
大型語言模型 (LLM) 極大地改變了普通人獲取數據的方式。不到一年前,訪問公司數據需要具備技術技能,包括熟練掌握各種儀表板工具,甚至深入研究數據庫查詢語言的復雜性。然而,隨著 ChatGPT 等 LLM 的興起,隨著所謂的檢索增強型 LLM 應用程序的興起,隱藏在私人數據庫中或可通過各種 API 訪問的豐富知識現在比以往任何時候都更容易獲得。
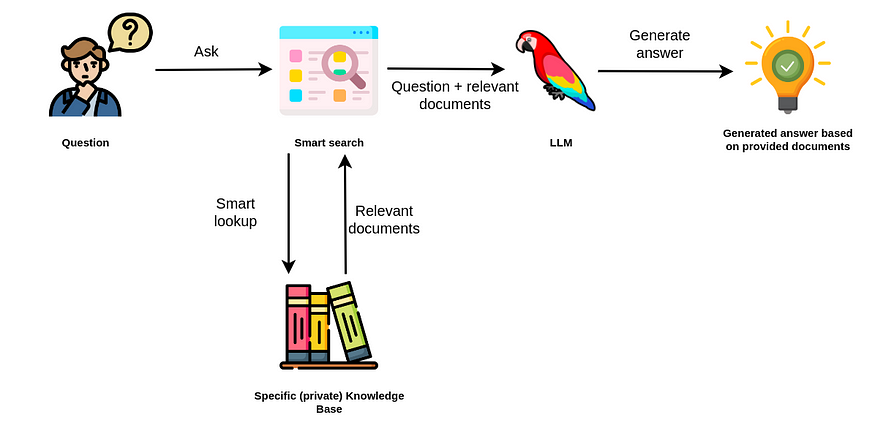
檢索增強生成應用程序。
檢索增強應用程序背后的想法是從各種來源檢索更多信息,以便 LLM 生成更好、更準確的結果。OpenAI 似乎也注意到了這一趨勢,他們最近推出了 OpenAI函數。新的 OpenAI 模型經過訓練,可以使用為函數(或其他庫所稱的工具))提供參數,這些函數的簽名和描述在上下文中傳遞,以便在查詢時根據需要檢索更多信息。
我們觀察到,在檢索增強應用中,向量相似性搜索具有很強的偏向性。如果您在過去三個月內打開過 Twitter 或 LinkedIn,您可能已經看到過各種“與 PDF 聊天”應用。在這些示例中,實現相對簡單。文本從 PDF 中提取,根據需要拆分成塊,最后連同其文本嵌入表示一起存儲在向量數據庫中。
這類應用的入門門檻很低,特別是當你處理少量數據時。如今發表的很多文章給人的印象是只有矢量數據庫才適用于檢索增強應用,這真是令人著迷。
雖然基于向量相似度的非結構化文本信息檢索具有巨大的潛力,但我們相信結構化信息在 LLM 應用中發揮著重要作用。
上次我們寫了關于多跳問答以及知識圖譜如何幫助解決從多個文檔中檢索信息以生成準確答案的問題。此外,我們暗示向量相似性搜索不是為分析工作流設計的,因為我們依賴結構化信息。
例如,以下問題:
- 誰可以把我介紹給 Emil Eifrém(Neo4j 的首席執行官)?
- ALOX5 基因與克羅恩病有何關系?
- 當我們的某個微服務出現中斷時,它會對我們的產品產生什么影響?
- 航班延誤是如何在網絡中傳播的?
- 哪些用戶可以為社交媒體帖子的病毒式傳播做出貢獻?
所有這些問題都需要高度關聯的信息才能準確回答問題。例如,要了解誰可以把你介紹給埃米爾,你需要有關人際關系的信息。
另一方面,您需要映射微服務和產品之間的依賴關系,以評估特定微服務故障的規模和嚴重程度。
在這篇博文中,我們將介紹一些您可能希望在 LLM 應用程序中實現的實時圖形分析的常見用例。
尋找(最短)路徑
關系是原生圖形數據庫中的頭等公民。盡管知識圖譜允許您執行典型的聚合和過濾來回答諸如“本周我們獲得了多少客戶?”之類的問題,但我們將更多地關注以遍歷關系為主要組成部分的分析用例。一個這樣的例子是找到數據點之間的最短或所有可能路徑。例如,要回答這個問題:
誰可以把我介紹給 Emil Eifrem?
我們必須在圖中找到我和埃米爾·艾弗萊姆之間的最短路徑。
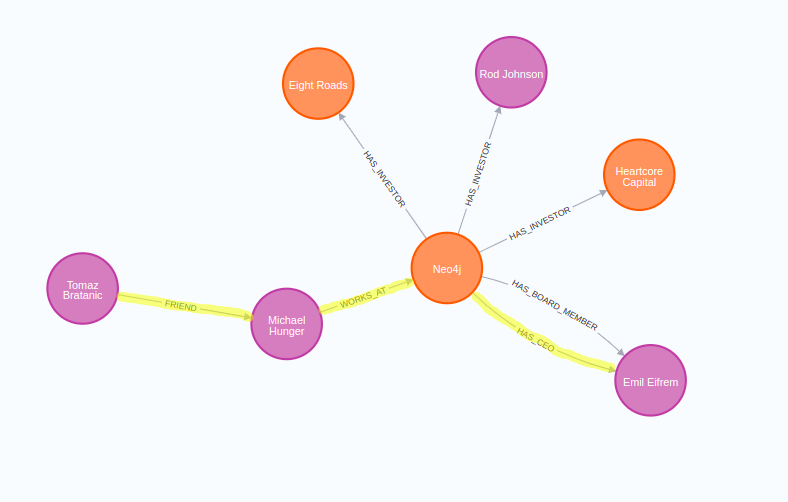
實時查找最短路徑的另一個有用用例是任何類型的運輸、物流或路線規劃應用程序。在這些應用程序中,您可能需要評估前 N 條最短路徑,以確保在發生意外情況時有某種后備計劃。
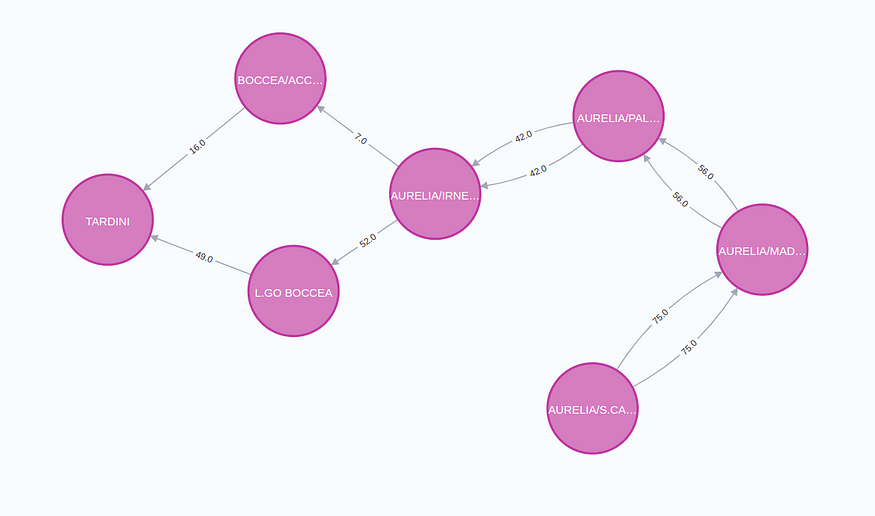
此圖顯示了羅馬兩站之間的前 2 條最短路徑。這些最短路徑可針對距離、時間、成本或組合進行優化。
另一個在 LLM 申請中尋找數據點之間路徑的領域是生物醫學領域。在生物醫學領域,你要處理基因、蛋白質、疾病、藥物等。也許更重要的是,這些實體并不是孤立存在的,而是相互之間存在復雜的、通常是多層的關系。
例如,一個基因可能與多種疾病有關,一種蛋白質可能與許多其他蛋白質相互作用,一種疾病可能可以通過多種藥物治療,一種藥物可能對不同的基因和蛋白質產生多種影響。
鑒于可用的生物醫學數據量驚人,這些數據點之間的潛在關系數量是巨大的,非常適合以知識圖譜的形式來表示。

生物醫學知識圖譜可以支持 LLM 應用程序,其中用戶有興趣回答以下問題
ALOX5 基因與克羅恩病有何關系?
雖然我們今天看到的大多數 LLM 應用程序都以自然語言生成答案,但也有一個絕佳的機會以線、條甚至網絡可視化的形式返回響應。通常 LLM 甚至可以返回圖表庫所需的配置結構。
網絡傳播信息
另一個強大的知識圖譜匹配是具有依賴關系網絡的域。例如,您可以擁有一個包含系統完整微服務架構的知識圖譜。這樣的知識圖譜將允許您為 DevOps 聊天機器人提供支持,使您能夠實時評估架構并執行假設分析。
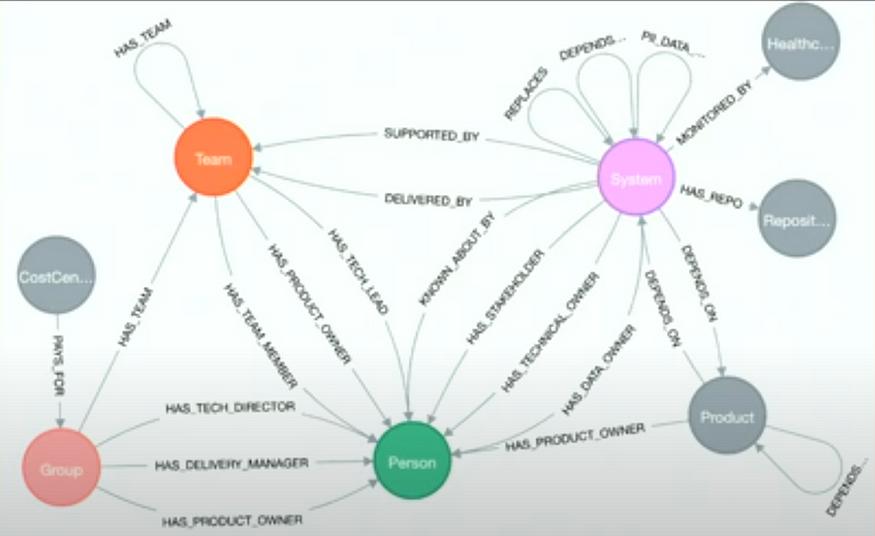
?
我想到的另一個領域是供應鏈。

將供應鏈數據納入知識圖譜可以顯著增強大型語言應用程序的功能。這種方法使我們能夠將復雜的供應鏈信息結構化為節點和關系,從而生成材料、組件和產品如何從供應商流向客戶的整體圖景。內在的互連和依賴關系變得顯而易見且易于分析。
對于語言應用程序,這可以實現更深入的上下文理解和知識生成。例如,像 ChatGPT 這樣的人工智能模型可以利用這種數據結構來對供應鏈場景、中斷或管理策略做出更準確、更有見地的響應。它可以理解和解釋某個組件短缺的連鎖反應,預測潛在的瓶頸,或提出優化策略。
通過將供應鏈動態的復雜性與人工智能的認知能力相結合,我們可以增強眾多工業和商業環境中大型語言應用的功能和價值。
社會網絡分析與數據科學
如果您的公司聊天機器人超越了文檔范圍,并作為人員分析的一部分幫助提供見解和建議,那會怎樣?
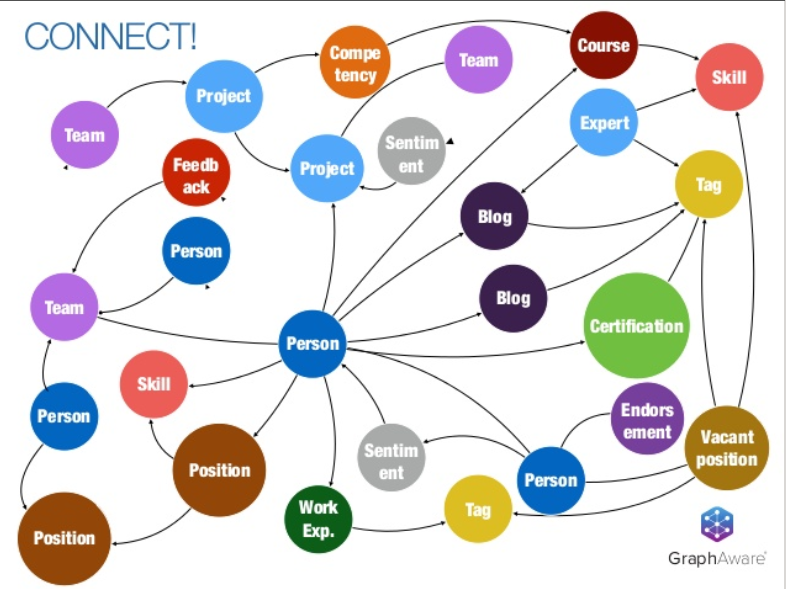
HCM 中的知識圖譜可以成為推動公司內部人員分析的寶貴工具,主要通過創建一個強大、互聯的信息系統,可以深入、全面地了解員工的行為、技能、能力、互動和績效。本質上,知識圖譜捕獲并鏈接復雜的員工數據(包括人口統計信息、角色歷史、項目參與度、績效指標和技能組合),從而進行多方面的分析。
這種互聯數據和機器學習工具的結合使人力資源和團隊領導者能夠發現隱藏的模式、識別高潛力人才、預測未來表現、評估技能差距并告知培訓需求,從而推動數據驅動的決策。通過利用知識圖譜,公司可以簡化人才管理和發展流程,提高整體組織效率并培養持續學習和改進的文化。
將聊天機器人界面整合到這個知識圖譜驅動的人員分析系統中,可能會徹底改變公司處理人力資源和人才管理的方式。具體方法如下:
方便用戶訪問復雜數據
聊天機器人界面為用戶提供了一種直觀的對話方式來與復雜的數據集進行交互。員工、經理或人力資源人員無需了解復雜的數據庫或分析工具;他們只??需向聊天機器人詢問有關員工績效、技能或團隊動態的問題即可。
該聊天機器人具有自然語言處理能力,可以解釋問題,從知識圖譜中檢索相關信息,并以可理解的格式提供答復。
實時洞察
聊天機器人界面可以提供即時訪問數據洞察的功能,從而實現及時決策。
如果經理想知道有多少個項目正在進行中,以及哪些人適合且可以參與特定項目,他們可以詢問聊天機器人并實時獲得答案,而不必等待全面的報告。
可擴展的培訓和支持
聊天機器人可以為員工提供個性化支持,回答有關公司政策、程序或職業發展機會的問題。
它甚至可以根據個人的角色、技能和職業目標提供個性化的培訓建議(甚至實際培訓本身)。這將使學習和發展資源的獲取更加民主化,使員工更容易提高技能或重新學習技能。
預測分析
先進的人工智能聊天機器人可以分析知識圖譜中的模式和趨勢,從而做出預測,例如哪些員工可能面臨離職風險,或者未來哪些技能可能會受到追捧。這些預測分析功能可以幫助公司在人力資源戰略方面采取主動而不是被動的態度。
從本質上講,將聊天機器人界面與知識圖譜驅動的人員分析系統相結合,將使復雜的員工數據更易于訪問、可操作且對組織的所有成員都更有用。這將徹底改變人才管理和發展,推動人力資源采用更加數據化、主動性和個性化的方法。
總結
總之,隨著我們深入大型語言模型時代,我們必須牢記知識圖譜在這些應用程序中構建、組織和檢索信息的巨大潛力。結構化和非結構化數據檢索的結合為更準確、更可靠、更有影響力的結果鋪平了道路,超越了自然語言答案,延伸到視覺呈現信息的領域。
盡管基于向量相似性的數據檢索(召回率)非常流行,但我們不應低估結構化信息的作用及其為 LLM 應用帶來的巨大價值。無論是尋找最短路徑、理解復雜的生物醫學關系、分析供應鏈場景,還是通過人員分析徹底改變人力資源,知識圖譜的應用都是廣泛而深遠的。我們相信基于 LLM 的應用的未來是向量相似性搜索方法與 Cypher 等數據庫查詢語言的結合。
通過這篇博文,我們探索了一些令人興奮的實時圖形分析用例,這些用例可以實現到您的 LLM 應用程序中。這只是一個開始。我們預計未來大型語言模型將與知識圖譜更加緊密地協同工作,為現實世界的問題帶來更多創新的解決方案。
項目開源地址
NaLLM項目開源地址:GitHub - neo4j/NaLLM: Repository for the NaLLM project


















)
