分布式
如何理解分布式
狹義的分布是指,指多臺PC在地理位置上分布在不同的地方。
分布式系統
分布式系**統:**多個能獨立運行的計算機(稱為結點)組成。各個結點利用計算機網絡進行信息傳遞,從而實現共同的“目標或者任務”。
分布式程序: 運行在分布式系統上的計算機程序。
分布式計算:利用分布式系統解決來計算問題。在分布式計算里,一個問題被細化成多個任務,每個任務可以被一個或者多個計算機來完成。
區分分布式計算和并行計算:共同點都是大任務劃分為小任務。不同點: 分布式計算:基于多臺PC,每臺PC完成同一任務中的不同部分。分布式的計算被分解后的小任務互相之間有獨立性,節點之間的結果幾乎不互相影響,實時性要求不高。并行計算:基于同一個臺PC,利用CPU的多核共同完成一個任務。
-
分布式操作系統:負責管理分布式處理系統資源和控制分布式程序運行。它和集中式操作系統的區別在于資源管理、進程通信和系統結構等方面
-
分布式文件系統:分布式文件系統具有執行遠程文件存取得能力,并以透明方式對分布在網絡上得文件進行管理和存取
-
分布式程序設計和編譯解釋系統
分布式事務
事務 事務提供一種“要么什么都不做,要么做全套(All or Nothing)”的機制,她有ACID四大特性 原子性(Atomicity):事務作為一個整體被執行,包含在其中的對數據庫的操作要么全部被執行,要么都不執行。 一致性(Consistency):事務應確保數據庫的狀態從一個一致狀態轉變為另一個一致狀態。一致狀態是指數據庫中的數據應滿足完整性約束。除此之外,一致性還有另外一層語義,就是事務的中間狀態不能被觀察到(這層語義也有說應該屬于原子性)。 隔離性(Isolation):多個事務并發執行時,一個事務的執行不應影響其他事務的執行,如同只有這一個操作在被數據庫所執行一樣。 持久性(Durability):已被提交的事務對數據庫的修改應該永久保存在數據庫中。在事務結束時,此操作將不可逆轉。 單機事務 以mysql的InnoDB存儲引擎為例,來了解單機事務是如何保證ACID特性的。

分布式事務 單機事務是通過將操作限制在一個會話內通過數據庫本身的鎖以及日志來實現ACID,那么分布式環境下該如何保證ACID特性那? 2.2.1 XA協議實現分布式事務
2.2.1.1 XA描述 X/Open DTP(X/Open Distributed Transaction Processing Reference Model) 是X/Open 這個組織定義的一套分布式事務的標準,也就是了定義了規范和API接口,由各個廠商進行具體的實現。 X/Open DTP 定義了三個組件: AP,TM,RM
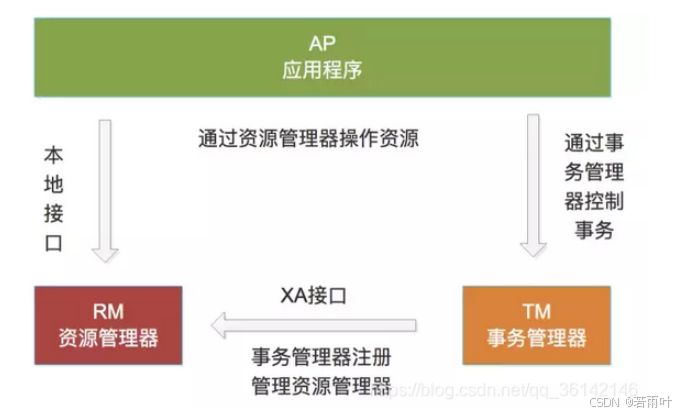
2PC
二階段提交
二階段提交是一種強一致性設計,2PC引入一個事務協調者的角色來協調管理各參與者(各本地資源)的提交和回滾,二階段分別指的是準備和提交兩個階段
準備階段:協調者會給各參與者發送準備命令,可以把準備命令理解成除了提交事務之外的事都做完了
同步等待所有資源的響應之后就進入第二階段即提交階段(提交階段不一定是提交事務,也可能是回滾事務)
假如在第一階段所有參與者都返回準備成功,那么協調者則向所有參與者發送提交事務命令,然后等待所有事務都提交成功之后,返回事務執行成功。
假如在第一階段有一個參與者返回失敗,那么協調者就會向所有參與者發送回滾事務的請求,即分布式事務執行失敗
如果第二階段提交失敗
第一種情況:第二階段執行的是回滾事務操作,那么就是不斷重試,直到所有參與者都回滾了。不然那些在第一階段準備成功的參與者會一直阻塞著
第二種情況:第二階段執行的是提交事務操作,也是不斷重試,因為有可能一些參與者的事務已經提交成功了,這個時候只有一條路,就是不斷的重試,直到提交成功。
2PC是一個同步阻塞協議,像第一階段協調者會等待所有參與者響應了才會進行下一步操作,當然第一階段的協調者有超時機制,假設因為網絡原因沒有收到某參與者的響應或某參與者掛了,那么超時之后就會判斷事務失敗,向所有參與者發送回滾命令
協調者故障分析
協調者是一個單點,存在單點故障問題
假設協調者在發送準備命令之前掛了,就等于事務還沒開始
假設協調者在發送準備命令之后掛了,參與者等于都執行了處于事務資源鎖定的狀態。不僅事務執行不下去,還會因為鎖定了一些公共資源而阻塞系統其他操作
假設協調者在發送回滾事務命令之前掛了,事務無法執行,且在第一階段那些準備成功參與者都阻塞著
假設協調者在發送回滾事務命令之后掛了,至少命令發出去了,很大的概率都會回滾成功,資源都會釋放,但是 如果出現網絡分區的問題,某些參與者將因為收不到命令而阻塞著。
假設協調者在發送提交事務命令之前掛了,這下所有資源都阻塞了
假設協調者在發送提交事務命令之后掛了,至少命令發出去了,很大概率都會提交成功,然后釋放資源,但是如果出現網絡分區問題某些參與者將因為收不到命令而阻塞著
協調者故障,通過選舉得到新協調者
因為協調者單點問題,因此我們可以通過選舉等操作選出一個新協調者來頂替。
如果處于第一階段,其實影響不大都回滾好了,在第一階段事務肯定還沒提交。
如果處于第二階段,假設參與者都沒掛,此時新協調者可以向所有參與者確認它們自身情況來推斷下一步的操作。
假設有個別參與者掛了!這就有點僵硬了,比如協調者發送了回滾命令,此時第一個參與者收到了并執行,然后協調者和第一個參與者都掛了。
此時其他參與者都沒收到請求,然后新協調者來了,它詢問其他參與者都說OK,但它不知道掛了的那個參與者到底O不OK,所以它傻了。
問題其實就出在每個參與者自身的狀態只有自己和協調者知道,因此新協調者無法通過在場的參與者的狀態推斷出掛了的參與者是什么情況。
雖然協議上沒說,不過在實現的時候我們可以靈活的讓協調者將自己發過的請求在哪個地方記一下,也就是日志記錄,這樣新協調者來的時候不就知道此時該不該發了?
但是就算協調者知道自己該發提交請求,那么在參與者也一起掛了的情況下沒用,因為你不知道參與者在掛之前有沒有提交事務。
如果參與者在掛之前事務提交成功,新協調者確定存活著的參與者都沒問題,那肯定得向其他參與者發送提交事務命令才能保證數據一致。
如果參與者在掛之前事務還未提交成功,參與者恢復了之后數據是回滾的,此時協調者必須是向其他參與者發送回滾事務命令才能保持事務的一致。
所以說極端情況下還是無法避免數據不一致問題
協調者:write START_2PC to local log; //開始事務multicast VOTE_REQUEST to all participants; //廣播通知參與者投票while not all votes have been collected {wait for any incoming vote;if timeout { //協調者超時write GLOBAL_ABORT to local log; //寫日志multicast GLOBAL_ABORT to all participants; //通知事務中斷exit;}record vote;}//如果所有參與者都okif all participants sent VOTE_COMMIT and coordinator votes COMMIT {write GLOBAL_COMMIT to local log;multicast GLOBAL_COMMIT to all participants;} else {write GLOBAL_ABORT to local log;multicast GLOBAL_ABORT to all participants;}?
參與者:
?write INIT to local log; //寫日志wait for VOTE_REQUEST from coordinator;if timeout { //等待超時write VOTE_ABORT to local log;exit;}if participant votes COMMIT {write VOTE_COMMIT to local log; //記錄自己的決策send VOTE_COMMIT to coordinator;wait for DECISION from coordinator;if timeout {multicast DECISION_REQUEST to other participants; //超時通知wait until DECISION is received; ?/* remain blocked*/write DECISION to local log;}if DECISION == GLOBAL_COMMITwrite GLOBAL_COMMIT to local log;else if DECISION == GLOBAL_ABORTwrite GLOBAL_ABORT to local log;} else {write VOTE_ABORT to local log;send VOTE_ABORT to coordinator;}
??
每個參與者維護一個線程處理其它參與者的DECISION_REQUEST請求:
?while true {wait until any incoming DECISION_REQUEST is received;read most recently recorded STATE from the local log;if STATE == GLOBAL_COMMITsend GLOBAL_COMMIT to requesting participant;else if STATE == INIT or STATE == GLOBAL_ABORT;send GLOBAL_ABORT to requesting participant;elseskip; ?/* participant remains blocked */}
?2PC是一種盡量保證強一致性的分布式事務,因此他是同步阻塞的,而同步阻塞就導致長久的資源鎖定問題,總體而言效率低,并且存在單點故障問題,在極端條件下存在數據不一致的風險
3PC
相比于2PC它在參與者中也引入了超時機制,并且新增了一個階段使得參與者可以利用這一個階段統一各自的狀態
三個階段:準備階段、預提交階段和提交階段
準備階段 不會直接執行事務,而是先詢問此時的參與者是否有條件接這個任務,因此不會一來就干活直接鎖資源,使得在某些資源不可用的情況下所有參與者都阻塞著
預提交階段的引入起到了一個統一狀態的作用,它像一道柵欄,表明在預提交階段前所有參與者其實還未都回應,在預處理階段表明所有參與者都已經回應了
假如你是一位參與者,你知道自己進入了預提交狀態那你就可以推斷出來其他參與者也都進入了預提交狀態。
但是多引入一個階段也多一個交互,因此性能會差一些,而且絕大部分的情況下資源應該都是可用的,這樣等于每次明知可用執行還得詢問一次。
2PC 是同步阻塞的,上面我們已經分析了協調者掛在了提交請求還未發出去的時候是最傷的,所有參與者都已經鎖定資源并且阻塞等待著。
那么引入了超時機制,參與者就不會傻等了,如果是等待提交命令超時,那么參與者就會提交事務了,因為都到了這一階段了大概率是提交的,如果是等待預提交命令超時,那該干啥就干啥了,反正本來啥也沒干。
然而超時機制也會帶來數據不一致的問題,比如在等待提交命令時候超時了,參與者默認執行的是提交事務操作,但是有可能執行的是回滾操作,這樣一來數據就不一致了。 3PC 的引入是為了解決提交階段 2PC 協調者和某參與者都掛了之后新選舉的協調者不知道當前應該提交還是回滾的問題。
新協調者來的時候發現有一個參與者處于預提交或者提交階段,那么表明已經經過了所有參與者的確認了,所以此時執行的就是提交命令。
所以說 3PC 就是通過引入預提交階段來使得參與者之間的狀態得到統一,也就是留了一個階段讓大家同步一下。
但是這也只能讓協調者知道該如果做,但不能保證這樣做一定對,這其實和上面 2PC 分析一致,因為掛了的參與者到底有沒有執行事務無法斷定。
所以說 3PC 通過預提交階段可以減少故障恢復時候的復雜性,但是不能保證數據一致,除非掛了的那個參與者恢復。
讓我們總結一下, 3PC 相對于 2PC 做了一定的改進:引入了參與者超時機制,并且增加了預提交階段使得故障恢復之后協調者的決策復雜度降低,但整體的交互過程更長了,性能有所下降,并且還是會存在數據不一致問題。
所以 2PC 和 3PC 都不能保證數據100%一致,因此一般都需要有定時掃描補償機制。
提交階段和2PC的一樣
無論哪一個階段有參與者返回失敗都會宣布事務失敗
TCC
2PC和3PC都是數據庫層面的,而TCC是業務層面的分布式事務
TCC指的是Try confirm Cancel
-
try指的是預留,即資源的預留和鎖定
-
confirm 指的是確認操作,這一步其實就是真正的執行了
-
cancel指的是撤銷操作,可以理解為把預留階段的的動作撤銷了
其實從思想上看和 2PC 差不多,都是先試探性的執行,如果都可以那就真正的執行,如果不行就回滾。
比如說一個事務要執行A、B、C三個操作,那么先對三個操作執行預留動作。如果都預留成功了那么就執行確認操作,如果有一個預留失敗那就都執行撤銷動作。
TCC對業務的侵入比較大和業務緊耦合,需要根據特定的場景和業務邏輯來設計相應的操作
撤銷和確認操作的執行可能需要重試,因此還需要保證操作的冪
相對于 2PC、3PC ,TCC 適用的范圍更大,但是開發量也更大,畢竟都在業務上實現,而且有時候你會發現這三個方法還真不好寫。不過也因為是在業務上實現的,所以TCC可以跨數據庫、跨不同的業務系統來實現事務。
本地消息表
本地消息表其實就是利用了 各系統本地的事務來實現分布式事務。
本地消息表顧名思義就是會有一張存放本地消息的表,一般都是放在數據庫中,然后在執行業務的時候 將業務的執行和將消息放入消息表中的操作放在同一個事務中,這樣就能保證消息放入本地表中業務肯定是執行成功的。
然后再去調用下一個操作,如果下一個操作調用成功了好說,消息表的消息狀態可以直接改成已成功。
如果調用失敗也沒事,會有 后臺任務定時去讀取本地消息表,篩選出還未成功的消息再調用對應的服務,服務更新成功了再變更消息的狀態。
這時候有可能消息對應的操作不成功,因此也需要重試,重試就得保證對應服務的方法是冪等的,而且一般重試會有最大次數,超過最大次數可以記錄下報警讓人工處理。
可以看到本地消息表其實實現的是最終一致性,容忍了數據暫時不一致的情況。
消息事務
RocketMQ就很好的支持了消息事務
第一步先給Broker發送事務消息即半消息,半消息不是說一般消息,而是這個消息對消費者來說不可見,然后發送成功后發送方在執行本地事務
再根據本地事務的結果向Broker發送Commit或者RollBack命令
并且RocketMQ的發送方會提供一個反查事務狀態接口,如果一段時間內半消息沒有收到任何操作請求,那么Broker會通過反查接口得知發送方事務是否執行成功,然后執行Commit或者RollBack命令
如果是Commit那么訂閱方就能收到這條消息,然后再做對應的操作,做完了之后再消費這條消息即可
如果是RollBack那么訂閱方收不到這條消息,等于事務就沒執行過
可以看到通過 RocketMQ 還是比較容易實現的,RocketMQ 提供了事務消息的功能,我們只需要定義好事務反查接口即可。
:圖像處理與深度學習的革命性技術)







)




C++11 可變參數模版、lambda表達式、包裝器與部分新內容添加)
)




