方出現異常。事務都會被回滾。即使ServiceB.methodB的事務已經被提交,可是ServiceA.methodA在接下來fail要回滾,ServiceB.methodB也要回滾
2.PROPAGATION_SUPPORTS
??假設當前在事務中。即以事務的形式執行。假設當前不在一個事務中,那么就以非事務的形式執行
3PROPAGATION_MANDATORY
??必須在一個事務中執行。也就是說,他僅僅能被一個父事務調用。否則,他就要拋出異常
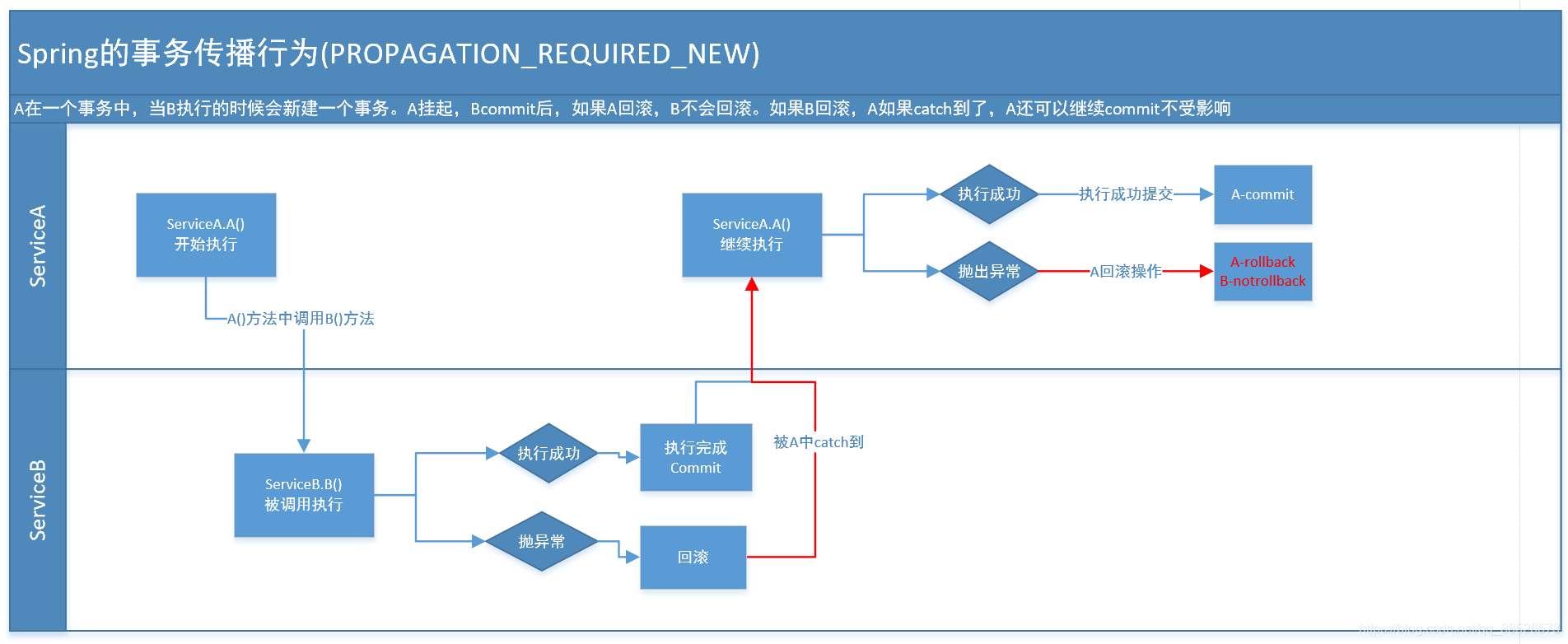
4.PROPAGATION_REQUIRES_NEW
??這個就比較繞口了。 比方我們設計ServiceA.methodA的事務級別為PROPAGATION_REQUIRED,ServiceB.methodB的事務級別為PROPAGATION_REQUIRES_NEW。那么當運行到ServiceB.methodB的時候,ServiceA.methodA所在的事務就會掛起。ServiceB.methodB會起一個新的事務。等待ServiceB.methodB的事務完畢以后,他才繼續運行。
他與PROPAGATION_REQUIRED 的事務差別在于事務的回滾程度了。由于ServiceB.methodB是新起一個事務,那么就是存在兩個不同的事務。假設ServiceB.methodB已經提交,那么ServiceA.methodA失敗回滾。ServiceB.methodB是不會回滾的。假設ServiceB.methodB失敗回滾,假設他拋出的異常被ServiceA.methodA捕獲,ServiceA.methodA事務仍然可能提交。
5.PROPAGATION_NOT_SUPPORTED
??當前不支持事務。比方ServiceA.methodA的事務級別是PROPAGATION_REQUIRED 。而ServiceB.methodB的事務級別是PROPAGATION_NOT_SUPPORTED ,那么當執行到ServiceB.methodB時。ServiceA.methodA的事務掛起。而他以非事務的狀態執行完,再繼續ServiceA.methodA的事務。
6.PROPAGATION_NEVER
??不能在事務中執行。
如果ServiceA.methodA的事務級別是PROPAGATION_REQUIRED。 而ServiceB.methodB的事務級別是PROPAGATION_NEVER ,那么ServiceB.methodB就要拋出異常了。
7.PROPAGATION_NESTED
??如果當前存在事務,則在嵌套事務內執行。如果當前沒有事務,則執行與PROPAGATION_REQUIRED類似的操作。
10.Spring事務實現的方式
編程式事務管理:這意味著你可以通過編程的方式管理事務,這種方式帶來了很大的靈活性,但很難維護。
聲明式事務管理:這種方式意味著你可以將事務管理和業務代碼分離。你只需要通過注解或者XML配置管理事務。
11.事務注解的本質是什么
??@Transactional 這個注解僅僅是一些(和事務相關的)元數據,在運行時被事務基礎設施讀取消費,并使用這些元數據來配置bean的事務行為。 大致來說具有兩方面功能,一是表明該方法要參與事務,二是配置相關屬性來定制事務的參與方式和運行行為
??聲明式事務主要是得益于Spring AOP。使用一個事務攔截器,在方法調用的前后/周圍進行事務性增強(advice),來驅動事務完成。
??@Transactional注解既可以標注在類上,也可以標注在方法上。當在類上時,默認應用到類里的所有方法。如果此時方法上也標注了,則方法上的優先級高。 另外注意方法一定要是public的。
https://cloud.fynote.com/share/d/IVeyV0Jp
12.談談你對BeanFactory和ApplicationContext的理解
目的:考察對IoC的理解
BeanFactory:Bean工廠 ==》IoC容器
BeanDefinition ===》Bean定義
BeanDefinitionRegistry ==》 BeanDefinition 和 BeanFactory的關聯
…
ApplicationContext:應用上下文
ApplicationContext ac = new ClasspathXmlApplicationContext(xxx.xml);
13.談談你對BeanFactoryPostProcessor的理解
BeanFactoryPostProcessor:是在BeanFactory創建完成后的后置處理
BeanFactory:對外提供Bean對象
需要知道怎么提供Bean對象–>BeanDefinition
XML/注解 --》 BeanDefinition --》注冊 --》完成BeanFactory的處理
1.需要交代BeanFactoryPostProcessor的作用
2.舉個例子
@Configuration 注解 --》 Java被 @Configuration注解標識–> 這是一個Java配置類
@Configuration–》@Component -->BeanDefinition --> 存儲在BeanFactory中 是當做一個普通的Bean管理的
@Bean @Primary 。。。。
ConfigurationClassPostProcessor
14.談談你對BeanPostProcessor的理解
針對Bean對象初始化前后。 針對Bean對象創建之后的處理操作。
SpringIoC 核心流程
BeanDefinition --> 注冊BeanDefinition -->BeanFactory --》BeanFactory的后置處理 --> 單例bean --> AOP --》 代理對象 —> advice pointcut join point 。。。
BeanPostProcessor 提供了一種擴展機制
自定義接口的實現 --》 注冊到BeanFactory的 Map中
BeanDefinition --> 注冊BeanDefinition -->BeanFactory --》BeanFactory的后置處理 --> 單例bean -->
遍歷上面的Map 執行相關的行為 --> 。。。。。
===》 AOP
IoC 和AOP的關系
有了IoC 才有 AOP DI
15.談談你對SpringMVC的理解
控制框架:前端控制器–》Servlet --》Web容器【Tomcat】
SpringMVC和Spring的關系 IoC容器關系–》父子關系
https://www.processon.com/view/link/63dc99aba7d181715d1f4569
Spring和SpringMVC的關系理解
Spring和SpringMVC整合的項目中
Controller Service Dao
具體的有兩個容器Spring中的IoC容器。然后SpringMVC中也有一個IoC容器
Controller中定義的實例都是SpringMVC組件維護的
Service和Dao中的實例都是由Spring的IoC容器維護的
這兩個容器有一個父子容器的關系
Spring容器是SpringMVC容器的父容器
16.談談你對DelegatingFilterProxy的理解
web.xml
Shiro SpringSecurity
Spring整合的第三方的組件會非常多
JWT 單獨登錄 OAuth2.0
組件:組合起來的零件–》組件 組合起來的技術棧–》組件框架
17.談談你對SpringBoot的理解
約定由于配置
自動裝配
SpringBoot和Spring的關系
SpringBoot的初始化 --> IoC Spring的初始化
SpringBoot的啟動 --> IoC
@SpringApplication注解 --> @Configuration -->ConfigurationClassPostProcessor --》 @Import注解 --》 延遲加載 --》 自動裝配 --> SPI 去重 排除 過濾
spring.factories
SSM框架的整合
1。導入依賴
2。添加配置文件
3。設置配置文件 web.xml
18.介紹下Import注解的理解
@Import注解是在Spring3.0的時候提供。目的是為了替換在XML配置文件中的import標簽。
@Import注解除了可以導入第三方的Java配置類還擴展了其他的功能
- 可以把某個類型的對象注入到容器中
- 導入的類型如果實現了ImportSelector接口。那么會調用接口中聲明的方法。然后把方法返回的類型全類路徑的類型對象注入到容器中
- 如果導入的類型實現了ImportBeanDefinitionRegistrar這個接口。那么就會調用聲明的方法在該方法中顯示的提供注冊器來完成注入
19.SpringBoot自動裝配中為什么用DeferredImportSelector
在SpringBoot自動裝配中核心是會加載所有依賴中的META-INF/spring.factories文件中的配置信息。
我們可以有多個需要加載的spring.factories文件。那么我們就需要多次操作。我們可以考慮把所有的信息都加載后再統一把這些需要注入到容器中的內容注入進去
DeferredImportSelector:延遲注入Bean實例的作用
20.SpringBoot中有了屬性文件為什么還要加一個bootstrap.yml文件?
??在單體的SpringBoot項目中其實我們是用不到bootstrap.yml文件的,bootsrap.yml文件的使用需要SpringCloud的支持,因為在微服務環境下我們都是有配置中心的,來統一的管理系統的相關配置屬性,那么怎么去加載配置中心的內容呢?一個SpringBoot項目啟動的時候默認只會加載對應的application.yml中的相關信息,這時bootstrap.yml的作用就體現出來了,會在SpringBoot正常啟動前創建一個父容器來通過bootstrap.yml中的配置來加載配置中心的內容。
21.如果要對屬性文件中的賬號密碼加密如何實現?
??其實這是一個比較篇實戰的一個問題,我們在application.yml中保存的MySQL數據庫的賬號密碼或者其他服務的賬號密碼,都可以保存加密后的內容,那么我們在處理的時候要怎么解密呢?這個其實比較簡單只需要對SpringBoot的執行流程清楚就可以了,第一個我們可以通過自定義監聽器可以在加載解析了配置文件之后對加密的文件中做解密處理同時覆蓋之前加密的內容,或者通過對應的后置處理器來處理,具體的實現如下:
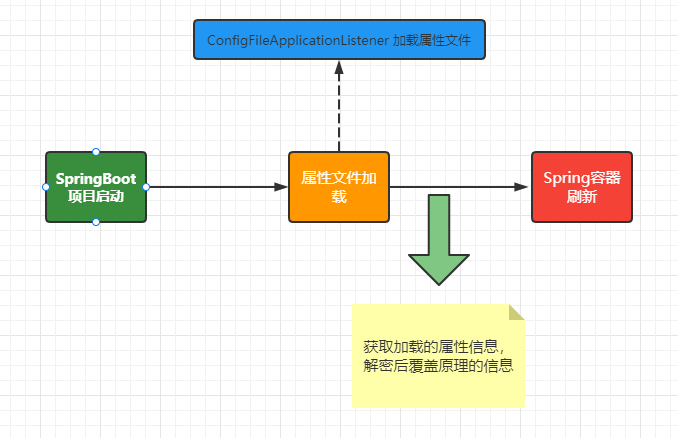
然后我們通過案例代碼來演示下,加深大家的理解
首先我們在屬性文件中配置加密后的信息
spring.datasource.driverClassName=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/mb?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.username=root
# 對通過3DES對密碼加密
spring.datasource.password=t5Jd2CzFWEw=spring.datasource.type=com.alibaba.druid.pool.DruidDataSourcemybatis.mapper-locations=classpath:mapper/*.xml
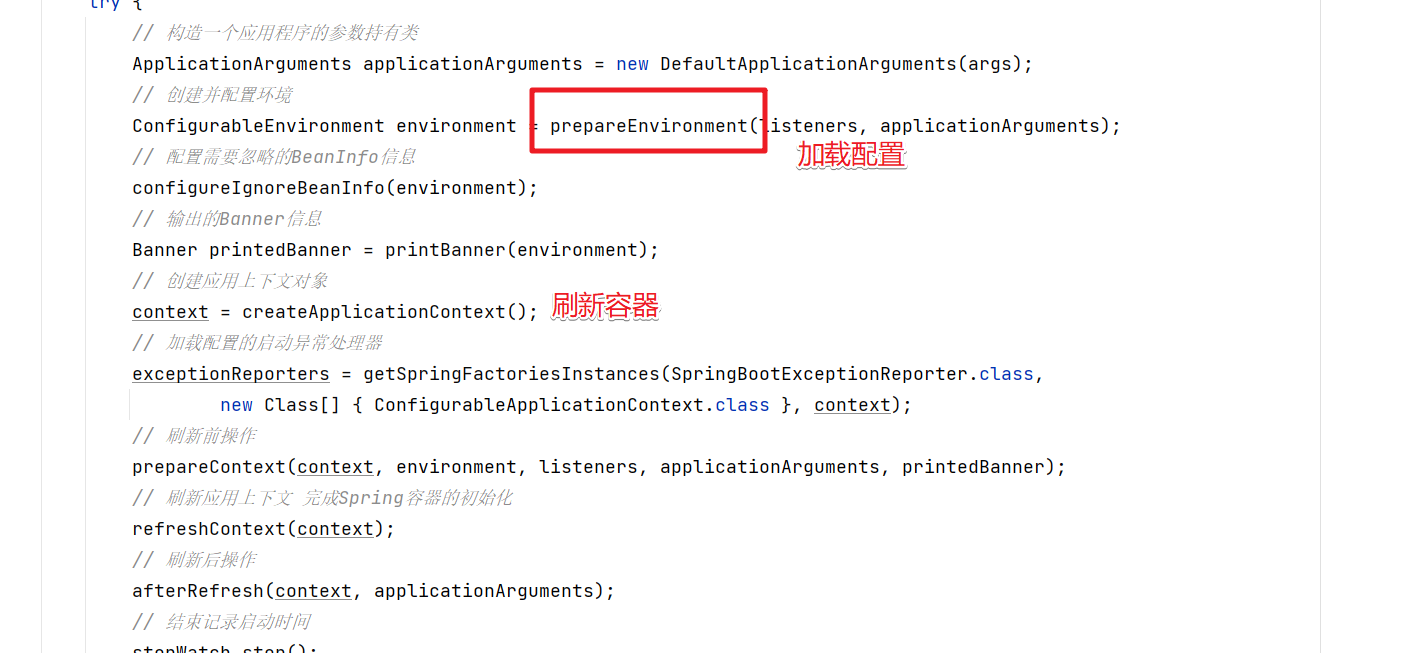
??在SpringBoot項目啟動的時候在在刷新Spring容器之前執行的,所以我們要做的就是在加載完環境配置信息后,獲取到配置的 spring.datasource.password=t5Jd2CzFWEw= 這個信息,然后解密并修改覆蓋就可以了。
 ??然后在屬性文件的邏輯其實是通過發布事件觸發對應的監聽器來實現的
??然后在屬性文件的邏輯其實是通過發布事件觸發對應的監聽器來實現的
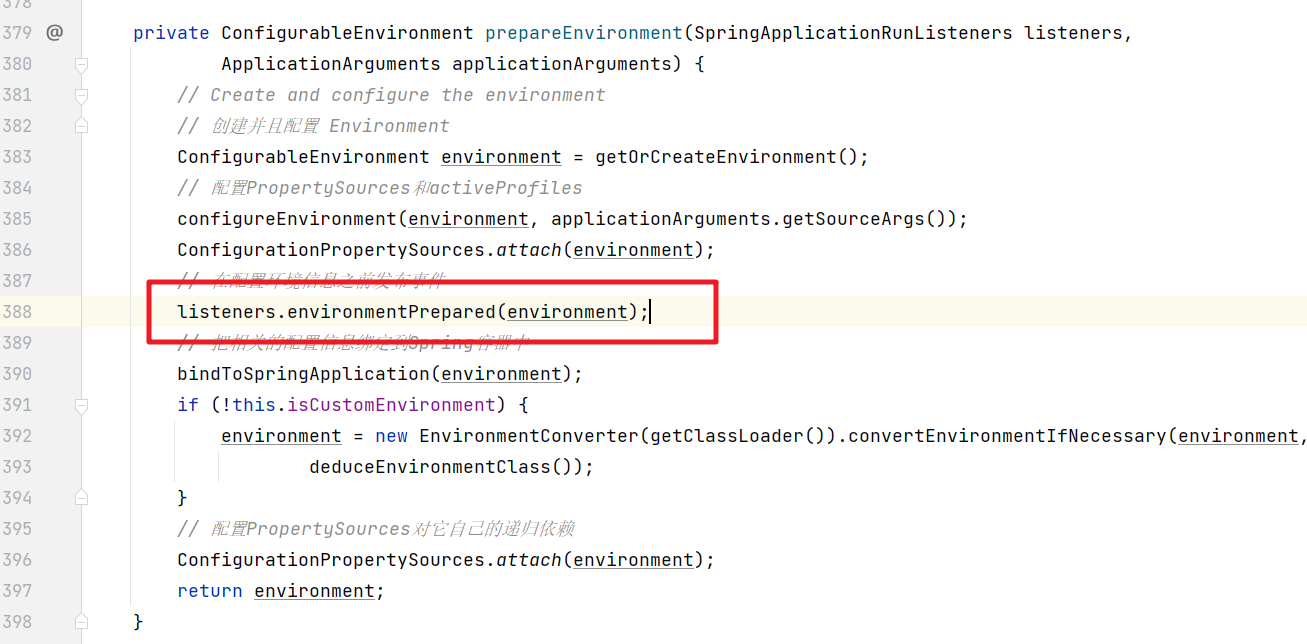
??所以第一個解決方案就是你自定義一個監聽器,這個監聽器在加載屬性文件(ConfigFileApplicationListener)的監聽器之后處理,這種方式稍微麻煩點,
??還有一種方式就是通過加載屬性文件的一個后置處理器來處理,這就以個為例來實現
3DES的工具類
/*** 3DES加密算法,主要用于加密用戶id,身份證號等敏感信息,防止破解*/
public class DESedeUtil {//秘鑰public static final String KEY = "~@#$y1a2n.&@+n@$%*(1)";//秘鑰長度private static final int secretKeyLength = 24;//加密算法private static final String ALGORITHM = "DESede";//編碼private static final String CHARSET = "UTF-8";/*** 轉換成十六進制字符串* @param key* @return*/public static byte[] getHex(String key){byte[] secretKeyByte = new byte[24];try {byte[] hexByte;hexByte = new String(DigestUtils.md5Hex(key)).getBytes(CHARSET);//秘鑰長度固定為24位System.arraycopy(hexByte,0,secretKeyByte,0,secretKeyLength);} catch (UnsupportedEncodingException e) {e.printStackTrace();}return secretKeyByte;}/*** 生成密鑰,返回加密串* @param key 密鑰* @param encodeStr 將加密的字符串* @return*/public static String encode3DES(String key,String encodeStr){try {Cipher cipher = Cipher.getInstance(ALGORITHM);cipher.init(Cipher.ENCRYPT_MODE, new SecretKeySpec(getHex(key), ALGORITHM));return Base64.encodeBase64String(cipher.doFinal(encodeStr.getBytes(CHARSET)));}catch(Exception e){e.printStackTrace();}return null;}/*** 生成密鑰,解密,并返回字符串* @param key 密鑰* @param decodeStr 需要解密的字符串* @return*/public static String decode3DES(String key, String decodeStr){try {Cipher cipher = Cipher.getInstance(ALGORITHM);cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(getHex(key),ALGORITHM));return new String(cipher.doFinal(new Base64().decode(decodeStr)),CHARSET);} catch(Exception e){e.printStackTrace();}return null;}public static void main(String[] args) {String userId = "123456";String encode = DESedeUtil.encode3DES(KEY, userId);String decode = DESedeUtil.decode3DES(KEY, encode);System.out.println("用戶id>>>"+userId);System.out.println("用戶id加密>>>"+encode);System.out.println("用戶id解密>>>"+decode);}}
聲明后置處理器
public class SafetyEncryptProcessor implements EnvironmentPostProcessor {@Overridepublic void postProcessEnvironment(ConfigurableEnvironment environment, SpringApplication application) {for (PropertySource<?> propertySource : environment.getPropertySources()) {System.out.println("propertySource = " + propertySource);if(propertySource instanceof OriginTrackedMapPropertySource){OriginTrackedMapPropertySource source = (OriginTrackedMapPropertySource) propertySource;for (String propertyName : source.getPropertyNames()) {//System.out.println(propertyName + "=" + source.getProperty(propertyName));if("spring.datasource.password".equals(propertyName)){Map<String,Object> map = new HashMap<>();// 做解密處理String property = (String) source.getProperty(propertyName);String s = DESedeUtil.decode3DES(DESedeUtil.KEY, property);System.out.println("密文:" + property);System.out.println("解密后的:" + s);map.put(propertyName,s);// 注意要添加到前面,覆蓋environment.getPropertySources().addFirst(new MapPropertySource(propertyName,map));}}}}}
}
然后在META-INF/spring.factories文件中注冊
org.springframework.boot.env.EnvironmentPostProcessor=com.bobo.util.SafetyEncryptProcessor
然后啟動項目就可以了
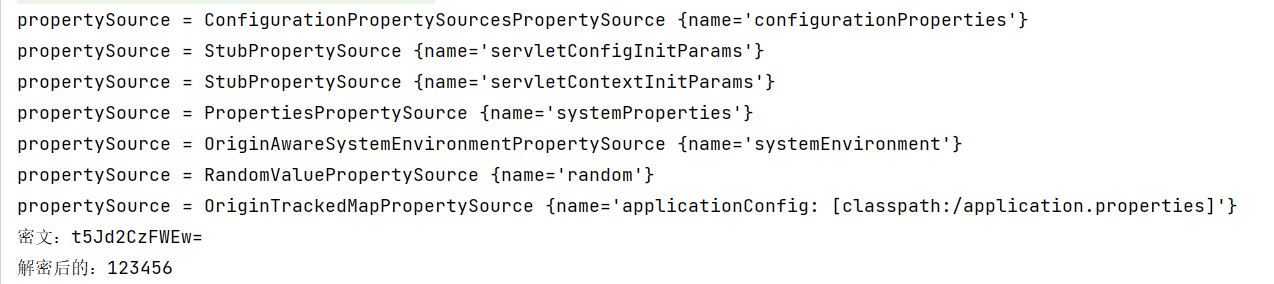
??搞定
22.談談Indexed注解的作用
@Indexed注解是Spring5.0提供
Indexed注解解決的問題:是隨著項目越來越復雜那么@ComponentScan需要掃描加載的Class會越來越多。在系統啟動的時候會造成性能損耗。所以Indexed注解的作用其實就是提升系統啟動的性能。
在系統編譯的時候那么會收集所有被@Indexed注解標識的Java類。然后記錄在META-INF/spring.components文件中。那么系統啟動的時候就只需要讀取一個該文件中的內容就不用在遍歷所有的目錄了。提升的效率
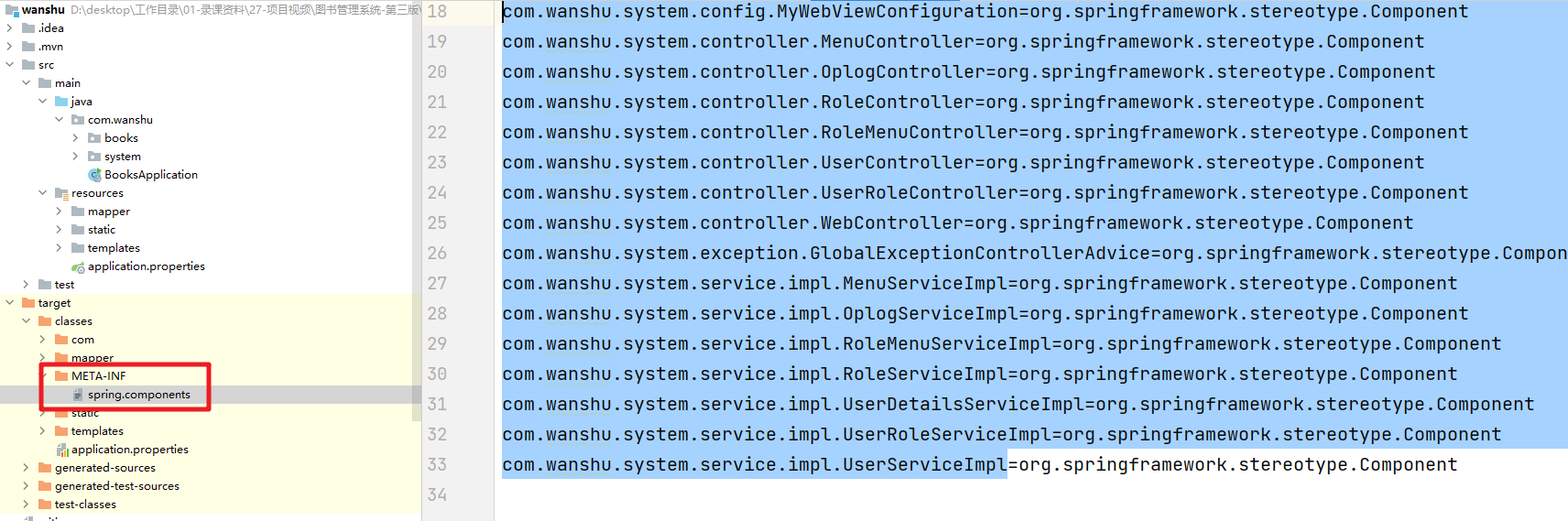
23.@Component, @Controller, @Repository,@Service 有何區別?
@Component :這將 java 類標記為 bean。它是任何 Spring 管理組件的通用構造型。spring 的組件掃描機制現在可以將其拾取并將其拉入應用程序環境中。
@Controller :這將一個類標記為 Spring Web MVC 控制器。標有它的Bean 會自動導入到 IoC 容器中。
@Service :此注解是組件注解的特化。它不會對 @Component 注解提供任何其他行為。您可以在服務層類中使用@Service 而不是 @Component,因為它以更好的方式指定了意圖。
@Repository :這個注解是具有類似用途和功能的 @Component 注解的特化。它為 DAO 提供了額外的好處。它將 DAO 導入 IoC 容器,并使未經檢查的異常有資格轉換為 Spring DataAccessException。
24.有哪些通知類型(Advice)
前置通知:Before - 這些類型的 Advice 在 joinpoint 方法之前執行,并使用@Before 注解標記進行配置。
后置通知:After Returning - 這些類型的 Advice 在連接點方法正常執行后執行,并使用@AfterReturning 注解標記進行配置。
異常通知:After Throwing - 這些類型的 Advice 僅在 joinpoint 方法通過拋出異常退出并使用 @AfterThrowing 注解標記配置時執行。
最終通知:After (finally) - 這些類型的 Advice 在連接點方法之后執行,無論方法退出是正常還是異常返回,并使用 @After 注解標記進行配置。
環繞通知:Around - 這些類型的 Advice 在連接點之前和之后執行,并使用@Around 注解標記進行配置。
25.什么是 Spring 的依賴注入?
依賴注入,是 IOC 的一個方面,是個通常的概念,它有多種解釋。這概念是說你不用創建對象,而只需要描述它如何被創建。你不在代碼里直接組裝你的組件和服務,但是要在配置文件里描述哪些組件需要哪些服務,之后一個容器(IOC 容器)負責把他們組裝起來。
BeanFactory
BeanDefinition
BeanDefinitionRegistry
ApplicationContext
–》 DI
–》 AOP
–》事務。日志
26.Spring 框架中的單例 bean 是線程安全的嗎?
不,Spring 框架中的單例 bean 不是線程安全的。









)

特征檢測與描述用于檢測二值圖像中連通區域(即“斑點”或“blob”)的類cv::SimpleBlobDetector的使用)







