文生圖
文生圖,全稱“文字生成圖像”(Text-to-Image),是一種AI技術,能夠根據給定的文本描述生成相應的圖像。這種技術利用深度學習模型,如生成對抗網絡(GANs)或變換器(Transformers),來理解和解析文本中的語義信息,并將其轉化為視覺表現。文生圖可以用于創意設計、圖像編輯、虛擬現實、游戲開發等多個領域,為用戶提供了從文字到圖像的創造性轉換工具。例如,用戶可以輸入“一只藍色的貓坐在月球上”,AI將嘗試生成符合描述的圖像。

Stable Diffusion
Stable Diffusion 是一種潛在的文本到圖像擴散模型。得益于 Stability AI 慷慨的計算資源捐贈以及 LAION 的支持,我們得以使用 LAION-5B 數據庫的一個子集中的 512x512 圖像來訓練一個潛在擴散模型。與 Google 的 Imagen 類似,此模型使用一個凍結的 CLIP ViT-L/14 文本編碼器來根據文本提示對模型進行條件設定。該模型擁有 8.6 億參數的 UNet 和 1.23 億參數的文本編碼器,相對輕量,只需要至少 10GB VRAM 的 GPU 即可運行。詳情請參閱以下部分和模型卡片。
簡而言之,Stable Diffusion 是一個由 Stability AI 和 LAION 支持的項目,使用 LAION-5B 數據庫中的圖像訓練而成。它借鑒了 Google Imagen 的設計理念,使用 CLIP ViT-L/14 文本編碼器處理文本提示,具有相對較小的模型大小,使得它在普通 GPU 上即可運行。
Stable Diffusion 3 Medium 是目前 Stable Diffusion 3 系列中最新、最先進的文本到圖像 AI 模型,包含 20 億個參數。它擅長照片級真實感,處理復雜的提示并生成清晰的文本。
stable-diffusion-3-medium模型開源地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium
硅基流動
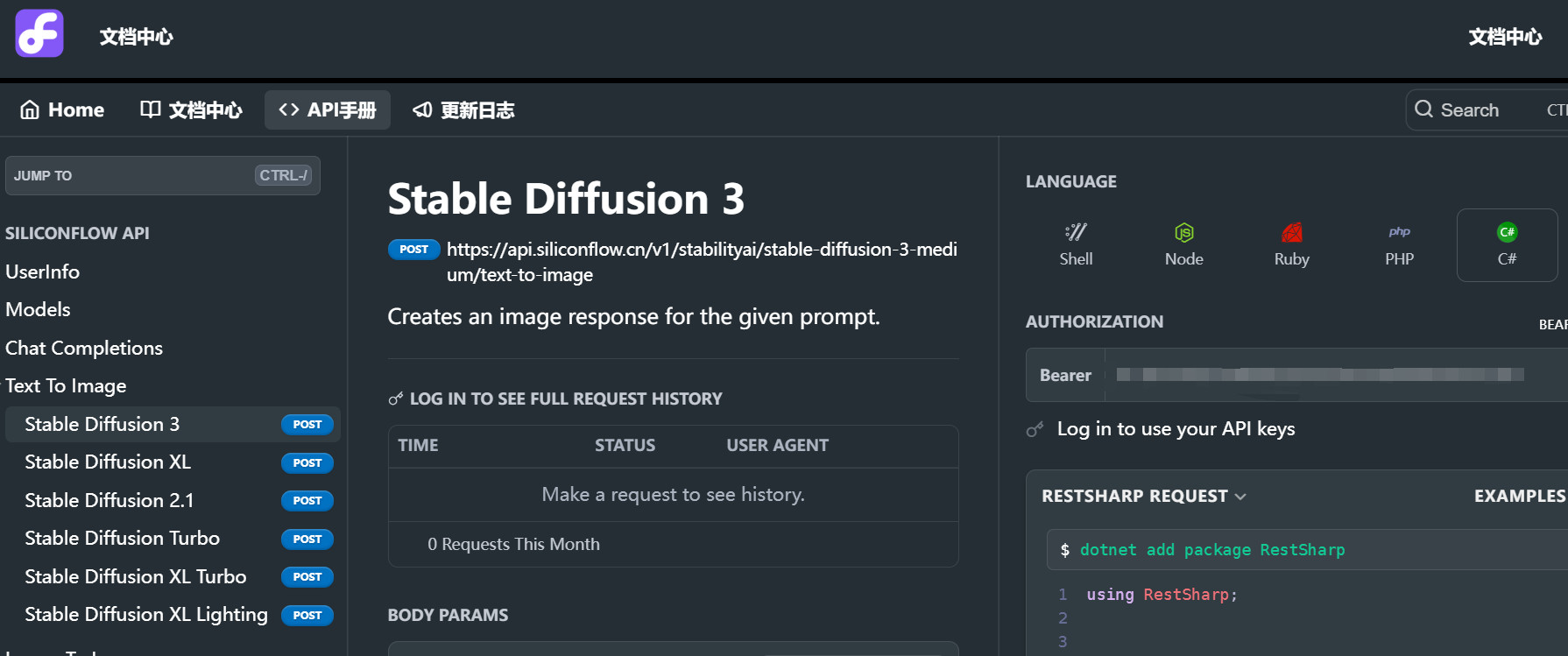
由于我目前硬件資源不行無法本地運行stable-diffusion-3-medium,但又想試試文生圖模型,因此現階段可以采用調用api的方式來使用。硅基流動平臺目前提供了stable-diffusion-3的調用接口,并且限時免費,因為選擇調用硅基流動提供的api。
Avalonia
基于Avalonia可以使用C#+Xaml構建跨平臺應用。
本項目或許不具備太大的實用價值,權且當做學習Avalonia的一個練手項目。
項目架構:
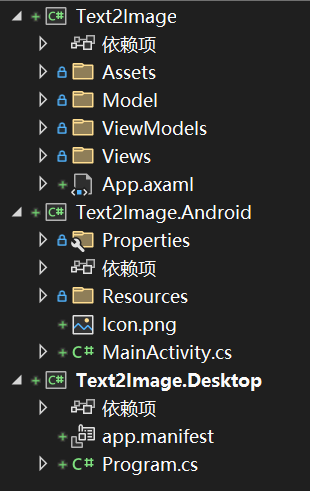
在使用Avalonia的模板創建項目之后,更改項目為.net8,并升級一下包,這樣可能會避免一些報錯。
由于發現不支持中文提示詞,因此還是使用SemanticKerenl基于LLM將中文提示詞翻譯為英文提示詞,然后根據英文提示詞繪圖。
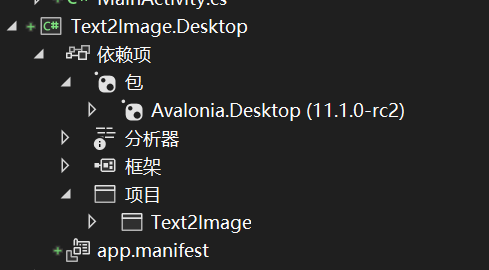
觀察一下桌面端的依賴項,桌面端引用了核心項目,使用的包是Avalonia.Desktop。
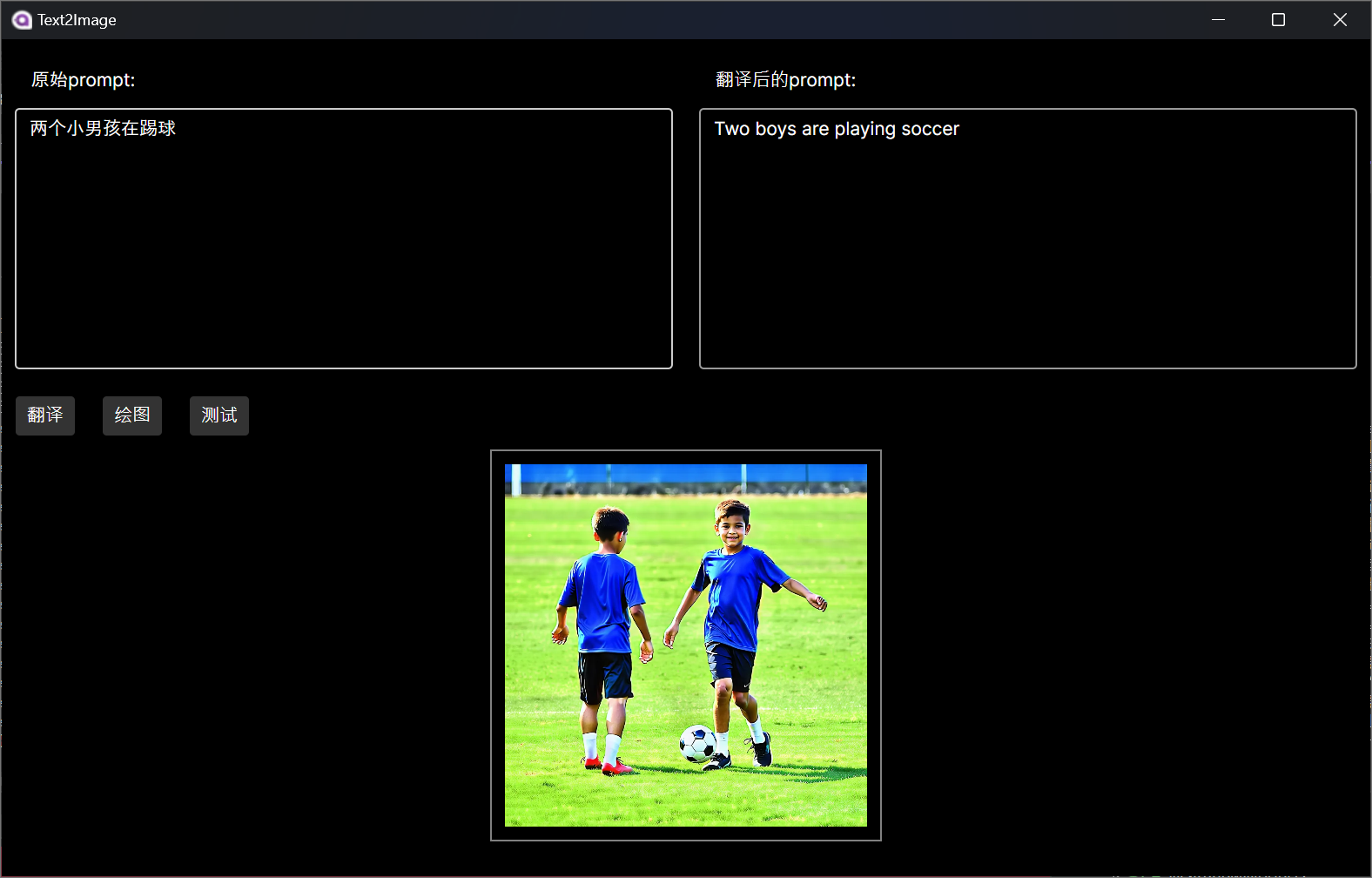
桌面端實現效果如下所示:
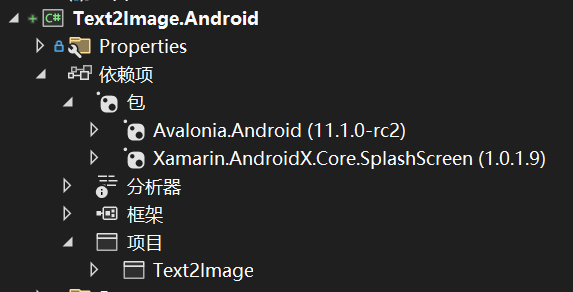
觀察一下Android端的依賴項,Android端也引用了核心項目,使用的包是Avalonnia.Android與Xamarin.AndroidX.Core.SplashScreen。
Android端調試可以選擇模擬器與物理機。

避坑
選擇物理機調試時要打開開發者模式,打開USB調試,最重要的是要允許通過USB安裝,我之前沒有設置這個,就會遇到一個被用戶取消的錯誤提示。
Android端不知道為什么SenmanticKernel對提示模板不起作用如下所示:

現在只能自己寫英文提示詞繪圖。
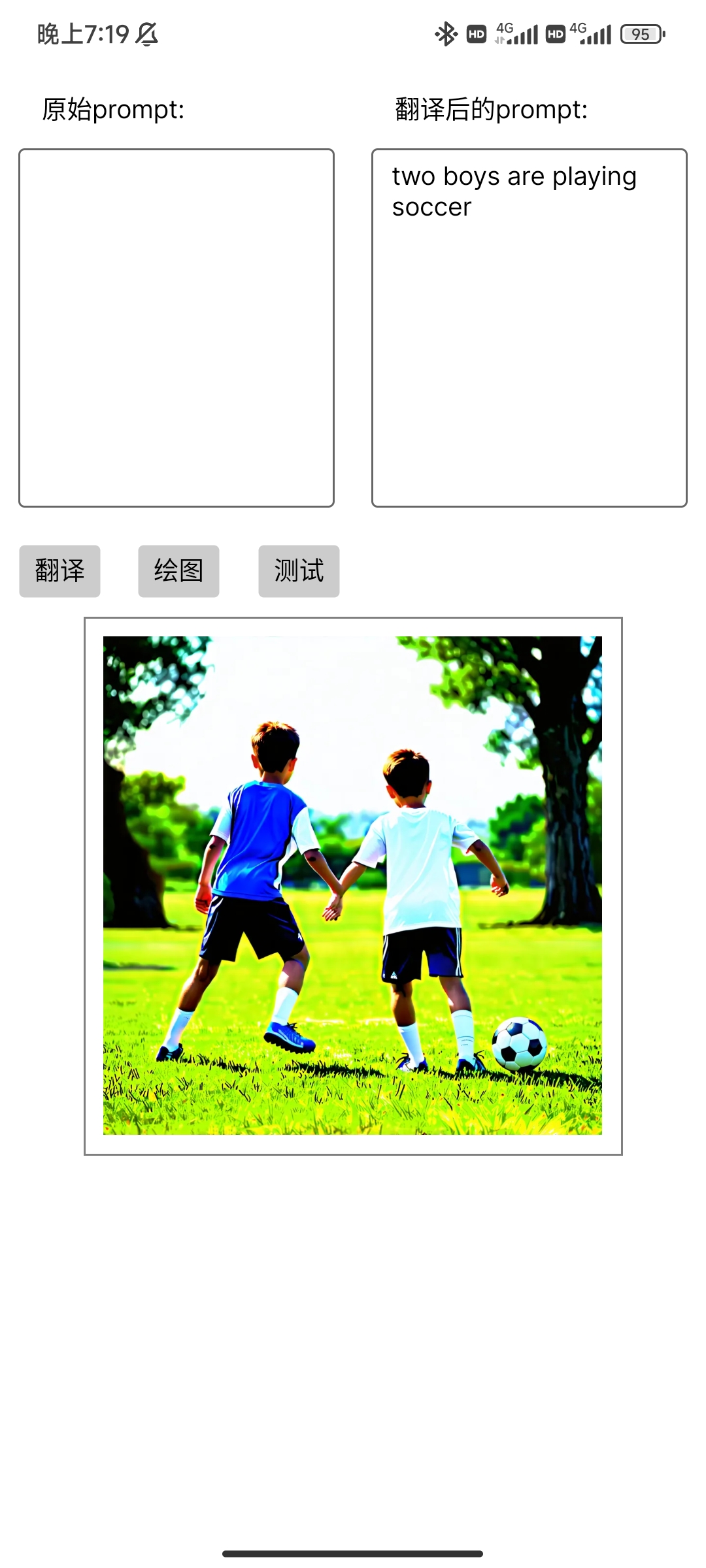
Android端的實現效果如下:
以上就是動手學Avalonia:基于硅基流動構建一個文生圖應用(一)的內容,希望對使用C#構建跨平臺應用感興趣的小伙伴有所幫助。
及同類型軟件介紹)










)







