
在日常的數據處理工作中,Excel無疑是一個強大的工具。然而,當數據量較大或需要自動化處理時,Python憑借其強大的庫支持,如pandas和openpyxl,能夠更高效地處理Excel文件。
本文將介紹Python中常用的五種Excel操作**,**并額外添加兩個實用功能,幫助你提升數據處理和文件美化能力。

一、讀寫Excel數據
為了演示方便,我們先生成一張Excel表:
import pandas as pd \# 創建一個DataFrame
data = { 'Name': \['John', 'Anna', 'Peter', 'Linda'\], 'Age': \[28, 34, 29, 32\]
}
df = pd.DataFrame(data) \# 寫入Excel文件
df.to\_excel('output.xlsx', index=False) \# 讀取Excel文件
df = pd.read\_excel('output.xlsx', sheet\_name='Sheet1')
print(df)我們生產了一個dataframe數據表,利用to_excel函數將這個表保存到本地路徑,保存為’output.xlsx’。
然后再用read_excel函數將這個Excel表讀取進來,數據如下:

現在,這些數據已經被保存到output.xlsx這個Excel表格中,接下來我們對這份數據進行后續操作。

二、修改Excel文件
現在我們將第一個人“John”的年齡改為30歲:
\# 讀取Excel文件
df = pd.read\_excel('output.xlsx') \# 修改數據
df.loc\[0, 'Age'\] = 30 \# 將第一行的Age改為30 \# 寫入Excel文件
df.to\_excel('modified.xlsx', index=False)我們先把剛才保存好的output.xlsx讀取進來,修改第一個人的年齡為30歲,然后再保存為modified.xlsx。
可以看到,當前路徑下有兩張Excel表格。
我們打開modified.xlsx看看:
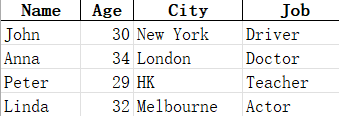
可以看到John的年齡被修改為30歲了。

三、添加和刪除行列
接下來,我們在modified.xlsx表格的基礎上做一些添加和刪除的操作:
●新增一個人的信息;
●添加一列“Pet”,給這幾位靚仔添加一些寵物;
●為了保護個人隱私,把City這一列刪除。
如下:
\# 讀取Excel文件
df = pd.read\_excel('modified.xlsx') \# 添加行
df.loc\[4, :\] = \['Bob', 45, 'Osaka', 'Dancer'\]
\# 添加列
df\['Pet'\] = \['Cat', 'Lion', 'Dog', 'Tiger', 'Monkey'\]
\# 刪除列
df.drop('City', axis=1, inplace=True) \# 寫入Excel文件
df.to\_excel('modified2.xlsx', index=False)我們首先利用df.loc定位到最后一行,新增Bob的相關信息,然后添加Pet這一列的信息,刪除Age這一列,最后保存為modified2.xlsx:
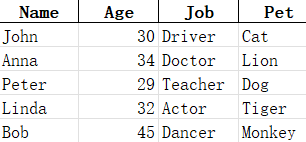
可以看到,Bob的信息被添加進去了,而且City也被刪除了,此外,每位靚仔都擁有了一個寵物!

四、篩選和排序數據
接下來,我們把表格中年齡大于30歲的人篩選出來,保存到另一張Excel表中:
\# 讀取Excel文件
df = pd.read\_excel('modified2.xlsx') \# 篩選Age大于30的數據
filtered\_df = df\[df\['Age'\] > 30\]
\# 按Age列排序
sorted\_df = df.sort\_values(by='Age') \# 寫入Excel文件
df.to\_excel('modified3.xlsx', index=False)首先依然是讀取Excel表格,然后利用dataframe的篩選語句,篩選出Age這一列大于30的人,再用sort_values函數進行排序。
注意,**sort_values函數默認為升序排列,**如果想改為降序排列,需要設定參數ascending=False。
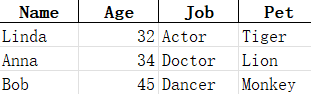
現在新生成的modified3.xlsx表格如下:

五、實現Excel的VLOOKUP
最后我們來點復雜的操作,**實現Excel的王牌函數:**VLOOKUP!
VLOOKUP函數本質上是把兩種表格按照某列關鍵字進行橫向拼接,現在我們再生成一張新表:

沒錯,就是剛才我們刪除的City……這張新表命名為city.xlsx。
現在我們要以Name這一列作為關鍵字,把modified3.xlsx與city.xlsx這兩張表進行橫向拼接:
\# VLOOLUP函數
df1 = pd.read\_excel('modified3.xlsx')
df2 = pd.read\_excel('city.xlsx')
df\_new = pd.merge(df1, df2, on='Name', how='left')
df\_new.to\_excel('last.xlsx')
print(df\_new)這段代碼的關鍵點在于pd.merge函數。
該函數的主要參數如下:

●前兩個參數的參與拼接的表格,df1是左表,df2是右表;
●on參數用于指定關鍵字,一般只用一個關鍵字;
●how參數用于設定合并方式,可以設定為’left’, ‘right’, ‘inner’或’outer’。**這里我們設定為’left’,意思是以左表df1作為標準進行合并。**左表是讀取的modified3.xlsx, 這張表里只有年齡大于30歲的人。
最終生成的last.xlsx表格如下:

任務完成!
通過本文,你學習了如何使用Python進行常用的Excel操作。這些操作能夠幫助你更高效地處理大量數據,提升工作效率。
掌握這些技能后,你可以進一步探索python辦公自動化的其他功能,以應對更復雜的數據處理需求。












之Linux常用命令)
)
)




