1. 一維數組的創建和初始化
數組是一組相同類型元素的集合。


變長數組是不能初始化的。
數組的初始化是指,在創建數組的同時給數組的內容一些合理初始值(初始化)。

例如上圖
char ch3[ ]="abc";里面方的就是 a b c \0
char ch3[ ]="abc";里面方的就是 a b c \0
對于數組的使用我們之前介紹了一個操作符:[ ],下標引用操作符。它其實就數組訪問的操作符。
總結:
- 數組是使用下標來訪問的,下標是從0開始。
- 數組的大小可以通過計算得到
一維數組在內存中的存儲
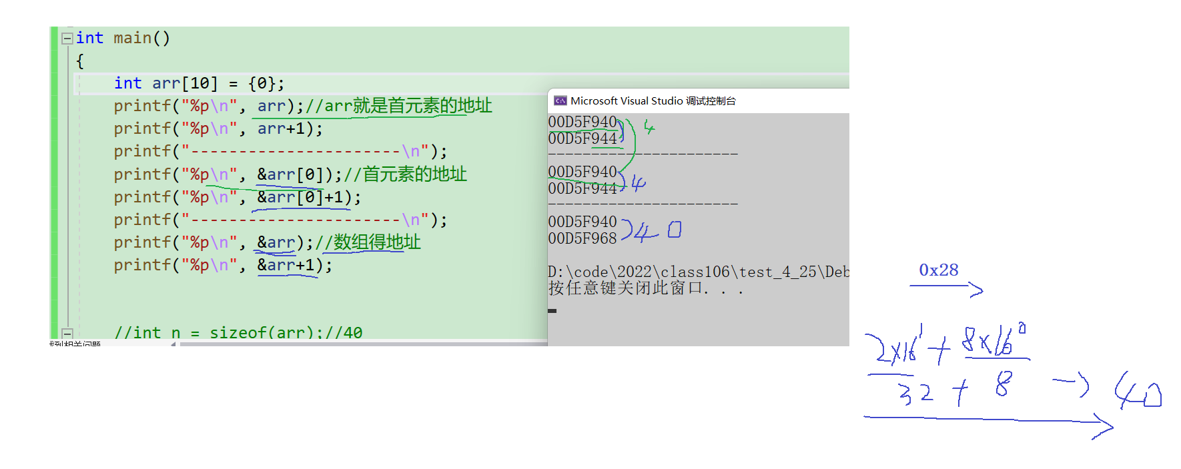
地址和地址之間差四個字節,因為一個整形占4個字節。
隨著數組下標的增長,元素的地址,也在有規律的遞增。
由此可以得出結論:數組在內存中是連續存放的。

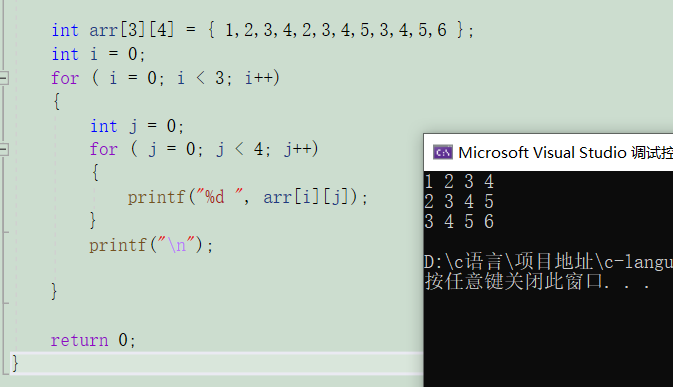
2. 二維數組的創建和初始化



二維數組可以省略行,不能省略列。


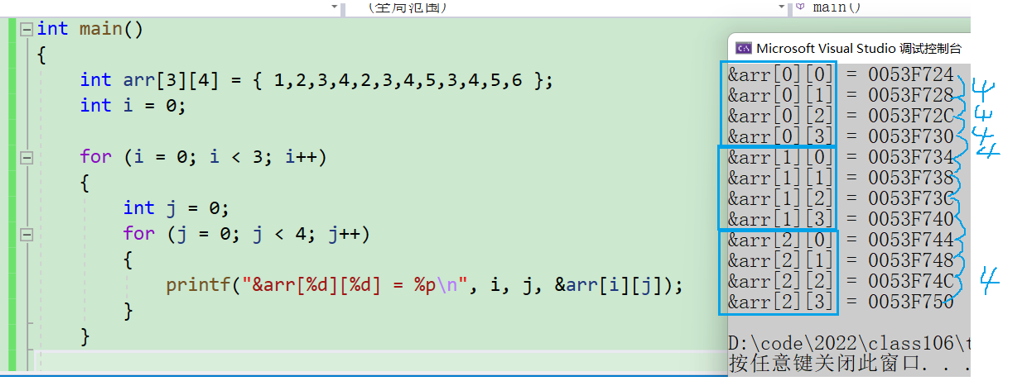
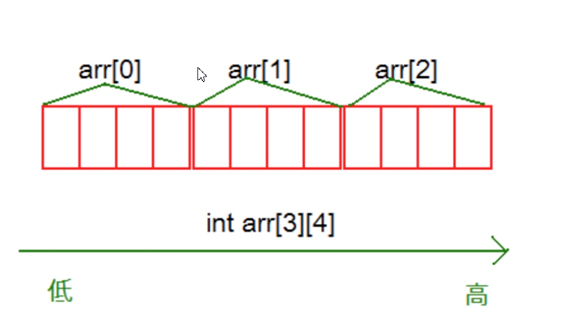
二維數組在內存中也是連續存儲的。
3. 數組越界
數組的下標是有范圍限制的。
數組的下規定是從0開始的,如果數組有n個元素,最后一個元素的下標就是n-1。
所以數組的下標如果小于0,或者大于n-1,就是數組越界訪問了,超出了數組合法空間的訪問。
C語言本身是不做數組下標的越界檢查,編譯器也不一定報錯,但是編譯器不報錯,并不意味著程序就是正確的, 所以程序員寫代碼時,最好自己做越界的檢查。
越界之后打印的是隨機數。
4. 數組作為函數參數
往往我們在寫代碼的時候,會將數組作為參數傳個函數,比如:我要實現一個冒泡排序(這里要講算法 思想)函數。將一個整形數組排序。
冒泡排序的核心思想:兩個相鄰的元素進行比較。
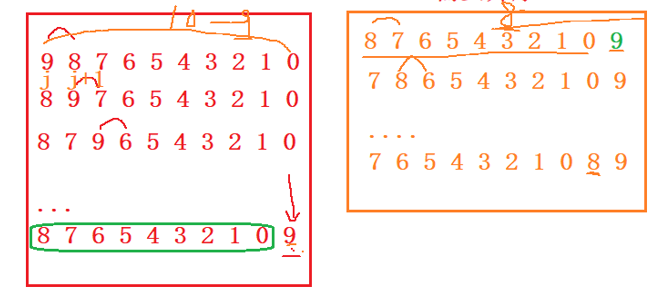
一趟冒泡排序讓一個數據來到它最終應該出現的位置上!
10個元素需要9次。
n個元素需要n-1次冒泡排序。
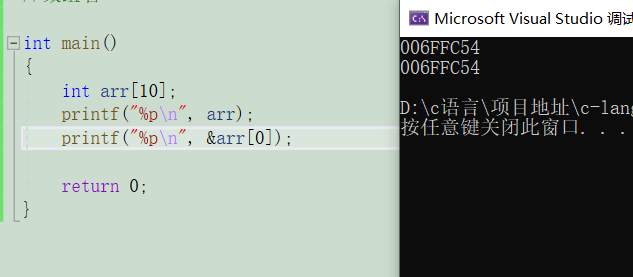
數組名本質上是:數組首元素的地址

//數組傳參的時候,形參有2種寫法:
//1.數組
//2.指針//形參是數組的形式
void bubble_sort(int arr[],int sz)
{int i = 0;for ( i = 0; i < sz-1; i++){//一次冒泡排序int j = 0;for ( j = 0; j < sz-1-i; j++){if (arr[j] > arr[j + 1]){//交換int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}}int main()
{//把數組的數據排列成升序int arr[] = { 9,8,7,6,5,4,3,2,1,0 };//降序int sz = sizeof(arr) / sizeof(arr[0]);//冒泡排序的算法,對數組進行排序bubble_sort(arr,sz);int i = 0;for ( i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}//形參是指針的形式
void bubble_sort(int* arr,int sz)
{int i = 0;for ( i = 0; i < sz-1; i++){//一次冒泡排序int j = 0;for ( j = 0; j < sz-1-i; j++){if (arr[j] > arr[j + 1]){//交換int tmp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tmp;}}}}int main()
{//把數組的數據排列成升序int arr[] = { 9,8,7,6,5,4,3,2,1,0 };//降序int sz = sizeof(arr) / sizeof(arr[0]);//冒泡排序的算法,對數組進行排序bubble_sort(arr,sz);int i = 0;for ( i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}5.數組名是什么?
數組名確實能表示首元素的地址。
但是又兩個例外:
1.sizeof(數組名),這里的數組名表示整個數組,計算的是整個數組的大小,單位是字節。
2.&數組名,這里的數組名表示整個數組,取出的是整個數組的地址。

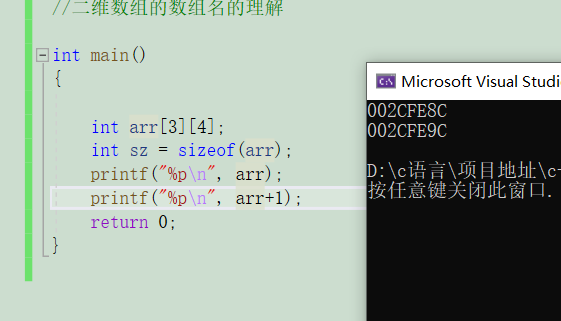
二維數組的數組名也表示首元素的地址。
表示的這一行的地址
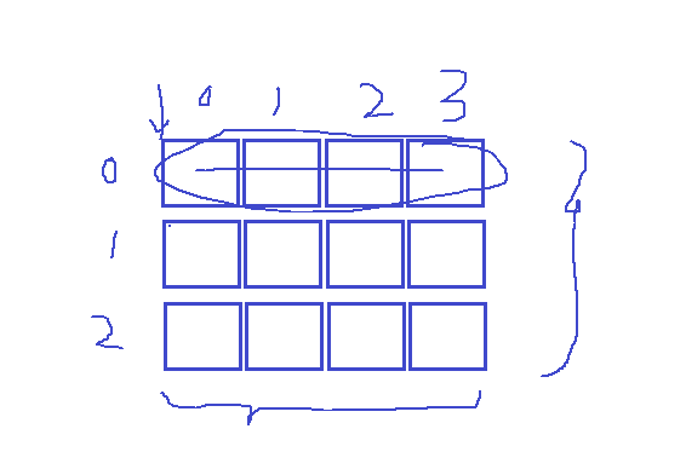
中間隔了十六個字節,也就是四個數值。
行列計算










![[python]Markdown圖片引用格式批處理桌面應用程序](http://pic.xiahunao.cn/[python]Markdown圖片引用格式批處理桌面應用程序)

)
?)
)


)


