節前,我們星球組織了一場算法崗技術&面試討論會,邀請了一些互聯網大廠朋友、參加社招和校招面試的同學。
針對算法崗技術趨勢、大模型落地項目經驗分享、新手如何入門算法崗、該如何準備、面試常考點分享等熱門話題進行了深入的討論。
合集:
《大模型面試寶典》(2024版) 正式發布!

在不斷發展的深度學習領域,數據的數量和質量問題一直是一個長期存在的難題。最近大語言模型(LLMs)的出現為合成數據生成提供了一種以數據為中心的解決方案,緩解了現實世界數據的限制。然而,目前對這一領域的研究缺乏統一的框架,大多停留在表面。
因此,本文基于合成數據生成的一般工作流程,整理了相關研究。通過這樣做,我們突出了現有研究中的空白,并概述了未來研究的潛在方向。本研究旨在引導學術界和工業界向更深入、更系統地探究LLMs驅動的合成數據生成的能力和應用。
在深度學習領域不斷演變的背景下,數據數量和質量的問題一直是一個長期存在的困境。大語言模型(LLMs)的革命性出現引發了深度學習領域的顯著范式轉變(Zhang et al., 2023a; Guo et al., 2023; Bang et al., 2023)。盡管有這些進展,大量高質量數據仍然是構建穩健自然語言處理(NLP)模型的基礎(Gandhi et al., 2024)。具體來說,這里的高質量數據通常指的是包含豐富監督信號(通常以標簽形式)并與人類意圖緊密對齊的多樣化數據。然而,由于高成本、數據稀缺、隱私問題等原因,依賴于人類數據來滿足這些需求有時是具有挑戰性甚至是不現實的(Kurakin et al., 2023)。此外,多項研究(Hosking et al., 2023; Singh et al., 2023; Gilardi et al., 2023)表明,人類生成的數據由于其固有的偏見和錯誤,可能并不是模型訓練或評估的最佳選擇。這些考慮促使我們更深入地探討一個問題:是否有其他更有效和可擴展的數據收集方法可以克服當前的限制?
鑒于LLMs的最新進展,它們展示了生成與人類輸出相當的流暢文本的能力(Hartvigsen et al., 2022; Sahu et al., 2022; Ye et al., 2022a; Tang et al., 2023; Gao et al., 2023a),由LLMs生成的合成數據成為了人類生成數據的一種可行替代品或補充。具體來說,合成數據旨在模仿真實世界數據的特征和模式(Liu et al., 2024)。一方面,LLMs通過廣泛的預訓練,積累了豐富的知識庫,并展現出卓越的語言理解能力(Kim et al., 2022; Ding et al., 2023a),這為生成真實的數據奠定了基礎。另一方面,LLMs深厚的指令遵循能力允許在生成過程中實現更好的可控性和適應性,從而能夠為特定應用創建定制的數據集,并設計更靈活的流程(Eldan and Li, 2023)。這兩個優勢使LLMs成為極具前景的合成數據生成器。
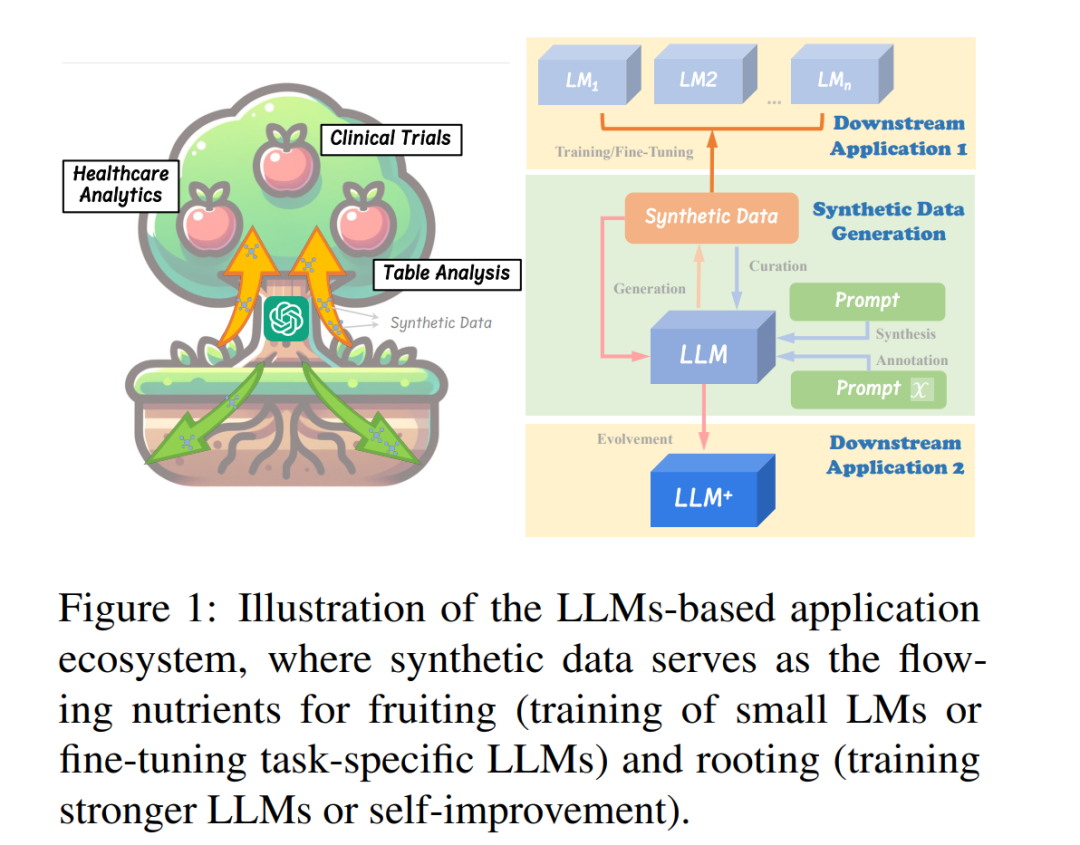
作為LLMs的一項關鍵應用,合成數據生成對于深度學習的發展具有重要意義。如圖1所示,LLMs驅動的合成數據生成(Li et al., 2023c; Wang et al., 2021; Seedat et al., 2023)使整個模型訓練和評估過程實現自動化,最小化了人類參與的需求(Huang et al., 2023),從而使深度學習模型的優勢可以應用于更廣泛的領域。除了提供可擴展的訓練和測試數據供應之外,LLMs驅動的合成數據生成還可能為開發下一代LLMs鋪平道路。來自TinyStories(Eldan and Li, 2023)和Phi系列(Gunasekar et al., 2023; Li et al., 2023b)的見解強調了數據質量對于有效模型學習的重要性,而LLMs賦予我們主動“設計”模型學習內容的能力,通過數據操作顯著提高了模型訓練的效率和可控性。截至2024年6月,Hugging Face上已有超過300個被標記為“合成”的數據集,許多主流LLMs利用高質量的合成數據進行訓練,包括Alpaca(Taori et al., 2023)、Vicuna(Zheng et al., 2023)、OpenHermes 2.5和Openchat 3.5(Wang et al., 2023a)。
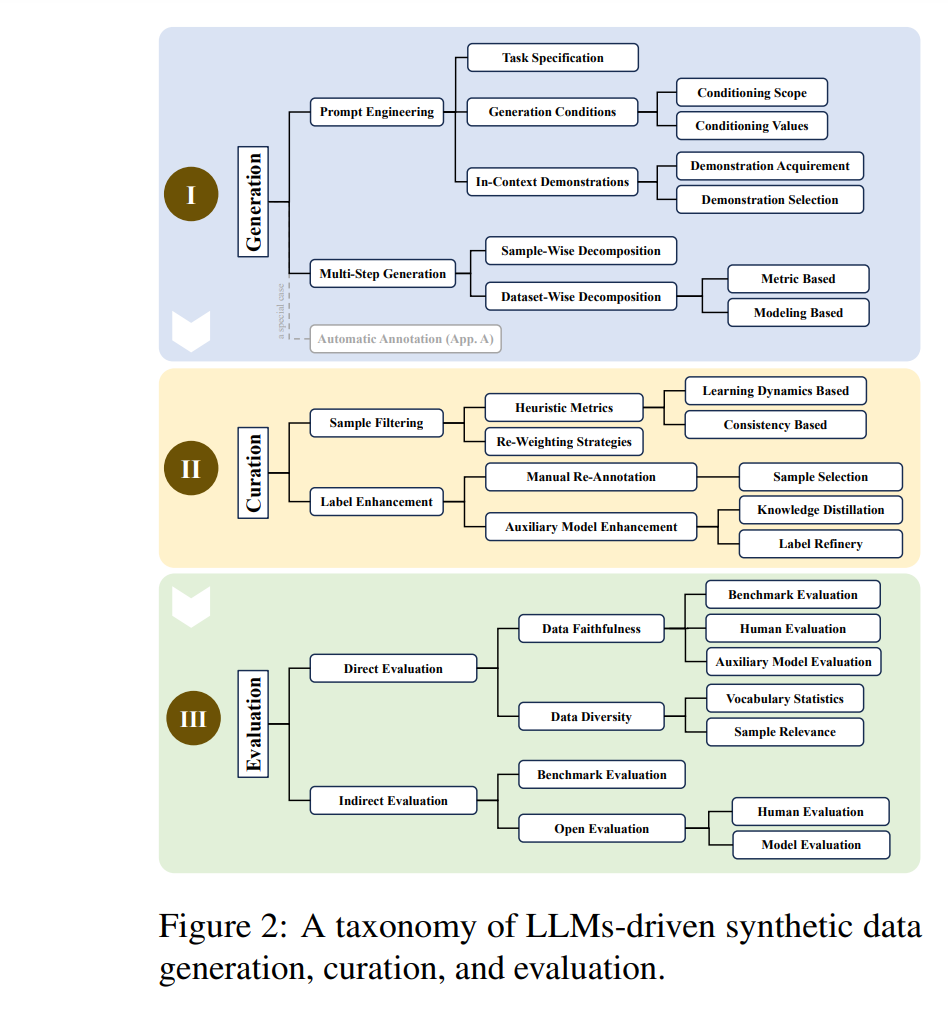
盡管看似簡單,但生成同時具有高正確性和足夠多樣性的合成數據集需要精心設計過程,并涉及許多技巧(Gandhi et al., 2024),使得LLMs驅動的合成數據生成成為一個非平凡的問題。雖然大多數現有工作通常針對各種任務(如預訓練(Gunasekar et al., 2023; Li et al., 2023b; Eldan and Li, 2023)、微調(Mukherjee et al., 2023; Mitra et al., 2023; Xu et al., 2023a)、評估(Feng et al., 2023; Wei et al., 2024))和不同領域(如數學(Yu et al., 2023a; Luo et al., 2023a)、代碼(Luo et al., 2023b; Wei et al., 2023b)、指令(Honovich et al., 2023a; Wang et al., 2023d))進行數據生成,但它們共享許多共同的理念。為了應對LLMs驅動的合成數據生成這一新興領域中缺乏統一框架的問題,并開發通用工作流程,本綜述調查了最近的研究,并根據生成、策展和評估三個密切相關的主題進行組織,如圖2所示。我們的主要目的是提供該領域的全面概述,確定關鍵關注領域,并突出需要解決的空白。我們希望為學術界和工業界帶來見解,并推動LLMs驅動的合成數據生成的進一步發展。




:縮放點積注意力機制)














