1. 簡介
融合激光雷達和相機的信息已經變成了3D目標檢測的一個標準,當前的方法依賴于激光雷達傳感器的點云作為查詢,以利用圖像空間的特征。然而,人們發現,這種基本假設使得當前的融合框架無法在發生 LiDAR 故障時做出任何預測,無論是輕微還是嚴重。這從根本上限制了實際場景下的部署能力。相比之下,在BEVFusion框架中,其相機流不依賴于 LiDAR 數據的輸入,從而解決了以前方法的缺點。
有兩個版本的BEVFusion,分別是北大與阿里合作的Bevfusion: A Simple and Robust LiDAR-Camera和麻省理工發表的Bevfusion: Multi-task multi-sensor fusion with unified bird's-eye view representation,下面分別進行介紹。
2. PKU BEVFusion
作者認為,LiDAR和相機融合的理想框架應該是,無論彼此是否存在,單個模態的每個模型都不應該失敗,但同時擁有兩種模態將進一步提高感知準確性。為此,作者提出了一個令人驚訝的簡單而有效的框架,它解決了當前方法的LiDAR相機融合的依賴性,稱為BEVFusion。具體來說,如圖1 (c)所示,作者的框架有兩個獨立的流,它們將來自相機和LiDAR傳感器的原始輸入編碼為同一BEV空間內的特征。然后作者設計了一個簡單的模塊,在這兩個流之后融合這些BEV的特征,以便最終的特征可以傳遞到下游任務架構中。由于作者的框架是一種通用方法,作者可以將當前用于相機和LiDAR的單模態BEV模型合并到作者的框架中。作者采用Lift-Splat-Shoot作為相機流,它將多視圖圖像特征投影到3D車身坐標特征以生成相機BEV特征。同樣,對于LiDAR流,作者選擇了三個流行的模型,兩個基于超體素(voxel)的模型和一個基于柱子(pillar)的模型將LiDAR特征編碼到BEV空間中。
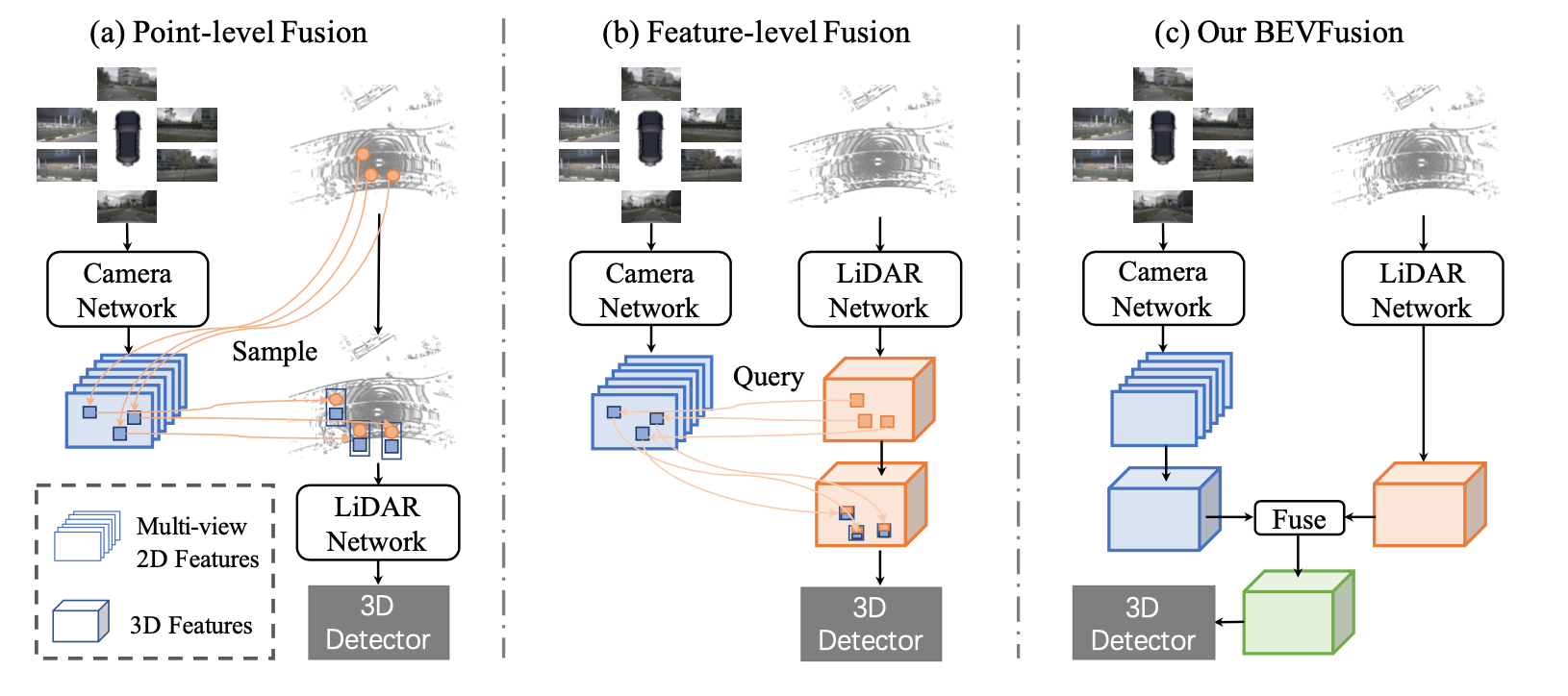
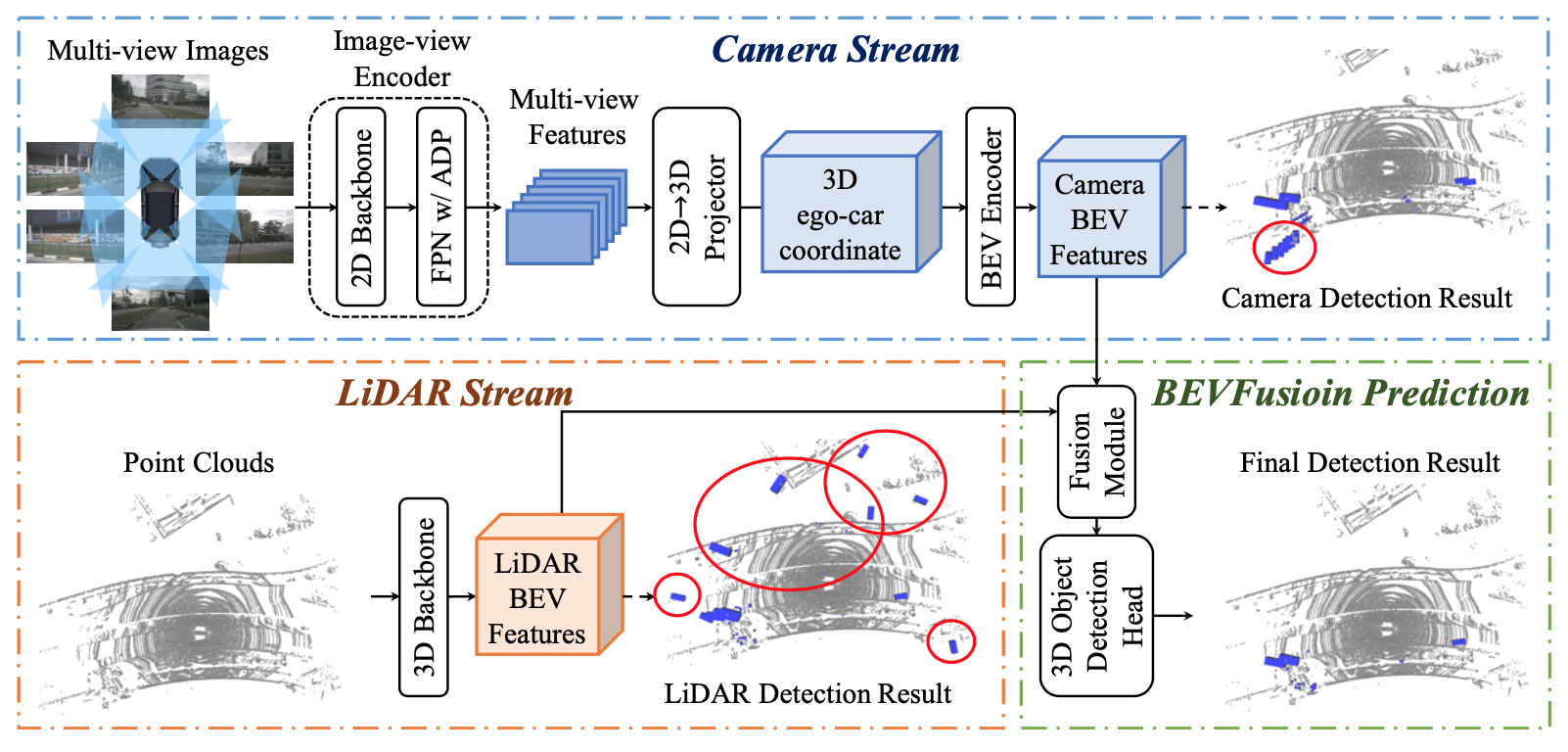
3. MIT BEVFusion

 3.1. 統一表示
3.1. 統一表示
不同的視圖中可以存在不同的特征。例如,相機特征在透視視圖中,而激光雷達/雷達特征通常在3D/鳥瞰視圖中。即使是相機功能,每個功能都有不同的視角(即前、后、左、右)。這個視圖差異使得特征融合變得困難,因為不同特征張量中的相同元素可能對應完全不同的空間位置(在這種情況下,naive elementwise特征融合將不起作用)。因此,找到一個共享的表示是至關重要的,這樣(1)所有傳感器特征都可以很容易地轉換為它而不丟失信息,(2)它適合于不同類型的任務。
相機。在RGB-D數據的激勵下,一種選擇是將LiDAR點云投影到相機平面上,并渲染2.5D稀疏深度。然而,這種轉換在幾何上是有損的。深度圖上的兩個鄰居在3D空間中可以彼此遠離。這使得相機視圖對于專注于物體/場景幾何的任務(如3D物體檢測)的效果較差。
激光雷達。大多數最先進的傳感器融合方法用相應的攝像機特征(例如語義標簽、CNN特征或虛擬點)裝飾LiDAR點。然而,這種攝像頭到激光雷達的投影在語義上是有損耗的。相機和激光雷達功能的密度有很大的不同,導致只有不到5%的相機功能與激光雷達點匹配(對于32通道激光雷達掃描儀)。放棄相機特征的語義密度嚴重損害了模型在面向語義任務(如BEV地圖分割)上的性能。類似的缺點也適用于潛在空間中的最新融合方法(例如,對象查詢)。
鳥瞰圖。采用鳥瞰圖(BEV)作為融合的統一表示。這個視圖對幾乎所有的感知任務都是友好的,因為輸出空間也是在BEV中。更重要的是,向BEV的轉換同時保持幾何結構(來自激光雷達特征)和語義密度(來自相機特征)。一方面,LiDAR- bev投影將稀疏的LiDAR特征沿高度維度平坦化,從而不會在圖1a中產生幾何失真。另一方面,相機到BEV投影將每個相機特征像素投射回3D空間中的射線(下一節將詳細介紹),這可能導致圖1c中密集的BEV特征映射,其中保留了來自相機的完整語義信息。
3.2. 高效的攝像頭到BEV的轉換
攝像頭到BEV的轉換不是簡單的,因為與每個攝像頭特征像素相關的深度本質上是模糊的。根據LSS和BEVDet,他們明確地預測了每個像素的離散深度分布。然后,他們將每個特征像素沿攝像機射線分散到D個離散點,并根據相應的深度概率重新縮放相關特征(圖3a)。這將生成一個大小為N HW D的相機特征點云,其中N是相機的數量,(H, W)是相機特征映射的大小。該三維特征點云沿x、y軸進行量化,步長為r(例如0.4m)。他們使用BEV池化操作來聚集每個r × r BEV網格中的所有特征,并沿z軸將特征平坦化。
雖然簡單,但BEV池化的效率和速度驚人地低,在RTX 3090 GPU上需要超過500毫秒(而他們模型的其余部分只需要大約100毫秒)。這是因為攝像特征點云非常大:對于典型的工作負載,每幀可能生成大約200萬個點,比激光雷達特征點云的密度大兩個數量級。為了克服這一效率瓶頸,他們提出了通過預計算和間隔縮短來優化BEV池。
預先計算。BEV池化的第一步是將攝像機特征點云中的每個點與BEV網格關聯。與LiDAR點云不同,相機特征點云的坐標是固定的(只要相機的intrinsic和extrinsics保持不變,這通常是在適當校準后的情況下)。在此基礎上,他們預先計算每個點的3D坐標和BEV網格索引。他們還根據網格索引對所有點進行排序,并記錄每個點的排名。在推理過程中,他們只需要根據預先計算的秩對所有特征點進行重新排序。這種緩存機制可以將網格關聯的延遲從17ms減少到4ms。
間隔的減少。網格關聯后,同一BEV網格內的所有點在張量表示中都是連續的。BEV池化的下一步是通過一些對稱函數(例如,均值、最大值和和)聚合每個BEV網格中的特征。如圖3b所示,現有實現首先計算所有點的前綴和,然后減去索引變化邊界處的值。然而,前綴和操作需要GPU上的樹約簡,并產生許多未使用的部分和(因為他們只需要邊界上的那些值),這兩者都是低效的。為了加速特征聚合,他們實現了一個專門的GPU內核,它直接在BEV網格上并行:他們為每個網格分配一個GPU線程,計算它的間隔和并將結果寫回來。該內核消除了輸出之間的依賴關系(因此不需要多級樹約化),并避免將部分和寫入DRAM,將特征聚合的延遲從500ms減少到2ms(圖3c)。
其他。通過優化的BEV池化,相機到BEV的轉換速度提高了40倍:延遲從超過500ms減少到12ms(僅占他們模型端到端運行時間的10%),并且在不同的特征分辨率上都能很好地伸縮(圖3d)。這是在共享BEV表示中統一多模態感官特征的關鍵使能器。我們同時進行的兩項工作也確定了僅在相機的3D檢測中的效率瓶頸。他們通過假設均勻的深度分布或截斷每個BEV網格中的點來近似視圖轉換器。相比之下,他們的技術是精確的,沒有任何近似,同時仍然更快。
3.3. 全卷積融合
將所有的感官特征轉換為共享的BEV表示,他們可以很容易地用一個元素操作符(如拼接)將它們融合在一起。盡管在同一空間中,由于視圖轉換器的深度不準確,LiDAR BEV特征和相機BEV特征仍然會在一定程度上出現空間錯位。為此,他們應用了一個基于卷積的BEV編碼器(帶有一些剩余塊)來補償這種局部失調。他們的方法可能從更精確的深度估計中受益(例如,用地面真實深度監視視圖轉換器),他們將其留給未來的工作。
3.4. 多任務頭
他們將多個特定于任務的頭應用到融合BEV特征圖中。他們的方法適用于大多數3D感知任務。他們展示了兩個例子:三維物體檢測和BEV地圖分割。
檢測。他們使用特定于類的中心熱圖頭來預測所有對象的中心位置,并使用一些回歸頭來估計對象的大小、旋轉和速度。我們建議讀者參考之前的3D檢測論文[1, 67, 68]了解更多細節。
分割。不同的地圖類別可能會重疊(例如,人行橫道是可駕駛空間的子集)。因此,他們將這個問題表述為多個二進制語義分割,每個類一個。他們遵循CVT,用標準focal loss來訓練分割頭。


參考文獻
https://download.csdn.net/blog/column/11257654/134724055
Bevfusion: A Simple and Robust LiDAR-Camera
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework - 知乎
BEVFusion:A Simple and Robust LiDAR-Camera Fusion Framework 論文筆記_bevfusion: a simple and robust lidar-camera fusion-CSDN博客
Bevfusion: Multi-task multi-sensor fusion with unified bird's-eye view representation
技術精講 | BEVFusion: 基于統一BEV表征的多任務多傳感器融合-CSDN博客?
BEVFusion論文解讀-CSDN博客

)














遠程終端協議TELNET)
)

