獲取數據
requests庫
獲取數據環節需要用到requests庫。安裝方式也簡單
pip install requests
爬取頁面豆瓣讀書 Top 250
用requests庫來訪問
import requests
res = requests.get('https://book.douban.com/top250/')解析:
- 導入requests庫
- 調用了requests庫中的get() 方法,傳入URL 發送請求,并把收到的響應保存到變量res中
res長什么樣呢?我們打印一下

變量res的值是<Response [418]>,怎么回事呢?
Response對象
? ? 這是因為,HTTP 響應內容不單單包括客戶端所請求的資源本身,還包含響應狀態等信息。因此 requests 庫選擇將獲取的響應打包為?Response?對象,方便我們通過類的?屬性?或?方法?獲取想要的內容。而當我們打印?Response?對象本身時,Python 會按照 requests 庫約定好的方式,打印出類名(Response)和本次響應狀態碼。
<Response [418]>,說明本次響應狀態為418,表明本次請求發生了客戶端錯誤
消息頭 headers
按照下面的步驟操作一下
- 點擊練習上面的 URL,此時瀏覽器會在新標簽頁為你打開豆瓣讀書 Top 250 頁面;
- 頁面加載完成后,打開網頁開發者工具,切換到 Network 面板;
- 刷新頁面;
- 在 Network 面板請求列表中找到名為?top250?的請求,并在請求詳情頁找到?Request Headers(請求頭)?信息。

無論是瀏覽器想服務器發送請求,還是服務器想瀏覽器作出響應,這中間都會通過header傳遞附加信息。這些附加信息中就包含了我們爬蟲程序偽裝瀏覽器的關鍵。
觀察請求列表中每條請求的消息頭,我們會發現許多重復出現的名稱,其中有一項名為?user-agent。(下面這個是我電腦上的,每個人的應該都有差異)
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
我們只需要將需要附上的信息組織成?字典?的格式,再通過?headers?參數傳遞給?get()?方法,requests 庫幫我們向服務器發送請求時,就會自動帶上這些信息了。
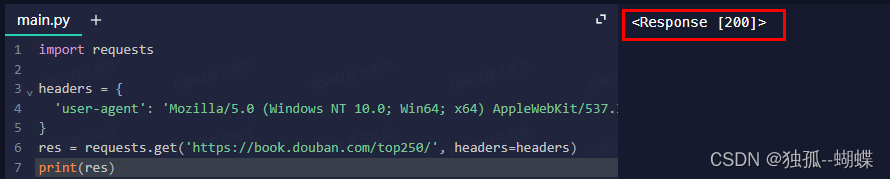
import requests# 定制消息頭
headers = {# 消息頭中有一項附加信息 user-agent'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
# 攜帶消息頭向服務器發送請求
res = requests.get('https://book.douban.com/top250/', headers=headers)偽裝成功了!
requests 庫早已把響應內容轉換為?字符串?類型,保存到 Response 對象的?text?屬性中,我們能很輕松地通過?.?運算符訪問到:
import requestsheaders = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
res = requests.get('https://book.douban.com/top250/', headers=headers)
print(res.text)# 輸出:
# <!DOCTYPE html>
# <html lang="zh-cmn-Hans" class="ua-mac ua-webkit book-new-nav">
# <head>
# <meta http-equiv="Content-Type" content="text/html; charset=utf-8">
# <title>豆瓣讀書 Top 250</title>
# ...返回的是HTML源代碼。
解析數據
BeautifulSoup對象
解析數據我們需要用到BeautifulSoup對象。
安裝
pip install bs4
導入
from bs4 import BeautifulSoup
說明文檔主要說明兩個關鍵信息:
- 創建?BeautifulSoup 對象?時,它會把 HTML/XML 文檔解析成?樹形結構
- BeautifulSoup 類繼承自 Tag 類,因此 BeautifulSoup 類和 Tag 類有許多共用的方法。
創建
創建BeautifulSoup對象時,需要傳入兩個參數:
- 所需解析的?HTML 代碼,即響應的文本內容(
res.text); - 用于解析 HTML 代碼的?解析器,課程內使用的是 Python 內置解析器?
html.parser(parser:解析器)。
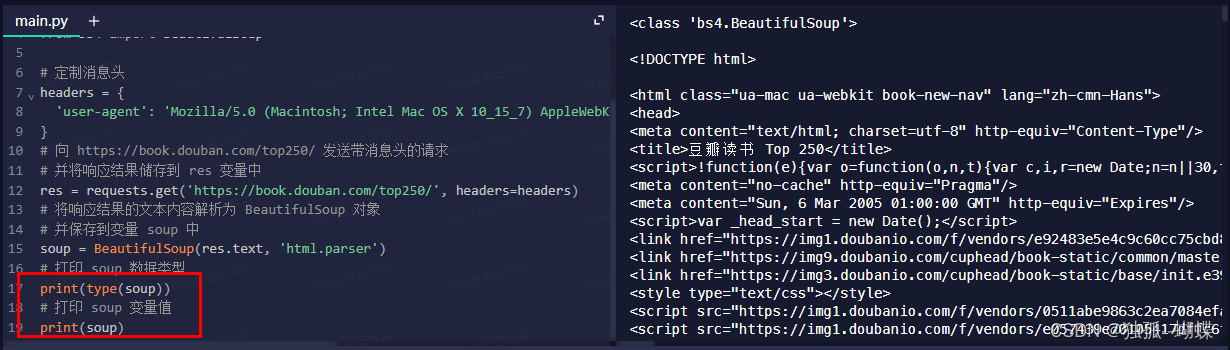
# 導入 requests 庫
import requests
# 從 bs4 庫中導入 BeautifulSoup
from bs4 import BeautifulSoup# 定制消息頭
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
# 發送帶消息頭的請求
res = requests.get('https://book.douban.com/top250', headers=headers)
# 創建 BeautifulSoup 對象,解析響應的文本內容
soup = BeautifulSoup(res.text, 'html.parser')執行結果
BeautifulSoup 對象?內部結構像一棵倒著生長的樹,樹根在上面,枝葉在下面,每個節點都對應著 HTML 代碼中的一個元素。順著這棵?HTML 文檔樹,我們就能定位到某個或某群具有相同特征的元素,從而提取出元素文本內容——也就是我們所需的數據。
HTML 文檔樹
<!DOCTYPE html>
<html lang="zh">
<head><meta charset="UTF-8"><title>我的網頁</title><style> body { background-color: #101324; color: #ffffff; font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, 'Helvetica Neue', Arial, 'Noto Sans', sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol', 'Noto Color Emoji'; } a { color: #1890ff; } code { background: rgba(255, 255, 255, 0.15); padding: 0 6px; border-radius: 4px; color: rgba(255, 255, 255, 0.87); } img { width: 100%; } </style>
</head>
<body><h2>Web 真好玩!</h2><p>今天我在 <a href="https://web.shanbay.com/codetime-study/pc/uduni">爬蟲課第 2 關</a> 學到了這些內容:</p><ol><li>HTML 基本語法</li><li>HTML 文檔結構</li><li>Elements 面板 <code>Edit text</code> 功能</li></ol><p>其中常見的 HTML 元素有這些:</p><img src="https://media-image1.baydn.com/storage_media_image/svpyor/ff5185b0ab456965c9f89c7506ed0a9e.bff6930d34f5dca7819b5e571f421b9b.png">
</body>
</html>該 HTML 文檔根節點為?html 元素。它有兩個子節點,分別是?head 元素?和?body 元素。再往內推,head 與 body 內也分別包含諸多元素。我們將這些元素按照?根節點?–?子節點?–?子節點的子節點……?順序從上至下梳理出的圖譜,就是?HTML 文檔樹。
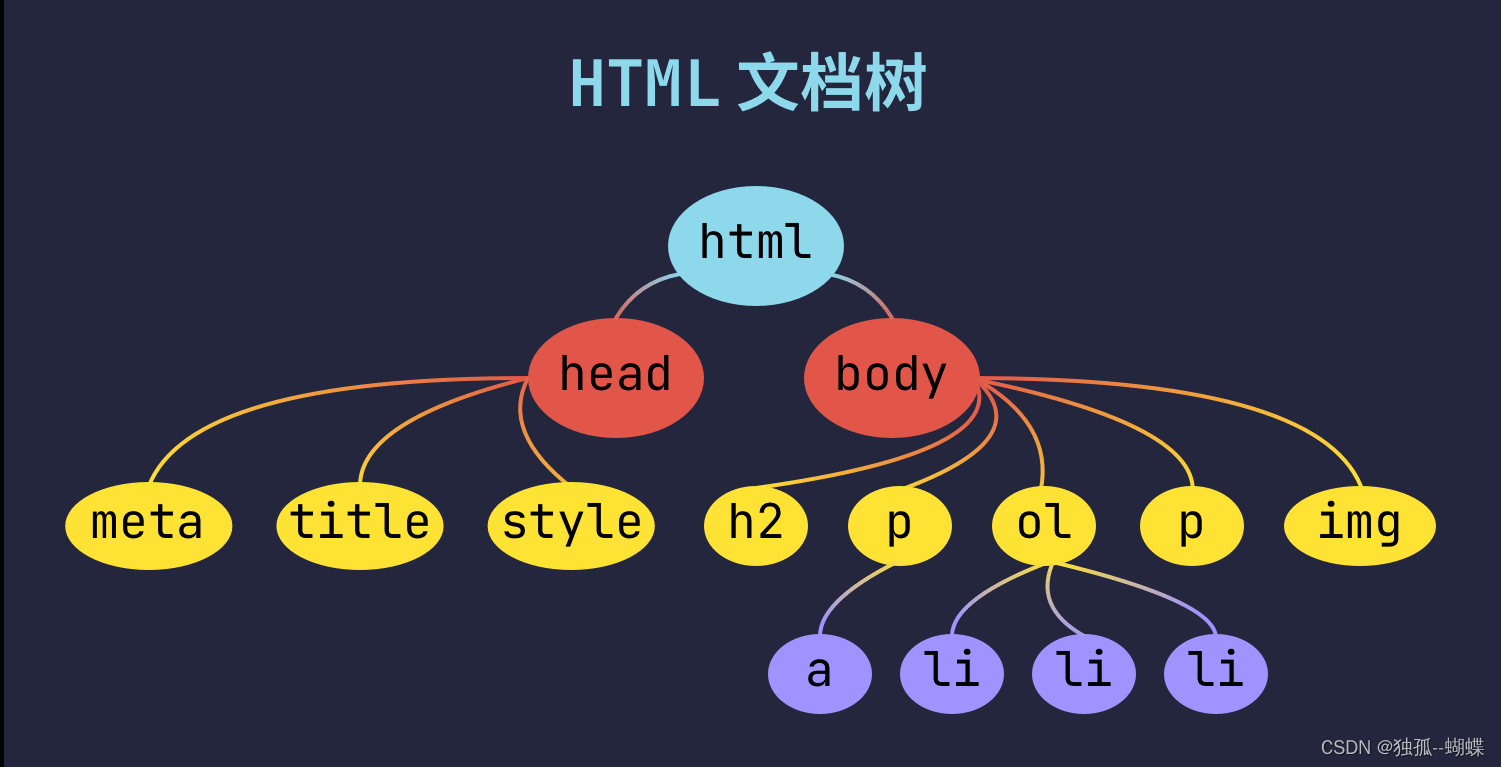
一棵文檔樹就像是這些元素的族譜:
- html 元素是所有其它元素的?祖先,反過來說,其它元素都是 html 的?后代;
- head 元素和 body 元素的?父節點?是 html 元素,因此它們是 html 的?直接后代;
- 由于 head 和 body 父節點相同,所以它們互為?兄弟節點;
提取數據
通過css選擇器提取
CSS 選擇器
CSS 選擇器是 CSS 語言中的一部分,能通過 HTML 元素的?類型、標識?和?關系?快速選擇符合條件的?所有元素。
靠 class 屬性值檢索的選擇器被稱為?類選擇器,需要寫成?.class_name,表示檢索所有 class 屬性值為?class_name?的元素。靠 id 屬性值檢索的被稱為?ID 選擇器,寫成?#id_name,表示檢索所有 id 屬性值為?id_name?的元素。
元素與元素之間的關系可以分為?祖先?–?后代、祖先?–?直接后代、兄弟?–?兄弟?三類,因此兩個元素之間的組合關系也分為三種:
A B:檢索 A 元素?后代?中的所有 B 類型元素;A > B:檢索 A 元素?直接后代?中所有 B 類型元素;A ~ B:檢索 A 元素?兄弟?中所有 B 類型元素。
總結一下,選擇器分為兩大類:
- 基本選擇器:通過元素的?類型、class 屬性值、id 屬性值?檢索;
- 組合選擇器:通過元素和元素之間的?關系?檢索,分為?直接后代組合器、后代組合器?和?兄弟組合器。

我們需要從豆瓣讀書 Top 250 頁面中提取出每本書的?書名、作者?和?出版社?信息。通過檢查元素我們發現,每本書的結構是一致的,并且書名信息都在 a 元素之中:

根據上面學習的方法,什么樣的css選擇器可以定位到書名信息所在的a元素呢?
div.pl2 > a?和?div.pl2 ?a 均可。
select() 方法
BeautifulSoup 對象?有一個名為?select()?的方法,我們將?CSS 選擇器?傳進去,它會返回一個列表,列表中每個元素都是符合條件的檢索結果。
# 前面代碼省略,soup 為解析好的 BeautifulSoup 對象
book_name_tags = soup.select('div.pl2 a')
print(book_name_tags)
# 輸出:
# [<a href="https://book.douban.com/subject/1007305/" onclick=""moreurl(this,{i:'0'})"" title="紅樓夢">
# 紅樓夢
# </a>, <a href="https://book.douban.com/subject/4913064/" onclick=""moreurl(this,{i:'1'})"" title="活著">
# 活著
# </a>, <a href="https://book.douban.com/subject/6082808/" onclick=""moreurl(this,{i:'2'})"" title="百年孤獨">
# 百年孤獨
# </a>, ...]print(type(book_name_tags[0]))
# 輸出:<class 'bs4.element.Tag'>可以看到,所有書名信息所在元素都被我們提取出來了。并且通過打印?book_name_tags?列表第一個元素的數據類型我們發現,它是一個特殊的數據類型,Tag 類。正如我在介紹 BeautifulSoup 對象時說過的,BeautifulSoup 類繼承自 Tag 類。我們通過?select()?方法獲得的一個個節點,是一個個?Tag 對象。
Tag對象
Tag 類有許多實用的屬性和方法,最為常用的是以下三個
- tag.text? 獲取標簽的文本內容
- tag['屬性名']? 獲取標簽 HTML 屬性的值
- tag.select() 方法? 返回被選擇器選助攻的所有元素
是的,Tag 類也有?select()?方法——這是因為,BeautifulSoup 類中的?select()?方法就是繼承自 Tag 類的。除此之外,我們還能通過 Tag 對象的?text?屬性訪問到該元素的?元素內容,通過?Tag對象['元素屬性名稱']?形式訪問到該元素的某個屬性的值。
比如對于?book_name_tags?列表中第一個元素來說
book = book_name_tags[0]
print(book)
# 輸出:
# <a href="https://book.douban.com/subject/1007305/" onclick=""moreurl(this,{i:'0'})"" title="紅樓夢">
# 紅樓夢
# </a>我們可以通過?book.text?獲取元素內容,通過?book['href']?獲取圖書鏈接。
print(book['title'])
# 輸出:紅樓夢同樣的道理,我們可以編寫代碼提取出每本書作者、出版社信息所在元素
# 前面代碼省略,soup 為解析好的 BeautifulSoup 對象
book_info_tags = soup.select('p.pl')
print(book_info_tags)
# 輸出:
# [<p class="pl">[清] 曹雪芹 著 / 人民文學出版社 / 1996-12 / 59.70元</p>, <p class="pl">余華 / 作家出版社 / 2012-8-1 / 20.00元</p>, <p class="pl">[哥倫比亞] 加西亞·馬爾克斯 / 范曄 / 南海出版公司 / 2011-6 / 39.50元</p>, ...]可以看到,書籍信息存在于 p 元素的?文本內容?中,我們可以通過?text?屬性獲取。每條書籍信息則由若干項組成,依次是作者、譯者(如果為外文作品)、出版社、出版年份、圖書價格,每項中間用?/?分割。因此我們在提取圖書作者、出版社信息時可分以下四步:
- 遍歷?
book_info_tags?中每個元素; - 對每個元素,通過?
text?屬性獲取書籍信息,保存到?info?里; - 按?
/?分割?info?字符串,得到列表?info_list; info_list?中?第一項元素?是作者信息,倒數第三項元素?是出版社信息。
# 前面代碼省略,soup 為解析好的 BeautifulSoup 對象
book_info_tags = soup.select('p.pl')
# 遍歷所有書籍信息元素
for info_tag in book_info_tags:# 獲取書籍信息info = info_tag.text# 按“ / ”分割字符串info_list = info.split(' / ')# 結果列表中第一項為作者信息author = info_list[0]# 倒數第三項為出版社信息publisher = info_list[-3]print(author, publisher)# 輸出:
# [清] 曹雪芹 著 人民文學出版社
# 余華 作家出版社
# [哥倫比亞] 加西亞·馬爾克斯 南海出版公司
# ...?下面是整體代碼
# 導入 requests 庫
import requests
# 從 bs4 庫導入 BeautifulSoup
from bs4 import BeautifulSoup# 定制消息頭
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
# 向 https://book.douban.com/top250/ 發送帶消息頭的請求
# 并將響應結果儲存到 res 變量中
res = requests.get("https://book.douban.com/top250/", headers=headers)# 將響應結果的文本內容解析為 BeautifulSoup 對象
# 并保存到變量 soup 中
soup = BeautifulSoup(res.text, 'html.parser')# 所有書名所在元素
book_name_tags = soup.select('div.pl2 a')
# 所有書籍信息所在元素
book_info_tags = soup.select('p.pl')
print(book_info_tags)
# 遍歷每本圖書
for i in range(len(book_name_tags)):# 通過元素 title 屬性提取書名name = book_name_tags[i]['title']# 獲取書籍信息info = book_info_tags[i].text# 按“ / ”分割字符串info_list = info.split("/")# 結果列表中第一項為作者信息author = info_list[0]# 倒數第三項為出版社信息publisher = info_list[-3]# 打印書名、作者、出版社信息print(name, author, publisher)下面是返回的結果
[<p class="pl">[清] 曹雪芹 著 / 人民文學出版社 / 1996-12 / 59.70元</p>, <p class="pl">余華 / 作家出版社 / 2012-8 / 20.00元</p>, <p class="pl">[英] 喬治·奧威爾 / 劉紹銘 / 北京十月文藝出版社 / 2010-4-1 / 28.00</p>, <p class="pl">J.K.羅琳 (J.K.Rowling) / 蘇農 / 人民文學出版社 / 2008-12-1 / 498.00元</p>, <p class="pl">劉慈欣 / 重慶出版社 / 2012-1 / 168.00元</p>, <p class="pl">[哥倫比亞] 加西亞·馬爾克斯 / 范曄 / 南海出版公司 / 2011-6 / 39.50元</p>, <p class="pl">[美國] 瑪格麗特·米切爾 / 李美華 / 譯林出版社 / 2000-9 / 40.00元</p>, <p class="pl">[英] 喬治·奧威爾 / 榮如德 / 上海譯文出版社 / 2007-3 / 10.00元</p>, <p class="pl">林奕含 / 北京聯合出版公司 / 2018-2 / 45.00元</p>, <p class="pl">[明] 羅貫中 / 人民文學出版社 / 1998-05 / 39.50元</p>, <p class="pl">[英] 阿·柯南道爾 / 丁鐘華 等 / 群眾出版社 / 1981-8 / 53.00元/68.00元</p>, <p class="pl">[日] 東野圭吾 / 劉姿君 / 南海出版公司 / 2013-1-1 / 39.50元</p>, <p class="pl">[法] 圣埃克蘇佩里 / 馬振騁 / 人民文學出版社 / 2003-8 / 22.00元</p>, <p class="pl">(丹麥)安徒生 / 葉君健 / 人民文學出版社 / 1997-08 / 25.00元</p>, <p class="pl">金庸 / 生活·讀書·新知三聯書店 / 1994-5 / 96.00元</p>, <p class="pl">三毛 / 哈爾濱出版社 / 2003-8 / 15.80元</p>, <p class="pl">魯迅 / 人民文學出版社 / 1973-3 / 0.36元</p>, <p class="pl">【美】傅高義 (Ezra.F.Vogel) / 馮克利 / 生活·讀書·新知三聯書店 / 2013-1-18 / 88.00元</p>, <p class="pl">[德] 赫爾曼·黑塞 / 姜乙 / 天津人民出版社 / 2017-1 / 32.00元</p>, <p class="pl">[美] 哈珀·李 / 高紅梅 / 譯林出版社 / 2012-9 / 32.00元</p>, <p class="pl">當年明月 / 中國海關出版社 / 2009-4 / 358.20元</p>, <p class="pl">[意] 埃萊娜·費蘭特 / 陳英 / 人民文學出版社 / 2018-7 / 62.00元</p>, <p class="pl">[意] 埃萊娜·費蘭特 / 陳英 / 人民文學出版社 / 2017-4 / 59.00元</p>, <p class="pl">魯迅 / 人民文學出版社 / 1973-3 / 0.20元</p>, <p class="pl">王小波 / 中國青年出版社 / 1997-10 / 27.00元</p>]
紅樓夢 [清] 曹雪芹 著 人民文學出版社
活著 余華 作家出版社
1984 [英] 喬治·奧威爾 北京十月文藝出版社
哈利·波特 J.K.羅琳 (J.K.Rowling) 人民文學出版社
三體全集 劉慈欣 重慶出版社
百年孤獨 [哥倫比亞] 加西亞·馬爾克斯 南海出版公司
飄 [美國] 瑪格麗特·米切爾 譯林出版社
動物農場 [英] 喬治·奧威爾 上海譯文出版社
房思琪的初戀樂園 林奕含 北京聯合出版公司
三國演義(全二冊) [明] 羅貫中 人民文學出版社
福爾摩斯探案全集(上中下) [英] 阿·柯南道爾 1981-8
白夜行 [日] 東野圭吾 南海出版公司
小王子 [法] 圣埃克蘇佩里 人民文學出版社
安徒生童話故事集 (丹麥)安徒生 人民文學出版社
天龍八部 金庸 生活·讀書·新知三聯書店
撒哈拉的故事 三毛 哈爾濱出版社
吶喊 魯迅 人民文學出版社
鄧小平時代 【美】傅高義 (Ezra.F.Vogel) 生活·讀書·新知三聯書店
悉達多 [德] 赫爾曼·黑塞 天津人民出版社
殺死一只知更鳥 [美] 哈珀·李 譯林出版社
明朝那些事兒(1-9) 當年明月 中國海關出版社
失蹤的孩子 [意] 埃萊娜·費蘭特 人民文學出版社
新名字的故事 [意] 埃萊娜·費蘭特 人民文學出版社
野草 魯迅 人民文學出版社
沉默的大多數 王小波 中國青年出版社
?
)



)














