- 🍨 本文為🔗365天深度學習訓練營中的學習記錄博客
- 🍖 原作者:K同學啊
一、Transformer和Seq2Seq
在之前的博客中我們學習了Seq2Seq(深度學習系列 | Seq2Seq端到端翻譯模型),知曉了Attention為RNN帶來的優點。那么有沒有一種神經網絡結構直接基于attention構造,并且不再依賴RNN、LSTM或者CNN網絡結構了呢?答案便是:Transformer。Seq2Seq和Transformer都是用于處理序列數據的深度學習模型,但它們是兩種不同的架構。
- Seq2Seq:
- 定義: Seq2Seq是一種用于序列到序列任務的模型架構,最初用于機器翻譯。這意味著它可以處理輸入序列,并生成相應的輸出序列。
- 結構: Seq2Seq模型通常由兩個主要部分組成:編碼器和解碼器。編碼器負責將輸入序列編碼為固定大小的向量,而解碼器則使用此向量生成輸出序列。
- 問題: 傳統的Seq2Seq模型在處理長序列時可能會遇到梯度消失/爆炸等問題,而Transformer模型的提出正是為了解決這些問題。
- Transformer:
- 定義: Transformer是一種更現代的深度學習模型,專為處理序列數據而設計,最初用于自然語言處理任務。它不依賴于RNN或CNN等傳統結構,而是引入了注意力機制。
- 結構: Transformer模型主要由編碼器和解碼器組成,它們由自注意力層和全連接前饋網絡組成。它使用注意力機制來捕捉輸入序列中不同位置之間的依賴關系,同時通過多頭注意力來提高模型的表達能力。
- 優勢: Transformer的設計使其能夠更好地處理長距離依賴關系,同時具有更好的并行性。
在某種程度上,可以將Transformer看作是Seq2Seq的一種演變,Transformer可以執行Seq2Seq任務,并且相對于傳統的Seq2Seq模型具有更好的性能和可擴展性.
關于Transformer的歷史這里不贅述了, 本文重點從技術層面解析Transformer
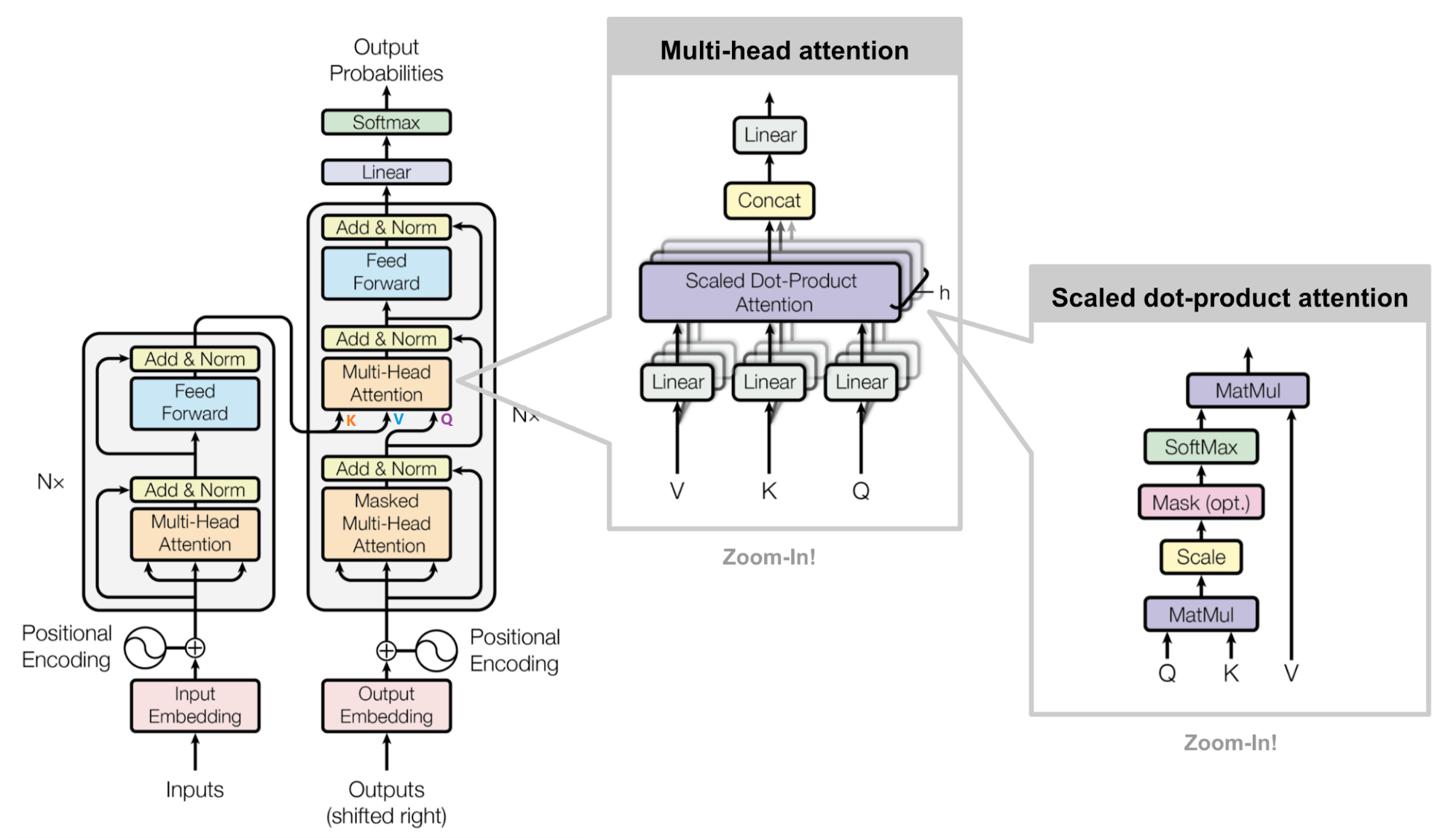
二、Transformer的宏觀結構
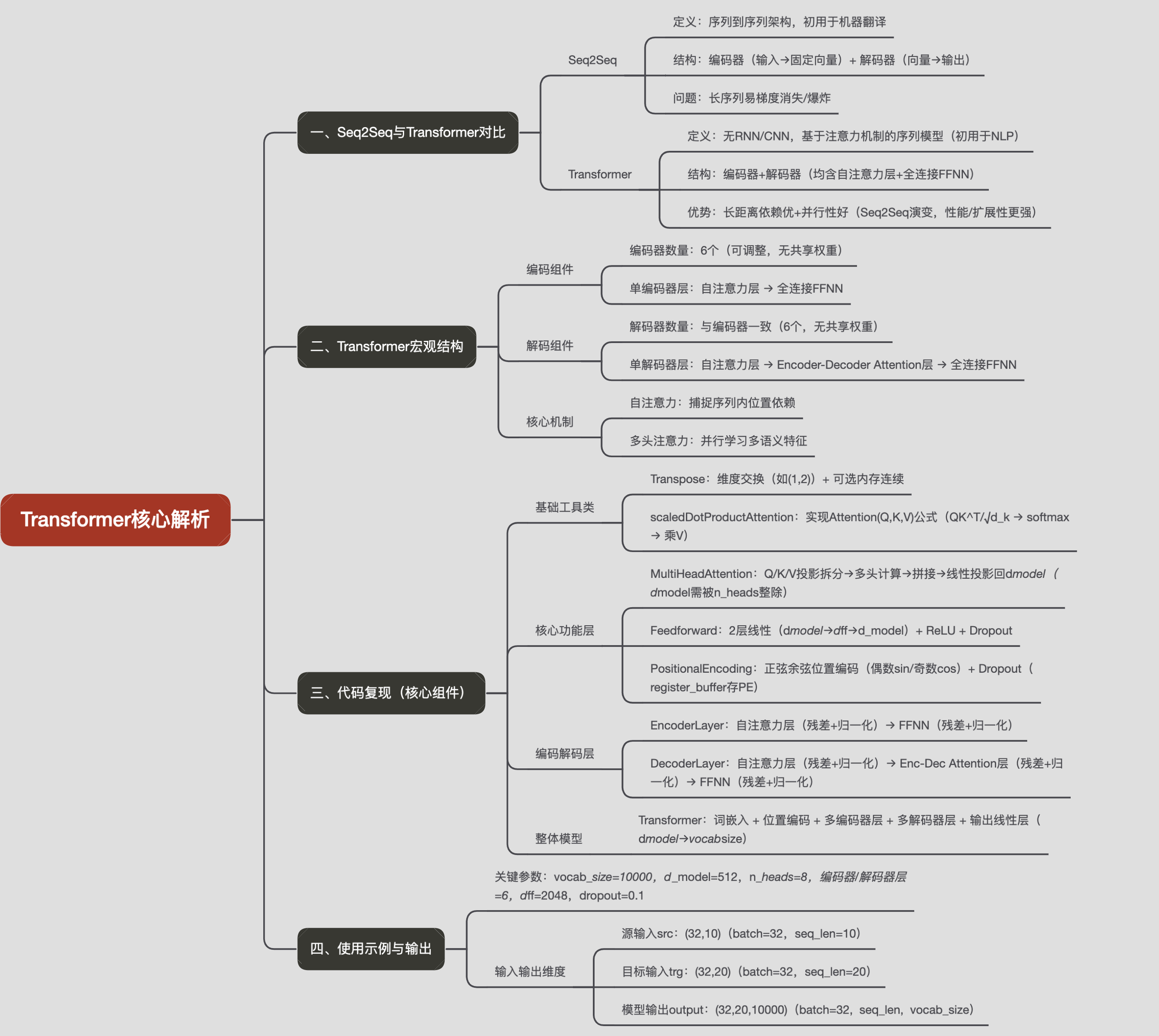
我們先把模型看作一個黑盒子。在機器翻譯應用中,它會接受一種語言的句子,然后輸出另一種語言的翻譯。

打開“The Transformer”,我們可以看到一個編碼組件、一個解碼組件以及它們之間的連接。
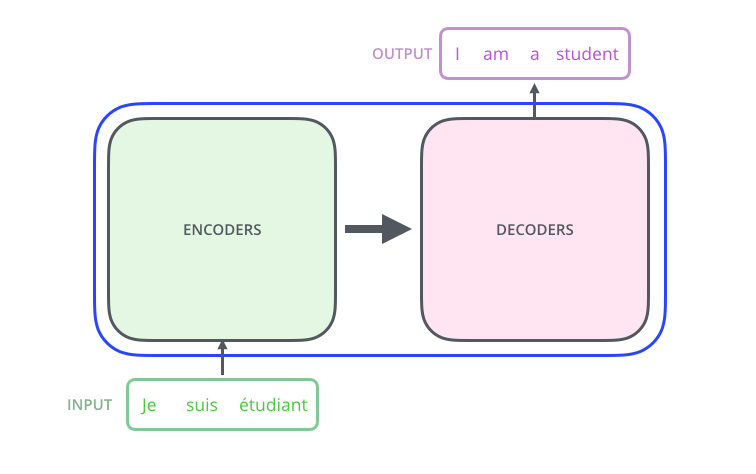
編碼組件是一堆編碼器(論文中將6個編碼器堆疊在一起——“6”這個數字并沒有什么神奇之處,當然可以嘗試其他排列方式)。解碼組件是一堆相同數量的解碼器。
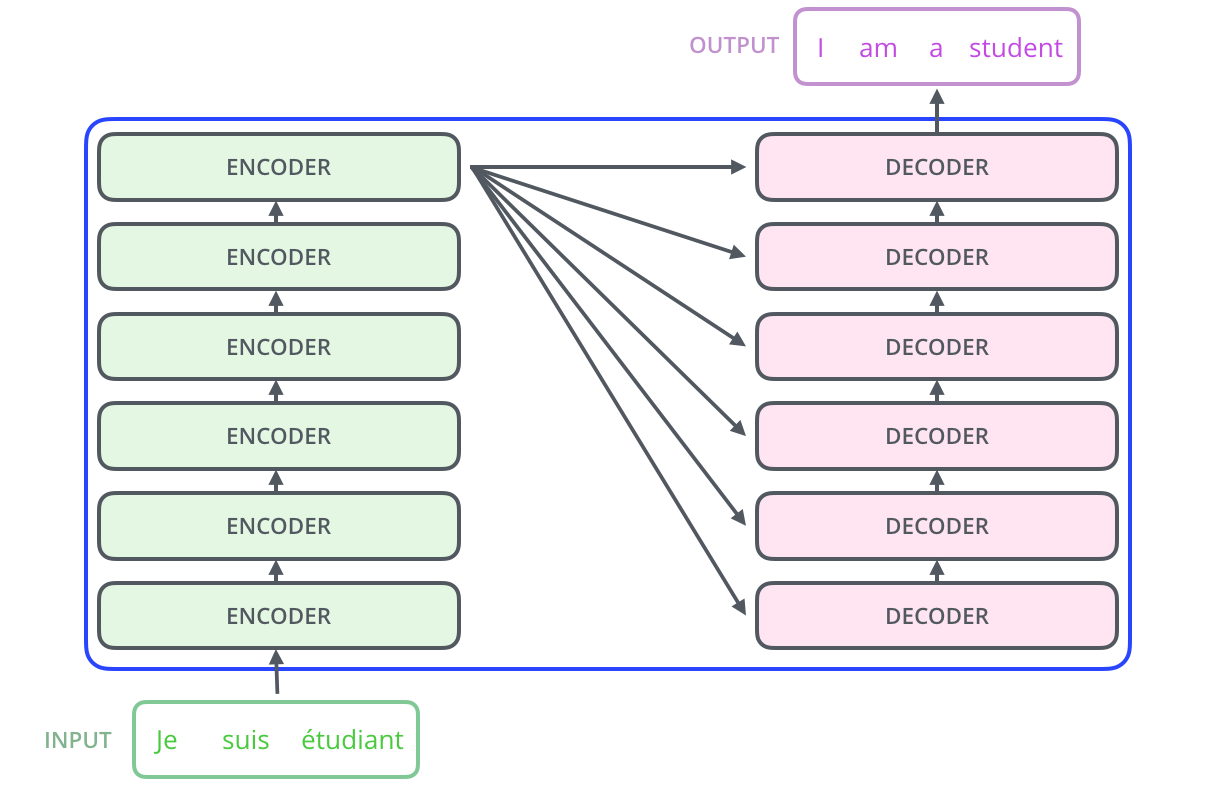
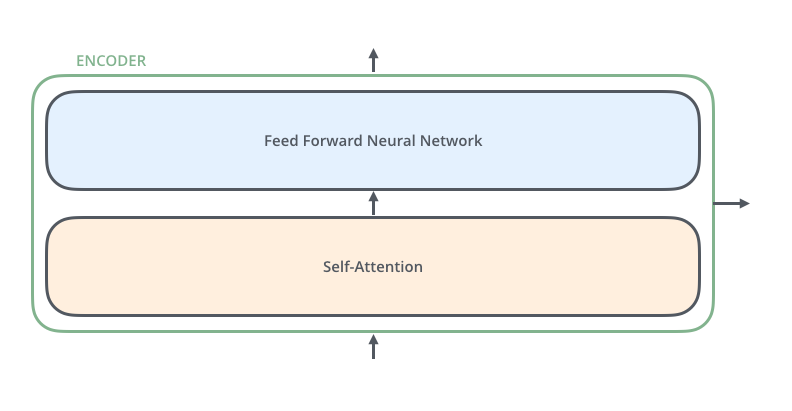
所有編碼器的結構完全相同(但它們不共享權重)。每個編碼器又分為兩個子層 ,主要由自注意力層(Self-Attention Layer)和全連接前饋網絡(Feed Forward Neural Network, FFNN)與組成,如下圖所示:
其中,解碼器在編碼器的自注意力層和全連接前饋網絡中間插入了一個Encoder-Decoder Attention層,這個層幫助解碼器聚焦于輸入序列最相關的部分。
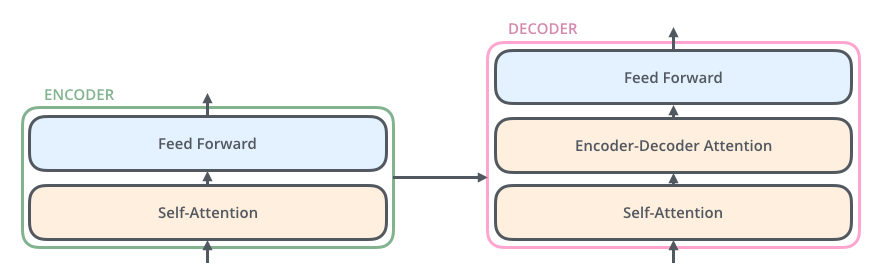
最后總結一下,我們基本了解了Transformer由編碼部分和解碼部分組成,而編碼部分和解碼部分又由多個網絡結構相同的編碼層和解碼層組成。每個編碼層由自注意力層和全連接前饋網絡組成,每個解碼層由自注意力層、全連接前饋網絡和encoder-decoder attention組成。
三、代碼復現
1、導入包
import math
import torch
import torch.nn as nn#設置GPU訓練
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
devicedevice(type='mps')2、shape變化類
將張量的指定維度進行交換,并可選擇讓轉置后的張量在內存中保持 “連續” 狀態(contiguous)。它本質是對 PyTorch 原生的 transpose 和 contiguous 方法的封裝,方便在神經網絡的層結構中復用
- transpose作用: 交換張量的兩個維度,(batch_size, seq_len, hidden_dim) 經過transpose(1,2)后會將其轉換為(batch_size, hidden_dim, seq_len)
- contiguous作用: 通過復制數據確保張量在內存中是“連續存儲的”,后續view,reshape操作需要
class Transpose(nn.Module):def __init__(self, *dims, contiguous=False):super(Transpose, self).__init__()self.dims = dims #要交換的維度(如 (1, 2) 表示交換第1和第2維)self.contiguous = contiguous # 是否在轉置后強制內存連續def forward(self, x):if self.contiguous:return x.transpose(*self.dims).contiguous()else:return x.transpose(*self.dims)3、Scaled dot-product Attention
Self-Attention機制的一個具體實現 , QKV實現點積, 兩個向量若他們的點積越大, 可以表示向量間靠的更接近, 在語義空間中 也可表示兩個詞更相似, 更有關系
- torch.softmax(..., dim=-1)
- dim=-1表示在張量的最后一個維度上應用 Softmax 函數(這里最后一個維度是 “被關注的位置” 維度,即context_length)
代碼實現功能:
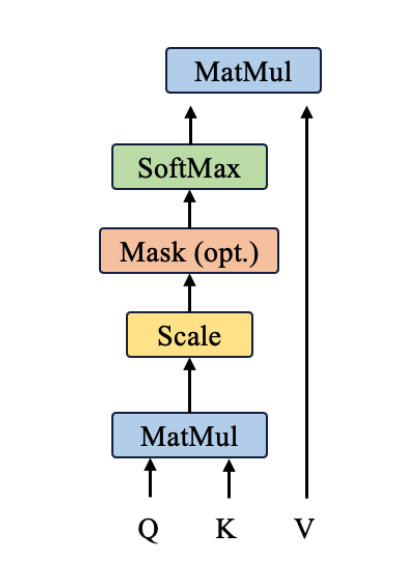
import torch.nn.functional as Fclass scaledDotProductAttention(nn.Module):def __init__(self, d_k):super(scaledDotProductAttention, self).__init__()self.d_k = d_k #表示縮放因子'''計算注意力機制的核心步驟1、先計算Q和K的點積,得到相似分數,k需要轉置2、scale: 縮放分數, 防止梯度消失3、應用掩碼,decode用,將掩碼設置成一個極小的值4、對分數進行softmax, 得到注意力權重概率5、根據注意力權重和v進行加權求和'''def forward(self, q, k, v, mask=None):scores = torch.matmul(q, k) # scores形狀: [batch_size, num_heads, d_k, seq_len]scores = scores/ self.d_k ** 0.5 # scale#掩碼應用if mask is not None:scores.masked_fill(mask, -1e9)attn = F.softmax(scores, dim=-1)#和v進行加權求和context = torch.matmul(attn, v)return context4、多頭注意力機制
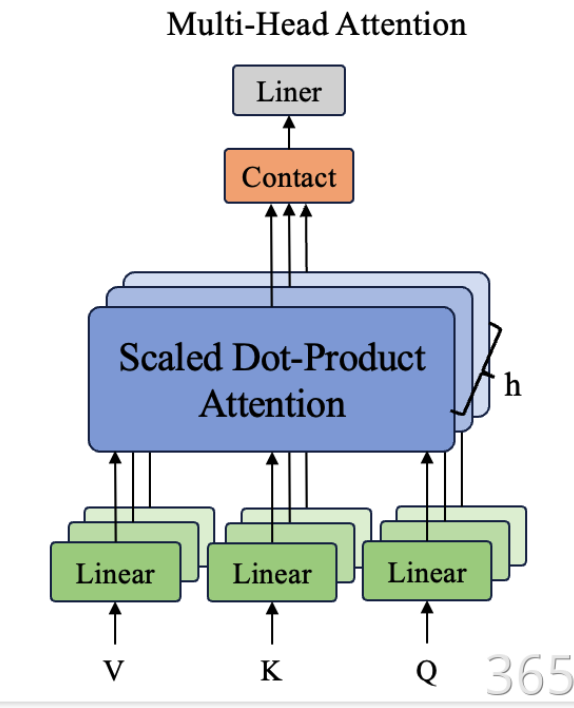
多頭注意力,可以直接理解為我們有多個腦袋去注意不同的事情,從全局角度來看,更為全面。那么怎么做到呢?
通過將Q/K/V投影到不同的子空間(subspace),使模型能夠并行學習多種語義特征。具體實現分為四個步驟:

class MultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads):'''多頭注意力機制的初始化函數d_model:輸入的特征維度n_heads:注意力頭的數量d_k:每個頭的縮放因子 鍵/查詢向量的維度 d_model // n_headsd_v:每個頭中值向量維度'''super(MultiHeadAttention, self).__init__()#確保d_model可以被n_heads整除assert d_model % n_heads ==0, f"d_model:{d_model}不能被 n_heads:{n_heads}整除"self.d_k = d_model//n_headsself.d_v = d_model//n_headsself.n_heads = n_heads#定義Q、K、V的線性層, 本質上都是 nn.Linear(d_model, d_model, bias= False)self.W_Q = nn.Linear(d_model, self.d_k * n_heads, bias= False)self.W_K = nn.Linear(d_model, self.d_k * n_heads, bias= False)self.W_V = nn.Linear(d_model, self.d_v * n_heads, bias= False)#用于將多頭輸出的拼接結果投影回輸入特征維度的線性層self.W_O = nn.Linear(n_heads* self.d_v, d_model, bias= False)'''前向傳播函數:計算多頭注意力'''def forward(self, Q, K, V, mask=None):batch_size = Q.size(0) #獲取批量的大小#1、將輸入向量進行頭拆分,并進行維度變換q_s= self.W_Q(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)k_s= self.W_K(K).view(batch_size, -1, self.n_heads, self.d_k).permute(0, 2, 3, 1)v_s= self.W_V(V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1, 2)#2、計算縮放點積注意力context = scaledDotProductAttention(self.d_k)(q_s, k_s, v_s)#3、將多頭的輸出拼接起來,拼接后的形狀 [batch_size, q_len, n_heads* d_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v)#4、通過線性層映射回輸入特征維度out_put = self.W_O(context) #output形狀:[batch_size, q_len, d_model]return out_put5、前饋傳播
class Feedforward(nn.Module):def __init__(self, d_model, d_ff, dropout= 0.1):super(Feedforward, self).__init__()#兩層線性變換self.linear1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):x = F.relu(self.linear1(x))x = self.dropout(x)x = self.linear2(x)return x6、位置編碼
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout, max_len = 5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p= dropout)#初始化shape為(max_len, d_model)的PEpe = torch.zeros(max_len, d_model)#初始化一個tensorposition = torch.arange(0, max_len).unsqueeze(1)#這里是sin和cos括號里的內容div_term = torch.exp(torch.arange(0 ,d_model, 2)* -math.log(10000)/d_model)pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0) #在最外層加一個batch_sizeself.register_buffer("pe", pe)def forward(self, x):x= x + self.pe[: , :x.size(1)].requires_grad_(False)return self.dropout(x)7、編碼層
class EncoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(EncoderLayer, self).__init__()#編碼器層包含自注意力機制和前饋神經網絡self.self_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):#自注意力機制,初始值Q、K、V一致attn_output = self.self_attn(x, x, x, mask)x= x+self.dropout(attn_output)x= self.norm1(x)#前饋神經網絡ff_output= self.feedforward(x)x = x+ self.dropout(ff_output)x = self.norm2(x)return x8、解碼層
class DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super(DecoderLayer, self).__init__()#解碼器層包含自注意力機制、編碼器-解碼器注意力機制和前饋神經網絡self.self_attn = MultiHeadAttention(d_model, n_heads)self.enc_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, self_mask, context_mask):#自注意力機制attn_output = self.self_attn(x, x, x, self_mask)x = x + self.dropout(attn_output)x = self.norm1(x)#編碼器-解碼器注意力機制attn_output = self.enc_attn(x, enc_output, enc_output, context_mask)x = x +self.dropout(attn_output)x = self.norm2(x)#前饋神經網絡ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x9、Transformer模型構建
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout):super(Transformer, self).__init__()#Transformer 包含詞嵌入,位置編碼,編碼器和解碼器self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model, dropout)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)#編碼器for layer in self.encoder_layers:src = layer(src, src_mask)#解碼器for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)#輸出層output = self.fc_out(trg)return output10、輸出模型結構
#使用示例
vocab_size = 10000 #假設詞匯表大小為10000
d_model = 512
n_heads = 8
n_encoder_layers = 6
n_dncoder_layers = 6
d_ff = 2048
dropout=0.1transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_dncoder_layers, d_ff, dropout)#定義輸入
src = torch.randint(0, vocab_size, (32, 10))#源語言句子
trg = torch.randint(0, vocab_size, (32, 20))#目標語言句子
src_mask = (src!=0).unsqueeze(1).unsqueeze(2)
trg_mask = (trg!=0).unsqueeze(1).unsqueeze(2)print("實際|輸入數據維度:", src.shape)
print("實際|輸出數據維度:", trg.shape)output = transformer_model(src, trg, src_mask, trg_mask)print("實際|輸出數據維度:", output.shape)
實際|輸入數據維度: torch.Size([32, 10])
實際|輸出數據維度: torch.Size([32, 20])
實際|輸出數據維度: torch.Size([32, 20, 10000])參考文章
https://jalammar.github.io/illustrated-transformer/








)

)




-- 配置與部署)



