文章匯總


式中, y s y^s ys表示源域數據的one-hot ground-truth, K K K為類數, w i w_i wi?和 z ~ s \tilde{z}_s z~s?分別表示源域經過提示調優的最終文本表示和最終圖像表示的第 i i i類。
同理,為了進一步利用目標領域的數據,我們使用偽標簽來訓練這些未標記的數據。為了提高這些偽標簽的可靠性,我們設置了一個固定的閾值 τ \tau τ。如果CLIP預測的給定圖像的最大概率 τ p \tau_p τp?低于該閾值,則丟棄偽標簽。同樣,我們采用對比損失函數:

其中 I ( ? ) \mathbb{I}(\cdot) I(?)為指示函數, y ~ t \tilde{y}^t y~?t為目標域數據的one-hot ground-truth, z ~ t \tilde{z}^t z~t為目標域經過提示調優后的最終圖像表示(有IFT那個模塊生成)。
如何構建特征庫。
通過訪問源域和目標域的數據,我們可以從兩個域獲得文本特征和圖像特征。基于CLIP強大的Zero-shot inference能力,我們可以構建魯棒準確的特征庫。首先,我們用Zero-shot inference CLIP的預測為源域中的圖像生成置信度分數(即最大概率)。類似地,我們為目標域中的每個圖像生成置信度分數和相應的偽標簽。具體來說,最大置信度得分的指標就是圖像的偽標簽。我們為源域和目標域選擇在每個類別中置信度得分最高的圖像的視覺特征,并構建一個K-way C-shot源域特征庫和目標域特征庫,其中K表示類別數量,C表示每個類別的樣本數量。然后分別得到每一類的質心特征作為最終的源域特征庫 z s c z_{sc} zsc?和目標域特征庫 z t c z_{tc} ztc?。
IFT流程如下:

IFT利用特征庫引導圖像獲得自增強和跨域特征,如圖2(右)所示。我們首先使用一個權值共享的投影層 f p r e f_{pre} fpre?,即一個三層多層感知器,將圖像特征 z ^ \hat z z^、源域特征庫 z s c z_{sc} zsc?、目標域特征庫 z t c z_{tc} ztc?轉化為查詢、鍵和值,可以表示為:

我們使圖像特征關注源域和目標域特征庫,從而得到增強的圖像特征。這些特征然后被另一個重量共享投影儀轉換 f p o s t f_{post} fpost?。注意整個過程可表述為:
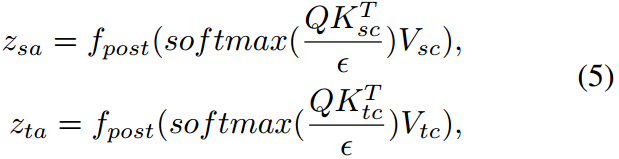
其中, ? \epsilon ?表示尺度值, T T T表示轉置運算。然后,我們將一個加范數模塊與原始的視覺特征結合起來,可以表示為:
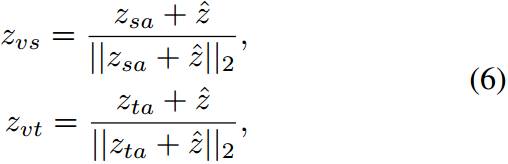
其中 ∥ ? ∥ 2 \|\cdot\|_2 ∥?∥2?表示2范數。則最終的增廣圖像表示 z ^ \hat z z^可表示為 β 1 z v s + β 2 z v t \beta_1z_{vs}+\beta_2z_{vt} β1?zvs?+β2?zvt?。
然后利用對比損失函數對源域和目標域的圖像表示和特征庫進行對齊,可以表示為:

其中 h h h表示IFT模塊, h ( z ^ s ) h(\hat z^s) h(z^s)表示源域的增廣圖像表示。
與基分支相似,我們利用目標域的數據,得到目標域 z ^ t \hat z^t z^t的增廣圖像表示。則采用對比損失函數:

總損失如下:

摘要
最近,盡管大型預訓練視覺語言模型(VLMs)在廣泛的下游任務上取得了前所未有的成功,但現實世界的無監督域自適應(UDA)問題仍然沒有得到很好的探索。因此,在本文中,我們首先通過實驗證明了無監督訓練的VLMs可以顯著降低源域和目標域之間的分布差異,從而提高UDA的性能。然而,直接在下游UDA任務上部署這種模型的一個主要挑戰是提示工程,這需要對齊源領域和目標領域的領域知識,因為UDA的性能受到良好的領域不變表示的嚴重影響。我們進一步提出了一種基于提示的分布對齊方法,將領域知識整合到提示學習中。具體而言,PDA采用兩分支提示范式,即基礎分支和對齊分支。基分支專注于將與類相關的表示集成到提示符中,確保不同類之間的區分。為了進一步減少域差異,在對齊分支中,我們分別為源域和目標域構建了特征庫,并提出了圖像引導特征調優(IFT),使輸入關注特征庫,有效地將自增強和跨域特征集成到模型中。這樣,這兩個分支可以相互促進,以增強VLMs對UDA的適應性。我們在三個基準上進行了廣泛的實驗,以證明我們提出的PDA達到了最先進的性能。代碼可在https://github.com/BaiShuanghao/Prompt-basedDistribution-Alignment上獲得。
1.介紹
無監督域自適應(UDA)旨在通過使用標記的源域和未標記的目標域來提高預訓練模型在目標域的泛化性能(Wilson and Cook 2020;Zhu等2023年)。已經提出了許多方法來解決UDA問題,主要包括對抗性訓練(Ganin和Lempitsky 2015;Rangwani et al 2022)和度量學習(Saito et al 2018;唐、陳、賈2020;張,Wang, and Gai 2020)。然而,通過領域對齊來緩解分布可能會無意中導致語義信息的丟失,這是因為語義和領域信息的糾纏性(Tang, Chen, and Jia 2020;Ge等人2022;Zhang, Huang, and Wang 2022)。
最近,像CLIP (Radford et al . 2021)這樣的大型視覺語言模型(VLMs)在各種下游任務中表現出了令人印象深刻的泛化性能。通過分離視覺和語義表示,可以避免語義信息的丟失,提高UDA的性能。鑒于此,我們進行了一項實證實驗,以證明VLMs對UDA問題的適用性。具體來說,我們評估了單模模型視覺變壓器(ViT) (Dosovitskiy等人2021)和帶有手工制作提示的zero-shot CLIP的性能。在圖1中,盡管CLIP的源特征 r ( I s ) r(I_s) r(Is?)和目標特征 r ( I t ) r(I_t) r(It?)的緊密度與監督訓練的ViT相似。,但最大平均差異(MMD)和KL散度(KL)最小,從而提高了目標域(Acc)的精度。這表明CLIP有可能將UDA的域差異最小化,從而受益于多模態相互作用。

圖1:Office-Home的度量比較。值越高越好。 r r r度量特征的緊度(即類內 L 2 L_2 L2?距離和類間 L 2 L_2 L2?距離 L 2 i n t e r L^{inter}_2 L2inter?)。MMD和KL散度度量域差異。 T , I s T,I_s T,Is?和 I t I_t It?分別表示源域和目標域的文本特征和圖像特征。該方法具有最易識別的文本特征、最緊湊的圖像特征、最小的域差異和最佳的準確率。
為了進一步使VLM適應下游UDA任務,最有效的范例之一是提示調優。當前最先進的提示調優方法,如CoOp (Zhou等)2022b)和MaPLe (Khattak et al . 2023)在一些特定的下游任務上表現出了優越的性能。CoOp方法采用軟提示學習合適的文本提示,MaPLe進一步引入視覺語言提示,確保相互協同。如圖1所示,我們觀察到1)與CLIP相比,MaPLe朝著對齊域邁出了一步,其較低的KL散度和MMD證明了這一點,這表明提示調優可以幫助最小化域移位。2) MaPLe的圖像特征更加緊湊,提示調整可以進一步提高CLIP模型的判別能力。盡管如此,這些提示調優方法(如CoOp或MaPLe)可能不足以完全解決域轉移問題,因為這些方法主要關注提示的位置,而可能無法直接解決域轉移的潛在原因。因此,我們認為提示不僅要注重其設計,而且要通過將領域知識融入提示中來適應不同的領域。
為此,我們提出了一種基于提示的分布對齊(PDA,Prompt-based Distribution Alignment)方法。PDA由兩個支路組成,即基支路和對準支路。基本分支生成帶有提示調優的圖像和文本表示,其重點是將與類相關的表示集成到提示中,確保每個領域的不同類之間的區分。UDA的主要目標是最小化圖像表示的分布偏移。對齊分支利用圖像表示引入領域知識,使領域差異最小化。為此,我們首先構建源域和目標域特征庫,并提出圖像引導特征調優(IFT),使輸入的圖像表示關注特征庫,從而有效地將自增強和跨域特征集成到模型中。如圖1所示,PDA不僅在獲得更容易區分的圖像和文本表示方面表現出色,而且還有效地緩解了域差異。因此,我們的方法可以保證模型的可分辨性,并有效地捕獲源域和目標域的重要特征,從而實現域對齊,使模型更好地適應目標域。我們的主要貢獻如下:
?我們首先通過實驗驗證了VLM在UDA下游任務上的有效性。然后,在此基礎上,我們進一步提出了一種基于提示的分布對齊(PDA)方法來將提示調整到目標域。
?提出的PDA包括兩個訓練分支。首先,基分支確保了不同類之間的區別。其次,對齊分支通過圖像引導特征調優獲得域不變信息;
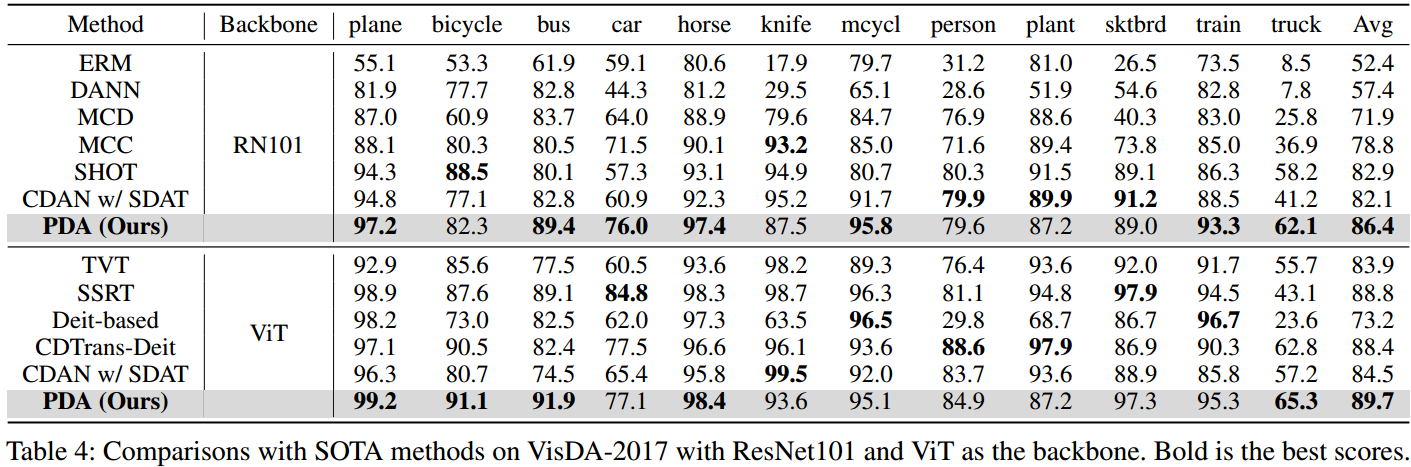
?廣泛的實驗證明了所提出的PDA的有效性,它在Office-Home, Office-31和VisDA-2017上實現了最先進的性能。
2.相關工作
2.1無監督域自適應
無監督域自適應(UDA)旨在通過學習域不變特征表示來對齊源域和目標域(Zhang等人2023b;Chen, Xiao, and Kuang 2022;Xiao et al . 2022)。一種對齊域的方法是最小化不同域之間的散度。已經提出了許多散度度量,如最大平均差異(MMD) (Long et al . 2015),相關對齊(CORAL) (Sun, Feng, and Saenko 2016)和最大密度散度(MDD) (Zhang et al . 2019)。另一種工作是由對抗性學習的成功所激發的。通過將優化過程建模為極大極小問題(Ganin and Lempitsky 2015;Long等人2018;Rangwani et al . 2022;Xiao et al . 2021),引入了一個域鑒別器來區分來自不同域的樣本,目的是訓練模型生成可以欺騙域鑒別器的域不變特征。隨著變壓器模型的出現,TVT (Yang et al . 2023)提出了一種自適應模塊來獲得可轉移和可判別的特征,CDTrans (Xu et al . 2022)利用交叉關注模塊的魯棒性,提出了一種跨域變壓器來直接對特征進行校準。與這些主流的單模態UDA方法不同,我們專注于利用視覺語言模型固有的可轉移性,由于多模態交互,視覺語言模型顯示出有希望的領域對齊能力。
2.2視覺語言模型
預訓練的視覺語言模型(VLMs)通過各種預訓練任務學習圖像-文本相關性,例如掩膜語言建模(Kim, Son, and Kim 2021),掩膜語言建模(Tan and Bansal 2019),圖像文本匹配(Huang et al 2021)和對比學習(Jia et al 2021;張等2022a;Chen et al . 2021)。盡管這些模型在包括零熱和少量視覺識別在內的廣泛任務中取得了前所未有的成功,但將它們有效地適應下游任務仍然是一個艱巨的挑戰。已經提出了許多工作,通過引入額外的特征適配器來增強下游任務的泛化能力(Gao等人2021;張等2023a;Bai et al . 2024)、注意力(Guo et al . 2023)、緩存模型(Zhang et al . 2022b)等。提示學習范式最初用于自然語言處理(NLP)領域,也被集成到VLMs中,成為在各種下游任務中微調VLMs的最有效方法之一。在這項工作中,我們遵循提示學習方法的路線,提出了一種基于提示的分布對齊方法,以提高CLIP的可轉移性,以解決UDA問題。
2.3視覺語言模型的提示微調
提示微調是參數高效調諧的重要組成部分之一,其目的是通過輸入組合(Pfeiffer等)只學習少量的參數2023;Zhu et al . 2023b),同時保持大模型固定。CoOp (Zhou et al . 2022b)首次在VLM中引入了軟提示,證明了合適的文本提示可以提高圖像識別性能。CoCoOp (Zhou et al .2022a)通過集成輕量級神經網絡對CoOp進行擴展,為單個圖像動態生成提示,以處理提示的過擬合問題。VPT (Jia et al 2022)在變壓器模型中使用一些視覺提示實現了令人印象深刻的結果。此外,MaPLe (Khattak et al . 2023)將文本和視覺提示結合到CLIP中,以改善文本和圖像表示之間的對齊。為了利用UDA(無監督域自適應)提示調優的有效性,我們引入了一個由基分支和對齊分支組成的雙分支訓練范式。基礎分支利用提示調優來增強CLIP模型的可辨別性。對于對齊分支,我們設計了一個圖像引導的特征調優來減輕域差異。
3 Preliminaries
3.1無監督域適應
UDA側重于利用源域的標記數據和目標域的未標記數據來提高模型的泛化性能。形式上,給定源域的標記數據集 D S = { x i s , y i s } i = 1 n s D_S=\{x^s_i,y_i^s\}^{n_s}_{i=1} DS?={xis?,yis?}i=1ns??,未標記數據集 D t = { x j t } j = 1 n t D_t=\{x^t_j\}^{n_t}_{j=1} Dt?={xjt?}j=1nt??,其中 n s n_s ns?和 n t n_t nt?分別表示源域和目標域的樣本大小。注意,兩個域的數據是從兩個不同的分布中采樣的,我們假設這兩個域共享相同的標簽空間。我們將輸入空間表示為 X X X,將標簽集表示為 Y Y Y。有一個從圖像到標簽的映射 M : { X } → Y M:\{X\}\rightarrow Y M:{X}→Y。在這項工作中,我們將提示符 V V V合并到輸入中,因此從圖像和提示符到標簽的映射可以重新表述為 M : { X , V } → Y M:\{X,V\}\rightarrow Y M:{X,V}→Y。我們的目標是緩解 D S D_S DS?和 D t D_t Dt?之間的領域差異問題,并學習一個可以促進知識從源領域轉移到目標領域的廣義提示 P P P。
3.2回顧提示學習
對比語言-圖像預訓練(CLIP)模型由圖像編碼器和文本編碼器組成,分別對圖像和相應的自然語言描述進行編碼。
Zero-shot inference。預訓練的CLIP模型適應于具有手工提示的下游任務,而不是對模型進行微調。文本總是手動設計為“a photo of a [CLASS]”([CLASS]是類標記)。使用圖像表示 z z z與對應第 i i i類的文本表示 w i w_i wi?之間的余弦相似度 s i m ( w i , z ) sim(w_i,z) sim(wi?,z)計算圖像-文本匹配分數。圖像表示從具有輸入圖像的圖像編碼器中派生,而文本表示 w i w_i wi?使用與第 i i i類關聯的提示描述從文本編碼器中提取。圖像屬于第 i i i類的概率可表示為:

式中 t t t為溫度參數, K K K為類數, s i m sim sim為余弦相似度。
文本提示調優。避免了人工提示工程,增強了CLIP的傳遞能力。CoOp (Zhou et al . 2022b)引入了一組 M M M個連續可學習上下文向量 v = [ v 1 , v 2 , . . . , v M ] v=[v^1,v^2,...,v^M] v=[v1,v2,...,vM],則第 i i i類文本提示符 t i t^i ti定義為 t i = [ v , c i ] t^i = [v,c^i] ti=[v,ci],其中 c i c^i ci為固定輸入令牌嵌入。可學習的上下文向量可以擴展到基于transformer架構的文本編碼器的更深層次的transformer層,因此每層輸入可以重新表述為 [ v j , c j ] j = 1 J [v_j,c_j]^J_{j=1} [vj?,cj?]j=1J?,其中 J J J為文本編碼器中的transformer層數, [ ? , ? ] [\cdot,\cdot] [?,?]表示連接操作。
視覺提示調整。它采用了與文本提示調優類似的范例,其中自動學習輸入到圖像編碼器的每一層的附加上下文向量。對于基于transformer的圖像編碼器,VPT (Jia et al . 2022)在一系列patch embedding e e e和可學習的類令牌 c c c之間插入提示符集合 v ~ \tilde{v} v~,可設計為 [ v ~ j , e j , c j ] j = 1 J [\tilde{v}_j,e_j,c_j]^J_{j=1} [v~j?,ej?,cj?]j=1J?。
多模態提示協調。文本提示符 v v v和可視提示符 v ~ \tilde{v} v~組合成CLIP。例如,MaPLe (Khattak et al . 2023)通過在兩種模式之間共享提示來調整CLIP的視覺和語言分支。
4.方法
受上一節觀察結果的啟發,我們嘗試為UDA設計一種高效且有效的提示調優方法。為了增強提示的可轉移性,我們提出了一種基于提示的分布對齊(PDA)方法,其框架如圖2所示。我們介紹我們的PDA方法如下。
圖2:提出的基于提示的分布對齊(PDA)方法的概述。雪表示凍結的參數,火表示可學習的參數。從左到右,我們分別展示了PDA的詳細框架和IFT模塊的架構。我們的PDA方法主要采用多模態提示調諧。此外,IFT模塊使視覺特征參加源/目標域特征庫進行域對齊。
4.1 Prompting for Base Branch

提示的設計。我們主要采用多模式提示模式。對于圖像編碼器的早期層,使用文本提示符通過投影層生成視覺提示符。這意味著使用文本提示來指導圖像的編碼過程,使圖像在特征空間中具有與給定文本相關的信息,從而實現圖像與相關文本信息的對齊。對于圖像編碼器的后一層,每一層使用一個獨立的提示符。這種設計允許每一層獨立捕獲圖像的不同視覺和語義特征,實現更好的圖像-文本交互,捕獲不同的視覺和語義特征。
損失函數。然后使用對比損失函數對圖像和文本表示進行對齊,可以表示為:
式中, y s y^s ys表示源域數據的one-hot ground-truth, K K K為類數, w i w_i wi?和 z ~ s \tilde{z}_s z~s?分別表示源域經過提示調優的最終文本表示和最終圖像表示的第 i i i類。
為了進一步利用目標領域的數據,我們使用偽標簽來訓練這些未標記的數據,如Ge等人(Ge et al 2022)。偽標簽由CLIP模型的預測生成。為了提高這些偽標簽的可靠性,我們設置了一個固定的閾值 τ \tau τ。如果CLIP預測的給定圖像的最大概率 τ p \tau_p τp?低于該閾值,則丟棄偽標簽。同樣,我們采用對比損失函數:
其中 I ( ? ) \mathbb{I}(\cdot) I(?)為指示函數, y ~ t \tilde{y}^t y~?t為目標域數據的one-hot ground-truth, z ~ t \tilde{z}^t z~t為目標域經過提示調優后的最終圖像表示。
4.2 Pipeline of Alignment Branch
對于對齊分支,我們為源域和目標域構建特征庫,并提出圖像引導特征調優(IFT),使輸入關注特征庫以實現域對齊。
構建特征庫。通過訪問源域和目標域的數據,我們可以從兩個域獲得文本特征和圖像特征。基于CLIP強大的Zero-shot inference能力,我們可以構建魯棒準確的特征庫。首先,我們用Zero-shot inference CLIP的預測為源域中的圖像生成置信度分數(即最大概率)。類似地,我們為目標域中的每個圖像生成置信度分數和相應的偽標簽。具體來說,最大置信度得分的指標就是圖像的偽標簽。我們為源域和目標域選擇在每個類別中置信度得分最高的圖像的視覺特征,并構建一個K-way C-shot源域特征庫和目標域特征庫,其中K表示類別數量,C表示每個類別的樣本數量。然后分別得到每一類的質心特征作為最終的源域特征庫 z s c z_{sc} zsc?和目標域特征庫 z t c z_{tc} ztc?。
圖像引導特征調整(IFT)。IFT利用特征庫引導圖像獲得自增強和跨域特征,如圖2(右)所示。我們首先使用一個權值共享的投影層 f p r e f_{pre} fpre?,即一個三層多層感知器,將圖像特征 z ^ \hat z z^、源域特征庫 z s c z_{sc} zsc?、目標域特征庫 z t c z_{tc} ztc?轉化為查詢、鍵和值,可以表示為:
我們使圖像特征關注源域和目標域特征庫,從而得到增強的圖像特征。這些特征然后被另一個重量共享投影儀轉換 f p o s t f_{post} fpost?。注意整個過程可表述為:
其中, ? \epsilon ?表示尺度值, T T T表示轉置運算。然后,我們將一個加范數模塊與原始的視覺特征結合起來,可以表示為:
其中 ∥ ? ∥ 2 \|\cdot\|_2 ∥?∥2?表示2范數。則最終的增廣圖像表示 z ^ \hat z z^可表示為 β 1 z v s + β 2 z v t \beta_1z_{vs}+\beta_2z_{vt} β1?zvs?+β2?zvt?。
損失函數。然后利用對比損失函數對源域和目標域的圖像表示和特征庫進行對齊,可以表示為:
其中 h h h表示IFT模塊, h ( z ^ s ) h(\hat z^s) h(z^s)表示源域的增廣圖像表示。
與基分支相似,我們利用目標域的數據,得到目標域 z ^ t \hat z^t z^t的增廣圖像表示。則采用對比損失函數:
因此,我們的PDA方法可以使用總對比損失進行端到端訓練:
其中 γ \gamma γ是超參數。在測試階段,我們計算來自基礎分支和對齊分支的預測的加權和,從而得到我們模型的最終預測。這兩個分支不僅對增強模型的可分辨性,而且對調整源域和目標域之間的分布轉移至關重要。
5.實驗
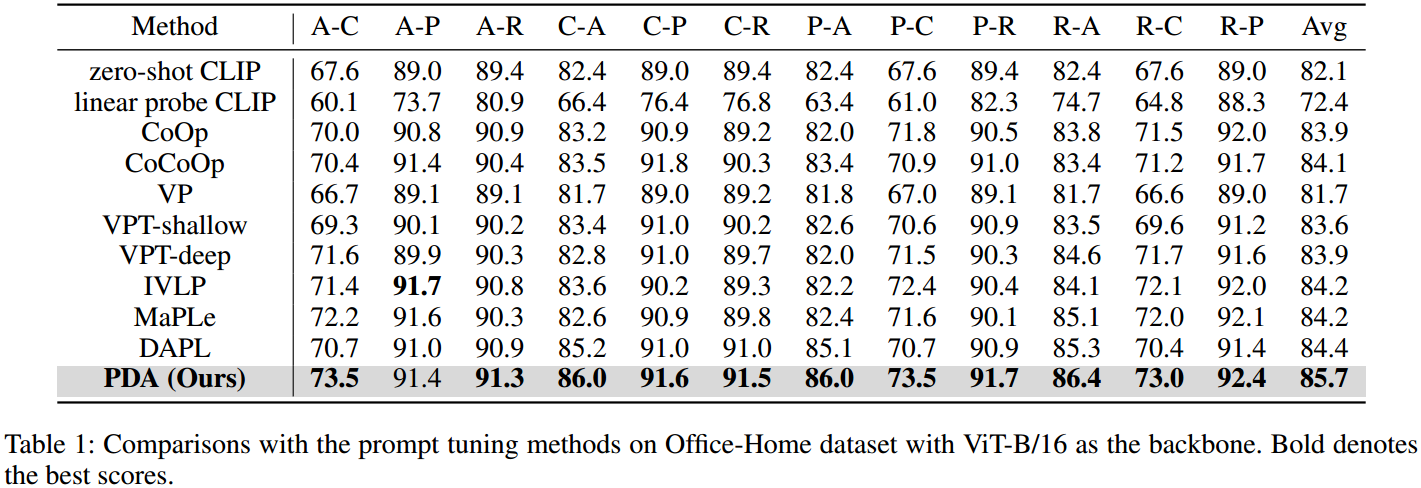

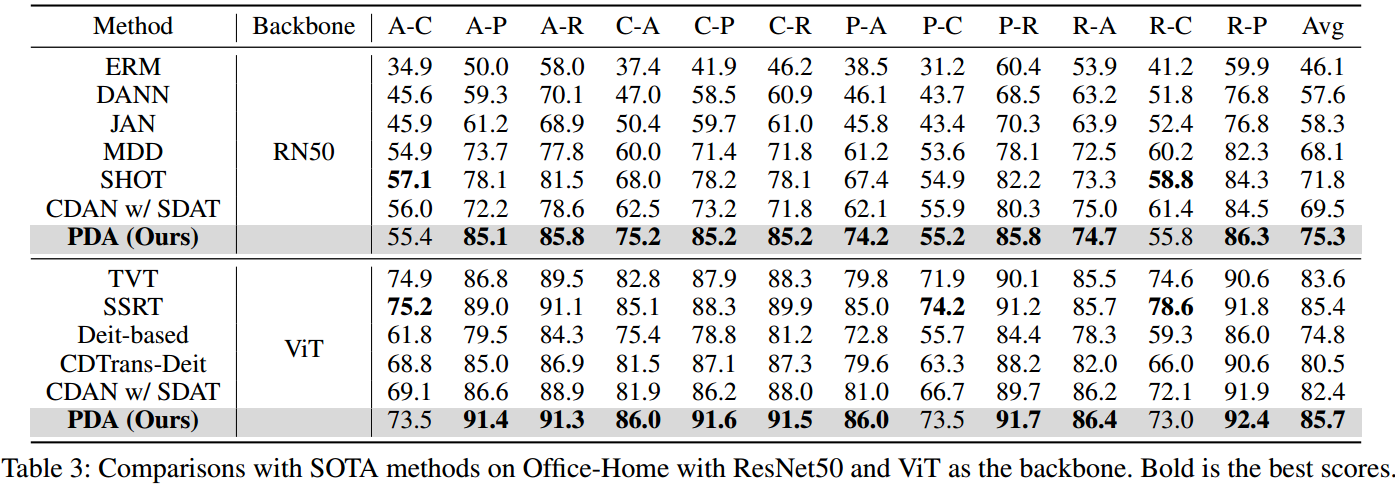

如圖3所示,我們通過t-SNE將zero-shot CLIP、MaPLe和PDA在三個數據集中的四個任務上提取的圖像特征可視化。我們可以觀察到,我們的PDA方法可以更好地對齊兩個域。
6.結論
在本文中,我們證明了視覺語言模型和VLM的提示調優對于無監督域自適應的有效性。在此基礎上,我們將分布對齊引入到提示調優中,提出了一種基于提示的分布對齊方法。這兩個分支不僅在提高模型的可分辨性方面起著至關重要的作用,而且在減輕源域和目標域之間的分布轉移方面起著至關重要的作用。大量的實驗證實了我們提出的方法的有效性,我們的PDA方法在無監督域自適應方面取得了新的最先進的性能。由于學習提示的可轉移性,我們可以在未來的工作中進一步探索無監督域適應或其他下游任務的提示對齊。
參考資料
論文下載(AAAI 2024)
https://arxiv.org/abs/2312.09553v2

代碼地址
https://github.com/BaiShuanghao/Prompt-based-Distribution-Alignment
)
)







)



滾動基類)

在同一域名下,傳遞消息給另一個頁面)

詳解)

![[Go] 字符串遍歷數據類型問題](http://pic.xiahunao.cn/[Go] 字符串遍歷數據類型問題)