??每周跟蹤AI熱點新聞動向和震撼發展 想要探索生成式人工智能的前沿進展嗎?訂閱我們的簡報,深入解析最新的技術突破、實際應用案例和未來的趨勢。與全球數同行一同,從行業內部的深度分析和實用指南中受益。不要錯過這個機會,成為AI領域的領跑者。點擊訂閱,與未來同行! 訂閱:https://rengongzhineng.io/

語音識別中的可理解性評估:超越詞錯誤率的意義保留
在自動語音識別(ASR)模型的評估中,詞錯誤率(WER)及其逆值詞準確率(WACC)是衡量句法準確性的常用指標。然而,這些指標未能反映ASR性能的一個關鍵方面:可理解性。這種局限性在針對具有非典型言語模式的用戶時尤為明顯,他們的WER往往超過20%,在某些情況下甚至超過60%。盡管如此,如果ASR模型能較好地保留其言語的意義,這些用戶仍能從中受益。這在實時對話、語音輸入文本信息、家庭自動化等對語法錯誤容忍度較高的應用中尤為重要。實際上,這些用戶和應用場景最能從保留意義的ASR模型中獲益,因為它們能顯著改善交流。
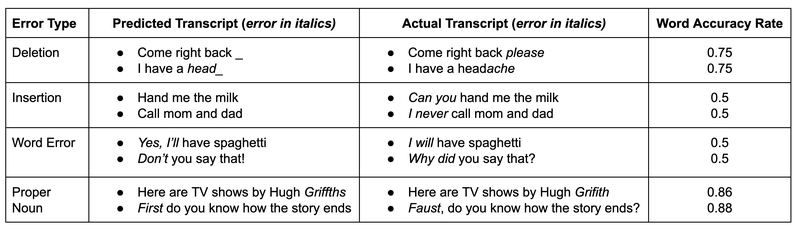
WER的局限性與意義保留的重要性
盡管WER和WACC可以衡量語音識別的句法準確性,但它們并不總能準確反映轉錄錯誤的嚴重性。以下是一些示例,展示了WACC如何未能準確反映轉錄錯誤的嚴重性。在兩個例子中,盡管WACC相似,第一個例子的錯誤相對無害,而第二個例子的錯誤則更為嚴重。
創建意義保留評估系統
為了解決這一問題,開發了一種新系統,以自動評估ASR模型有效傳達用戶意圖的能力。在論文《利用大型語言模型評估語音轉錄的可理解性》(ICASSP 2024)中,介紹了一種新方法,使用大型語言模型(LLM)來確定轉錄是否準確捕捉了與參考文本相比的預期意義。基于這一方法,還報告了使用Gemini模型如何在不顯著損失性能的情況下使用更小的模型,并在無需額外訓練的情況下實現多語言意義評估。
意義保留作為替代指標
研究利用了Project Euphonia語料庫,這是一個包含約2000名具有各種言語障礙的個體超過120萬條語句的語料庫。為了擴展對西班牙語使用者的數據收集,Project Euphonia與ALS/MND國際聯盟合作,收集了來自墨西哥、哥倫比亞和秘魯ALS患者的語音樣本。同樣,通過與巴黎腦科學研究所的Romain Gombert合作,Project Euphonia擴展到法國,收集了法國非典型言語者的數據。
在實驗中,生成了4731個包含真實值和轉錄錯誤對的示例數據集,并附有人類標注,指示這些對是否保留了意義。將數據集分為訓練集、測試集和驗證集(分別為80% / 10% / 10%),確保三個數據集在真實語句級別上沒有重疊。
訓練與評估
在基礎LLM上訓練了意義保留分類器。通過提示微調(一種參數高效的LLM適應方法),將基礎LLM調整為能夠預測“是”或“否”的標簽,以指示是否保留了意義。

在推理過程中,沒有生成響應,而是獲取LLM的logits作為兩個類別標簽(“是”和“否”)的分數。可以選擇得分較高的標簽,或在評估意義保留分類器時,使用“是”類別的得分。
使用Gemini進行意義保留評估
盡管在PaLM模型上取得的結果令人鼓舞,但最近AI模型的巨大進步激勵評估其在此任務中的適用性。重新訓練了意義保留分類器,現在使用Google的Gemini作為基礎LLM。對于許多相關的用例,這一評估任務最好使用小模型(例如用于設備上的應用)。因此,選擇了Google的Gemini小版本(Gemini Nano-1,具有1.8B參數,詳見Gemini 1.0技術報告)進行更高效的推理,其參數量不到最初使用的PaLM 62B模型的3%。在意義保留測試集上評估時,微調后的Gemini Nano-1表現非常競爭,AUC ROC得分為0.88,盡管其規模較小。
多語言意義保留評估
還創建了法語和西班牙語的意義保留測試集,作為Project Euphonia擴展數據收集工作的一部分。這些測試集基于收集的語句、說話者言語障礙的嚴重程度和病因學的元數據,以及從Google的高度多語言通用語音模型(USM)獲得的真實轉錄和ASR轉錄。
西班牙語測試集由來自六名說話者的518個示例組成,而法語測試集由來自十名說話者的199個示例組成。對于兩種語言,不同說話者具有不同的病因學和言語障礙程度,包括輕度、中度和重度。
基于Gemini Nano-1模型的意義保留分類器在法語和西班牙語測試集上獲得了約0.89的ROC AUC性能。鑒于該分類器僅用英文示例進行訓練,這一結果相當顯著。由于基礎Gemini模型的多語言能力,這些能力在無需重新訓練模型或創建新語言的訓練數據集的情況下得以顯現。
結論
提出使用意義保留作為比WER更有效的ASR系統評估指標,特別是在高錯誤率的情況下,如非典型言語和其他低資源領域或語言。通過關注意義保留,可以更好地評估模型對個體用戶的有用性,尤其是在Project Relate等助聽技術中,這些技術旨在通過訓練完全個性化的語音識別模型使非典型言語者得到更好的理解。
為了進一步推進意義保留工作,并將其惠及更多用戶和語言,還探索了Google Gemini模型的能力。Gemini Nano-1使能夠在使用顯著較小模型的情況下實現類似的分類器性能。盡管僅在英文示例上訓練,分類器顯示出在其他語言中準確評估意義保留的能力,如法語和西班牙語的測試所示。這一激動人心的發展為構建更高效、更通用的模型開辟了新的可能性,使更多用戶受益。
表達式(3)PAYLOAD EXPRESSIONS)



)
及同類型軟件介紹)










)


