????1 項目介紹
1.1 研究目的和意義
在電子商務日益繁榮的今天,精準預測商品銷售數據成為商家提升運營效率、優化庫存管理以及制定營銷策略的關鍵。為此,開發了一個基于深度學習的商品銷售數據預測系統,該系統利用Python編程語言與Django框架,實現了從數據收集、模型訓練到預測結果展示的全流程自動化。
系統首先通過Django框架構建的Web界面,收集并預處理歷史銷售數據。預處理步驟包括數據清洗、標準化以及特征工程,旨在提升后續模型訓練的效率和準確性。接著,利用Python的深度學習庫(如ARIMA),系統構建并訓練了適用于銷售數據預測的深度學習模型。這些模型能夠自動學習歷史數據中的復雜模式,從而準確預測未來一段時間內的銷售趨勢。
完成模型訓練后,系統會將預測結果以直觀的圖表或表格形式展示給用戶。商家可以通過Web界面輕松查看預測的銷售量、銷售額等關鍵指標,并根據這些信息進行庫存調整、促銷策略制定等決策分析。此外,系統還提供了豐富的數據可視化功能,幫助商家更直觀地理解銷售數據的變化趨勢和規律。
本系統具有多項優勢。首先,深度學習模型的引入使得預測結果更加準確可靠;其次,Django框架的采用使得系統具有良好的可擴展性和用戶友好性;最后,系統還支持多數據源接入,能夠處理不同來源、不同格式的銷售數據,滿足商家多樣化的需求。
基于深度學習的商品銷售數據預測系統為商家提供了一個高效、準確且易于使用的銷售預測工具。通過該系統,商家可以更加精準地把握市場變化,優化庫存管理和營銷策略,從而在激烈的市場競爭中脫穎而出。
1.2 系統技術棧
Python
MySQL
Django
LSTM
Scrapy
Echart
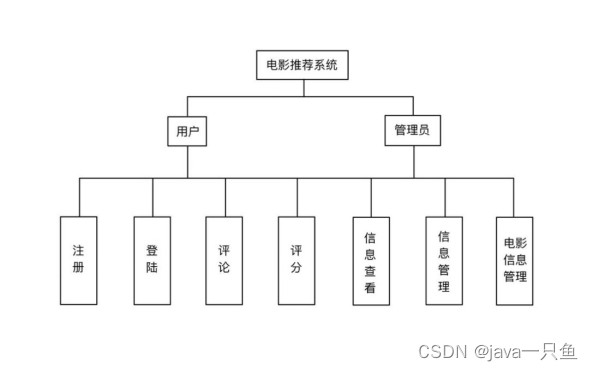
1.3 系統角色
管理員
用戶
1.4 算法描述
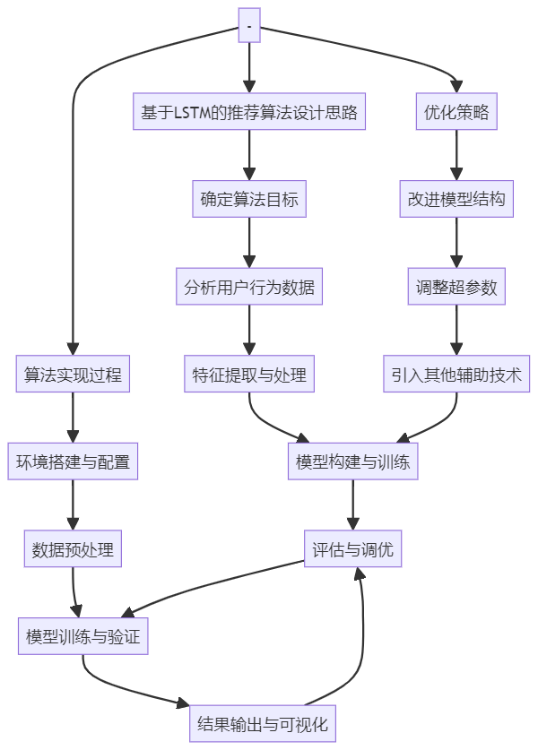
在構建基于深度學習的電影推薦系統時,推薦算法的設計與實現是至關重要的一環。LSTM(長短時記憶)算法作為深度學習領域的一種重要技術,因其出色的序列數據處理能力而被廣泛應用于各種推薦場景中。本節將詳細介紹基于LSTM的推薦算法設計思路、實現過程以及優化策略。
首先,需要明確LSTM算法在推薦系統中的作用。LSTM是一種特殊的循環神經網絡(RNN),它能夠有效地捕捉序列數據中的長期依賴關系。在電影推薦系統中,用戶的觀影歷史可以視為一種時間序列數據,LSTM能夠學習用戶觀影行為的時間序列特征,從而預測用戶未來的觀影偏好。
在設計基于LSTM的推薦算法時,首先需要準備相應的數據集。這包括用戶觀影歷史數據、電影特征數據等。其中,用戶觀影歷史數據是核心,它記錄了用戶在不同時間點的觀影行為。通過預處理這些數據,可以將其轉換為適合LSTM模型輸入的格式。
接下來是LSTM模型的構建。在構建模型時,需要考慮多個因素,如模型的層數、隱藏單元的數量、激活函數的選擇等。這些參數的設置將直接影響模型的性能和訓練效率。通過多次實驗和調整,可以找到一組合適的參數配置。
在模型構建完成后,需要進行模型的訓練。訓練過程中,采用反向傳播算法來優化模型的參數。通過不斷地迭代訓練,模型可以逐漸學習到用戶觀影行為中的潛在規律。為了提高訓練效率,還可以采用一些優化技巧,如批量訓練、學習率調整等。
訓練完成后,可以將LSTM模型應用于推薦系統中。在實際應用中,根據用戶的觀影歷史數據,通過LSTM模型預測用戶未來的觀影偏好,并據此為用戶推薦相應的電影。為了提高推薦的準確性,還可以結合其他技術,如基于內容的推薦、協同過濾等,形成混合推薦策略。
此外,針對LSTM模型的優化也是不可忽視的一環。在實際應用中,可能會遇到一些挑戰,如模型過擬合、訓練不穩定等。為了解決這些問題,可以采取一系列優化策略,如正則化、Dropout技術、梯度裁剪等。這些策略可以有效地提升模型的泛化能力,從而提高推薦系統的性能。
因此,基于LSTM的推薦算法設計與實現是一個復雜而富有挑戰性的過程。通過精心地設計模型結構、選擇合適的參數配置、采用有效的訓練和優化策略,可以構建出高性能的電影推薦系統,為用戶提供更加精準和個性化的觀影體驗。
1.5 系統功能框架圖
1.6 推薦算法流程圖
2? 系統功能實現截圖
2.1 用戶功能模塊實現
2.1.1 登錄

2.1.2 電影庫
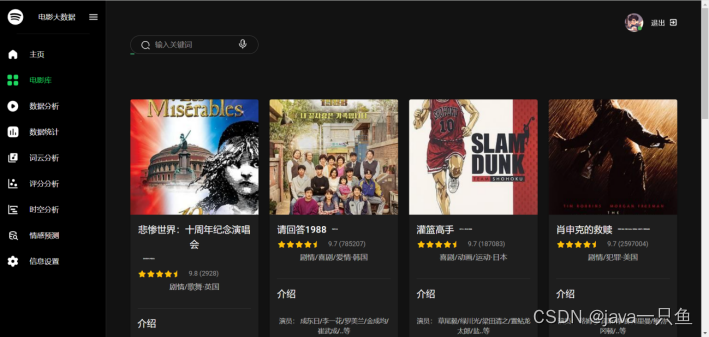
核心代碼如下:
@movieBp.route('/get', methods=["GET"])
def get():
????res = ResMsg()
????keyword = request.args.get('keyword')
????if keyword is None:
????????keyword = ""
????# print(keyword)
????result = db.session.query(Movie).filter(Movie.name.like('%' + keyword + '%')).order_by(Movie.douban_score.desc()).all()[:8]
????data = movie_schema.dump(result)
????res.update(code=ResponseCode.SUCCESS, data=data)
????return res.data
2.1.3 數據分析
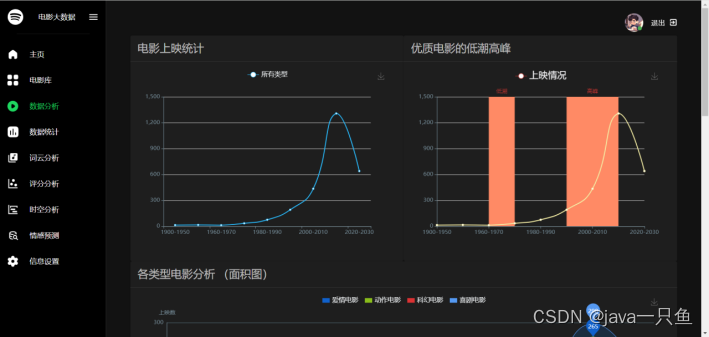
核心代碼如下:
def getChart1():
????res = ResMsg()
????all = []
????dz = []
????kh = []
????aq = []
????xj = []
????ranges = [('1900', '1950'), ('1950', '1960'), ('1960', '1970'), ('1970', '1980'), ('1980', '1990'),
??????????????('1990', '2000'), ('2000', '2010'), ('2010', '2020'), ('2020', '2030')]
????for r in ranges:
????????cnt = db.session.query(Movie).filter(Movie.year >= r[0], Movie.year < r[1]).count()
????????dzcnt = db.session.query(Movie).filter(Movie.genres.like('%動作%'), Movie.year >= r[0], Movie.year < r[1]).count()
????????khcnt = db.session.query(Movie).filter(Movie.genres.like('%科幻%'), Movie.year >= r[0], Movie.year < r[1]).count()
????????aqcnt = db.session.query(Movie).filter(Movie.genres.like('%愛情%'), Movie.year >= r[0], Movie.year < r[1]).count()
????????xjcnt = db.session.query(Movie).filter(Movie.genres.like('%喜劇%'), Movie.year >= r[0], Movie.year < r[1]).count()
????????chart = dict(name=r[0] + '-' + r[1], value=cnt)
????????all.append(chart)
????????chart2 = dict(name=r[0] + '-' + r[1], value=dzcnt)
????????dz.append(chart2)
????????chart3 = dict(name=r[0] + '-' + r[1], value=khcnt)
????????kh.append(chart3)
????????chart4 = dict(name=r[0] + '-' + r[1], value=aqcnt)
????????aq.append(chart4)
????????chart5 = dict(name=r[0] + '-' + r[1], value=xjcnt)
????????xj.append(chart5)
????# data = chart_data.dump(result)
????res.update(code=ResponseCode.SUCCESS, data=dict(all=all, kh=kh, dz=dz, aq=aq, xj=xj))
????return res.data
2.1.4 數據統計
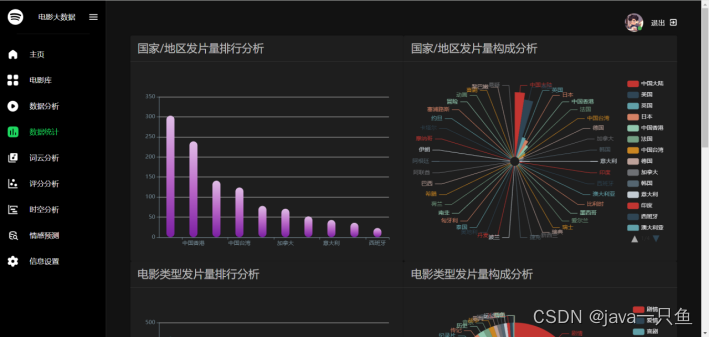
核心代碼如下:
@movieBp.route('/getTypeRank', methods=["GET"])
def getTypeRank():
????res = ResMsg()
????types = ['驚悚', '古裝', '武俠', '冒險', '喜劇', '恐怖', '犯罪', '歷史', '歌舞', '紀錄片', '動畫', '科幻', '西部', '戰爭', '家庭', '傳記', '懸疑',
?????????????'兒童', '災難', '奇幻', '劇情', '同性', '動作', '運動', '音樂', '情色', '愛情']
????datas = []
????for t in types:
????????cnt = db.session.query(Movie).filter(Movie.genres.like('%' + t + '%')).count()
????????chart = dict(name=t, value=cnt)
????????datas.append(chart)
????datas = sorted(datas, key=operator.itemgetter('value'), reverse=True)
????res.update(code=ResponseCode.SUCCESS, data=dict(datas=datas))
????return res.data

















-- 算法導論22.1 3題)

