1 介紹
機器遺忘(Machine Unlearning)是指從機器學習模型中安全地移除或"遺忘"特定的數據點或信息。這個概念源于數據隱私保護的需求,尤其是在歐盟通用數據保護條例(GDPR)等法規中提出的"被遺忘的權利"(Right to be Forgotten)。機器遺忘的目標是確保一旦用戶請求刪除其個人數據,相關的機器學習模型也能夠相應地更新,以確保不再利用這些數據進行預測或分析。
具體來說,機器遺忘包括以下幾個關鍵點:
- 數據點的移除:從訓練數據集中刪除特定的數據點,同時確保模型的泛化能力不受影響。
- 模型更新:在數據點被移除后,對模型進行更新,以反映數據的變更,這可能涉及到重新訓練或使用更高效的更新技術。
- 隱私保護:確保在數據被遺忘后,模型不會保留任何可以追溯到被遺忘數據的信息,從而保護用戶的隱私。
- 法律遵從:滿足法律法規對于數據刪除和隱私保護的要求。
本文介紹了機器遺忘技術的分類、優缺點、威脅、攻擊、防御機制以及評估方法。首先將機器遺忘技術分為精確遺忘和近似遺忘兩大類,并對每類中的不同方法進行了詳細討論。精確遺忘技術涉及SISA結構、圖模型、k-Means和聯邦學習等,而近似遺忘技術則基于影響函數、重新優化、梯度更新和特定于圖數據的方法。此外指出這些技術在存儲、假設、模型效用、計算成本和處理動態數據方面的局限性。

2 機器遺忘技術分類
2.1 技術分類
2.1.1 精確遺忘
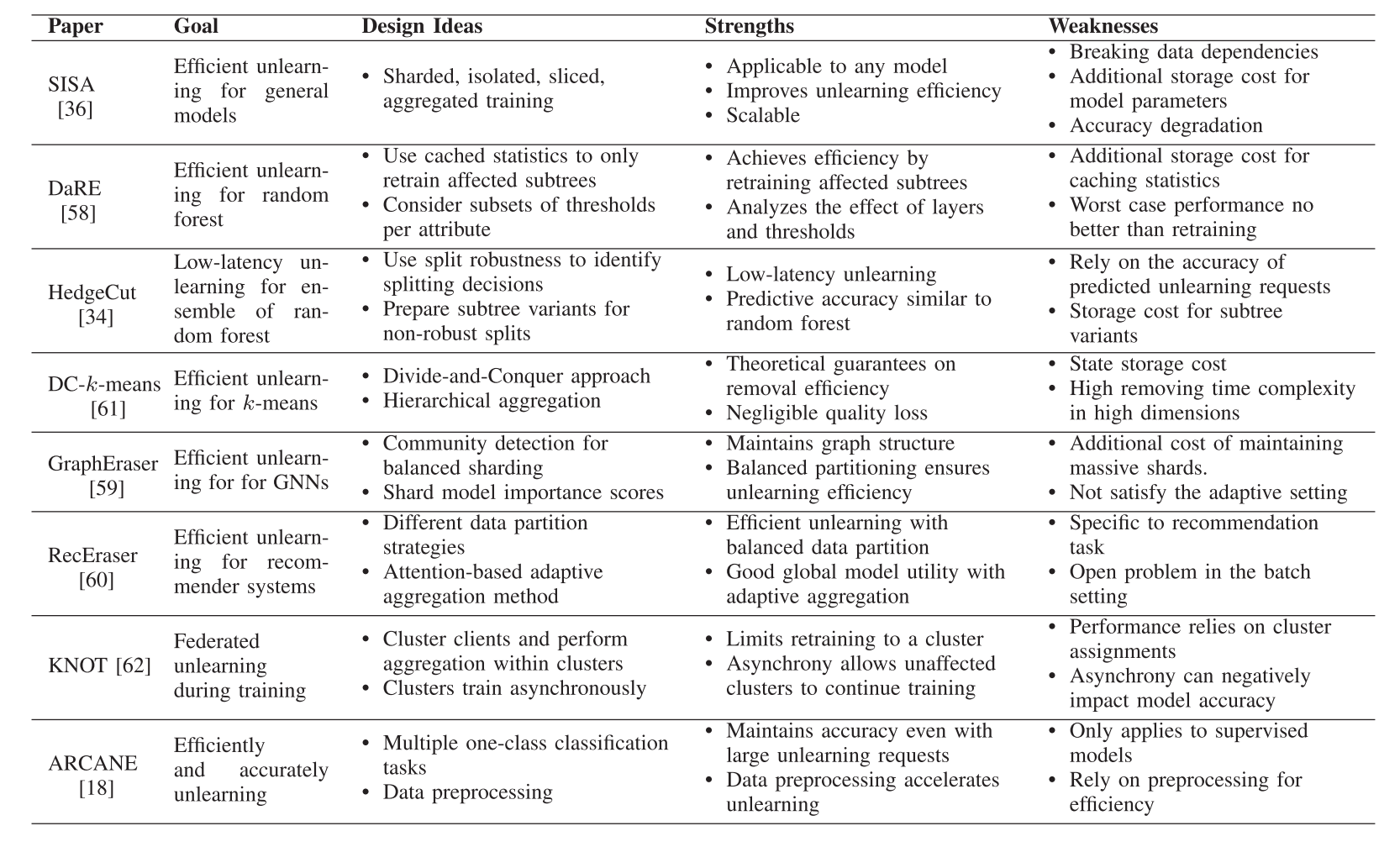
(1)基于SISA結構的精確遺忘
- 隨機森林的精確遺忘:討論了如何將SISA框架應用于隨機森林模型,特別是DaRE森林和HedgeCut方法,它們通過不同的策略來提高遺忘效率和降低延遲。
- 基于圖的模型的精確遺忘:由于圖數據的相互連接特性,提出了GraphEraser和RecEraser方法,這些方法擴展了SISA框架以適應圖數據結構。
- k-Means的精確遺忘:DC-k-means方法采用了類似SISA的框架,但使用了樹狀分層聚合方法。
- 聯邦學習的精確遺忘:KNOT方法采用了SISA框架,實現了客戶端級別的異步聯邦遺忘學習。
(2)非SISA的精確遺忘
- 統計查詢學習:Cao等人提出了一種中介層“求和”,通過更新求和來實現數據點的移除。
- 聯邦學習的快速重訓練:Liu等人提出了一種快速重訓練方法,利用一階泰勒近似技術和低代價的Hessian矩陣近似方法來減少計算和通信成本。
(3)精確遺忘方法的優缺點
- 附加存儲成本:精確遺忘方法通常需要大量的額外存儲空間來緩存模型參數、統計數據或中間結果。例如,SISA框架需要存儲每個數據分片的模型參數,而HedgeCut需要存儲子樹變體。這限制了在大型模型或頻繁遺忘請求中的可擴展性。
- 強假設:一些方法對學習算法或數據特性有強烈的假設。例如,SISA可能在處理高度依賴的數據時表現不佳,而統計查詢學習要求算法能夠以求和形式表達。特定于某些模型的方法,如DaRE、HedgeCut、GraphEraser和RecEraser,適用性有限。
- 模型效用:盡管大多數方法聲稱在遺忘后能夠保持準確性,但缺乏在不同設置下的徹底分析。需要對不同模型、數據集和移除量進行嚴格的評估,以提供具體的效用保證。
- 計算成本:精確遺忘方法在初始訓練期間增加了計算成本,因為需要訓練多個子模型并進行聚合。當計算資源有限時,這可能不可行。
- 處理動態數據:現有方法主要集中在固定訓練集上移除數據。處理動態變化的數據,以及持續的插入和移除請求,仍然是一個開放問題。
- 選擇和實用性:盡管現有的精確遺忘方法能夠高效準確地移除數據,但它們在存儲、假設、效用維持和可擴展性方面存在局限性。選擇最合適的方法取決于應用的具體要求,包括數據類型、模型類型、可用資源,以及效率和準確性之間的期望平衡。
2.1.2 近似遺忘
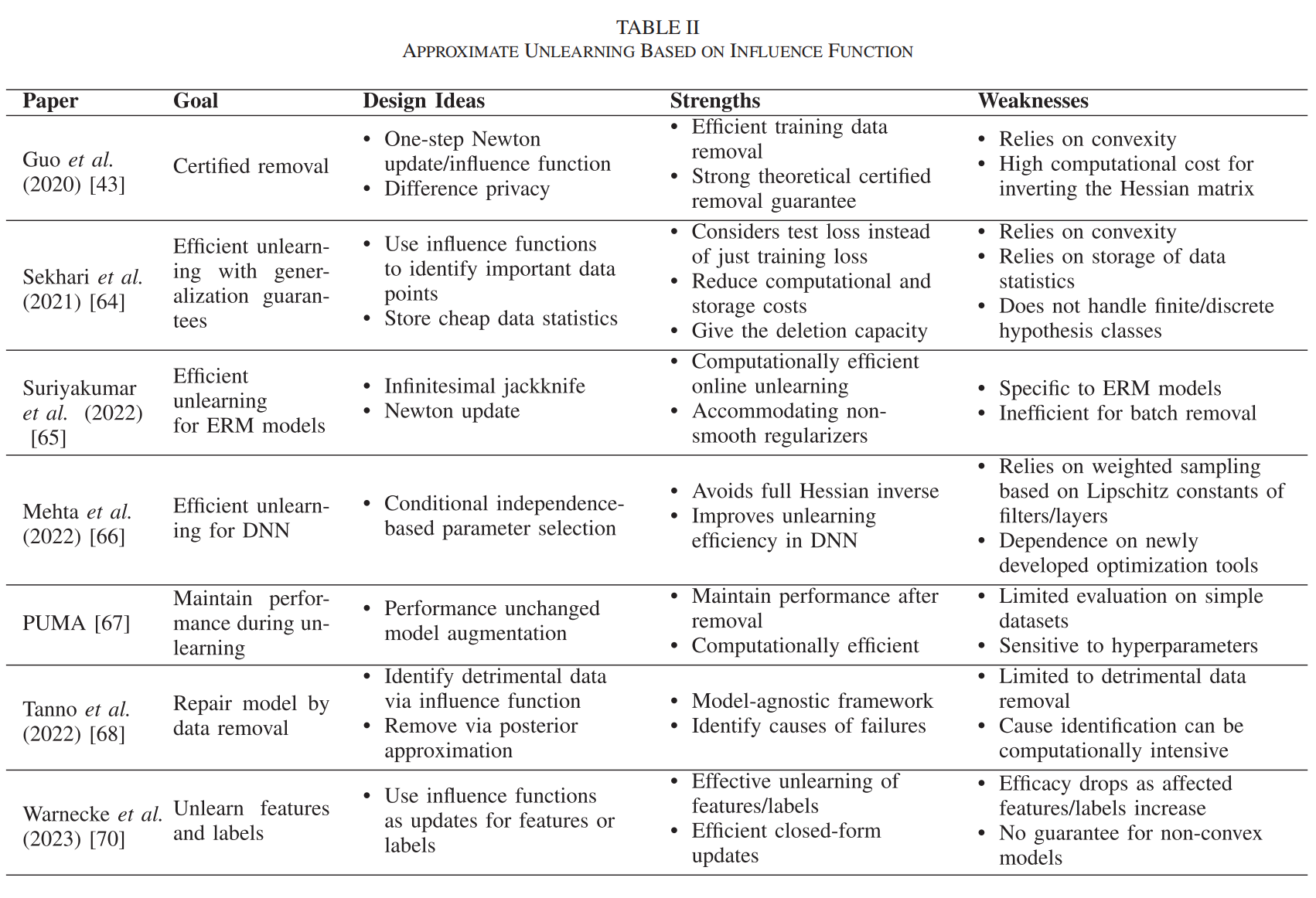
(1)基于移除數據的影響函數的近似遺忘
原理:這種方法通過計算被移除數據點對模型參數的影響,然后更新模型參數以減少這些數據點的影響。影響函數衡量了單個訓練樣本對模型預測的影響。
代表性算法:Guo等人提出的算法利用影響函數進行數據移除,并實現了L2正則化線性模型的認證移除。Sekhari等人的工作通過使用訓練數據的統計信息來減少存儲和計算需求。
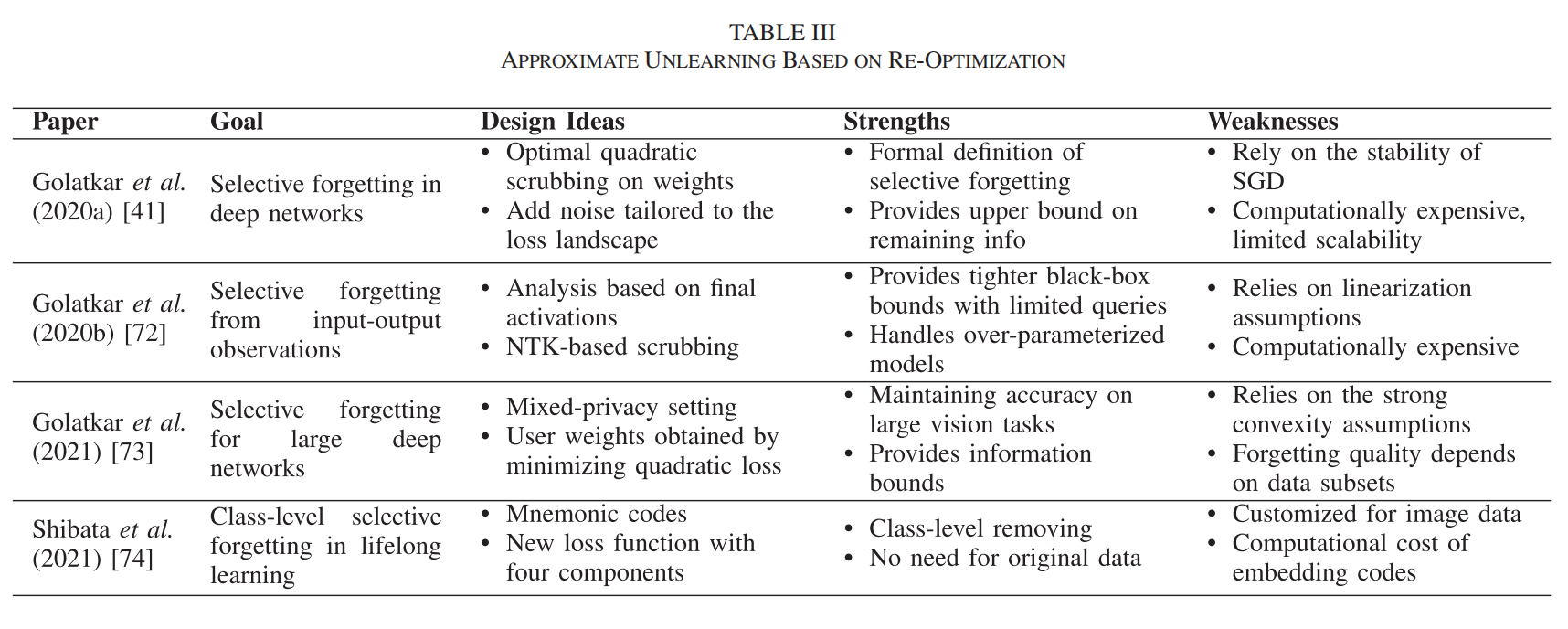
(2)基于移除數據后的重新優化的近似遺忘
原理:此方法首先在完整數據集上訓練模型,然后定義一個新的損失函數以在保留的數據上維持準確性,并通過重新優化過程來最小化這個新的損失函數,從而實現對特定數據點的遺忘。
代表性算法:Golatkar等人提出的選擇性遺忘算法通過修改網絡權重,使得被遺忘數據的分布與從未訓練過這些數據的網絡權重分布不可區分。
(3)基于梯度更新的近似遺忘
原理:在這種方法中,通過對新數據執行少量梯度更新步驟來適應模型參數的小變化,而無需完全重新訓練模型。
代表性算法:DeltaGrad算法利用緩存的梯度和參數信息來快速適應小的訓練集變化。FedRecover算法從被污染的模型中恢復準確的全局模型,同時最小化客戶端的計算和通信成本。

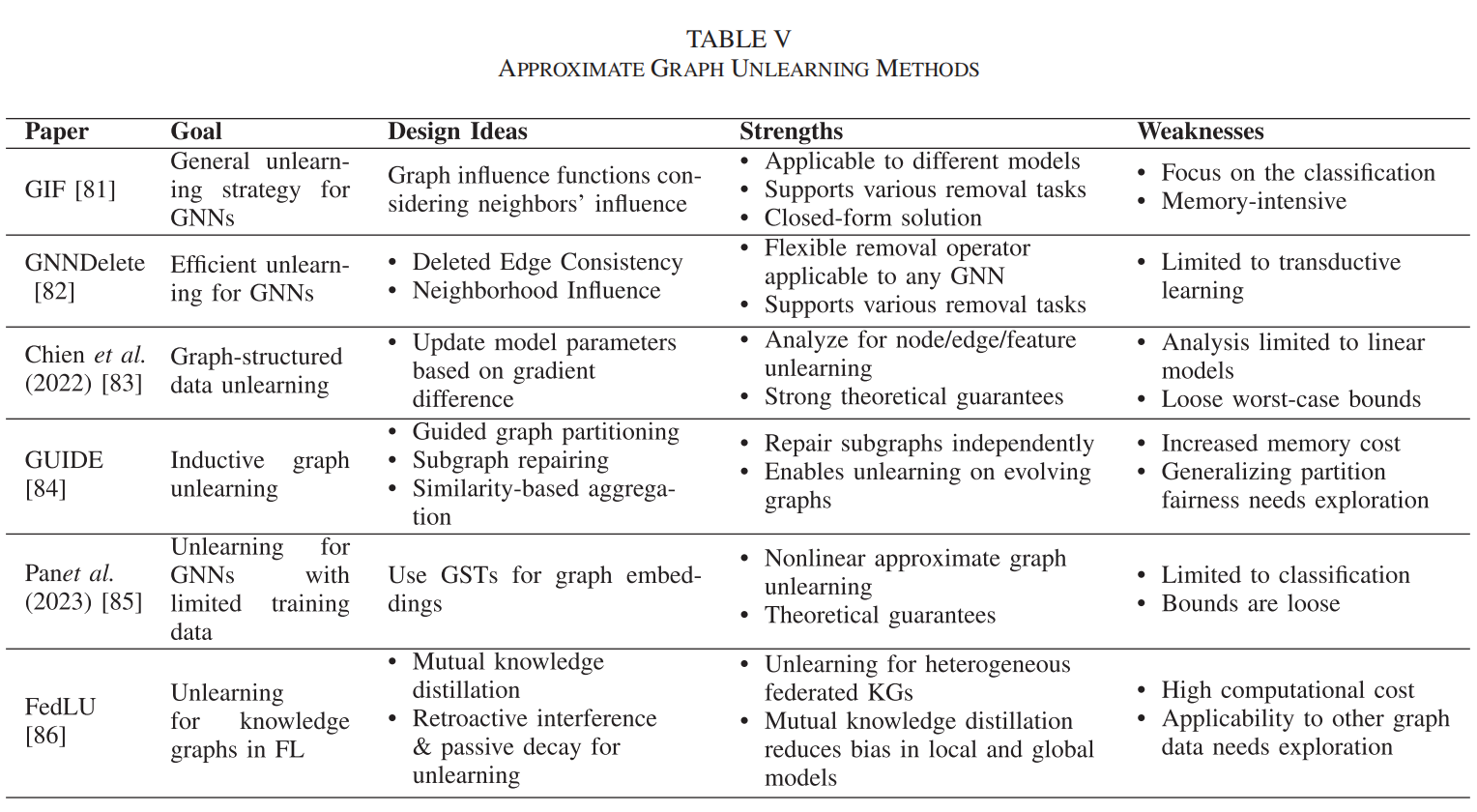
(4)特定于圖數據的近似遺忘
原理:圖數據由于其固有的依賴性,需要專門的方法來處理。這些方法考慮了圖結構數據中節點和邊的相互依賴性。
代表性算法:Wu等人提出的Graph Influence Function (GIF) 考慮了節點/邊/特征對其鄰居的結構影響。Cheng等人提出的GNNDELETE方法集成了一種新穎的刪除操作符來處理圖中邊的刪除影響。
(5)基于新穎技術的近似遺忘
原理:這種方法利用獨特的模型架構或數據特性來開發新的近似遺忘技術。
代表性算法:Wang等人提出的模型剪枝方法在聯邦學習中選擇性地移除CNN分類模型中的類別。Izzo等人提出的Projective Residual Update (PRU) 用于從線性回歸模型中移除數據。ERM-KTP是一種可解釋的知識級機器遺忘方法,通過在訓練期間使用減少糾纏的掩碼(ERM)來分離和隔離特定類別的知識。
2.2 威脅、攻擊、防御
(1)威脅(Threats):指的是危害機器遺忘系統的安全和隱私的潛在風險。這些威脅源自系統內部的脆弱性或外部的惡意行為。威脅包括信息泄露(Information Leakage)和惡意遺忘(Malicious Unlearning)。
- 信息泄露(Information Leakage):未遺忘模型和遺忘模型之間的差異被用來推斷敏感信息。
- 模型差異導致的泄露(Leakage from Model Discrepancy): 這種方式的信息泄露來自于訓練模型和被遺忘模型之間的差異。攻擊者可以利用這些差異來獲取關于被遺忘數據的額外信息。具體手段可能包括:
- 成員資格推斷攻擊(Membership Inference Attacks):攻擊者嘗試確定特定的數據點是否屬于被遺忘的數據,通過分析模型對數據點的響應差異。
- 數據重建攻擊(Data Reconstruction Attacks):攻擊者嘗試根據模型的輸出重建被遺忘的數據點。
- 惡意請求(Malicious Requests):惡意用戶提交請求以破壞模型的安全性或性能。
- 知識依賴性導致的泄露(Leakage from Knowledge Dependency): 這種方式的信息泄露來自于模型與外部知識源之間的自然關系。這可能包括:
- 自適應請求(Adaptive Requests):連續的遺忘請求可能揭示關于其他數據點的信息,攻擊者可以通過一系列請求來收集足夠的知識,以確定特定數據的成員資格。
- 緩存的計算(Cached Computations):遺忘算法可能緩存部分計算以加快處理速度,這可能無意中泄露了跨多個版本中本應被刪除的數據的信息。
- 模型差異導致的泄露(Leakage from Model Discrepancy): 這種方式的信息泄露來自于訓練模型和被遺忘模型之間的差異。攻擊者可以利用這些差異來獲取關于被遺忘數據的額外信息。具體手段可能包括:
- 惡意遺忘(Malicious Unlearning)
- 直接遺忘攻擊(Direct Unlearning Attacks): 這類攻擊僅在遺忘階段發生,不需要在訓練階段操縱訓練數據。攻擊者可能利用模型的推斷服務來獲取關于訓練模型的知識,并使用對抗性擾動等方法來制定惡意遺忘請求。直接遺忘攻擊可以是無目標的,旨在降低模型在遺忘后的整體性能,也可以是有目標的,目的是使遺忘模型對具有預定義特征的目標輸入進行錯誤分類。
- 預條件遺忘攻擊(Preconditioned Unlearning Attacks): 與直接遺忘攻擊不同,預條件遺忘攻擊采取更策略性的方法,在訓練階段操縱訓練數據。這些攻擊通常設計為執行更復雜和隱蔽的有目標攻擊。預條件遺忘攻擊通常通過以下步驟執行:
- 攻擊者在干凈數據集中插入有毒數據(Poisoned Data)和緩解數據(Mitigation Data),形成一個訓練數據集。
- 服務器基于這個數據集訓練機器學習模型并返回模型。
- 攻擊者提交請求以遺忘緩解數據。
- 服務器執行遺忘過程并返回一個遺忘模型,該模型實際上對應于僅在有毒數據和干凈數據上訓練的模型。通過這種方式,遺忘過程中移除緩解數據后,模型就會對訓練階段插入的有毒數據變得脆弱。
- 其他漏洞(Other Vulnerabilities)
- “減速攻擊”:一種旨在減慢遺忘過程的投毒攻擊,通過策略性地在訓練數據中制作有毒數據,最小化通過近似更新處理的遺忘請求的間隔或數量。
- 公平性影響:討論了遺忘算法本身可能在特定領域應用中引入的副作用,例如在大型語言模型中影響公平性。
(2)攻擊(Attacks):基于上述威脅,攻擊者執行的具體行動。這些攻擊發生在機器遺忘的任何階段,包括:
- 訓練階段攻擊(Training Phase Attacks):如數據投毒,攻擊者在訓練數據中注入惡意數據。
- 遺忘階段攻擊(Unlearning Phase Attacks):如提交設計精巧的請求以移除對模型性能至關重要的數據點。
- 后遺忘階段攻擊(Post-Unlearning Phase Attacks):利用對模型的雙重訪問來提取額外信息或發起更復雜的攻擊。
(3)防御(Defenses):為了保護機器遺忘系統免受威脅和攻擊,研究者和實踐者開發了多種防御機制。這些防御包括:
- 預遺忘階段(Pre-unlearning Stage):在遺忘過程開始之前檢測惡意請求或制定遺忘規則。
- 遺忘階段(In-unlearning Stage):監控模型變化,如果檢測到異常則停止遺忘過程。
- 后遺忘階段(Post-unlearning Stage):保護遺忘后模型的信息泄露,或恢復模型到攻擊前的狀態。
2.3 通過攻擊手段來評估機器遺忘系統的有效性
(1)隱私泄露審計(Audit of Privacy Leakage)
- 目的:評估機器遺忘系統在遺忘過程中可能產生的隱私泄露。
- 方法:使用攻擊手段,如推斷攻擊,來檢測訓練模型和遺忘模型之間的差異,或利用系統內部的漏洞來提取信息。
- 指標:采用諸如區域下曲線(AUC)和攻擊成功率(ASR)等指標來量化隱私攻擊的有效性,從而指示隱私泄露的程度。
(2)模型魯棒性評估(Assessment of Model Robustness)
- 目的:通過惡意遺忘評估遺忘模型的魯棒性,類似于對抗性攻擊中使用的原則。
- 方法:提交被擾動的數據點進行遺忘,以改變分類器的決策邊界,從而評估模型對邊界附近數據點的敏感性和對挑戰模型預測能力的點的影響。
- 技術:例如,在大型語言模型(LLMs)中,攻擊者可能插入對抗性嵌入到提示的嵌入中,以提取模型中本應被遺忘的知識。
(3)遺忘證明(Proof of Unlearning)
- 目的:使用攻擊手段來證明遺忘過程的有效性,即驗證數據是否已被有效地從模型中移除。
- 方法:如果遺忘后的數據在模型中沒有顯示出成員資格,或者遺忘數據中的后門無法被檢測到,則可以認為遺忘數據已以高概率從模型中有效移除。
- 應用:研究中使用了標準的推斷攻擊和后門攻擊的變體,或其他對抗性攻擊來檢測遺忘程序的不足。
2.4 驗證指標和評價指標
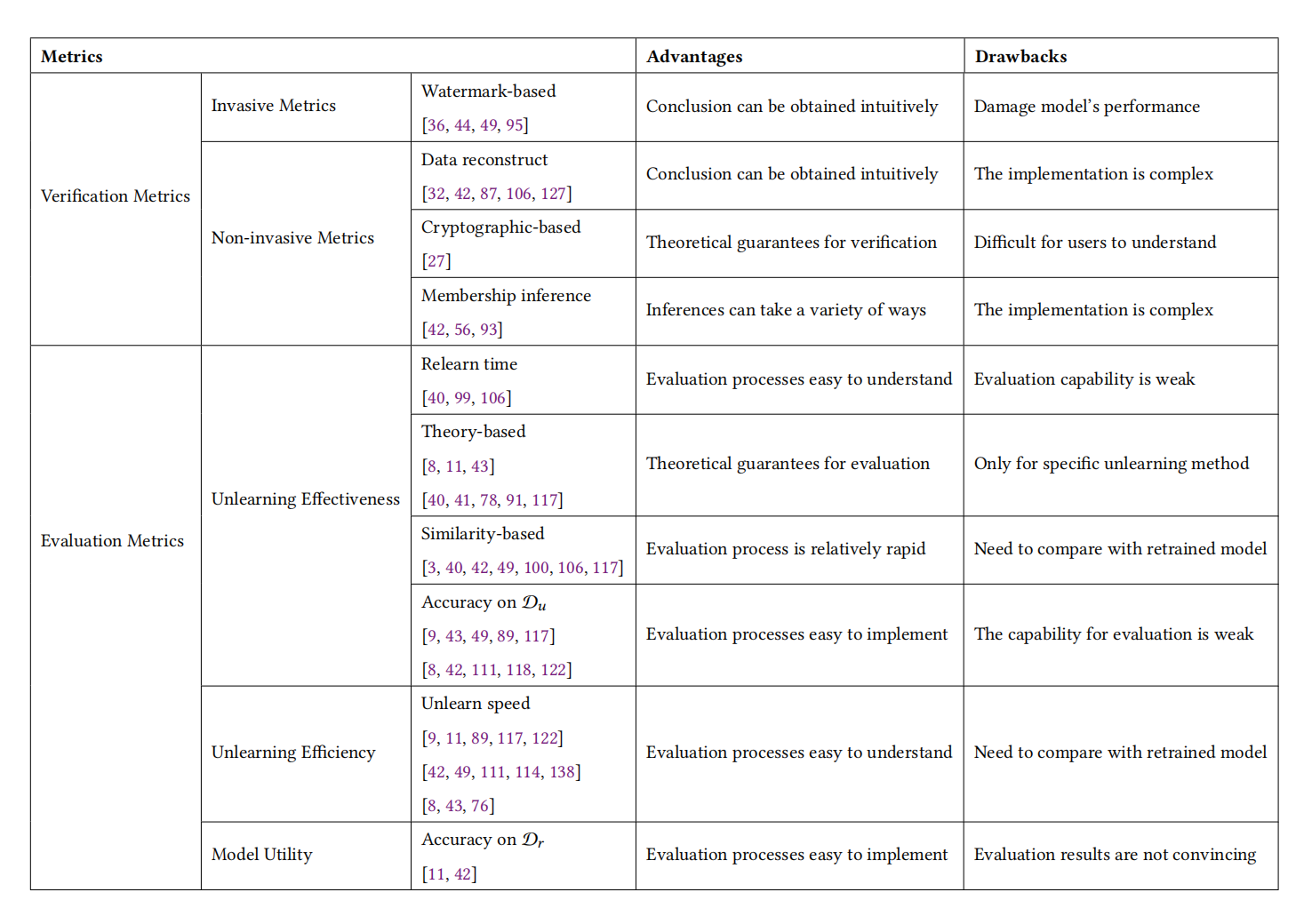
(1)驗證指標(Verification Metrics)
驗證指標主要用于數據提供者來驗證模型提供者聲稱的遺忘效果是否真實。
- 侵入性指標(Invasive Metrics):
- 基于水印的指標:通過在數據或模型參數中嵌入水印(如后門觸發器或特定二進制字符串),然后在遺忘后驗證這些水印是否仍被模型所記憶。
- 非侵入性指標(Non-invasive Metrics):
- 成員資格推斷指標:確定給定數據樣本是否存在于訓練數據集中,以驗證模型是否仍包含有關被遺忘數據的信息。
- 數據重構指標:基于模型輸出或參數,嘗試重構訓練數據信息,以驗證遺忘數據是否仍被模型保留。
- 基于密碼學的指標:使用密碼學方法提供遺忘過程的證明,如使用簡潔的非交互式知識論證。
(2)評價指標(Evaluation Metrics)
評價指標幫助模型提供者評估其遺忘算法的有效性、效用和效率。
- 有效性指標(Effectiveness Metrics):
- 重學時間指標:測量遺忘后的模型重新獲得與原始模型相同精度所需的訓練周期數。
- 基于相似度的指標:通過測量遺忘模型與重新訓練模型之間的激活、權重或分布距離來評估遺忘效果。
- 理論基礎的指標:基于特定遺忘方法設計的指標,如基于重學的指標和基于認證的指標。
- 效率指標(Efficiency Metrics):
- 遺忘速度指標:評估遺忘過程的效率,測量遺忘操作與從頭開始訓練相比所需的時間差異。
- 效用指標(Utility Metrics):
- 在被遺忘數據集上的精度:評估遺忘操作對模型在剩余數據集上預測準確性的影響,確保遺忘后的模型仍然可用。
(3)其他相關指標
- 遺忘率(Forgetting Rate):通過測量成員資格推斷的精度變化來直觀地衡量遺忘成功率。
- 記憶掩蔽(Neuron Masking):通過掩蓋神經網絡中的特定神經元來實現對特定數據的遺忘。
3 參考文獻
-
Xu J, Wu Z, Wang C, et al. Machine unlearning: Solutions and challenges[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024. 【引用量 12】
-
Liu Z, Ye H, Chen C, et al. Threats, attacks, and defenses in machine unlearning: A survey[J]. arXiv preprint arXiv:2403.13682, 2024. 【引用量 3】
-
Li N, Zhou C, Gao Y, et al. Machine Unlearning: Taxonomy, Metrics, Applications, Challenges, and Prospects[J]. arXiv preprint arXiv:2403.08254, 2024. 【引用量 3】
-
Wang W, Tian Z, Yu S. Machine Unlearning: A Comprehensive Survey[J]. arXiv preprint arXiv:2405.07406, 2024.【引用量 0】




![ES8.13.0 java client請求響應報錯status: 200, [es/search] Failed to decode response](http://pic.xiahunao.cn/ES8.13.0 java client請求響應報錯status: 200, [es/search] Failed to decode response)
)





,沒法在云服務器上魔法拉取鏡像的快來)


![[圖解]企業應用架構模式2024新譯本講解19-數據映射器1](http://pic.xiahunao.cn/[圖解]企業應用架構模式2024新譯本講解19-數據映射器1)




