引言
這篇文章將給大家講解關于DolphinScheduler與AWS的EMR和Redshift的集成實踐,通過本文希望大家能更深入地了解AWS智能湖倉架構,以及DolphinScheduler在實際應用中的重要性。
AWS智能湖倉架構
首先,我們來看一下AWS經典的智能湖倉架構圖。

這張圖展示了以S3為核心的數據湖,圍繞數據湖的是各種組件,包括數據庫、Hadoop的EMR、大數據處理、數據倉庫、機器學習、日志查詢和全文檢索等。
這些組件形成一個完整的生態系統,確保數據能夠在企業內部自由流動,無論是從外圍到核心,還是從核心到外圍。
智能湖倉架構的核心目標是實現數據在各個組件之間的自由移動,提升企業數據處理的靈活性和效率。
數據源與數據采集工具
為了讓大家更直觀地理解這張圖,我們可以從左到右進行解讀。左側是各種數據源,包括數據庫、應用程序以及數據采集和攝入工具。
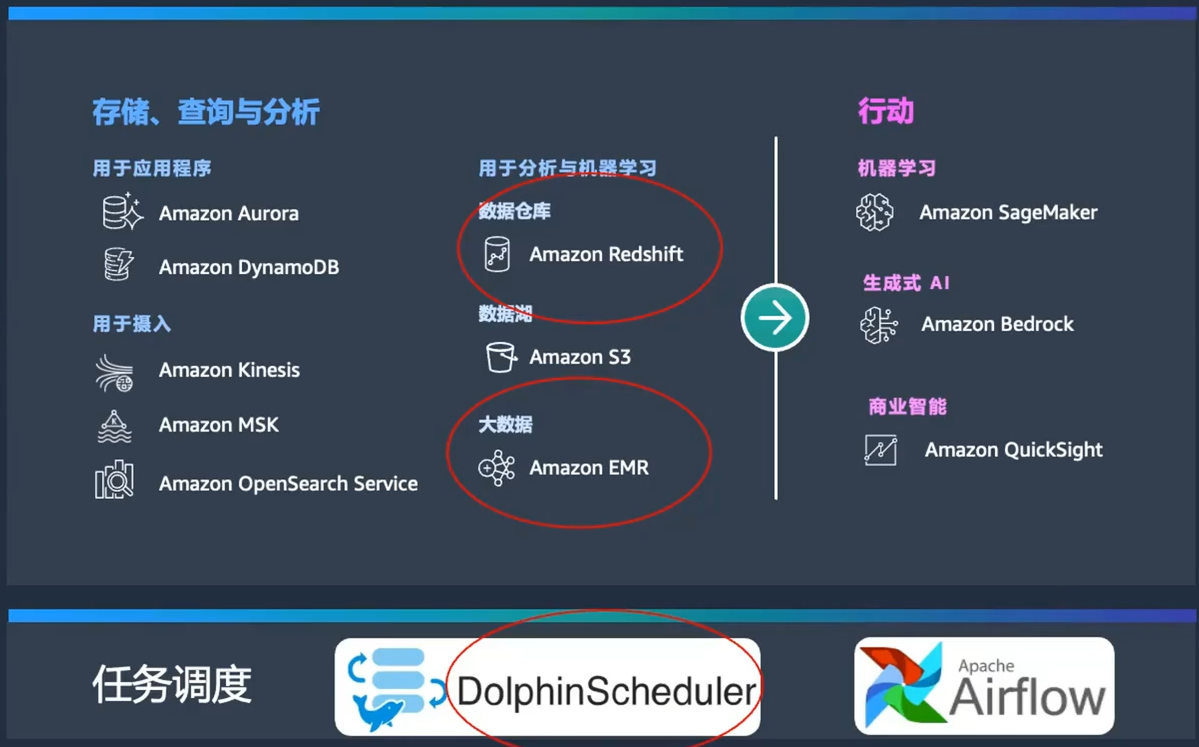
這些工具包括Kinesis、MSK(托管的Kafka)和OpenSearch,都是用于高效數據攝入的優秀工具。
核心組件介紹
今天的主角是圖中圈起來的幾個關鍵組件:
- Redshift:用于數據倉庫的解決方案。
- EMR:Hadoop生態圈的大數據處理組件。
- DolphinScheduler:任務調度工具。
在大數據處理的下游,還包括BI(商業智能)、傳統機器學習和最新的生成式AI,再往下是企業中的人、應用和設備。這張圖展示了整個數據處理和分析的流程,使得數據處理過程更加直觀和流暢。
今天的分享主要圍繞以下兩個核心點展開:
- EMR與DolphinScheduler的實踐
- Redshift與DolphinScheduler的實踐
在此之前,我們先對EMR做一個簡要介紹。
Amazon EMR 簡介
Amazon EMR(Elastic MapReduce)是亞馬遜云技術提供的一款云端服務,用于輕松運行Hadoop生態圈的各類組件,包括Spark、Hive、Flink、HBase等。
其主要特點包括:
- 及時更新:緊跟開源社區的最新版本,30天內提供最新的開源版本更新。
- 自動彈性擴容和縮容:根據工作負載自動調整集群規模。
- 多種計價模式:靈活組合使用不同的計價模式,實現極致性價比。
EMR與自建Hadoop集群的比較
相比于傳統IDC機房自建Hadoop集群,EMR具有以下優勢:
- 充分發揮原生特性
- 多種計價模式組合使用
- 自動彈性擴容和縮容
成本分析
在使用Hadoop進行數據分析和大數據處理時,企業越來越關注成本控制,而不僅僅是性能。
下圖展示了企業在IDC機房自建Hadoop集群的成本構成,包括服務器成本、網絡成本、人工維護成本以及其他額外費用。這些成本往往非常高。
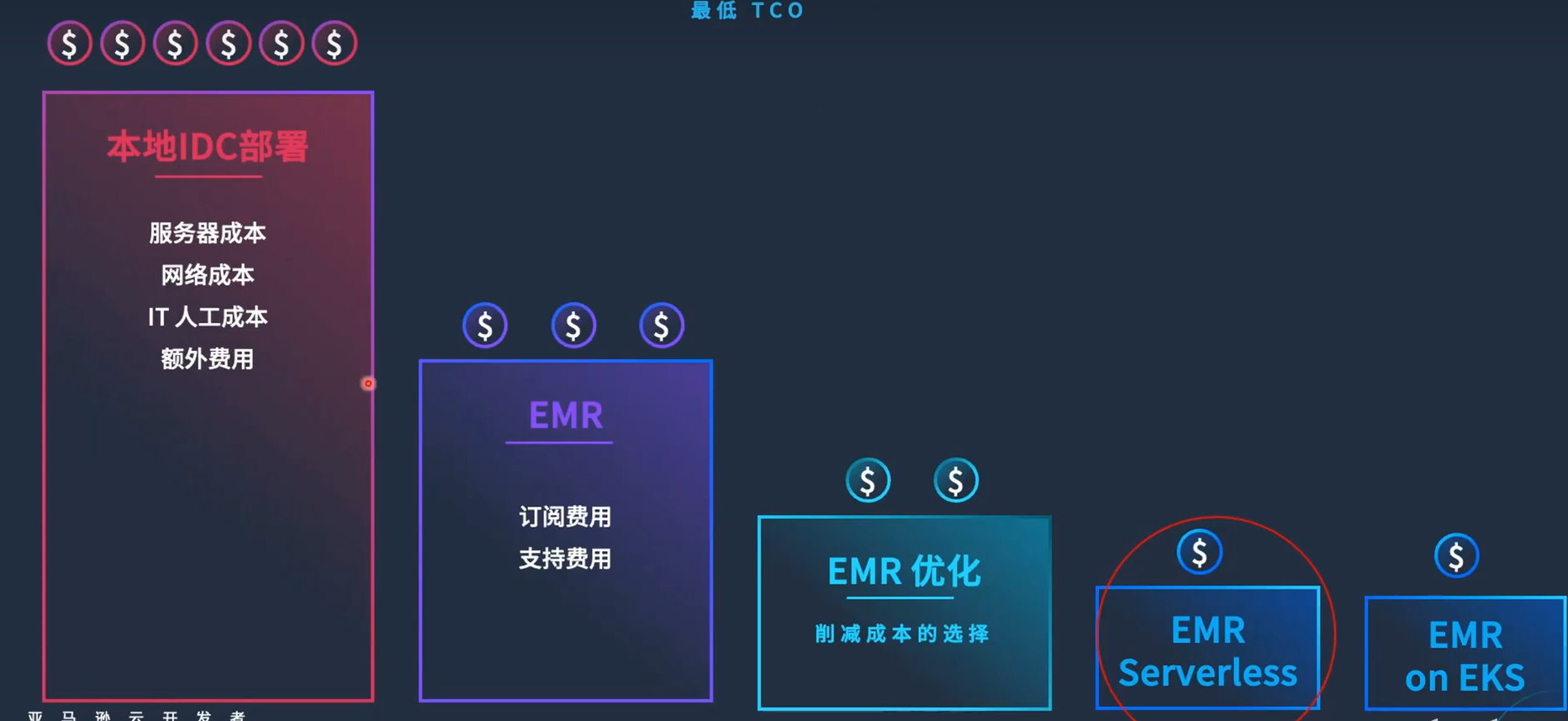
遷移到EMR的優勢
許多企業由于本地擴容困難、長周期采購流程以及升級困難等原因,逐漸將Hadoop工作負載遷移到云上的EMR。
通過支付訂閱費用和額外支持費用,企業可以享受到以下優勢:
- 靈活的計價模式組合
- 自動彈性伸縮
- 參數調優
進一步優化
在完成初步優化后,部分企業可能仍覺得不滿足其性價比的要求,進而轉向使用EMR Serverless和EMR on EKS。這兩者本質上都是基于容器化技術,旨在實現更高的性價比。
EMR Serverless
EMR Serverless讓企業擺脫了對硬件和基礎設施的維護,更加關注上層應用和業務開發,用戶只需設置應用程序代碼和相關參數即可。
EMR on EKS
EMR on EKS通過在Kubernetes上構建Hadoop集群,包括Spark和Flink等組件,進一步優化性價比。
不僅能提高數據處理的效率和靈活性,也使得企業能夠更好地控制成本,實現業務目標。
實踐案例分享:從IDC遷移到AWS EMR
接下來通過一個真實案例,分享一個客戶從IDC遷移到AWS EMR的優化過程。這將幫助大家了解在云上使用EMR和DolphinScheduler的具體實踐,以及如何通過這些工具實現性能和成本的雙重優化。
客戶背景與挑戰
該客戶原本在IDC機房采用CDH(Cloudera Distribution Hadoop),自建了一個Hadoop集群,共有13個節點。某個任務在機房內需要13個小時才能完成。客戶希望通過遷移到云上,降低成本并提升效率。
遷移與優化過程
初始遷移
客戶將其工作負載遷移到AWS云上,采用EMR On EC2。在遷移后的初始階段,使用Hive on EMR,僅用了6個節點,任務時間縮短至10小時。此時并未進行任何調優。
接著,客戶將Hive切換為Spark,仍使用6個節點,任務時間進一步縮短至3.5小時。
通過開啟EMR的彈性伸縮功能,并將數據格式轉換為parquet,任務時間進一步縮減至2.4小時。
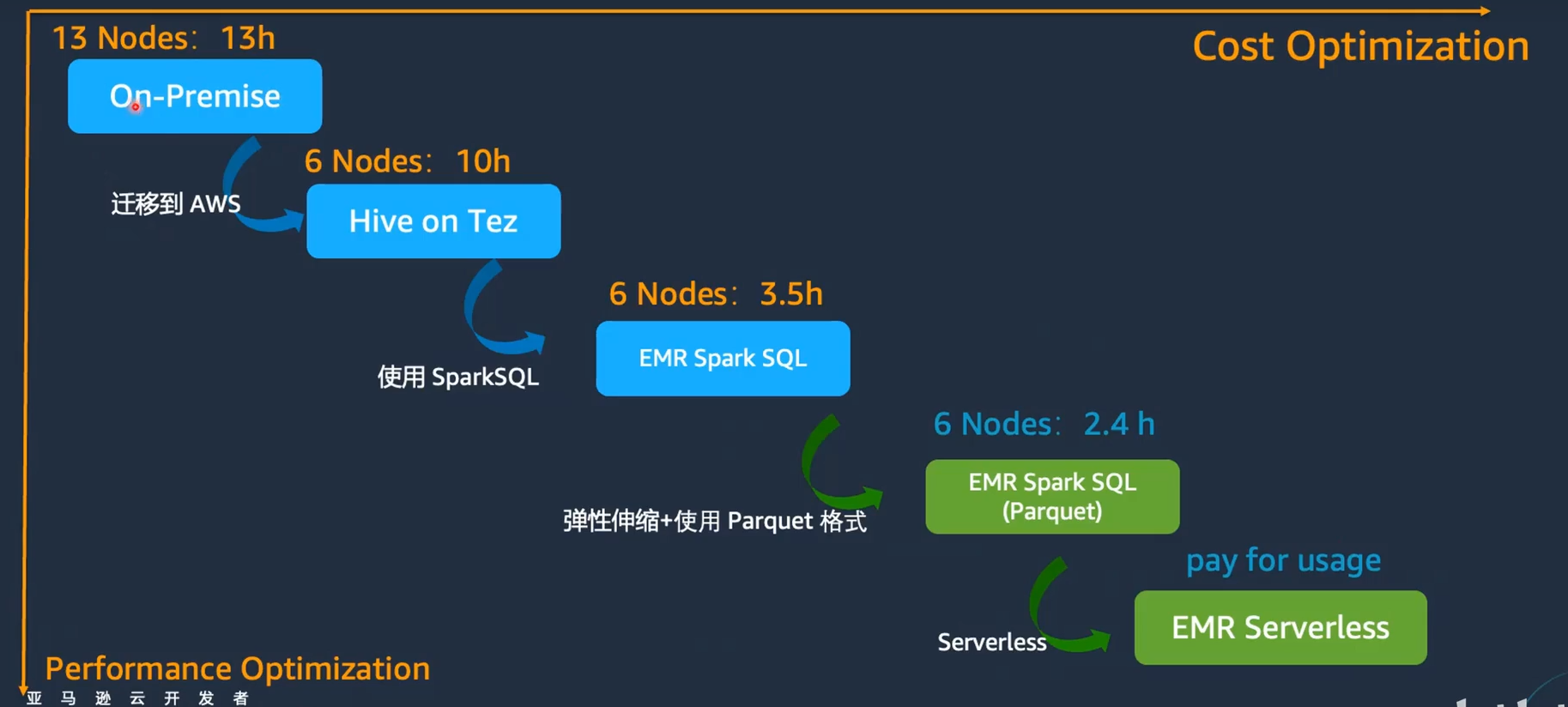
最終優化
客戶實現了集群版EMR與EMR Serverless的混合使用,將部分工作負載遷移到EMR Serverless上,達到了極致的性價比,性能優化在很大程度上也代表了成本優化。
調度優化與實踐
遷移后的調度方式
在遷移到云上的EMR On EC2后,客戶的調度方式如下:
- 任務分布在24小時內,小任務每個大約需要20-30分鐘。
- 較大的任務集中在一天的7小時內執行。
- 超級大的任務執行時間為3-5天,甚至一周,一次執行一個月可能只需要運行兩三次。
優化調度
通過Apache DolphinScheduler,客戶將工作負載分別調度到EMR On EC2和EMR Serverless上。
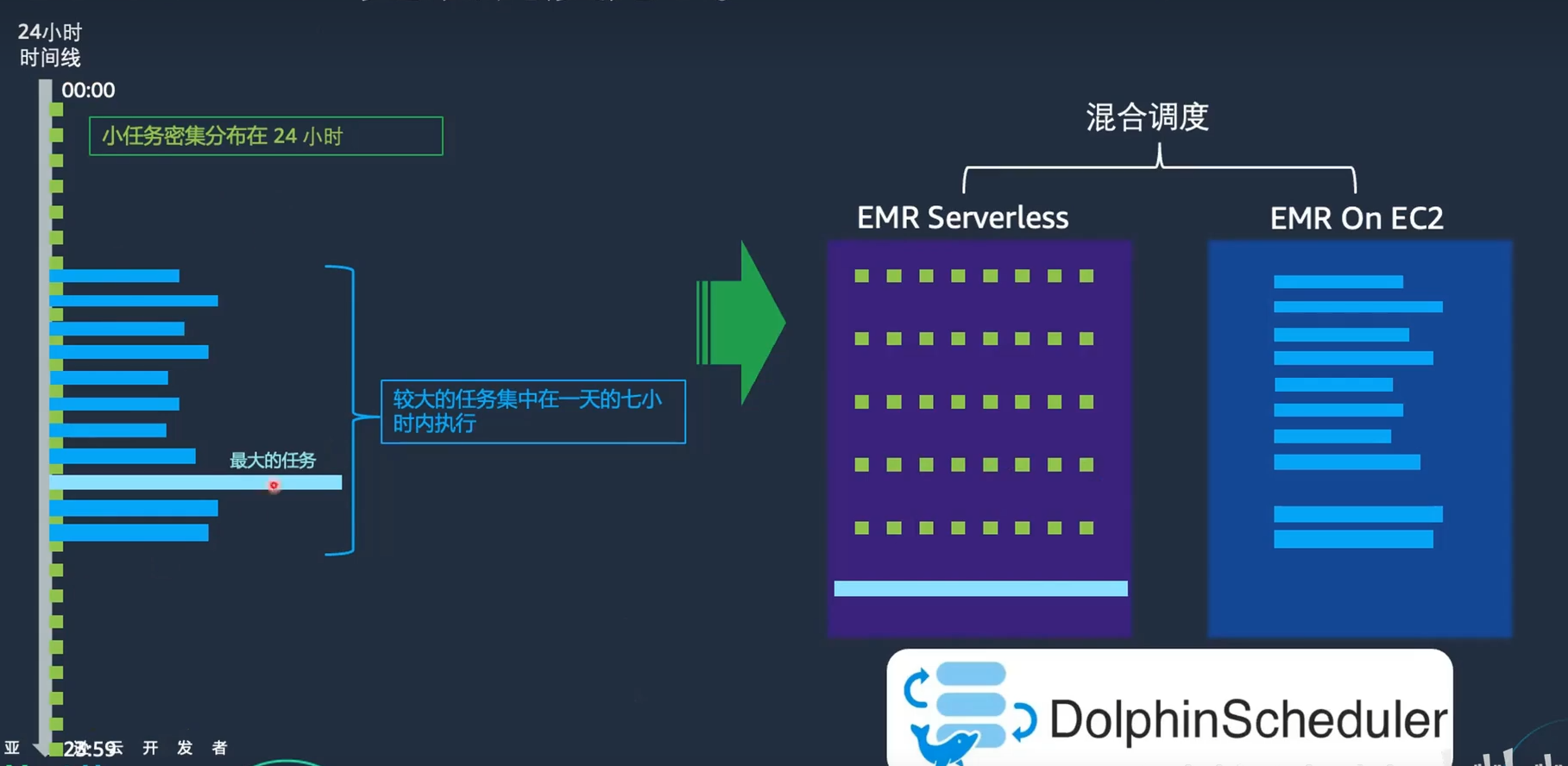
具體做法如下:
- 小任務:放到EMR Serverless上,因為這些任務不需要3-4臺節點,10GB-20GB內存即可滿足需求。
- 大任務:繼續保留在EMR On EC2上,因為這些任務在云上運行時間相對集中,則可以集群定時開關,降低成本。
- 超級大任務:放到EMR Serverless上,通過監控每次運行的CPU和內存消耗,,將每次任務運行的成本可視化,便于針對性地、持續地進行成本優化。
統一元數據管理
使用AWS Glue作為統一的元數據管理工具,使得集群的創建、銷毀、再創建過程無需恢復元數據或數據,同一份數據和元數據可以在EMR On EC2和EMR Serverless之間無縫使用。
挑戰與解決方案
在此過程中,我們也遇到了一些挑戰:
- 異步提交問題:EMR Serverless目前僅支持異步提交,而批處理任務需要同步執行。我們通過封裝Python類庫,實現了統一的API接口,解決了這個問題。
- 日志查看不一致:EMR和EMR Serverless的日志查看方式不同。通過DolphinScheduler,我們實現了統一的日志下載和查看,改善了客戶體驗。
- API接口差異:EMR和EMR Serverless的API接口不同。我們通過封裝統一的API接口,減少了客戶的維護成本。
- SQL提交限制:EMR Serverless暫時不支持直接提交SQL。我們通過Python腳本,間接實現了SQL提交。
解決方案實施
我們和客戶一起封裝了一個Python類庫,通過這個類庫,統一了EMR On EC2和EMR Serverless的任務提交、日志查詢和狀態查詢接口。在DolphinScheduler中,客戶可以通過統一的API無縫地的在EMR Serverless 和 EMR on EC2 之間切換工作負載。
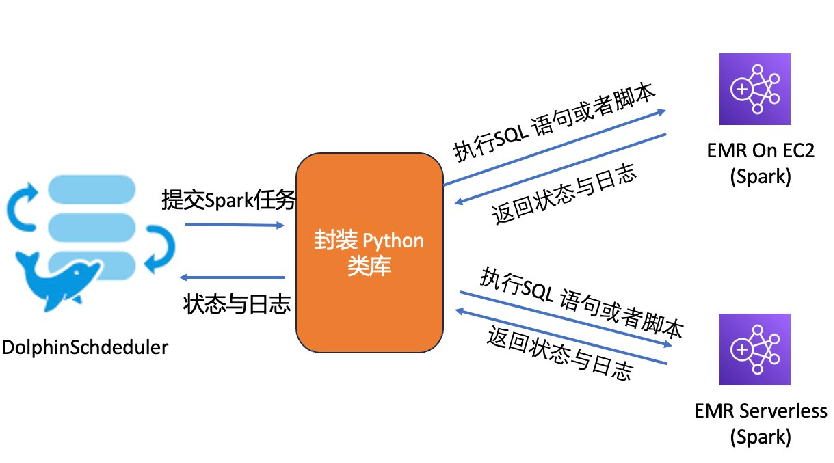
例如,在DolphinScheduler上調度到EMR On EC2時,腳本如下:
from emr_common import Sessionsession_emr = Session(job_type=0)
session_emr.submit_sql("job_name","your_sql_query")
session_emr.submit_file("job_name","your_pyspark_script")
而調度到EMR Serverless時,腳本如下:
from emr_common import Sessionsession_emrserverless = Session(job_type=1)
session_emrserverless.submit_sql("your_sql_query")
session_emrserverless.submit_file("job_name","your_pyspark_script"通過Apache DolphinScheduler的參數傳遞特性,整個代碼可以在不同引擎之間自由切換,實現了無縫調度。除了基本的job type參數之外,還有許多其他參數可供配置。
為了簡化用戶操作,系統為大部分參數設置了默認值,因此用戶通常不需要手動配置這些參數。
例如,用戶可以指定任務執行的集群,如果不指定,系統將默認選擇第一個活躍的應用或集群ID。
此外,用戶還可以為每個Spark任務設置driver和executor的相關參數。如果不指定這些參數,系統也會使用默認值。
封裝Session
為了實現簡化操作,我們封裝了一個session對象,這個session包含兩個子類:EMRSession和EMRServerlessSession。
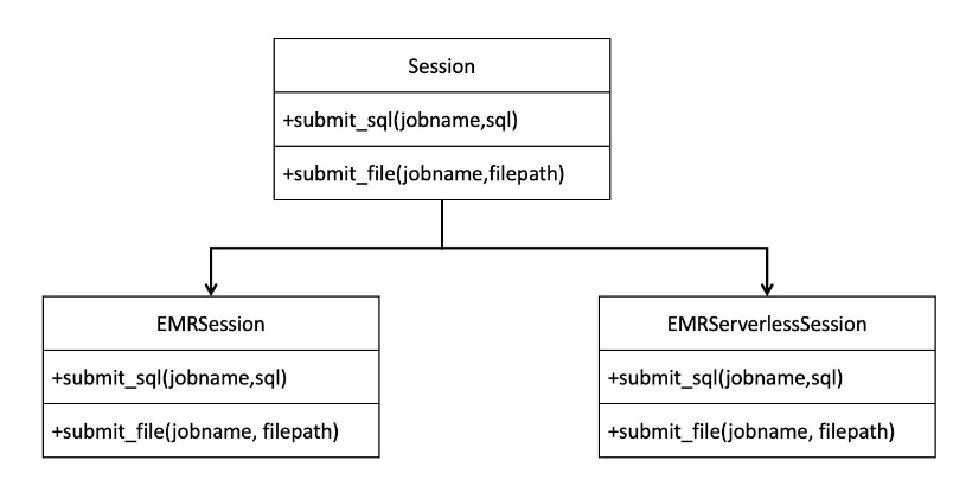
根據傳入參數的不同,系統會創建相應的session對象,無論是提交SQL語句還是腳本文件,其接口從上到下都是一致的。
使用體驗
下面通過一些DolphinScheduler的截圖來展示其使用體驗。
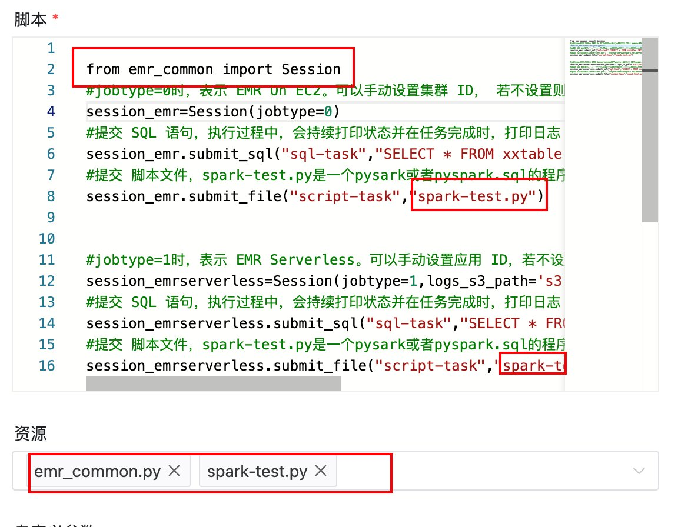
上圖是DolphinScheduler上的一個Python Operator示例,包含了EMR On EC2和EMR Serverless的代碼:
from emr_common import Session# EMR On EC2
session_emr = Session(job_type=0)
session_emr.submit_sql("job_name","your_sql_query")
session_emr.submit_file("job_name","your_pyspark_script")# EMR Serverless
session_emrserverless = Session(job_type=1)
session_emrserverless.submit_sql("your_sql_query")
session_emrserverless.submit_file("job_name","your_pyspark_script"實際效果
通過上述優化,客戶不僅大幅縮短了任務運行時間,還實現了成本的大幅節約。
例如,在未調優情況下,任務時間從13小時縮短到10小時,而經過多次優化后,最終任務時間縮短到2.4小時,同時實現了集群版本EMR和Serverless版本的混合使用。
通過這個案例,我們可以看到,通過使用AWS EMR和DolphinScheduler,企業可以在保證性能的同時,大幅降低成本,實現更高的性價比。希望這個案例能為大家在云上進行大數據處理和優化提供一些借鑒和參考。
Redshift 實踐分享
Redshift是AWS推出的云數據倉庫,已經存在十多年,是業界最成熟的云數據倉庫之一。通過Redshift,用戶可以實現數據倉庫、數據湖和數據庫的無縫集成。
Redshift簡介
Redshift是一款分布式數據倉庫產品,支持以下功能:
- 聯合查詢與聯邦查詢:直接查詢MySQL等關系數據庫的數據,無需通過ETL導入Redshift。
- 與S3數據湖的集成:通過Redshift Spectrum,直接查詢S3上的parquet等格式的數據,而無需將數據導入Redshift。
- 與機器學習的集成:在沒有機器學習經驗的情況下,通過寫SQL就能快速且自動地完成特征工程與模型訓練,然后進行趨勢預測、銷售預測、異常檢測等應用。
Redshift不僅支持集群部署,還提供Serverless模式,在這種模式下,用戶無需管理負載和資源擴展,只需關注SQL代碼和數據開發應用,進一步地簡化了數據開發的門檻,讓大家更加專注業務層面的開發,而不要去關注過多的關注底層的運維。

自3.0版本起,DolphinScheduler支持Redshift數據源。通過DolphinScheduler的SQL Operator,用戶可以直接編寫Redshift的SQL,進行大數據開發和應用。
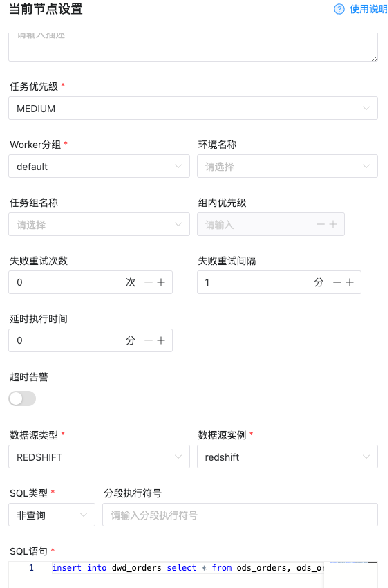
用戶可以通過拖拽界面操作,輕松定制DAG并監控各個任務和流程的執行情況。
并發控制
Redshift是一個OLAP數據庫,具有高吞吐量和快速計算的特點,但其并發擴展通常不超過50。這對于調度大量并發任務的客戶來說是一個挑戰。
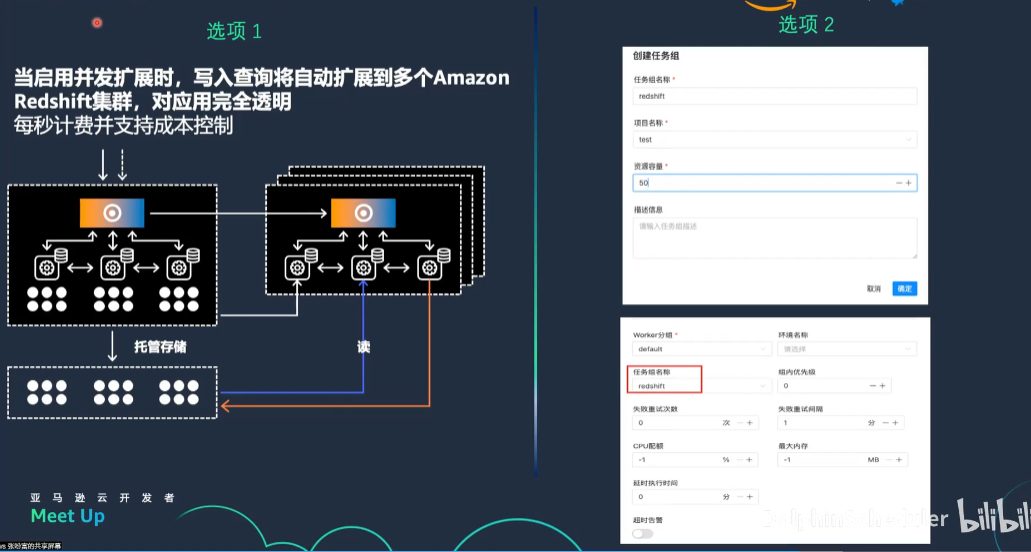
為了解決這一問題,有兩個選項:
- 開啟Redshift并發擴展:擴展到預置資源的10倍容量,但會增加額外成本。
- 使用DolphinScheduler的并發控制功能:創建任務組,設定資源容量,控制調度到Redshift的任務并發,避免集群過載。
Shell Operator實踐
在使用DolphinScheduler進行Redshift開發時,推薦使用SQL Operator,但也可以使用Shell Operator,通過sql - fxxx.sql 命令執行SQL文件。
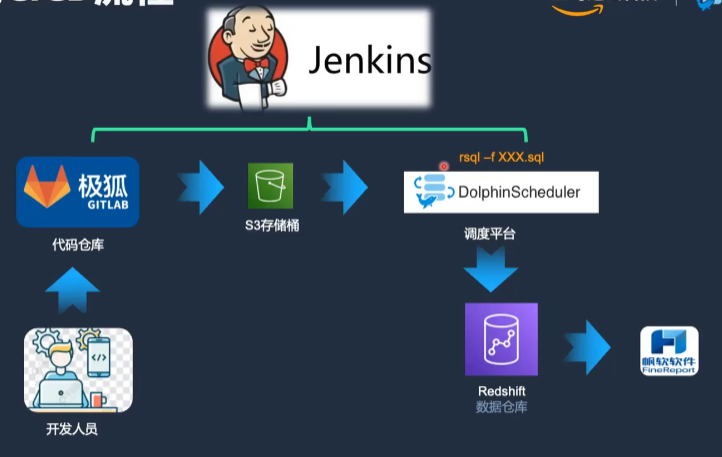
這種做法的好處在于可以與CICD流程集成。開發人員可以在個人電腦上通過GitLab開發代碼,提交后自動上傳到S3桶,DolphinScheduler支持從S3桶讀取代碼文件,并提交到Redshift中執行。
比如說通過Jenkins實現了代碼推送到GitLab后,自動上傳到S3存儲桶。在DolphinScheduler的資源中心創建文件后,自動向S3寫文件,并更新DolphinScheduler的元數據,實現了CICD的無縫集成。
總結
今天我們分享了EMR與EMR Serverless和DolphinScheduler的整合經驗和實踐,以及Redshift與DolphinScheduler的集成實踐。以下是我個人對DolphinScheduler社區的期望和展望:
- SQL語法樹解析生成血緣關系:希望DolphinScheduler能提供基于SQL語法樹解析生成的數據血緣關系,尤其是字段級別的血緣關系。
- 引入AI agent編排流程:希望未來DolphinScheduler能考慮引入AI agent的編排流程,或引入AI agent的Operator。

感謝大家的觀看,如果想了解更多詳情,歡迎加小助手進群交流。
本文由 白鯨開源科技 提供發布支持!







)






)

 Redis(6379) 端口)


