大模型增量預訓練新技巧-解決災難性遺忘
機器學習算法與自然語言處理?2024年03月21日 00:02?吉林
以下文章來源于NLP工作站?,作者劉聰NLP
NLP工作站.
AIGC前沿知識分享&落地經驗總結
轉載自 |?NLP工作站
作者 |?劉聰NLP
目前不少開源模型在通用領域具有不錯的效果,但由于缺乏領域數據,往往在一些垂直領域中表現不理想,這時就需要增量預訓練和微調等方法來提高模型的領域能力。
但在領域數據增量預訓練或微調時,很容易出現災難性遺忘現象,也就是學會了垂直領域知識,但忘記了通用領域知識,之前介紹過增量預訓練以及領域大模型訓練技巧,詳見:
-
如何更好地繼續預訓練-Continue PreTraining
-
領域大模型-訓練Trick&落地思考
今天給大家帶來一篇增量預訓練方法-Llama-Pro,對LLMs進行Transformer塊擴展后,增量預訓練過程中僅對新增塊進行訓練,有效地進行模型知識注入,并且極大程度地避免災難性遺忘。
LLaMA Pro: Progressive LLaMA with Block Expansion
LLaMA?Pro:?Progressive?LLaMA?with?Block?Expansion
Paper:?https://arxiv.org/abs/2401.02415
Github:?https://github.com/TencentARC/LLaMA-Pro
塊擴展方法
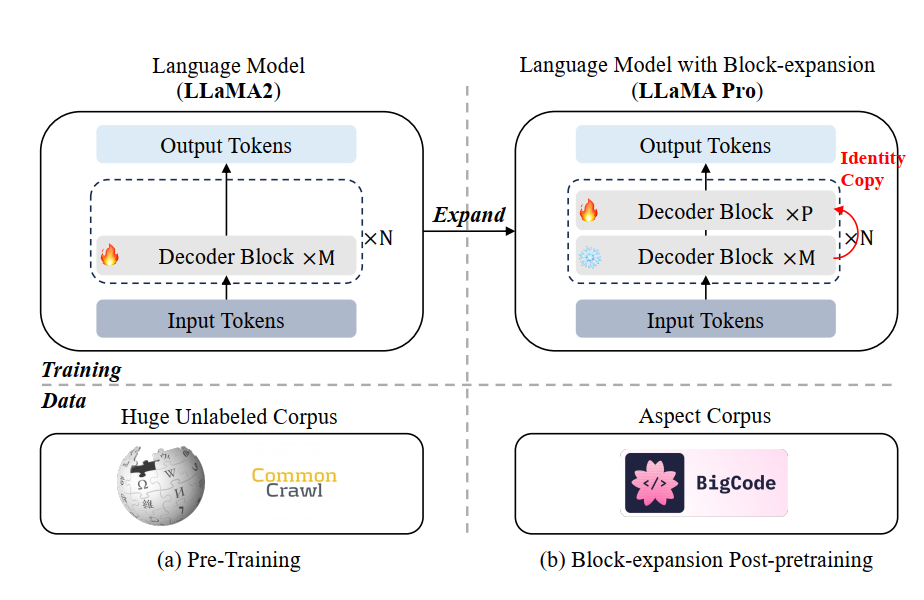
塊擴展,顧名思義,就是在原始模型中每個Transformer塊或者某幾個Transformer塊后增加一個Transformer塊,但為了保持擴展后的模型輸出保持不變,需要增加的塊為恒等塊(輸入輸出相同),如下圖所示。

在構建恒等塊過程中,主要是將多頭注意力層和FFN層中的最后一個線性層(Linear)權重置為0變成Zero-Linear,即可保持經過該塊的輸入輸出一致。
PS:論文附錄A中寫了大段的推導公式來證明,在此不做過多介紹。
塊的增加方式是,對原始模型的L個Transformer塊分成N組,每組中包含M=L/N個Transformer塊,對于每組后添加P個恒等塊。代碼實現具體如下:
model?=?AutoModelForCausalLM.from_pretrained(model_path,?torch_dtype=torch.float16)
ckpt?=?model.state_dict()#?original_layers是模型原始層數,layers是模型最后達到層數
split?=?int(original_layers?/?(layers?-?original_layers))layer_cnt?=?0output?=?{}
for?i?in?range(original_layers):for?k?in?ckpt:if?('layers.'?+?str(i)?+?'.')?in?k:output[k.replace(('layers.'?+?str(i)?+?'.'),?('layers.'?+?str(layer_cnt)?+?'.'))]?=?ckpt[k]layer_cnt?+=?1if?(i+1)?%?split?==?0:for?k?in?ckpt:if?('layers.'?+?str(i)?+?'.')?in?k:if?'down_proj'?in?k?or?'o_proj'?in?k:output[k.replace(('layers.'?+?str(i)?+?'.'),?('layers.'?+?str(layer_cnt)?+?'.'))]?=?torch.zeros_like(ckpt[k])else:output[k.replace(('layers.'?+?str(i)?+?'.'),?('layers.'?+?str(layer_cnt)?+?'.'))]?=?ckpt[k]layer_cnt?+=?1assert?layer_cnt==layers
for?k?in?ckpt:if?not?'layers'?in?k:output[k]?=?ckpt[k]torch.save(output,?output_path)
實驗細節
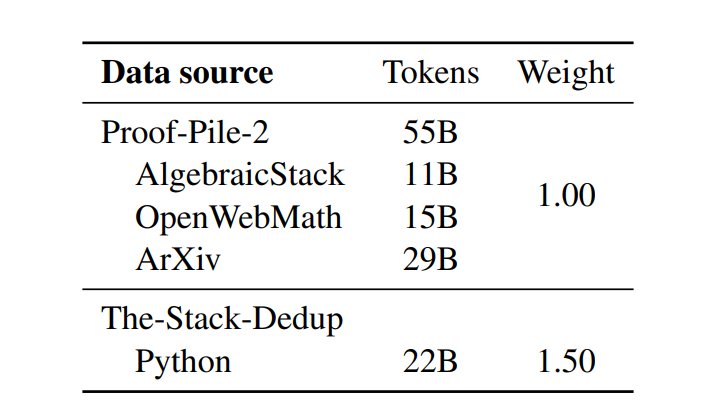
數據由代碼和數學組成,其中代碼數據采用The-Stack-Dedup數據集中Python語言部分共22B Token,數學數據采用Proof-Pile-2數據集中AlgebraicStack、OpenWebMath和ArXiv部分共55B,詳細如下表所示。
數據分布
基礎模型為LLaMA2-7B模型,通過塊擴展方法將32層模型擴展到40層,其中 P=1,M=4,N=8,每個組從4個Transformer塊擴展到5個Transformer塊。
對于代碼和數學數據進行增量預訓練,批量大小為1024,序列最大長度為4096,預熱比率為6%,學習率為2e-4,采用余弦學習率調度器,BF16混合精度訓練,權重衰減為0.1。使用16個NVIDIA H800 GPU進行了15900個步驟的訓練,大約耗費2830個GPU/小時。
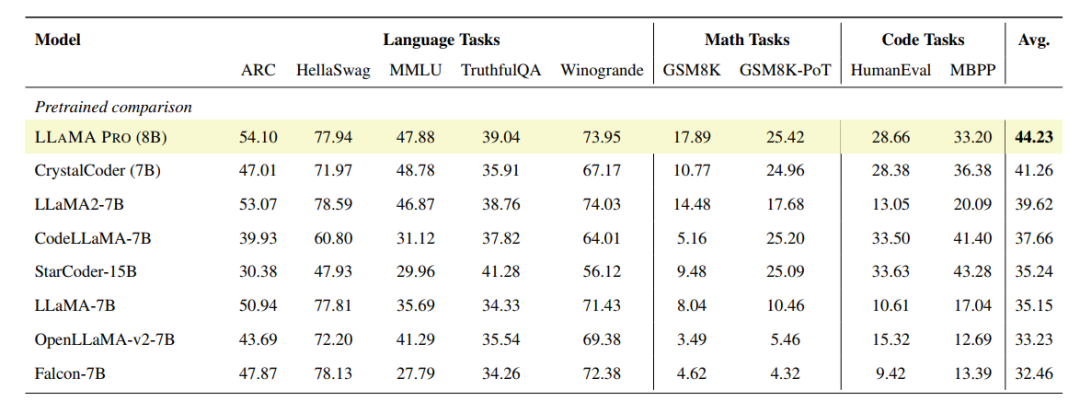
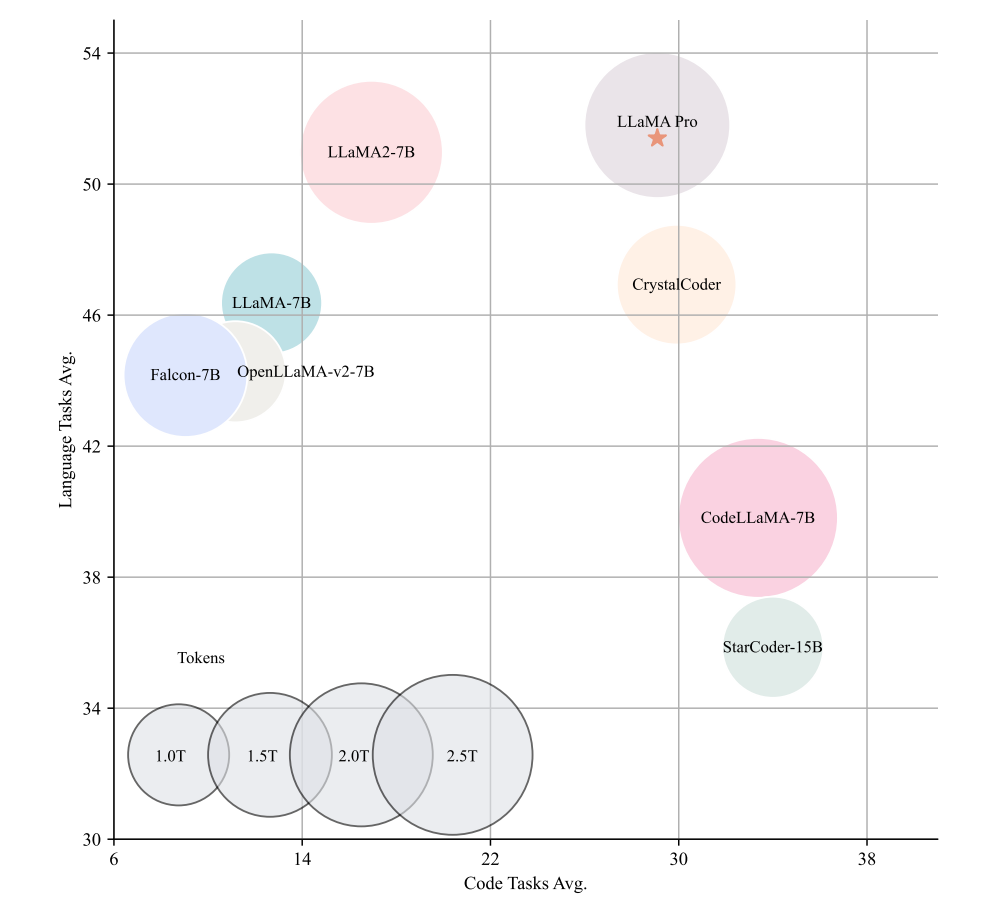
在ARC、HellaSwag、MMLU、TruthfulQA、Winogrande、GSM8K、GSM8K-PoT、HumanEval、MBPP等多個評測數據集中進行評測,可以看出,在保持通用任務能力不下降的情況下,數學和代碼能力較原始LLaMA2-7B模型有很大提升。
討論分析
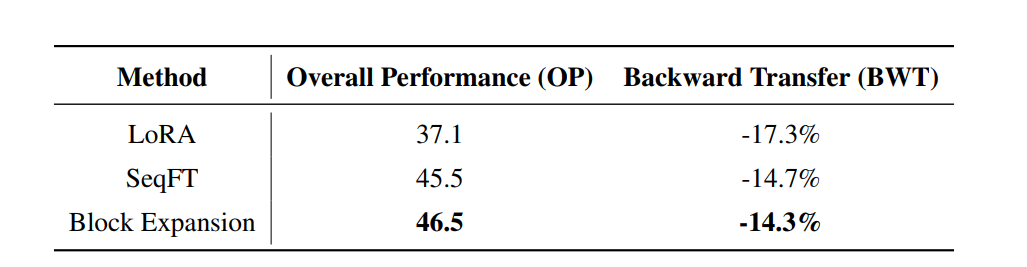
對比塊擴展方法與正常訓練和Lora方法之間的區別,采用TRACE基準利用總體性能(OP)和逆向轉移(BWT)指標進行評估。,如下表所示,塊擴展方法整體提升較大。
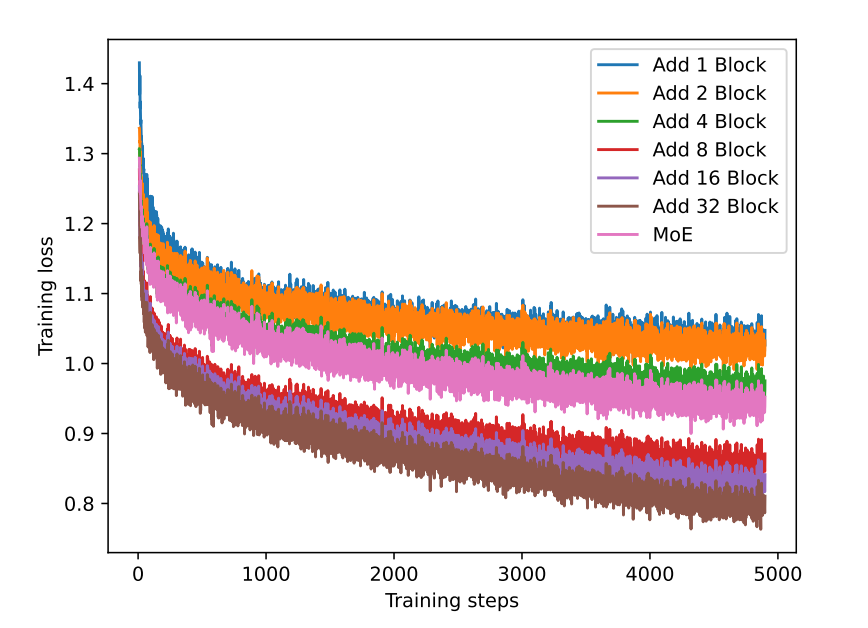
對比塊個數對塊擴展方法的影響,進行了不同個數塊的實驗,并且對比了MoE的方法,訓練損失如下,MoE方法的損失下降程度與添加四個塊相當。
在代碼和法律(16.7B)領域數據下進行增量預訓練,在通用任務以及領域任務上比較不同個數塊之間的差異,同時比較擴展塊全部添加到模型底部或頂部之間的差別,如下所示。可以發現塊個數為8時效果最佳,并且不能直接將擴展塊全部堆積在頭部或尾部,需要分開插入。

寫在最后
該方法主要通過增加恒定塊擴展模型層數,使模型在增量訓練過程中僅訓練新增層、凍結原始層,保持模型原有能力,防止模型出現災難性遺忘現象。
但有兩點存疑:
-
目前來說mistral要好于llama,為啥不用mistral進行實驗
-
不用恒定塊,性能會差多少


)



![ceph mgr [errno 39] RBD image has snapshots (error deleting image from trash)](http://pic.xiahunao.cn/ceph mgr [errno 39] RBD image has snapshots (error deleting image from trash))












